Что пишут в блогах
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Python для тестировщиковНачало: 10 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Python для начинающихНачало: 16 июля 2026
-
Азбука ИТНачало: 16 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
| Jira: когда дорогие плагины не нужны |
| 22.11.2022 00:00 |
|
кадр из анимационного фильма "Кунг-фу панда" Статья компании SimbirSoft При разработке крупного и длительного проекта зачастую используют Jira, так как с ее помощью легко формировать списки задач, отслеживать прогресс и решать разные проблемы, которые могут возникнуть. Многие скажут, что она сейчас не актуальна в связи с уходом Atlassian из России. На это мы можем возразить, что Jira является одной из самых популярных систем. Специалисты привыкли работать с ней, и многие компании продолжают ей пользоваться. Более того, она может помочь реализовать полный цикл обеспечения качества и часто используется в саппорте, поддержке системы в проде. Бизнес-требования одного из наших зарубежных клиентов заставили нас сильно углубиться в устройство Jira. Теперь мы знаем, как можно обратиться к БД Jira без использования плагинов и зачем это может понадобиться. Готовы поделиться этой информацией и с вами. Также расскажем, как работать с данными Jira напрямую (без плагинов) и минимизировать расходы на обслуживание. И все это при соблюдении GDPR (General Data Protection Regulation - общий регламент по защите персональных данных). Почему нельзя обойтись плагинами? Jira имеет хорошие базовые возможности, но часто их недостаточно. Кроме того, к ней существует довольно много плагинов, которые облегчают работу, но часто требуют лицензий, а значит увеличивают бюджет проекта. Посетив официальный сайт Atlassian, можно представить суммы, которые необходимо платить за обслуживание плагинов. Например, сегодня плагин для создания отчетов стоит от 2500 до 5000 долларов в год, если им пользуются 300 человек. В текущей ситуации оплатить их может быть затруднительно. При этом далеко не все возможности используются, в результате появляется «зоопарк» плагинов.
Все это еще больше ухудшается тем фактом, что часто «аппетит приходит во время еды». Изначально менеджмент хочет одни отчеты из Jira. Потом нужны дополнительные, которые изначально не планировались. Если возможностей действующего плагина на эти отчеты не хватает, приходится искать новый и т.д. К тому же плагины к Jira не так распространены, как сама Jira. Это создает проблемы еще и с точки зрения набора людей. Работа с платными плагинами требует их поддержки и обеспечения онбординга специалистов. А еще могут возникнуть проблемы, если имеющегося функционала недостаточно. Например, когда доступны не все сортировки, наложен лимит конфигураций, нельзя написать свою функцию или добраться до кастомных свойств, есть ограничение определенными полями, они не расширяемы и т.д. Но с Jira можно работать и напрямую через несложные запросы, которые могут создавать как разработчики, архитекторы, так и QA. Этот подход требует всего лишь уровня SQL. На одном из иностранных проектов мы с этим столкнулись. У нашего клиента есть Jira, которая размещена на его серверах. Спустя некоторое время заказчик захотел более детальных отчетов и IT-отдел клиента выбрал плагин AIO Report для Jira, чтобы использовать его для построения более детальных отчетов. Вначале возможностей AIO Report им хватало. С построением отчетом клиент справлялся самостоятельно. Но шло время, увеличилось количество команд, проектов, запросов в саппорт и т.д. После этого клиент захотел еще более детальных отчетов. И решил использовать встроенные возможности Jira, а также добавить атрибуты пользователям (Properties), кто и в какой команде находится. И тут всплыла проблема – AIO Reports не умел работать с этими атрибутами.
Тогда наш клиент попросил нас помочь ему построить систему детальных отчетов в проекте, особенно в части саппорта, поскольку стало сложно следить за выполнением SLA (service level agreement). Мы начали исследовать, что можно сделать. Один из вариантов решения – проанализировать требования к отчетам, найти плагин (еще один), который подходит под эти требования. Но в этом случае возник ряд проблем:
Пока отойдем чуть «в сторону» от проблемы, и поразмышляем на тему того, что такое хорошее решение. Логично, что оно должно удовлетворять следующим критериям:
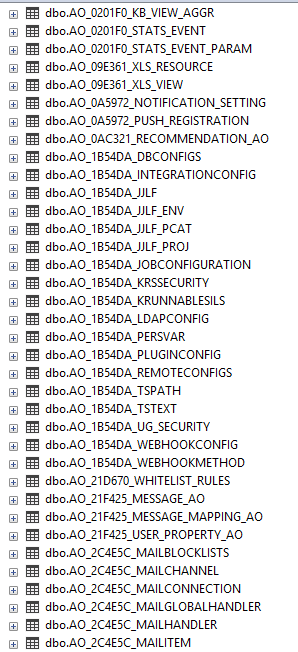
Обратите внимание, что понятие «правильной» технологии тут почти отсутствует. Если мы говорим о Jira, там можно реализовать систему custom fields, в которой можно вычислять нужные значения. Но особенность этих custom fields в том, что там необходимо знание языка Groovy. В команде нашего клиента не было людей, которые его знают. К тому же был риск, что при программировании на Groovy в отчет могли случайно попасть конфиденциальные данные, которых там быть не должно – это было одним из важнейших требований заказчика. В то же время более 50% команды хорошо знают SQL, поэтому мы начали размышлять, как можно использовать этот факт. Тогда мы решили посмотреть на Jira «глобально». По сути это интерфейс к базе данных, в которой используется SQL. Быстро найти описание структуры БД Jira не получилось, но мы попробовали исследовать её самостоятельно, полагаясь на здравый смысл. Но тут возникла небольшая проблема – некоторые поля в БД Jira содержали конфиденциальную информацию, а это связано с ограничениями GDPR, что блокировало идею. Но и тут мы нашли выход: попросили сделать репликацию БД Jira, исключив из нее столбцы, в которых были данные клиентов (почты, телефоны, attachment и т.д.). После того, как наш клиент это сделал, он проверил, что в реплицированной БД нет конфиденциальных данных, и дал нам доступ к ней. Так мы гарантировали соблюдение GDPR. врезка: Вывод: когда есть конфиденциальные данные, это не блокер. Можно поискать нестандартный вариант решения. Затем мы открыли БД и увидели следующую картину:
Как вы понимаете, названия таблиц нас не очень порадовали, хотя при желании можно было что-то разобрать. Для исследования мы решили сделать простой трюк. В нерабочее время, когда пользователей в Jira нет, добавляли одну запись в интересующее нас место и потом сравнивали количество записей в каждой таблице – до и после изменения. Такой подход почти сразу дал нам нужную информацию, что и где находится. Как оказалось, нам необходимо работать всего лишь с 9 таблицами: jiraissue, project, issuestatus, app_user, customfieldvalue, customfieldoption, label, changegroup, changeitem Рассмотрим, что содержат эти таблицы:
Самые важные для нас таблицы следующие:
Примеры задач, которые можно решить БЕЗ плагинов JiraТеперь давайте рассмотрим несколько практических задач, которые мы решали для наших целей. Приведенный ниже код – часть большого блока, поэтому использование некоторых полей локальной таблицы @historyTable отсутствует в приведенном фрагменте. На этом примере можно увидеть процесс движения работы «Open -> In Progress -> Resolved». Так мы узнали, что «реальных» путей жизненного цикла в нашей системе 42, но при этом 94% всех задач покрывается 4 путями жизненного цикла в саппорте. Или другой пример – построить таблицу, в которой будут указаны все проекты Jira (клиент просил, чтобы название столбца в отчете было CaseSource) и количество созданных задач в них, разбитых по неделе. Как видите, в целом ничего сложного. За исключением довольно редко используемого стандартного оператора pivot. Но он необходим, чтобы «повернуть» таблицу, и оформить каждую неделю отдельным столбцом. Для получения такого отчета необходимо выполнить всего 2 действия. При этом pivot в целом не нужен. Его пришлось использовать только из-за требований к оформлению отчета. И еще один пример. Клиенту надо было понимать, сколько времени было потрачено на прохождение каждой стадии при обработке задачи в Jira. «Изюминка» задачи – в команде были разные роли людей, которые работают из разных стран и имеют различные KPI. Мы сразу поняли, что стандартными средствами Jira решить этот кейс было бы проблематично. По соображениям NDA мы не можем предоставить полный код решения этой задачи, но покажем часть, которая не содержит бизнес-логики. Она определяет, кто и сколько потратил времени на обработку задачи в минутах рабочего времени. Как видите, в этой функции используется только 2 «основных» и довольно простых запроса. В этой статье мы привели несколько примеров того, как на первый взгляд сложная задача, которая должна решаться через плагины, может быть решена с помощью простых средств, например, обычного SQL. Конечно, в некотором роде надо иметь мужество, чтобы не «убежать» от такого варианта решения, когда видишь названия таблиц первых таблиц в Jira (для примера AO_1B54DA_JJLF). Исходя из соображений NDA, мы не можем привести части решений, которые содержат бизнес-логику нашего иностранного клиента. Но надеемся, что алгоритм вы поняли. Чем еще может быть полезна БД JiraДавайте отвлечемся от отчетов и посмотрим, где еще может быть полезна БД Jira. Рассмотрим такой пример. На одном из проектов после релиза очередной версии резко увеличилось количество обращений в техподдержку из-за одного и того же бага. Стандартное количество обращений – один раз в 2-3 месяца, а после релиза это значение выросло до 14 в неделю. Так как саппорт заводит задачи в Jira, можно обратиться к ее БД и с помощью несложных запросов QA-специалист может получить отчет о количестве обращений в саппорт. На его основе можно получить метрики, которые отражали бы качество работы команды QA. Если процент ошибок, попавших на прод, значительно выше, чем в предыдущих релизах, значит в процессе контроля качества что-то пошло не так. И это повод для команды QA проанализировать работу и учесть полученный опыт в будущем. Можно также отметить, что даже если у QA-специалиста нет доступа к БД Jira (например, из-за наличия конфиденциальных данных), то он все равно может использовать ее для снятия метрик. Он будет анализировать только результаты запросов, а сами запросы может периодически (раз в неделю, месяц или через какое-то время после релиза) выполнять тот член команды, у кого этот доступ есть.
К каким выводам мы пришли в итоге 1. Требования бизнеса первичны и они часто вынуждают использовать не совсем стандартные подходы. В данном случае важнейшим требованием было ненарушение GDPR. 2. Никогда не надо бояться «работать с основами», даже если от первого взгляда на названия таблиц хочется убежать подальше. В данном случае основой Jira является БД. 3. Не надо забывать, что любая система написана человеком, поэтому там должна быть логика хранения данных. Она может быть странной, но она есть. И всегда можно исследовать её через сравнение количества записей в каждой таблице до и после изменений. 4. Хорошее решение необязательно должно использовать последнюю версию какого-либо дорогостоящего плагина. Решение будет подходящим, если его может поддерживать текущая команда, оно будет хорошо ложиться на уровень экспертизы команды и не потребует очень специализированных знаний. 5. Всегда следует начать с поиска особенностей бизнес-логики системы, которые могут упростить задачу. Вспомните наш пример. Перед нами стояла задача построения отчетов в Jira, чтобы клиент мог посмотреть необходимую статистику по саппорту. Мы использовали тот факт, что клиенту было достаточно видеть отчеты с задержкой не более 5 минут. С учетом того, что рабочий день (с учетом перерыва на обед) 9 часов, то последние 5 минут не могут играть особой роли. Поэтому мы создали систему таблиц с заранее вычисленными значениями: если пользователь работал над задачей 10 минут и передал ее другому сотруднику, этот факт уже не изменится. Потом мы создали SQL Job и на основании таблиц changegroup и ChangeItem каждые 5 минут перевычисляли только изменившиеся задачи/значения. Это позволило избежать проблем перфоманса из-за довольно большого количества значений в отчетах и иногда странной структуры БД Jira. 6. Jira – система для работы людей, и, как правило, один человек не может генерировать 100 записей за секунду работы. Поэтому не надо добавлять в требования «жесткий» перфоманс, т.е. не нужно заниматься оптимизацией производительности. Нет разницы, если вычисление делается за 0,1 секунды или за 5 секунд – человек все равно работает медленнее. 7. Пример с метриками мы привели, чтобы показать, что область использования данных, полученных напрямую из БД Jira, не ограничивается составлением отчетов. 8. Очень важно более глубинное понимание того, как работает любой инструментарий. Способность нестандартно работать с ним, используя необычные методы, – признак профессионализма. Базовые инструменты, на примере Jira, могут стать хорошим средством интеграции усилий support-команды и QA. Они могут воплотиться в эффективный способ улучшения качества работы с support-запросами и оценкой качества тестирования системы в целом. Сюда относятся: количество наиболее проблемных запросов, категоризация запросов и другие более сложные кейсы, которые могут потребоваться по бизнес-логике для замены плагина Jira. Осуществляя, например, анализ меток, закладывая выражения через SQL для более сложного извлечения данных из Jira, можно получить информацию о состоянии проекта в целом. Ну и главное, не надо бояться применять новые подходы, если они используют «основы» бизнес-области, и тогда все получится :) О том, как мы работаем с Jira, рассказываем тут. Больше кейсов и полезных материалов для владельцев продуктов - в нашем ВК и Telegram. |