Что пишут в блогах
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Python для начинающихНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Азбука ИТНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
| Инфраструктура + тестирование = любовь |
| 20.04.2022 00:00 |
|
Автор: Максим Буранбаев, Этот e-mail адрес защищен от спам-ботов, для его просмотра у Вас должен быть включен Javascript Инфраструктура тестирования обсуждается реже чем проблемы программирования или шестизначные зарплаты. Дьявол кроется в деталях, а если точнее, то дьявол сидит в процессах внутри команды. В небольших командах процессы устраиваются сами собой без обсуждения. Продуктивность команды снижается по мере роста команды и в условиях игнорирования процессов. Статью будет полезно прочитать, если команда испытывает следующие трудности:
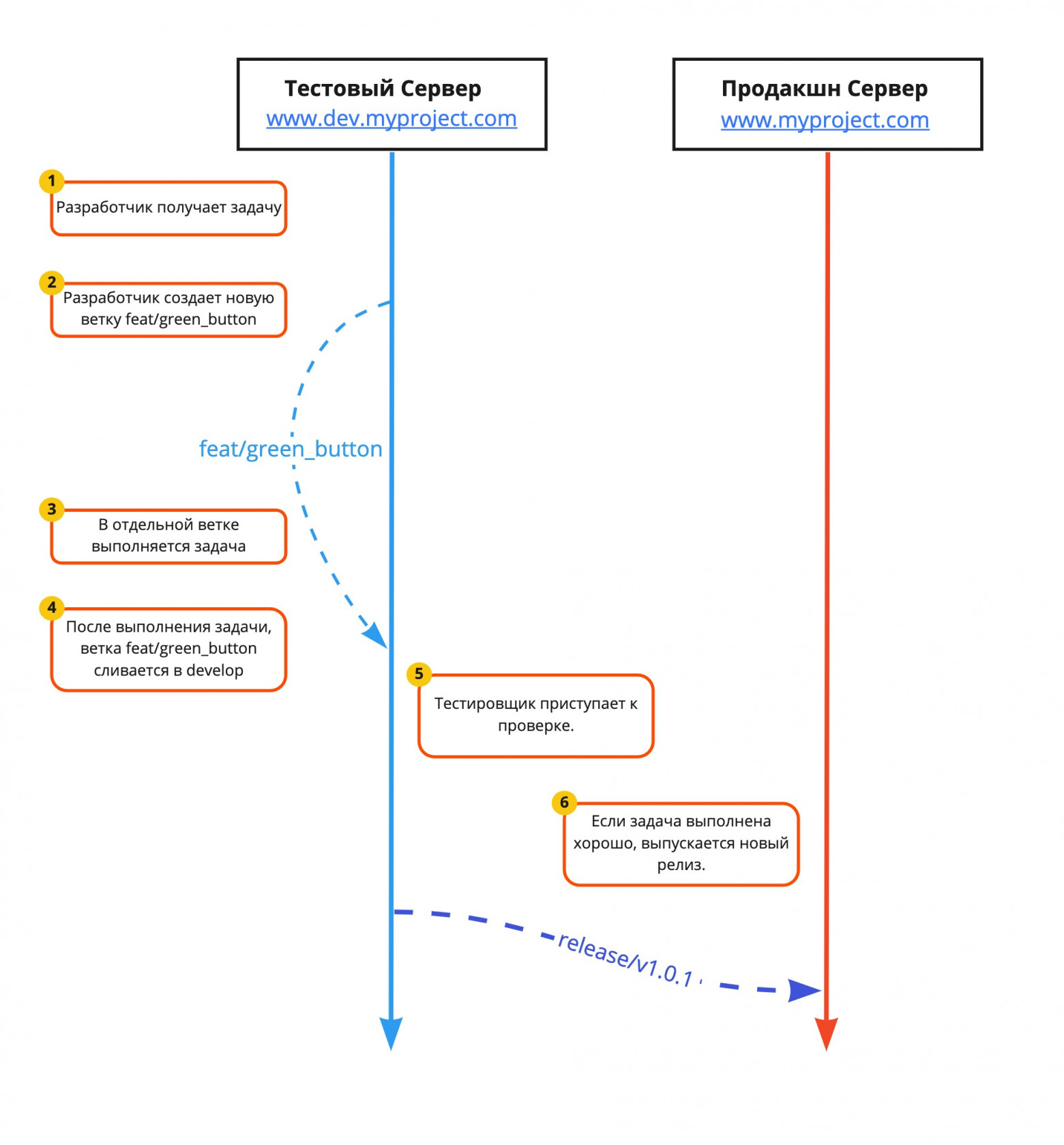
ПроцессКлассический процесс в микрокоманде на ранних этапах выглядит следующим образом:
Шаги с первого по четвертый не стоят обсуждения, сразу перейдем к шагу номер пять. Чаще в микрокомандах тестировщик не разворачивает проект локально и не переключается на нужную ветку. Тестирование проходит на тестовом сервере, который соответствует ветке develop. Процесс выстроен логично, но давайте пофантазируем насчет ожидаемых проблем. Если задача сложная и цикл тестирования и внесения изменений продолжительный, то такая задача тормозит остальные задачи и разработчики либо сделает релиз гораздо позже, либо будут мерджить небольшие задачи напрямую в ветку master.
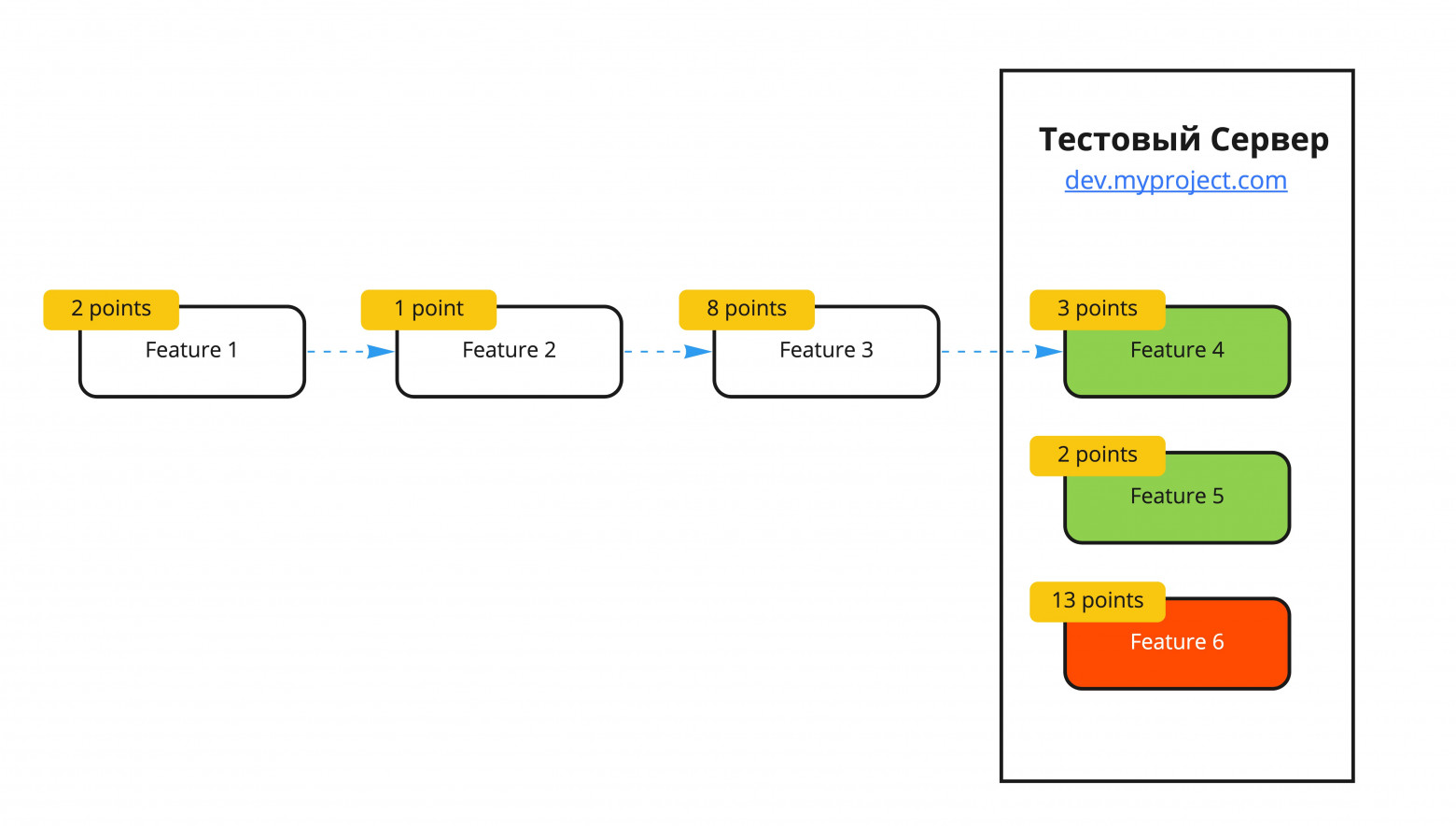
Получается нечто вроде конвейера, если на ленте (dev-server) застряла Feature 6, это блокирует конвейер и предприятие останавливается. Согласно теории ограничений, это классическое бутылочное горлышко. Выпуск релиза будет отложен ровно на столько, сколько требуется на исправление проблем в Feature 6. Если однажды Feature 6 попала в ветку develop, остальные задачи (Feature 4, Feature 5) будут ожидать исправления ошибок в Feature 6. При таком подходе, трудно делать релизы вовремя, будут задачи, которые блокируют релиз. Если внимательно посмотреть на схему, очевидное решение – сливать в ветку develop только готовые задачи, для этого код должен быть протестирован. Для тестировщика или менеджера затруднительно разворачивать локально проект и переключаться с одной ветки на другую. Следовательно, для каждой разрабатываемой задачи необходим собственный сервер с публичным доступом. Попробуем!
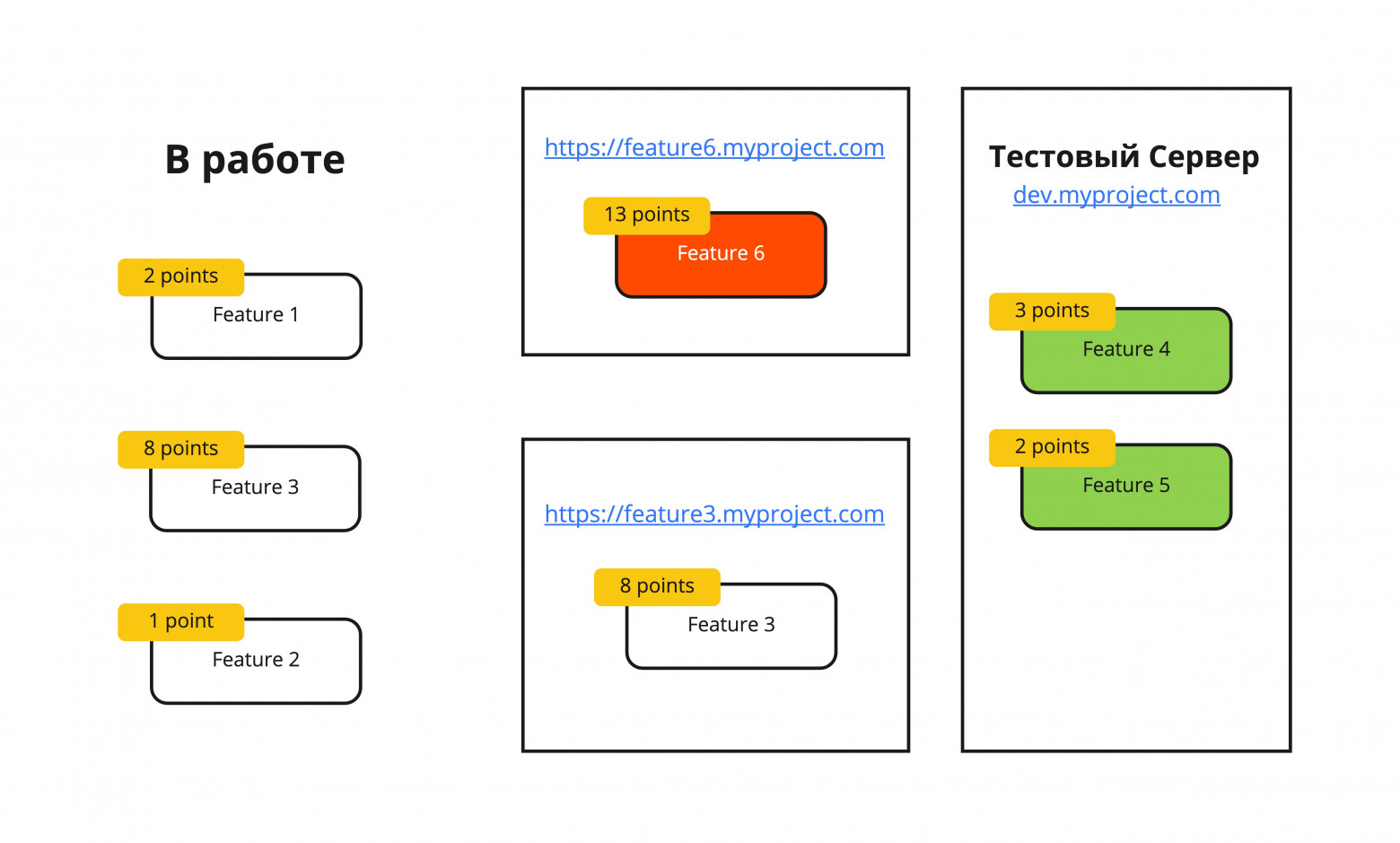
Теперь, разработчик для каждой задачи или состояния проекта имеет свой собственный домен и может отправить его тестировщику. При этом, если в коде есть какие-то проблемы, это не заблокирует релиз, так как проблемный код еще не попал в develop ветку. Значит, мы в любой момент времени можем готовить релиз, на тестовом сервере только готовые задачи. Вроде бы на этом можно и закончить, но каждый раз для каждой задачи даже разработчику или девопсу трудно разворачивать новое состояние приложения. РеализацияДля того чтобы погрузиться в техническую реализацию, предлагаю добавить некоторые детали к проекту. Предположим, у нас обычное веб-приложение, например на next.js. Пришла задача от дизайнера поменять цвет кнопки "Купить" на красный. Разработчик добросовестно выполнил задачу и теперь хочет показать красную кнопку тестировщику. Прежде чем разбираться, как это сделать, стоит сформулировать критерии выполнения задачи:
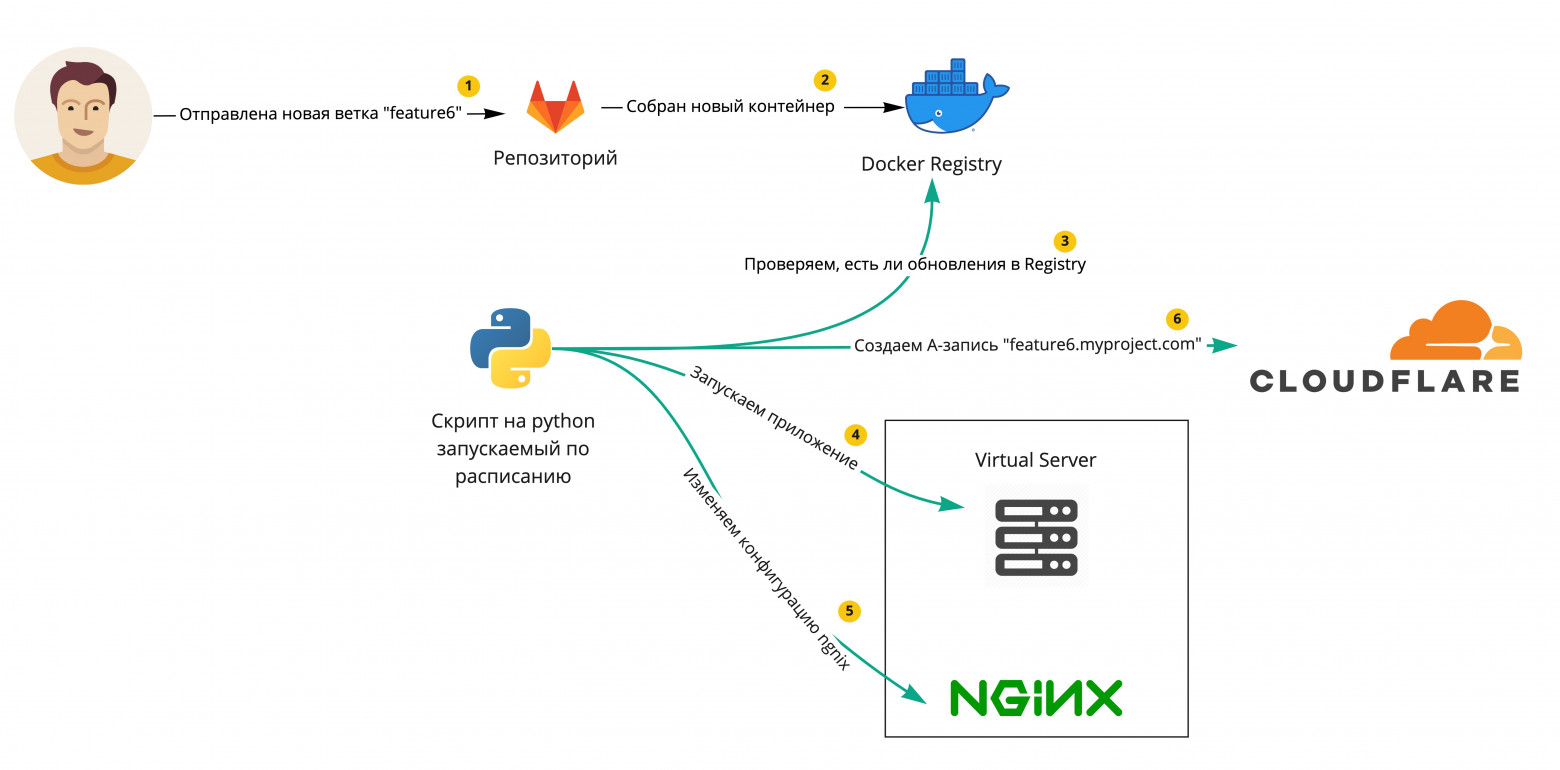
Попробуем схематично изобразить решение.
Выглядит просто, как рецепт приготовления макарон. Теперь по шагам помеченным на схеме цифрами в желтом круге.
Приведу псевдокод, показывающий алгоритм. РезультатМы избавились от бутылочного горлышка в процессе разработки и сделали жизнь разработчиков чуточку лучше. Бонусом, можно подключить уведомления в телеграмме, слеке или бейскемпе или даже прикреплять ссылку автоматически в jira. Эта логика также будет размещена в python-скрипте. Сегодня мы рассмотрели простой пример, в следующей статье рассмотрим ситуацию, в которой у нас более сложная архитектура приложения с бекендом, фронтом и админкой. |