



Эта статья является переводом статьи из блога Uber. Обычно мы в Qameta Software не занимаемся переводами, но мимо этой статьи пройти не смогли (спасибо @vbrekelovза то, что подкинул такой хороший пост на почитать!). Хороший и исчерпывающий материал о том, что такое flaky-тесты, какие они бывают и что с ними делать. Часть материала, посвященную переезду Uber с микросервисов на монорепо я опустил, оставив только то, что напрямую связано с отработкой flaky-тестов.
Юнит-тесты лежат в основе любой Continuous Integration (CI) системы. Они позволяют обеспечить контроль над качеством кода при высоких темпах разработки, предупреждая инженеров о багах в новом коде и регрессии в кодовой базе. Кроме того, они снижают стоимость разработки за счет обнаружения ошибок на ранних этапах. Именно поэтому построение стабильной и работающей тестовой инфраструктуры является одним из базовых требований для любой крупной разработки.
К сожалению, flaky-тесты осложняют жизнь тем, кто это требование пытается выполнить. Давайте считать, что мы будем принимать тест как flaky если на любых двух воспроизведениях он возвращает разные результаты: прошел или упал, — без изменения кода. Такие тесты чаще всего возникают в результате одной из двух причин: недетерминированность на уровне кода (порядок исполнения тредов и другие сложности с многопоточностью) или неоднородностью окружений, в которых выполняется тестирование (на одной машине все работает хорошо, а на CI-сервере тесты падают).
Давайте рассмотрим простой пример, на котором будет понятно, откуда у проблемы ноги растут:
private static int REDIS_PORT = 6380;
…
@Before
public void setUp() throws IOException, TException {
MockitAnnotations.initMocks(this);
…
server = RedisServer.newRedisServer(REDIS_PORT);
…
}
Метод SetUp, который исполняется до прогона тестов, подключается к RedisServer по порту 6380, объявленному в переменной REDIS_PORT. Это значит, что на локальной машине тесты будут успешно проходить (при отсутствии багов). Однако если запустить их на CI-сервере, они пройдут только если порт 6380 будет свободен в момент прогона. Если на сервере окажется другой код, слушающий этот порт, тесты упадут, бросив исключение "port already in use".
Получается, чтобы воспроизвести нестабильное поведение теста, разработчику надо понимать, откуда эта нестабильность возникает (в нашем примере — если порт захардкодили). А чтобы это понять, хорошо бы воспроизвести нестабильное поведение. Получается замкнутый круг, в котором у одной причины нестабильности поведения теста может быть много разных проявлений, а любое проявление проблемы может происходить по множеству причин. Более того, надо помнить о том, что воспроизвести стектрейс исключения можно только на правильно настроенном окружении (в нашем случае — учитывать состояние портов и многопоточность).
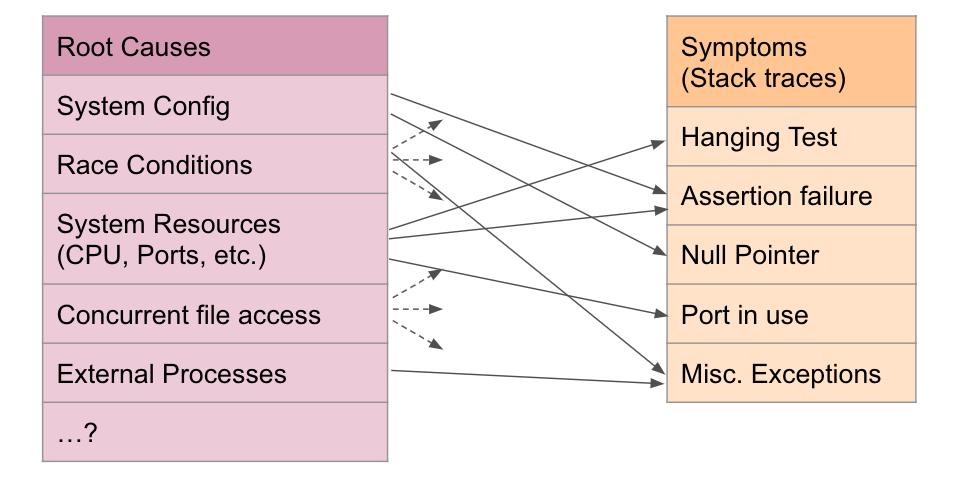
Тут стоит добавить, что наибольшую головную боль нестабильные тесты стали доставлять в момент, когда команда Uber затеяла переезд с микросевисов на монорепозитории, получив кучу красных тестов непонятного происхождения на большом CI (тесты, которые у команд спокойно выполнялись и проходили в микросервисные времена).
Далее пойдет рассказ о том, как команда Uber разрабатывали собственный Test Analyzer Service, который обслуживает unit-тесты и изолирует моргающие тесты. Кроме того, ниже будет представлена классификация источников нестабильности поведения и опыт построения инструментария для анализа и воспроизведения таких тестов.
Test Analyzer Service, что это и как работает
Главной задачей на первом этапе переезда на монорепо стало отделение стабильный тестов от нестабильных. По большому счету, это просто — нужно периодически прогонять все unit-тесты на главной ветке репозитория и вести историю последних k результатов прогона для каждого теста. Как только тест загорается красным — мы записываем его в категорию нестабильных и работаем с ним отдельно.
Для этого и был создан инструмент, помогающий анализировать и визуализировать репорты unit-тестов на масштабах тестирования Uber. Его ядром стал Test Analyzer Service (TAS), собирающий и обрабатывающий данные, связанные с прогоном каждого теста, так, чтобы любой разработчик мог их проанализировать. Сервис собирает набор метаданных, таких как время и частота исполнения теста, последний успешный результат и прочее. Сервис под конкретный ЯП каждого из репозиториев Uber, собирая информацию о сотнях тысяч тестов. В каждом репозитории работают разные CI-пайплайны, постоянно прогоняющие тесты и скармливающие результаты TAS. Новые данные хранятся в базе, а исторические — в хранилище (warehouse). В такой системе TAS используется как отдельный кастомный пайплайн для исполнения всех unit-тестов репозитория с целью обнаружения и изоляции flaky-тестов.
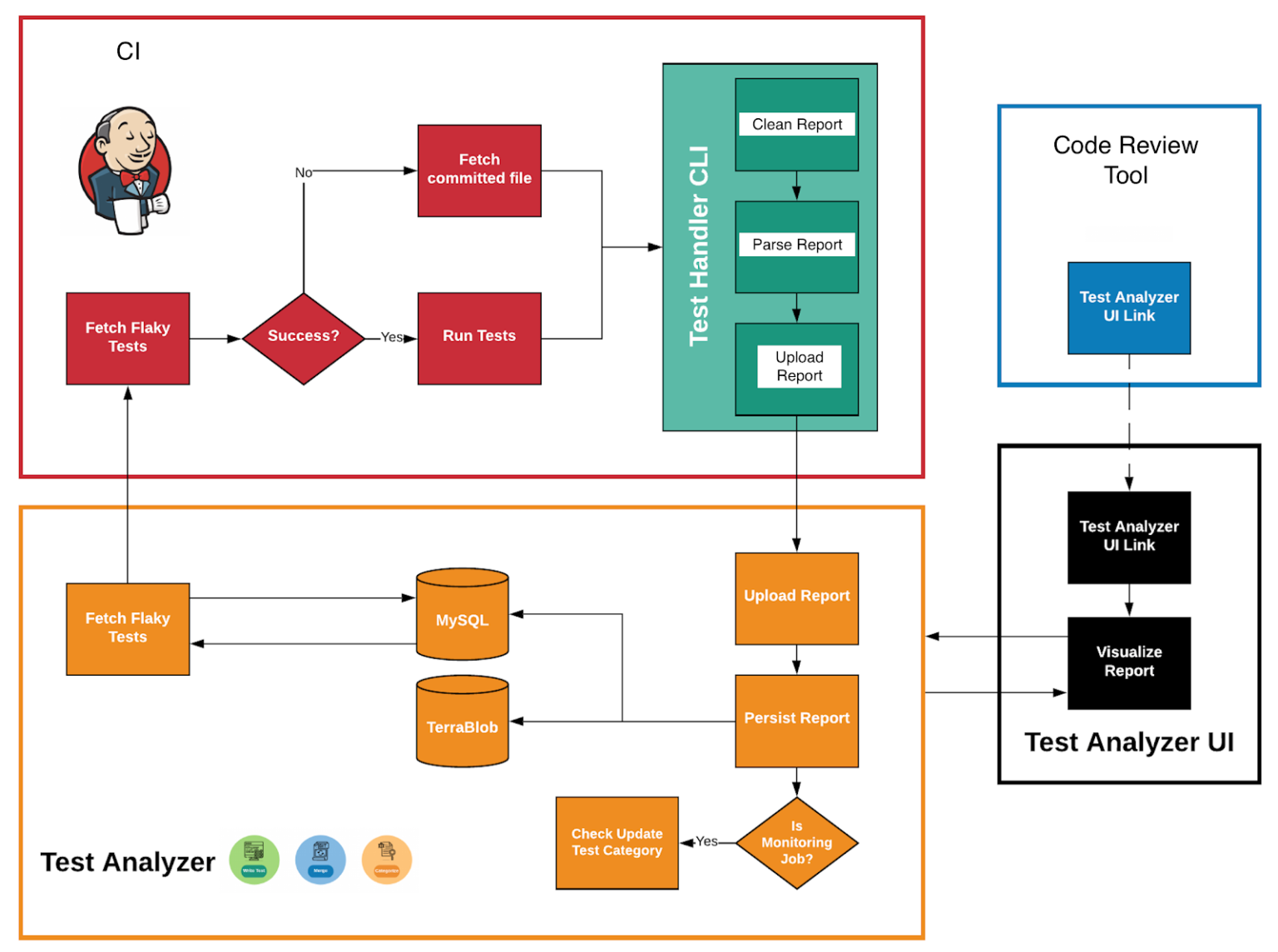
Для обнаружения нестабильного поведения собирается следующая информация о тетах и прогонах:
Метаданные тест-кейса:
Имя теста.
Имя набора тестов.
Имя для идентификации правил сборки в проекте.
Результат теста.
Время исполнения теста.
Количество последовательных успешных прогонов.
Стектрейс каждого падения теста, если такой имеется.
Текущий статус теста (стабильный или нестабильный).
Эта информация используется для того, чтобы по результатам 100 прогонов на главной ветке тест определяется как стабильный. Если нет — нестабильный. На основе такого разделения, сервис отключения flaky-тестов периодически такие тесты (внезапно) отключает от результатов прогона. Другими словами, упавшие как нестабильные тесты игнорируются при тестировании нового кода. Выглядит это следующим образом:
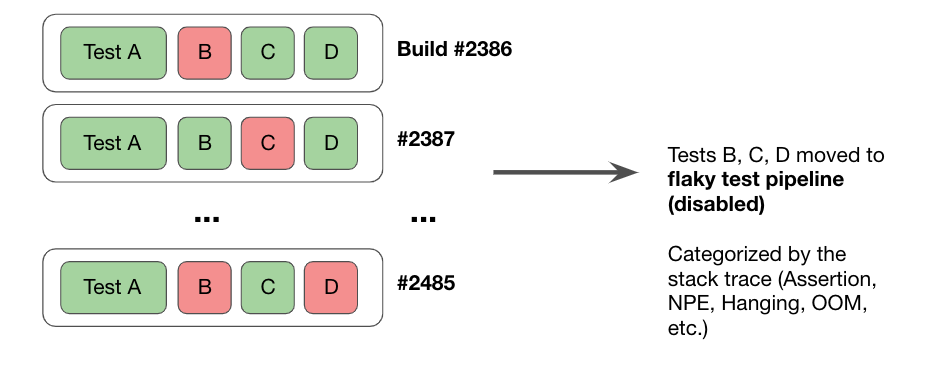
Как результат, flaky-тесты игнорируются при слиянии, что снижает их влияние на скорость выпуска релизов. Конечно, это влияет на надежность, поскольку функциональность, покрытая нестабильными тестами, остается вообще непротестированной на время, пока тест не признается нестабильным. Это осознанный выбор команды Uber, сделанный в пользу скорости разработки. В такой парадигме мы ожидаем, что разработчики и команды тестирования исправляют тесты или проверяемый код до тех пор, пока тест не пройдет 100 успешных прогонов на настроенном CI-пайплайне
Получается, что мы теперь можем определять и изолировать нестабильные тесты. Проблема решена, однако решена не полностью:
Мы же просто игнорируем тесты! По сути, закрывая глаза на потенциальные баги и оставляя решение проблемы "будущим себе".
У разработчиков нет инфраструктуры для оценки важности и исправления flaky-тестов. Как результат, очень много багов закрываются с резолюцией "невозможно воспроизвести".
Как все-таки справляться с нестабильными тестами?
К решению этой проблемы решили подойти поэтапно.
В первую очередь, вручную проанализировали, кластеризовали и приоритизировали причины нестабильности тестов, исправив вызывающие их инфраструктурные проблемы. Такое решение позволило сразу значительно понизить количество flaky-тестов, но масштабировать его не получилось бы — процесс не позволял быстро и эффективно отрабатывать длинный хвост симптомов и причин нестабильности. Кроме того, команда, ответственная за тестирование монолита не могла разобрать многие тесты в силу отсутствия контекста для множества тестов, созданных другими командами. А значит и исправить их они бы не могли.
Таким образом, для того, чтобы любой разработчик мог оценить и исправить баг, Uber разработали инструмент, способный воспроизводить баги локально. Также с целью снижения количества новых flaky-тестов, попадающих в репозиторий, Uber написали свой статический анализатор, не пропускающий в репозиторий тесты с уже известными источниками нестабильного поведения. Давайте поближе посмотрим, как эти шаги работают.
Категории нестабильности тестов
Как выше уже было сказано, нестабильный тест может быть таким сам по себе или в результате влияния внешних факторов: зависимостей, инфраструктуры, окружения или рантайма. Чтобы разобраться в этом, Uber проанализировали причины падения, изучая стектрейсы множества моргающих тестов. Получилось, что большая часть тестов падает в результате взаимодействия с внешними факторами:
Исполнение в высокопараллелизированном окружении: до перехода на монорепо, все репозитории прогоняли свои тесты последовательно. В едином репозитории тесты выполняются параллельно, и это может приводить к конфликтам доступа к ресурсам процессора/памяти, вызывающим нестабильное поведение.
Собственные серверы или базы данных: многие тесты использовали собственные инстансы баз данных (cassandra, mariadb, redis) с собственной логикой запуска, отключения и последующей чистки данных. Такие кастомные реализации часто содержали небольшие ошибки, которые приводили к тому, что сервера или падали, или не запускались — это приводило к тому, что все тесты, опирающиеся на такие инстансы, определялись как нестабильные.
Конфликты доступа к портам:
Серверы и базы данных из предыдущего пункта часто использовали порты, жестко прописанные в коде (захардкоженые, в общем), что приводило к нестабильности исполняемых на них тестов при параллельном исполнении на "главном" CI.
Spark по умолчанию запускает UI сервер, и при конфигурировании это периодически не отключалось. В результате возникали проблемы привязки портов в случае, если несколько тестов запускали свой Spark. Нестабильно!
Поскольку большинство flaky-тестов оказывались таковыми из-за внешних факторов, команда начала централизованную отработку таких факторов:
Мигрировали тесты с собственных инстансов БД на контейнеры при помощи testcontainers.
Это позволило отделить реализацию от исполнения и стабилизировать процессы запуска и остановки БД.
Базы данных теперь начали работать в собственных контейнерах, что автоматически решило проблему доступа к портам.
Testcontainers использовался для MariaDB, Cassandra, Redis, Elasticsearch и Kafka.
Для Spark тестов, Spark UI был полностью отключен за ненадобностью. Это исключило конфликты.
В процессе решения инфраструктурных причин нестабильности, Uber в то же время занялись созданием инструмента для воспроизведения ошибок, чтобы в будущем иметь возможность все-таки их дебажить, а не просто откладывать.
Воспроизводим моргающие тесты
Итак, чтобы обеспечить разработчика возможность воспроизводить ошибки, был создан отдельный инструмент, который позволял разработчику ввести все данные по упавшему тесту и запустить автоматический анализатор. Анализатор прогоняет тест по множеству сценариев с целью максимизации вероятности обнаружения причины ошибки. В частности, в его работу входили следующие шаги:
Прогнать сам тест.
Прогнать все тесты класса.
Прогнать все тесты, работающие с целевой функциональностью.
Прогнать тест в режиме обнаружения коллизий портов.
Повторять шаги с первого по третий с постепенным увеличением нагрузки.
Первые три категории исполнения нацелены на обнаружение локальных источников падения в тесте, классе или в тестируемом коде. Например, в редких случаях прогон тестового метода в отрыве от других тестов в классе вызывал падение из-за зависимости тестов друг от друга внутри класса (например, независимый тест использовал состояние, созданное другим тестом в классе). Такое простое правило позволило исправить немало кажущихся нетривиальными падений.
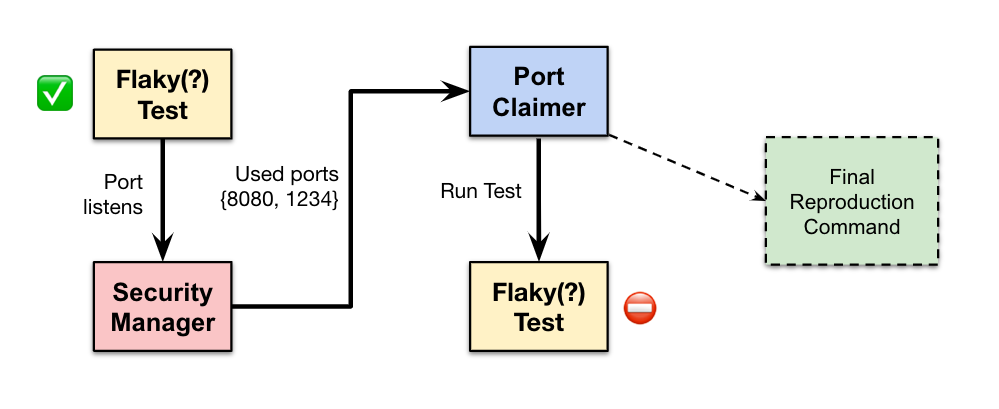
Как уже говорилось выше, много тестов падало в результате конфликта доступа к портам. Наблюдения показали, что обнаружить такие случаи можно только в случае единовременного вызова правильной комбинации тестов. Такой подход плохо работает на сотне тысяч тестов, как вы понимаете. Вместо этого, Uber спроектировали анализ тестов, обнаруживающий потенциальные источники конфликта портов с другими тестами при независимых запусках.
Для этого, при помощи Java Security Manager выяснялось, какие порты использует тест. Затем запускается отдельный сервис Port Claimer, который занимает эти порты (и на IPv4, и на IPv6). Тест перезапускается, видит занятые порты и пытается занять другие, после чего Port Claimer занимает и их. Так, цикл прогоняется несколько раз с целью выявления определения всех портов, которые задействует тест. Если в итоге тест падает, мы получаем простую команду, которая позволяет запустить Port Claimer, занять все используемые порты и выполнить нестабильный тест в таких условиях — такой подход позволяет решить проблему коллизий локально, без траты времени и ресурсов на параллельное исполнение больших наборов тестов.
Последнее — это прогон тестов под нагрузкой на ноду. Это делается через создание множества процессов (как в линуксовой команде stress) и позволяет проверить поведение теста в условиях высокой загрузки процессора. Если в коде теста есть зависимость от таймингов — еще одна причина, часто вызывающая нестабильность — эту нестабильность можно сразу обнаружить. Для воспроизведения ошибки, анализатор отдает данные о том, какая нагрузка на ЦП должна быть, чтобы локально воссоздать условия падения.
Статический анализ
Теперь можно с уверенностью сказать, что мы научились отрабатывать обнаруженные flaky-тесты, но это лишь полдела. Вторая задача — минимизировать количество новых нестабильных тестов в проекте.
Понятно, что на масштабах Uber, достичь этого хочется, не прибегая к запуску множества инстансов динамического анализатора тестов на весь тестовый набор — при каждом изменении кода это потребовало бы прогонять тысячи тестов для проверки потенциальных конфликтов. Кроме того, каждый тест пришлось бы выполнять много раз с разными условиями. Это все привело бы к неприемлемому росту времени на код ревью, так что естественным решением стала разработка статического анализатора, который ищет паттерны, часто приводящие к нестабильному поведению теста.
В Uber для статического анализа Java-кода используют фреймворк Error Prone от Google (на что еще посмотреть: NullAway, Piranha). То есть команда, ответственная за проект, разработала набор несложных инспекций, обнаруживающих паттерны, склонные вызывать нестабильное поведение тестов на CI.
Когда в тесте обнаруживаются подобные паттерны, при компиляции — и локально, и на CI — возникает ошибка, которая просит разработчика исправить или "подавить" (в оригинале используется suppress — сделать что-то, чтобы ошибка не проявлялась) проблему. Все это централизованно мониторится, ведется статистика срабатывания инспекций, а также частота "подавления" для каждой.
Далее рассмотрим, как это все работает на одном примере: на инспекции ForbidTimedWaitInTests. Вот у нас есть код, использующий джавовый CountDownLatch:
final CountDownLatch latch = new CountDownLatch(1);
Thread t = new Thread(new CountDownRunnable(latch));
t.start();
assertTrue(latch.await(100, TimeUnit.MILLISECONDS));
...При исполнении кода создается объект latch со значением обратного отсчета 1, после чего он пробрасывается в фоновый поток t, в котором выполняется та или иная задача (в примере это объект CountDownRunnable), по завершении которой вызовется сигнал завершения latch.countDown().
Запустив поток, код вызывает latch.await с ожиданием в 100 миллисекунд. Если исполнение кода уложится в это время, метод вернет значение True, и JUnit получит положительный результат и двинется дальше. Однако, если задача будет выполняться дольше, тест упадет и вызовет false на assert. Предполагается, что 100 миллисекунд достаточно для исполнения CountDownRunnable, но что будет происходит, если процессор находится под высокой нагрузкой?
В такой ситуации, лучше волюнтаристским решением запретить использование ограничений на базе API вызовов latch.await(…) в тестовом коде, заменив их неограниченными вызовами await(). Да, это приводит к проблемам другого рода и может подвешивать процессы. Тем не менее, вводя такое ограничение только на тестовом коде, можно положиться на правильно подобранное глобальное ограничение времени исполнения unit-тестов, это позволит обнаружить ошибки, вызывающие подвешивания. По мнению разработчиков, такой подход лучше, чем ситуация, когда каждый разработчик самостоятельно определяет, за какое время та или иная операция должна исполняться на CI. Стоит отдельно отметить, что в правилах есть отдельное разрешение на использование ограниченного ожидания для кода, если анализатор считает, что операция всегда может выбиваться за временные рамки независимо от нагрузки на CPU, так как это не будет причиной нестабильности (flakyness) из-за нагрузки.
И какая от всего этого польза?
Получается, что разработчики вносят изменения в код, проходящий через CI, обнаруживающий ошибки компиляции или падения тестов. В случае, если сборка проходит успешно, разработчик может смерджить свой код при помощи SubmitQueue (SQ). Нестабильные же тесты приводят к падению джоб CI и SQ, что приводило к тому, что разработчики ничего не могли сделать с этим, кроме как пытаться самостоятельно разобраться в том, что произошло. Из-за этого, скорость разработки и выкатывания новой функциональности сильно страдала.
Перечисленные выше шаги и инструменты позволили разработчикам лучше понимать, что произошло, а также снизить расходы на ресурсы, используемые CI, за счет уменьшения времени прогонов и количества перезапусков.
В итоге, команде удалось сократить количество flaky-тестов на 85%, что позволило выполнять перезапуск упавших тестов на главной CI с целью определения того, являются ли они flaky. Если это оказывалось так, то билд пропускался без запуска TAS (и удаления тестов). В итоге, такой подход минимизировал влияние нестабильных тестов на CI и SQ и привел к улучшению стабильности релизов и продуктивности разработки.
Что дальше?
Проект планируют развивать и дальше:
Расширение инструментария для определения причин нестабильного поведения, таких как ошибки многопоточности или любые взаимодействия между тестами.
Инструменты, способные назначать воспроизводимые нестабильные тесты на конкретных инженеров, обладающих контекстом и способностью такие тесты починить.
Расширение функциональности системы, воспроизводящей нестабильные тесты, и статического анализатора (например, запрет прописывания конкретных портов в коде, включая код зависимостей и конфигов).
Расширение поддержки языков для других монорепо Uber (Go, например)
Если вы дочитали до сюда, то вы молодец.