Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Азбука ИТНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Python для начинающихНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Инженер по тестированию программного обеспеченияНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
-
Bash: инструменты тестировщикаНачало: 1 октября 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 1 октября 2026
-
Docker: инструменты тестировщикаНачало: 1 октября 2026
-
SQL: Инструменты тестировщикаНачало: 1 октября 2026
-
Git: инструменты тестировщикаНачало: 1 октября 2026
| DevOps инструменты не только для Devops. Процесс построения инфраструктуры автоматизации тестирования с нуля - Продолжение |
| 17.04.2020 00:00 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
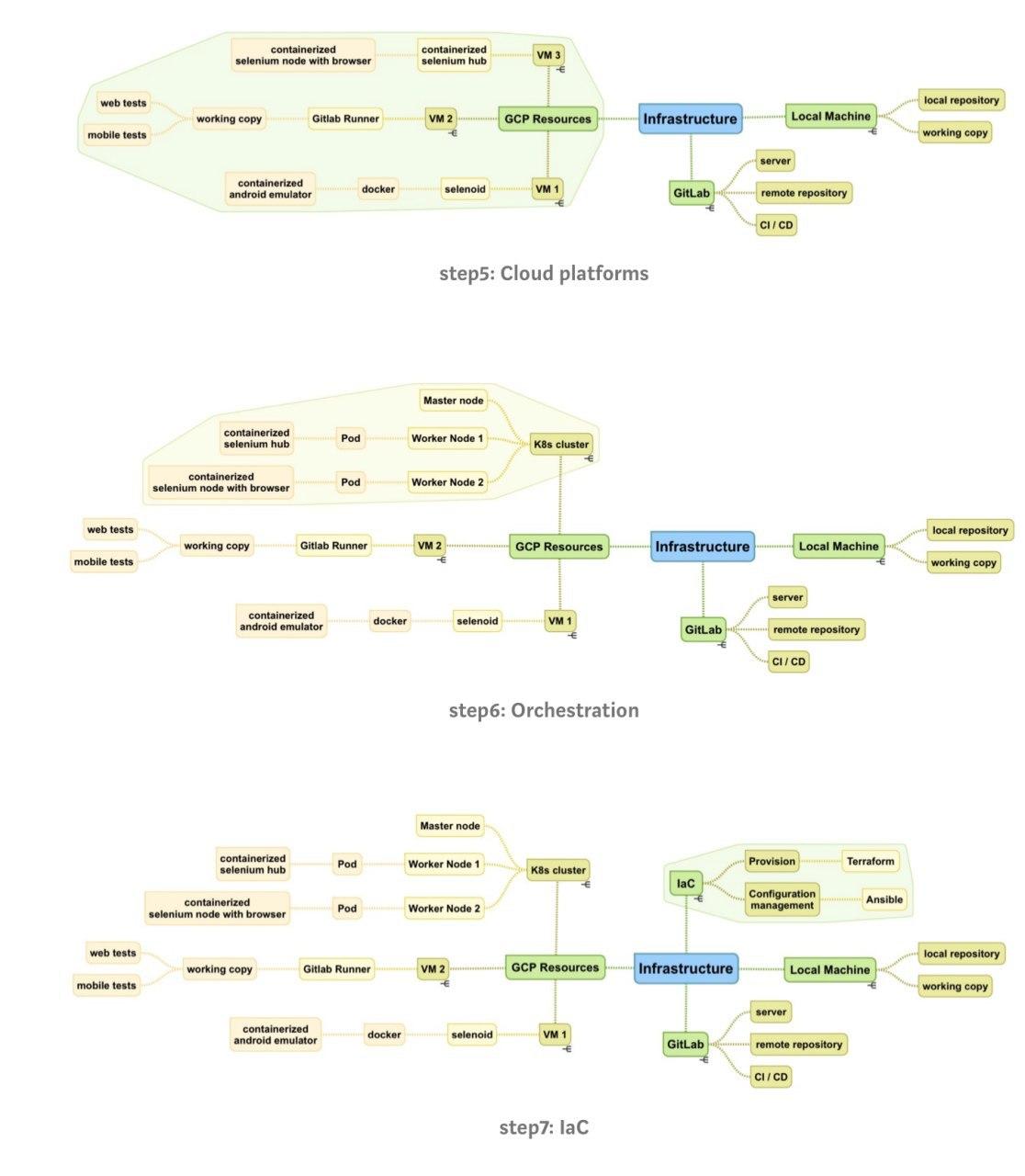
Автор: Алтунин Алексей 5. Облачные платформыКраткое описание технологииВ этом разделе мы поговорим о популярном тренде, который называется ‘публичные облака’. Несмотря на огромную пользу, которую дают описанные выше технологии виртуализации и контейнеризации, нам все еще необходимы вычислительные ресурсы. Компании приобретают дорогие сервера или арендуют дата-центры, но в таком случае необходимо сделать расчеты (иногда нереалистичные) того, как много ресурсов нам понадобится, будем ли мы их использовать 24/7 и для каких целей. Например, для production требуется работающий круглосуточно сервер, но нужны ли нам аналогичные ресурсы для тестирования в нерабочее время? Это также зависит от типа выполняемого тестирования. Примером могут быть нагрузочные/стрессовые тесты, которые мы планируем прогонять в нерабочие часы, чтобы получить результаты на следующий день. Но, определенно, круглосуточная доступность серверов не требуется для end-to-end авто-тестов и в особенности для сред ручного тестирования. Для таких ситуаций было бы хорошо получать столько ресурсов, сколько необходимо по требованию, использовать их и прекращать платить, когда они больше не нужны. Более того, было бы прекрасно получать их моментально, сделав несколько кликов мышкой или запустив пару скриптов. Для этого и используются публичные облака. Давайте посмотрим на определение: “The public cloud is defined as computing services offered by third-party providers over the public Internet, making them available to anyone who wants to use or purchase them. They may be free or sold on-demand, allowing customers to pay only per usage for the CPU cycles, storage, or bandwidth they consume”. Бытует мнение, что публичные облака – это дорого. Но их ключевая идея – уменьшение расходов компании. Как было упомянуто ранее, публичные облака позволяют получить ресурсы по требованию и платить только за время их использования. Также, иногда мы забываем, что сотрудники получают зарплату, а специалисты тоже являются дорогим ресурсом. Необходимо учитывать, что публичные облака значительно облегчают поддержку инфраструктуры, что позволяет инженерам сфокусироваться на более важных задачах. Ценность для инфраструктуры автоматизацииКакие конкретно ресурсы нам необходимы для end-to-end UI-тестов? В основном это виртуальные машины или кластеры (мы поговорим о Kubernetes в следующей секции) для запуска браузеров и эмуляторов. Чем больше браузеров и эмуляторов мы хотим запустить одновременно, тем больше CPU и памяти требуется и тем больше денег нам придется за это заплатить. Таким образом, публичные облака в контексте автоматизации тестирования позволяют нам запускать большое число (100, 200, 1000 …) браузеров/эмуляторов по требованию, получать результаты тестирования как можно быстрее и переставать платить за такие безумно ресурсозатратные мощности. Самыми популярными облачными провайдерами являются Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP). В практическом руководстве представлены примеры использования GCP, но в целом неважно, что именно вы будете использовать для задач автоматизации. Все они предоставляют примерно одинаковый функционал. Обычно для выбора провайдера руководство фокусируется на всей инфраструктуре компании и бизнес-требованиях, что за рамками данной статьи. Для инженеров по автоматизации будет интереснее сравнить использование облачных провайдеров с использованием облачных платформ конкретно для целей тестирования, таких как Sauce Labs, BrowserStack, BitBar и так далее. Так давай те же сделаем это! На мой взгляд, Sauce Labs является самой известной фермой облачного тестирования, поэтому я и взял ее для сравнения. GCP против Sauce Labs для целей автоматизации: Представим, что нам нужно прогнать одновременно 8 web-тестов и 8 Android-тестов. Для этого мы будем использовать GCP и запустим 2 виртуальные машины с Selenoid. На первой мы поднимем 8 контейнеров с браузерами. На второй – 8 контейнеров с эмуляторами. Давайте взглянем на цены:
Для запуска одного контейнера с Chrome, нам понадобится n1-standard-1 машина. В случае с Android это будет n1-standard-4 для одного эмулятора. На самом деле более гибкий и дешевый способ – это задание конкретных пользовательских значений для CPU/Memory, но в данный момент для сравнения с Sauce Labs это не принципиально. А вот тарифы на использование Sauce Labs:
Я полагаю, вы уже заметили разницу, но все же приведу таблицу с расчетами для нашей задачи:
Как видно, разница в стоимости огромна, особенно если запускать тесты только в рабочий двенадцатичасовой промежуток. Но можно еще сильнее сократить расходы, если использовать preemptible машины. Что же это такое? A preemptible VM is an instance that you can create and run at a much lower price than normal instances. However, Compute Engine might terminate (preempt) these instances if it requires access to those resources for other tasks. Preemptible instances are excess Compute Engine capacity, so their availability varies with usage. If your apps are fault-tolerant and can withstand possible instance preemptions, then preemptible instances can reduce your Compute Engine costs significantly. For example, batch processing jobs can run on preemptible instances. If some of those instances terminate during processing, the job slows but does not completely stop. Preemptible instances complete your batch processing tasks without placing additional workload on your existing instances and without requiring you to pay full price for additional normal instances. И это все еще не конец! В действительности я уверен, что никто не запускает тесты по 12 часов без перерыва. И если это так, то вы можете автоматически запускать и останавливать виртуальные машины, когда они не нужны. Реальное время использования может снизиться до 6 часов в сутки. Тогда оплата в контексте нашей задачи уменьшится аж до 11$ в месяц за 8 браузеров. Разве это не прекрасно? Но с preemptible машинами мы должны быть осторожны и готовы к прерываниям и нестабильной работе, хотя эти ситуации могут быть предусмотрены и обработаны программно. Оно того стоит! Но ни в коем случае я не говорю ‘никогда не используйте облачные тестовые фермы’. Они имеют ряд преимуществ. Прежде всего это не просто виртуальная машина, а полноценное решение для автоматизации тестирования с набором функционала из коробки: удаленный доступ, логи, скриншоты, видеозапись, различные браузеры и физические мобильные устройства. Во многих ситуациях это может быть незаменимой шикарной альтернативой. Особенно тестовые платформы полезны для IOS-автоматизации, когда публичные облака могут предложить только Linux/Windows-системы. Но разговор про IOS будет в следующих статьях. Я рекомендую всегда смотреть по ситуации и отталкиваться от задач: в каких-то дешевле и эффективнее использовать публичные облака, а в каких то тестовые платформы определено стоят потраченных денег. Иллюстрация текущего состояния инфраструктуры
6. ОркестрацияКраткое описание технологииУ меня хорошие новости – мы почти достигли конца статьи! На данный момент наша инфраструктура автоматизации состоит из web и Android-тестов, которые мы запускаем через GitLab CI параллельно, используя инструменты с поддержкой Docker: Selenium grid и Selenoid. Более того, мы используем созданные через GCP виртуальные машины для поднятия в них контейнеров с браузерами и эмуляторами. Для уменьшения расходов мы запускаем этим виртуальные машины только по требованию и останавливаем, когда тестирование не проводится. Существует ли что-то еще, что может улучшить нашу инфраструктуру? Ответ – да! Встречаем Kubernetes (K8s)! Для начала рассмотрим, как слова оркестрация, кластер и Kubernetes связаны между собой. На высоком уровне оркестрация – это система, которая разворачивает и управляет приложениями. Для автоматизации тестирования такими контейнеризируемыми (containerised) приложениями являются Selenium grid и Selenoid. Docker и K8s дополняют друг друга. Первый используется для развертывания приложений, второй – для оркестрации. В свою очередь K8s является кластером. Задача кластера использовать VMs в качестве Nodes, что позволяет устанавливать различный функционал, программы и сервисы в рамках одного сервера (кластера). Если какой либо из Node упадет, то подхватятся другие Nodes, что обеспечивает нашему приложению бесперебойную работу. В дополнение к этому K8s имеет важную функциональность, связанную с масштабированием (scaling), благодаря чему мы автоматически получаем оптимальное количество ресурсов, основываясь на нагрузке и установленных ограничениях. По правде говоря, ручное разворачивание Kubernetes с нуля является совсем нетривиальной задачей. Я оставлю ссылку на известное практическое руководство “Kubernetes The Hard Way”, и, если вам интересно, вы можете попрактиковаться. Но, к счастью, существуют альтернативные способы и инструменты. Самым легкий из них – использовать Google Kubernetes Engine (GKE) в GCP, что позволит получить готовый кластер после нескольких кликов. Для начала изучения я рекомендую использовать именно этот подход, так как он позволит вам сфокусироваться на изучении того, как использовать K8s для своих задач вместо исследования того, как внутренние компоненты должны быть между собой интегрированы. Ценность для инфраструктуры автоматизацииРассмотрим несколько значимых функций, которые предоставляет K8s:
Но K8s – все еще не серебряная пуля. Для понимания всех преимуществ и ограничений в контексте рассматриваемых нами инструментов (Selenium grid, Selenoid) кратко обсудим строение K8s. Cluster содержит два типа Nodes: Master Nodes и Workers Nodes. Master Nodes отвечают за управление, развертывание и scheduling decisions. Workers nodes – это то, где приложения запущены. Nodes также содержат среду запуска контейнеров. В нашем случае это Docker, который отвечает за операции, связанные с контейнерами. Но есть и альтернативные решения, например containerd. Важно понимать, что масштабирование или самовосстановление не относится к контейнерам напрямую. Это реализуется через добавление/уменьшение числа pods, которые в свою очередь содержат контейнеры (обычно один container на pod, но в зависимости от задачи может быть и больше). Высокоуровневая иерархия представляет собой worker nodes, внутри которых находятся pods, внутри которых подняты контейнеры. Функция масштабирования является ключевой и может быть применена как к nodes внутри cluster node-pool, так и к pods внутри node. Существует 2 типа масштабирования, которые относятся как к nodes, так и pods. Первый тип – горизонтальный – масштабирование происходит за счет увеличения числа nodes/pods. Такой тип является более предпочтительным. Второй тип, соответственно, вертикальный. Масштабирование осуществляется за счет увеличения размеров nodes/pods, а не их количества. Теперь рассмотрим наши инструменты в контексте вышеупомянутых терминов. Selenium grid: Как было упомянуто ранее, Selenium grid – очень популярный инструмент, и не сюрприз, что он был контейнеризирован (containerised). Следовательно, не вызывает удивление, что Selenium grid можно развернуть в K8s. Пример того, как это сделать, можно найти в официальном K8s-репозитории. Как обычно, прикладываю ссылки в конце секции. В дополнение к этому в практическом руководстве показано, как это сделать черед Terraform. Также есть инструкция, как масштабировать число pods, которые содержат контейнеры с браузерами. Но функция автоматического масштабирования в контексте K8s – все еще не до конца очевидная задача. Когда я начинал изучение, я не нашел никакого практического руководства или рекомендаций. После нескольких исследований и экспериментов при поддержке DevOps-команды мы выбрали подход поднятия контейнеров с нужными браузерами внутри одного pod, который находится внутри одного worker node. Такой способ позволяет нам применить стратегию горизонтального масштабирования nodes за счет увеличения их числа. Я надеюсь, что в будущем ситуация изменится, и мы увидим все больше и больше описаний лучших подходов и готовых решений, особенно после выпуска Selenium grid 4 с измененной внутренней архитектурой. Selenoid: В настоящее время развертывание Selenoid в K8s является самым большим разочарованием. Они не совместимы. Теоретически мы можем поднять Selenoid-контейнер внутри pod, но когда Selenoid начнет запускать контейнеры с браузерами, они все еще будут находиться внутри этого же pod. Это делает scaling невозможным и, как результат, работа Selenoid внутри кластера не будет отличаться от работы внутри виртуальной машины. Конец истории ❌. Moon: Зная это узкое место при работе с Selenoid, разработчики выпустили более мощный инструмент, который назвали Moon. Этот инструмент был изначально задуман для работы с Kubernetes и, как результат, можно и нужно использовать функцию автомасштабирования. Более того, я бы сказал, что в настоящий момент это единственный инструмент в мире Selenium, который из коробки имеет native K8s cluster-поддержку (уже нет, см. следующий инструмент). Ключевой особенностью Moon, которая обеспечивает данную поддержку, является: Completely stateless. Selenoid stores in memory information about currently running browser sessions. If for some reason its process crashes - then all running sessions are lost. Moon contrarily has no internal state and can be replicated across data centers. Browser sessions remain alive even if one or more replicas go down. Итак, Moon шикарное решение, но с одной проблемой, он не бесплатный. Цена зависит от числа сессий. Бесплатно можно запустить только 0-4 сессии, что не особо полезно. Но, начиная уже с пятой сессии, придется заплатить по 5$ за каждую. Ситуация может отличаться от компании к компании, но в нашем случае использование Moon бессмысленно. Как я описывал выше, мы можем запустить VMs с Selenium Grid по требованию или увеличить число Nodes в кластере. Приблизительно на один pipeline мы запускаем 500 браузеров и останавливаем все ресурсы после завершения тестов. Если бы мы использовали Moon, нам бы пришлось заплатить дополнительных 500 x 5 = 2500 $ в месяц и не важно, как часто мы запускаем тесты. И опять же, я не говорю “не используйте Moon”. Для ваших задач это может быть незаменимым решением, например, если у вас в организации много проектов/команд и вам нужен огромный общий кластер для всех. Как всегда, я оставляю ссылку в конце и рекомендую сделать все необходимые расчеты в контексте вашей задачи. Callisto: (Внимание! Этого нет в оригинальной статье и содержится только в русском переводе) Как я и сказал, Selenium – очень популярный инструмент, а сфера IT развивается очень быстро. Пока я работал над переводом, в сети появился новый многообещающий инструмент Callisto (привет Cypress и другим убийцам Selenium). Он работает нативно с K8s и позволяет запускать Selenoid-контейнеры в pods, распределено по Nodes. Все работает сразу из коробки, включая автомасштабирование. Фантастика, но надо тестировать. Мне уже удалось развернуть данный инструмент и поставить несколько экспериментов. Но выводы делать рано, после получения результатов на длинной дистанции, возможно, я сделаю обзор в следующих статьях. Пока оставляю только ссылки для самостоятельных исследований. Иллюстрация текущего состояния инфраструктуры
7. Инфраструктура как код (IaC)Краткое описание технологииИ вот мы подобрались к последнему разделу. Обычно, данная технология и связанные с ней задачи не входят в зону ответсвенности инженеров по автоматизации. И на это есть свои причины. Во-первых, во многих организациях инфраструктурные вопросы находятся под контролем DevOps отдела и команды разработки не особо заботятся о том, благодаря чему работает pipeline и каким образом нужно поддерживать все, что с ним связано. Во-вторых, будем честными, практика “Инфраструктура как код (IaC)” все еще не применяется во многих компаниях. Но определенно это стало популярным трендом и важно стараться быть вовлеченным в связанные с этим процессы, подходы и инструменты. Или, по крайней мере, быть в курсе событий. Начнем с мотивации использования данного подхода. Мы уже обсудили, что для запуска тестов в GitlabCI нам понадобятся как минимум ресурсы для запуска Gitlab Runner. А для запуска контейнеров с браузерами/эмуляторами нам нужно зарезервировать VM или кластер. Помимо ресурсов для тестирования, нам необходимо значительное число мощностей для поддержания сред разработки, staging, production, что также включает базы данных, автоматические расписания, конфигурации сети, балансировщик нагрузки, права пользователей и так далее. Ключевая проблема заключается в требуемых усилиях для поддержки этого всего. Есть несколько способов того, как мы можем вносить изменения и выкатывать обновления. Например, в контексте GCP мы можем использовать UI-консоль в браузере и выполнять все действия, кликая кнопки. Альтернативным способом может быть использование API-вызовов для взаимодействия с облачными сущностями или применение утилиты командной сроки gcloud для выполнения нужных манипуляций. Но при действительно большом количестве различных сущностей и инфраструктурных элементов становится тяжело или даже невозможно выполнять все операции вручную. Более того, все эти ручные действия неконтролируемые. Мы не можем отправить их на review перед выполнением, использовать систему контроля версий и быстро откатить правки, которые привели к инциденту. Для решения таких проблем инженеры создавали и создают автоматические bash/shell-скрипты, что ненамного лучше предыдущих способов, так как их не так уж и легко быстро прочесть, понять, поддерживать и модифицировать в процедурном стиле. В этой статье и практическом руководстве я использую 2 инструмента, относящихся к практике IaC. Это Terraform и Ansible. Некоторые полагают, что не имеет смысла использовать их одновременно, так как их функционал схож и они взаимозаменяемые. Но дело в том, что изначально перед ними ставятся совершенно разные задачи. И факт того, что эти инструменты должны дополнять друг друга, был подтвержден на совместной презентации разработчиками, представляющими компании HashiCorp и RedHat. Концептуальная разница заключается в том, что Terraform – это provisioning-инструмент для управления самими серверами. В то время как Ansible является инструментом управления конфигурациями, задачей которого является установка, настройка и управление софтом на этих серверах. Еще одной ключевой отличительной особенностью данных инструментов является стиль написания кода. В отличие от bash и Ansible, Terraform используют декларативный стиль, основанный на описании желаемого конечного состояния, которого необходимо достичь в результате выполнения. Например, если мы собираемся создать 10 VMs и применить изменения через Terraform, то мы получим 10 VMs. Если применить скрипт еще раз, ничего не произойдет, так как у нас уже есть 10 VMs, и Terraform знает об этом, поскольку он хранит текущее состояние инфраструктуры в state-файле. А вот Ansible использует процедурный подход и, если попросить его создать 10 VMs, то на первом запуске мы получим 10 VMs, аналогично с Terraform. Но после повторного запуска у нас уже будет 20 VMs. В этом и заключается важное отличие. В процедурном стиле мы не храним текущее состояние и просто описываем последовательность шагов, которые должны быть выполнены. Разумеется, мы можем обработать различные ситуации, добавить несколько проверок на существование ресурсов и текущее состояние, но нет смысла тратить наше время и прикладывать усилия на контролирование данной логики. К тому же это увеличивает риск совершить ошибки. Обобщив все выше сказанное, можно сделать вывод, что для provisioning серверов более подходящим инструментом является Terraform и декларативная нотация. А вот работу по управлению конфигурациями лучше делегировать на Ansible. Разобравшись с этим, давайте посмотрим на примеры использования в контексте автоматизации. Ценность для инфраструктуры автоматизацииЗдесь важно понимать лишь то, что инфраструктура автоматизации тестирования должна рассматриваться как часть всей инфраструктуры компании. А это значит, что все IaC-практики должны быть применены глобально к ресурсам всей организации. Кто за это ответственен, зависит от ваших процессов. DevOps-команда более опытна в данных вопросах, они видят всю картину происходящего. Однако QA-инженеры сильнее вовлечены в процесс построения автоматизации и структуру pipeline, что позволяет им лучше видеть все требуемые изменения и возможности для улучшения. Самый лучший вариант – это работать сообща, обмениваться знаниями и идеями для достижения ожидаемого результата. Приведу несколько примеров использования Terraform и Ansible в контексте автоматизации тестирования и инструментов, которые мы обсуждали до этого:
Иллюстрация текущего состояния инфраструктуры
Подведем итоги!
Что дальше?Итак, это конец статьи. Но в заключении я бы хотел установить с вами некоторые договоренности С вашей стороны Как было сказано вначале, я бы хотел, чтобы статья несла практическую пользу и помогла вам применить полученные знания в реальной работе. Добавляю еще раз ссылку на практическое руководство. Но даже после этого не останавливайтесь, практикуйтесь, изучайте соответствующие ссылки и книжки, узнавайте, как это работает у вас в компании, находите места, которые можно улучшить и принимайте в этом участие. Удачи С моей стороны Из заголовка видно, что это была только первая часть. Несмотря на то, что она получилось довольно большой, здесь все еще не раскрыты важные темы. Во второй части я планирую рассмотреть инфраструктуру автоматизации в контексте IOS. Из-за ограничений Apple, связанных с запусками IOS симуляторов только на macOS системах, наш набор решений сужен. Например, мы лишены возможности использовать Docker для запуска симулятора или публичных облаков для запуска виртуальных машин. Но это не означает, что нет других альтернатив. Я постараюсь держать вас в курсе передовых решений и современных инструментов! Также я не упомянул довольно большие темы, связанные с мониторингом. В части 3 я собираюсь рассмотреть наиболее популярные инструменты для мониторинга инфраструктуры, а также какие данные и метрики стоит принять во внимание. И напоследок. В будущем я планирую выпустить видео курс по построению тестовой инфраструктуры и популярным инструментам. В настоящее время в интернете довольно много курсов и лекций по DevOps, но все материалы представлены в контексте разработки, но не автоматизации тестирования. В этом вопросе мне очень нужна обратная связь, будет ли такой курс интересен и ценен для сообщества тестировщиков и автоматизаторов. Заранее спасибо! polls |