



Меня зовут Владислав Романенко, я Senior iOS QA Engineer в Badoo и Bumble. Мы регулярно внедряем новые фичи в приложения, и автоматизация тестирования — один из способов не пропустить баги. Фактически автотесты входят в жизненный цикл всех частей наших приложений: бэкенда, сервисов, фронтенда и мобильных клиентов. Чем раньше мы обнаружим ошибку, тем дешевле будет её исправить.
Сегодня я расскажу об автоматизации тестирования в iOS, потому что на протяжении всей своей карьеры в Badoo я плотно занимался тестированием наших нативных iOS-приложений, которые написаны на Objective-C и Swift. Хотя кое-где я буду упоминать характерные для iOS инструменты и термины (например, XCTest), общие принципы и подходы универсальны. Так что, даже если в вашем проекте используется совсем другой стек, статья будет вам полезна.
Что такое пирамида тестов?
Пирамида тестов — это абстракция, которая отражает группировку тестов программного обеспечения по разным уровням детализации. Также она характеризует относительное количество тестов в каждой группе.
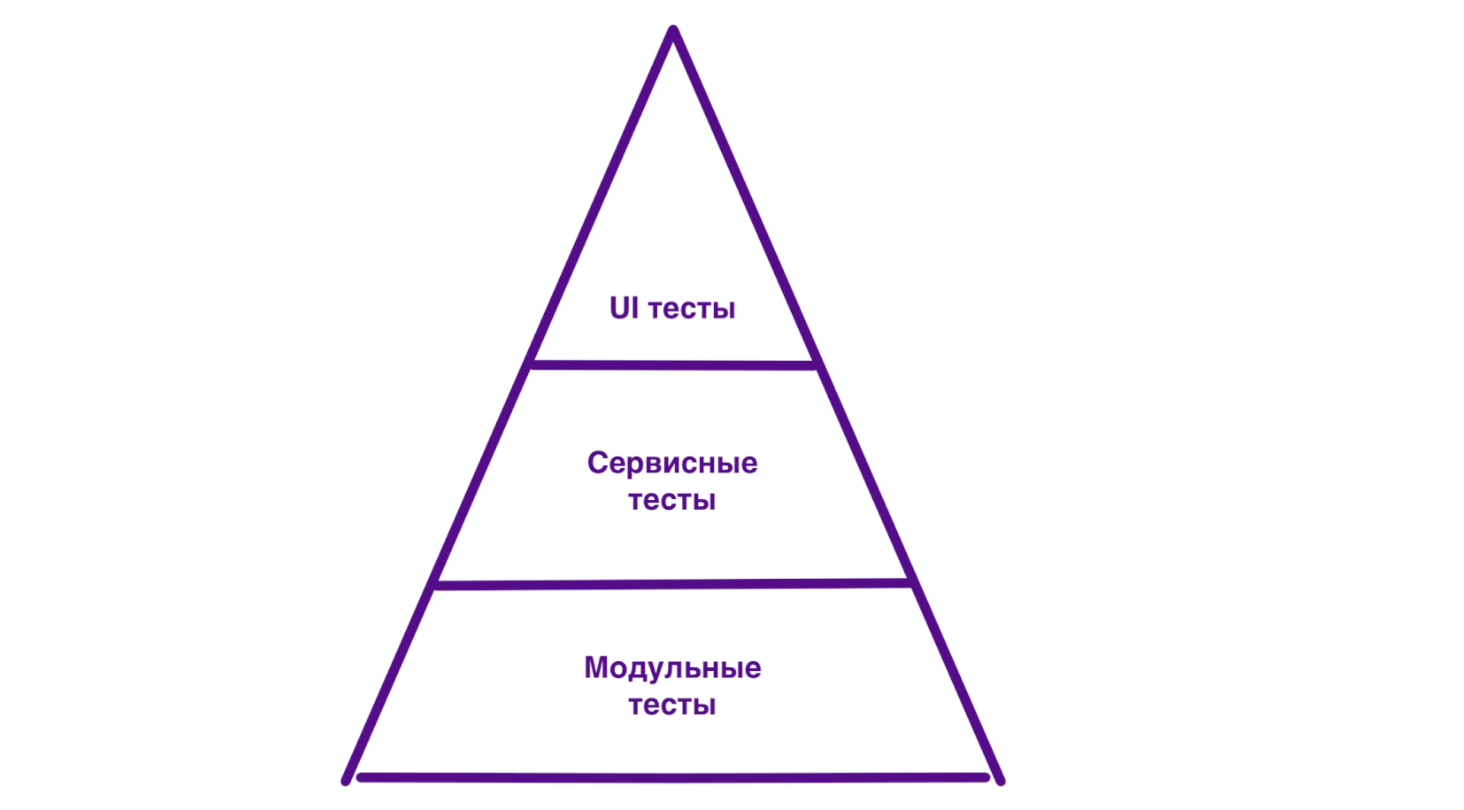
Так выглядит исходная пирамида тестов Майка Кона. Она состоит из трёх уровней: модульных тестов, сервисных тестов и тестов пользовательского интерфейса (UI). Вне зависимости от выбранных вами названий и гранулярности пирамида иллюстрирует два тезиса:
Тесты нужны на каждом из уровней пирамиды;
Чем выше вы поднимаетесь по пирамиде, тем меньше тестов вам требуется.
Иными словами:
пишите много маленьких и быстрых модульных тестов;
пишите поменьше тестов среднего уровня;
пишите совсем немного высокоуровневых сквозных тестов.
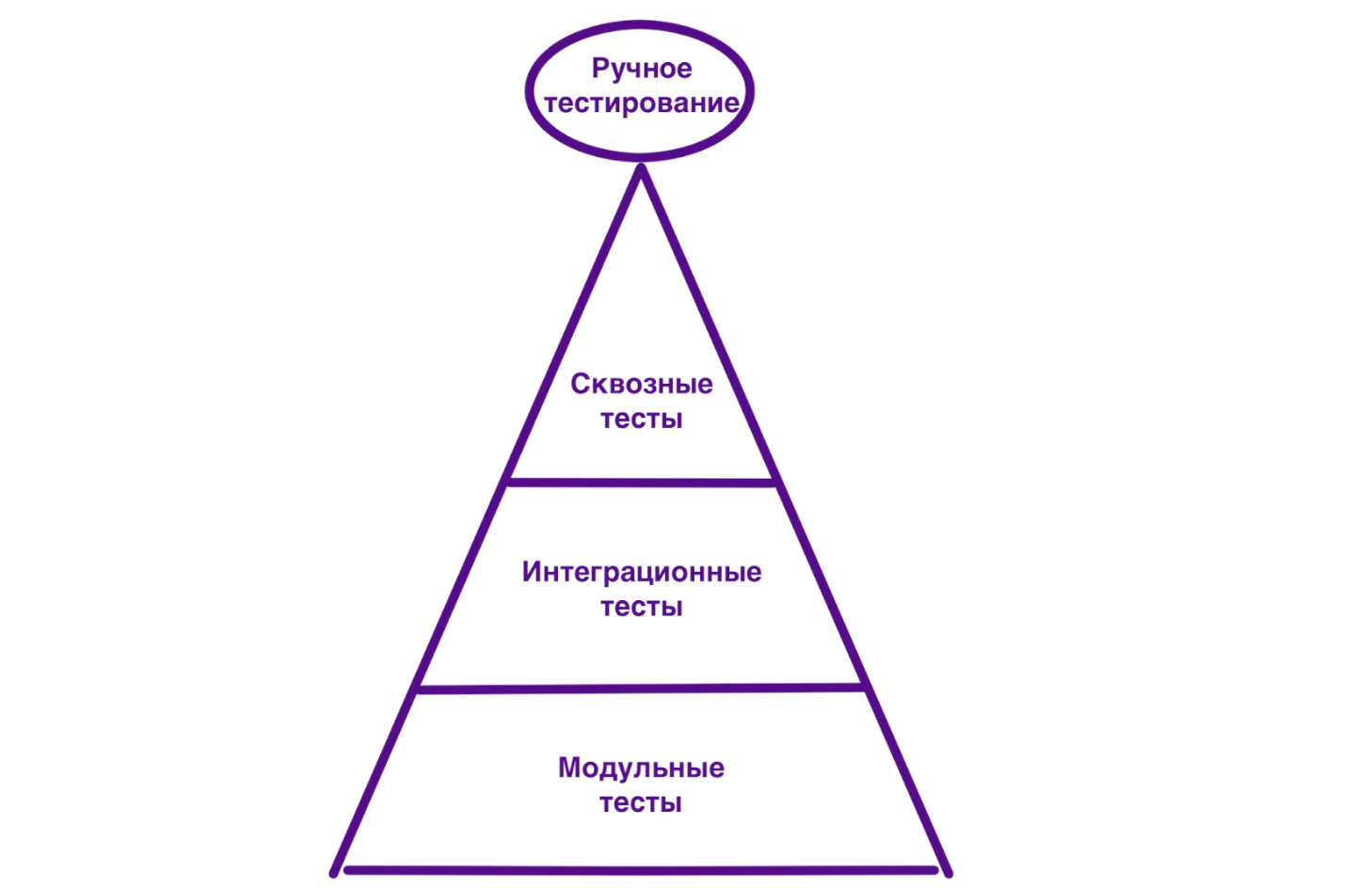
Количество уровней и их названия могут быть разными. Самая распространённая модель включает четыре категории тестов (сверху вниз): ручное тестирование, сквозные (end-to-end) тесты, интеграционные тесты, модульные тесты. Следовательно, пирамида в этом случае будет выглядеть так:
<
Все мы стремимся к идеалу и хотим иметь идеальную пирамиду тестов. Но по мере роста проекта ее форма часто меняется, становясь больше похожей на мороженое:
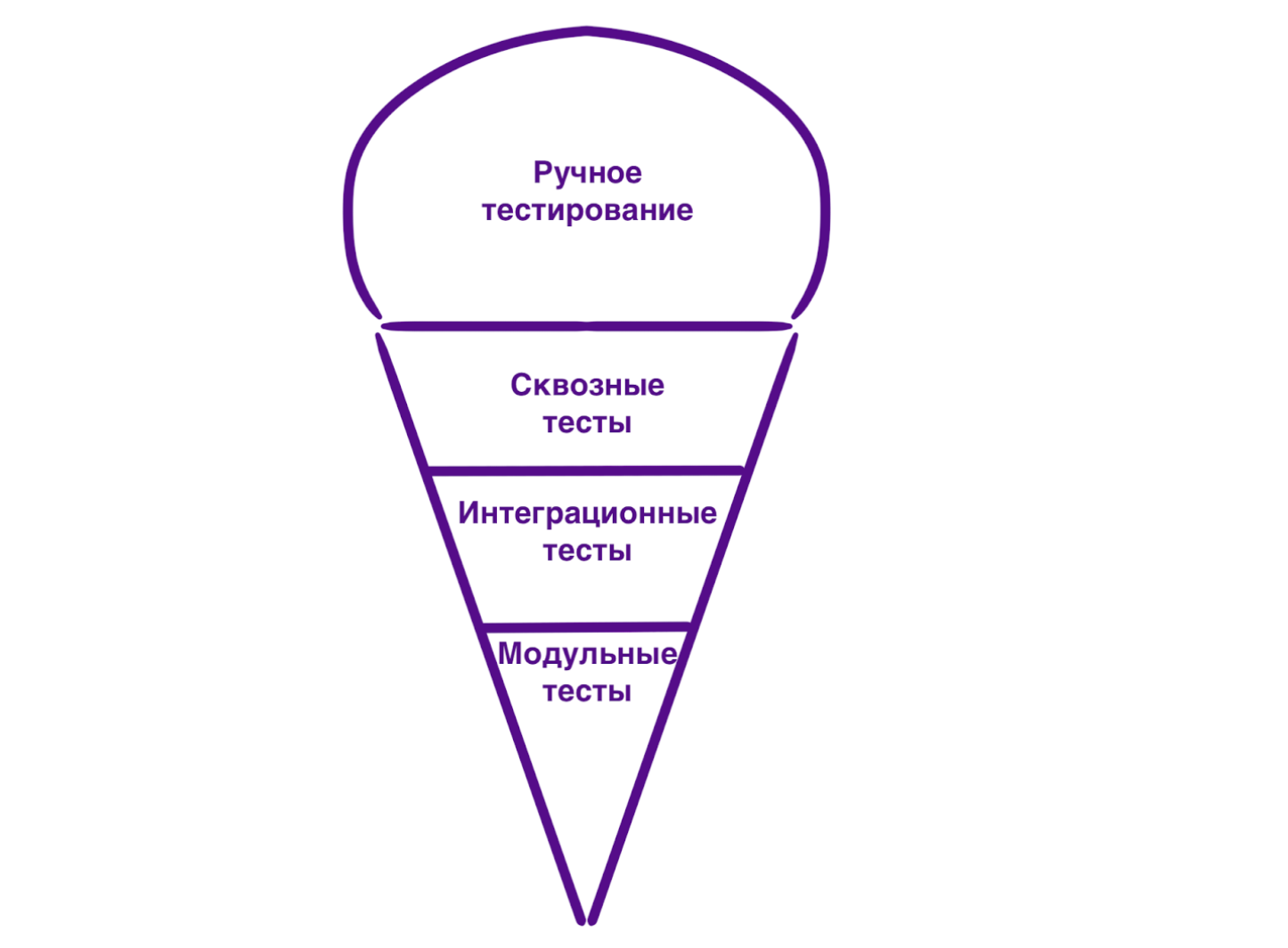
Такое случается при недостатке низкоуровневых тестов (модульных, интеграционных и компонентных), при избытке тестов, запускаемых через UI, и при ещё большем количестве ручного тестирования (в чуть более благоприятном варианте — сквозных).
Чаще всего это происходит, когда над проектом работают несколько разных команд, возможно, изолированных друг от друга, и они добавляют тесты на разные уровни пирамиды. Например, разработчики пишут модульные и интеграционные тесты независимо от QA-инженеров, которые пишут сквозные тесты. Это приводит не только к неправильному распределению тестов по уровням пирамиды (потому что некоторые сценарии автоматизируются на нескольких разных уровнях), но ещё и к дублированию действий.
Уровни iOS-тестирования в Badoo и Bumble
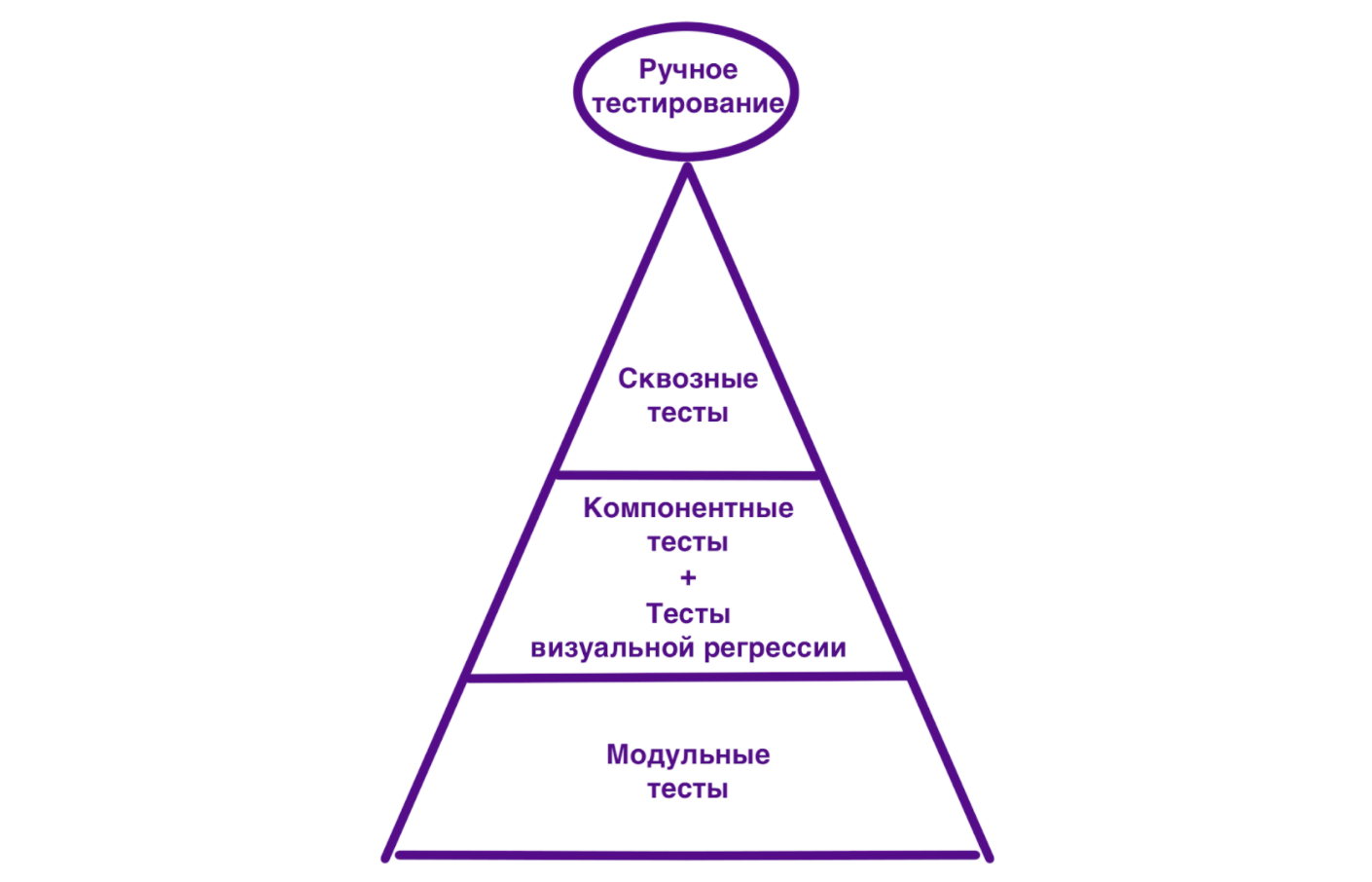
Мы применяем для тестирования iOS-приложений следующие тесты (сверху вниз):
Ручное тестирование. Мы используем его для небольшого количества сценариев и активно автоматизируем часто повторяющиеся и утомительные задачи. Но всё же ручное тестирование у нас присутствует. Например, при внедрении новой фичи (конечно же, покрытой автотестами) разработчики и QA-инженеры проводят так называемую «часовую QA-сессию», в ходе которой мы хотим убедиться, что фича реализована в соответствии с требованиями и готова к запуску. Более того, поскольку мы релизим приложения каждую неделю, перед выкаткой билда мы проводим ручное тестирование — проверяем самую важную функциональность, тестирование которой невозможно автоматизировать, или которая требует дополнительного внимания. Наконец, у нас есть разные активности вроде Testing Dojo, которые предполагают коллективное тестирование приложений многими людьми из разных команд.
Сквозные тесты. Это тесты типа «чёрный ящик», написанные нашими QA-инженерами. Эти тесты фокусируются на клиентской интеграции с другими сервисами и инфраструктурой. Мы используем кросс-платформенный фреймворк автоматизации тестирования Calabash. Эти тесты написаны на Ruby и используют синтаксис Cucumber и Gherkin. В своей предыдущей статье я приоткрыл завесу над некоторыми паттернами процессов, которые мы используем при создании сквозных тестов. Чтобы продемонстрировать наш фреймворк, мы даже опубликовали пример проекта. Также у нас есть набор тестов для разных девайсов и языков, которые проходят по всему приложению и делают скриншот каждого экрана. Мы называем эти тесты liveshots, о них подробно рассказано здесь.
Компонентные и интеграционные тесты. Это особые виды тестов типа «чёрный ящик». Проверяемые с их помощью сценарии зависят от спецификаций функциональных компонентов и их интеграции друг с другом и с iOS-сервисами. Эти тесты должны быть изолированы от остальных систем приложения. Они написаны на Swift (как и другие тесты на нижерасположенных уровнях пирамиды) и используют встроенный фреймворк XCTest. Мы ещё к ним вернёмся. В этой статье я объединил оба вида в одну категорию — компонентные тесты. Сделано это с одной стороны для простоты, с другой - потому что сейчас все эти тесты мы не разделяем. А в будущем мы планируем перенести компонентные тесты в специальные функциональные модули.
Тесты визуальной регрессии. Они проверяют, соответствует ли дизайн пользовательского интерфейса требованиям, и корректно ли интегрируются компоненты интерфейса с соответствующей подсистемой ОС. Часто такие тесты называют snapshot-тестами.
Модульные тесты. Они позволяют убедиться, что модуль соответствует своей архитектуре и ведёт себя как предписано. Часто модулем является целый интерфейс, например класс, но им может быть и отдельный метод. Такие тесты должны гарантировать проверку всех нестандартных путей кода (включая успешные и пограничные случаи).
Я уже говорил, что для ситуаций, когда тестовая пирамида напомнает форму мороженого характерен недостаток тестов на нижних уровнях (модульные тесты). А если отсутствуют тесты среднего уровня (интеграционные), то пирамида превращается в песочные часы. Собственно, такова сейчас структура наших тестов:
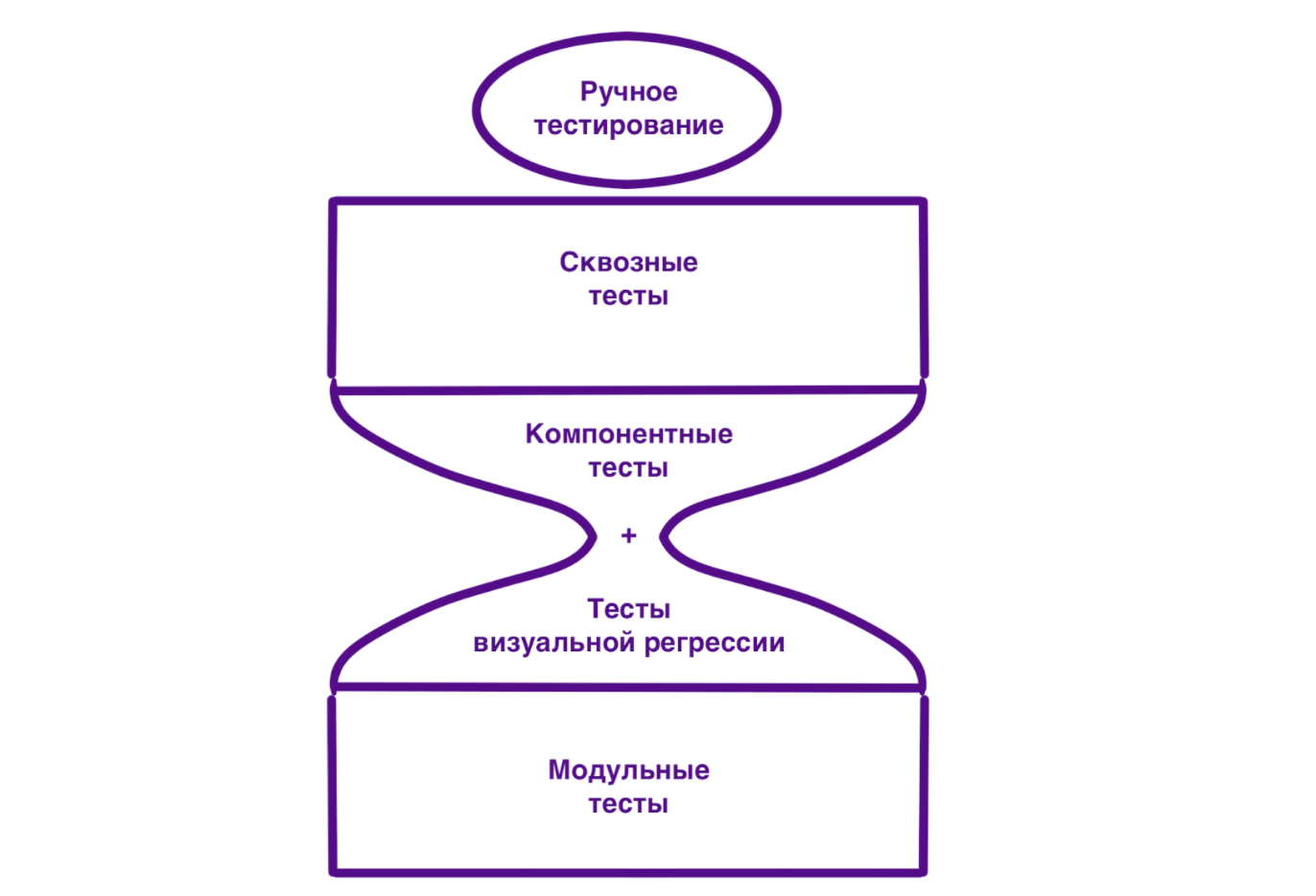
В такой структуре много сквозных и модульных тестов, но мало интеграционных. Это не так плохо, как в случае с формой мороженого, но всё ещё приводит к слишком большому количеству падений сквозных тестов. В то же время, обнаружить баги приложения, которые приводят к падениям этих тестов, было бы быстрее и проще с помощью среднеуровневых тестов. Более того, сквозные тесты обычно медленные, ненадёжные и сложные. К сожалению, избежать их сложности и недетерминированности невозможно. Мартин Фаулер считает, что главные причины этого - недостаток изолированности, асинхронное поведение, удалённые сервисы, утечки ресурсов.
Мой коллега недавно опубликовал серию статей, в которых рассказал о том, как мы улучшаем наши сквозные тесты: часть 1, часть 2.
Создаём тестовую пирамиду
Итак, нам нужно превратить песочные часы в пирамиду. Мы понимаем, что нам нужны тесты на всех уровнях, но при этом должны иметь больше тестов на более низких уровнях, поскольку они позволяют быстро и эффективно диагностировать проблемы.
Для нас, оптимальное соотношение тестов определяется по двум главным критериям: инженерной продуктивности и уверенности в продукте. Сосредоточившись на низкоуровневых тестах, мы быстро обретём уверенность на ранних стадиях разработки. С другой стороны, по мере развития продукта более высокоуровневые тесты будут выступать тестами работоспособности (sanity tests). Но их нельзя считать главным инструментом для поиска багов.
Вам может потребоваться другое соотношение. Но если вы сосредоточитесь на интеграционном тестировании, то может оказаться, что тесты выполняются дольше, но находят больше проблем во взаимодействии компонентов. Сосредоточитесь на модульных тестах — ваши тесты наверняка будут выполняться очень быстро и находить много распространённых логических багов. Однако модульные тесты не смогут проверить взаимодействие компонентов, например, контракт между двумя системами разрабатываемыми разными командами. Поэтому хороший тестовый набор содержит тесты разных размеров и типов, соответствующие локальным архитектурным и организационным условиям.
Нельзя за день получить желаемую структуру тестовой пирамиды — это долгий процесс. При изменении нашей пирамиды мы следуем таким принципам:
Покрытие тестами и уровни пирамиды нужно обсуждать на стадии планирования. Как только новая фича приложения готова к разработке, для неё назначают QA-инженеров. Они вместе с разработчиками и другими командами активно участвуют в организации начала работ. После этого QA-специалисты проверяют всю документацию и вместе с разработчиками принимаются прорабатывать разные тестовые сценарии. На этом этапе все участники обсуждают и вырабатывают на будущее тестовое покрытие. И только после завершения всех этих процедур мы начинаем писать код и можем запускать тесты.
У тестов может быть разная гранулярность, но они всегда должны быть полезны. Помните: чем выше уровень тестов, тем меньше их должно быть. Поэтому мы стараемся опустить тесты в пирамиде как можно ниже. Примечание: если более высокоуровневый тест даст вам больше уверенности в корректной работе приложения, то добавляйте его; в противном случае лучше сосредоточиться на нижних уровнях.
Обращаться с кодом автотестов нужно как с кодом тестируемого приложения. Необходимо уделять коду автотестов столько же внимания, сколько коду приложения, иначе можно получить кодовую базу тестов, которую невозможно поддерживать. Она не будет особо помогать и потребует много усилий для работы с ней.
Пишем низкоуровневые тесты
Поскольку я QA-инженер, мне чаще приходится иметь дело с руынм тестированием и высокоуровневыми сквозными тестами. Большая часть моего рабочего времени уходит на вещи вроде добавления тестов для поддержки новой функции приложения или перепроверки отчёта о непростом баге.
В ходе разработки новой фичи мы обсуждаем и проверяем тесты со всех уровней. Для любой фичи мы обязательно составляем план тестирования. Этот процесс предваряет фазу активной разработки и подразумевает создание «набросков» предполагаемых тестов. Также на этом этапе QA-инженеры могут попросить разработчиков проверить, у всех ли добавленных элементов есть идентификаторы для использования в сквозных тестах, или запросить необходимые вспомогательные инструменты (мы называем их QAAPI-методами, почитать о них можно здесь).
Хоть я и участвую в таких обсуждениях, однако никогда не чувствовал себя полностью вовлечённым ни в планирование или разработку низкоуровневых тестов, ни, что ещё важнее, в аргументирование перемещения тестов с верхних уровней вниз (для поддержания формы пирамиды). Мне хотелось этого не только из-за природного любопытства. Как и многие из нас, я знал, что если сосредоточиться на обширном наборе сквозных тестов, то можно проиграть в длительности тестирования, скорости получения обратной связи и эффективности результатов. То есть упустить все преимущества низкоуровневых тестов.
Чтобы представить себе это в перспективе, сегодня для приложения Bumble на iOS у нас около 900 сквозных сценариев в различных наборах тестов. Подавляющее большинство из них выполняется на симуляторах параллельно (насколько это возможно) и относительно быстро. Последние измерения показывают, что в среднем выполнение сквозного теста на симуляторе iOS занимает от 30 до 90 секунд (включая настройку и удаление). Следовательно, выполнение полного набора тестов займёт 20—30 минут. Кроме того, мы делаем тестовые запуски и на реальных iOS-устройствах. Это другое подмножество тестов, которые нельзя перенести в симулятор, потому что им, например, нужна физическая камера или какие-то разрешения. Такие прогоны занимают около 12 минут при средней продолжительности теста в две минуты. Обратите внимание, что, к счастью, мы не запускаем все эти конфигурации для каждого изменения в приложении. Мы внедрили специальную логику, которая выбирает для изменённых модулей и функций только подходящие тесты. Однако если мы спустимся по пирамиде вниз, от сквозных к более низкоуровневым тестам, то скорость и частота запусков вырастут, а объём ручного контроля уменьшится. Что касается длительности выполнения, то, забегая вперёд, скажу, что в разных конфигурациях запуск сценария компонентного тестирования занимает в среднем 12—15 секунд.
В прошлом году в компании ввели новую инициативу — “Focus Fridays”. Эта программа создана для того, чтобы дать сотрудникам передышку от таких особенностей удалённой работы, как многочисленные видеозвонки, письма и сообщения. Она позволяет выделять две пятницы в месяце на то, чтобы подумать, расслабиться и поработать без отвлекающих факторов. Я решил посвятить это время углублению в компонентное тестирование.
Переносим сквозные тесты на компонентный уровень
Компонентными называют приёмочные тесты, которые проверяют пользовательский опыт посредством взаимодействия с графическим интерфейсом. Они зависят от возможностей UI-тестирования фреймворка Apple XCTest. Приложение проверяется как чёрный ящик, а для всех внешних взаимодействий, например доступа по сети или пуш-уведомлений, используются заглушки или симуляции.
Сейчас мы работаем так:
Во время написания теста, мы прогоняем его на реальном сервере, взаимодействия с которым записываем и сохраняем;
после добавления в приложение новой функции прогоняем все тесты только в режиме воспроизведения. Если позже нужно внести изменения в тест, приходится перезаписывать его взаимодействия.
Прежде чем выбрать этот подход, хорошенько обдумайте все его достоинства и недостатки.
Трудности, с которыми мы сталкиваемся при компонентном тестировании, и наши подходы к избавлению от недетерминированности — темы для отдельной статьи. Скажу лишь, что мы придерживаемся политики нулевой терпимости к недетерминированности в компонентных тестах (а для приложения Bumble на iOS у нас их около 300).
Стоит отметить, что наши тесты компонентов не покрывают:
внешние по отношению к iOS компоненты, такие как сеть, сервер и службы Apple Push Notification (APNs), — их мы проверяем с помощью сквозных тестов;
дизайн пользовательского интерфейса, макет и внешний вид приложения — их мы проверяем с помощью тестов визуальной регрессии;
логику, определённую в наборе классов без пользовательского интерфейса или единственном классе, — её мы проверяем с помощью модульных тестов.
Для всех новых функций приложения мы сразу же добавляем компонентные тесты. Однако у нас ещё остаются сквозные тесты, которые можно перенести на нижние уровни пирамиды. Мы провели анализ и нашли подходящие для этого сценарии.
Вот два примера сквозных сценариев, которые можно перенести ниже в тестовой пирамиде и которые не требуют внешних зависимостей и взаимодействия с сервером:
Scenario: Cancelling Photo Upload doesn't upload any photos
Given new user with following parameters
| role | photos_count |
| primary_user | 0 |
And primary_user logs in
When primary_user goes to Own Profile
Then primary_user verifies Own Profile with NO photo
When primary_user taps on Add Photo on Own Profile page
And primary_user goes back from Add Photo page
Then primary_user verifies own profile with NO photoScenario: "Clear folders" warns user about consequences and can be cancelled
Given new user with following parameters
| role | photos_count |
| primary_user | 1 |
And primary_user goes to own profile
And primary_user taps on Account section
And primary_user taps on Delete account from Account screen
When primary_user selects 'Clear folders'
Then primary_user verifies the 'Clear folders' warning dialogue
When primary_user cancels clearing folders for account
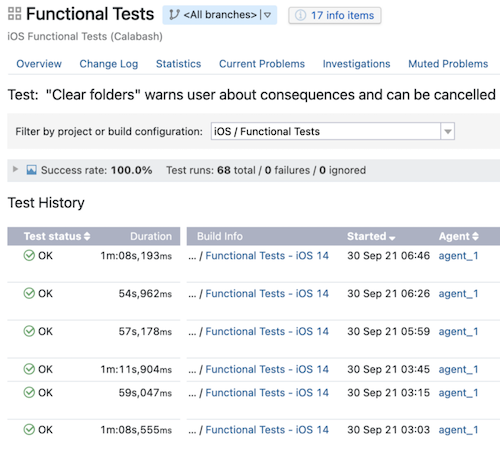
Then primary_user verifies the Delete Account, Are You Sure screen?В основном они сохранят ту же идею, структуру и набор шагов. Изменятся только особенности реализации, язык и фреймворк. Возьмём второй пример и посмотрим, как такая смена уровня влияет на длительность тестирования. У исходных сквозных тестов для наших агентов непрерывной интеграционной сборки средняя продолжительность составляет около минуты:
После переноса сценария средняя длительность выполнения стала меньше 15 секунд:
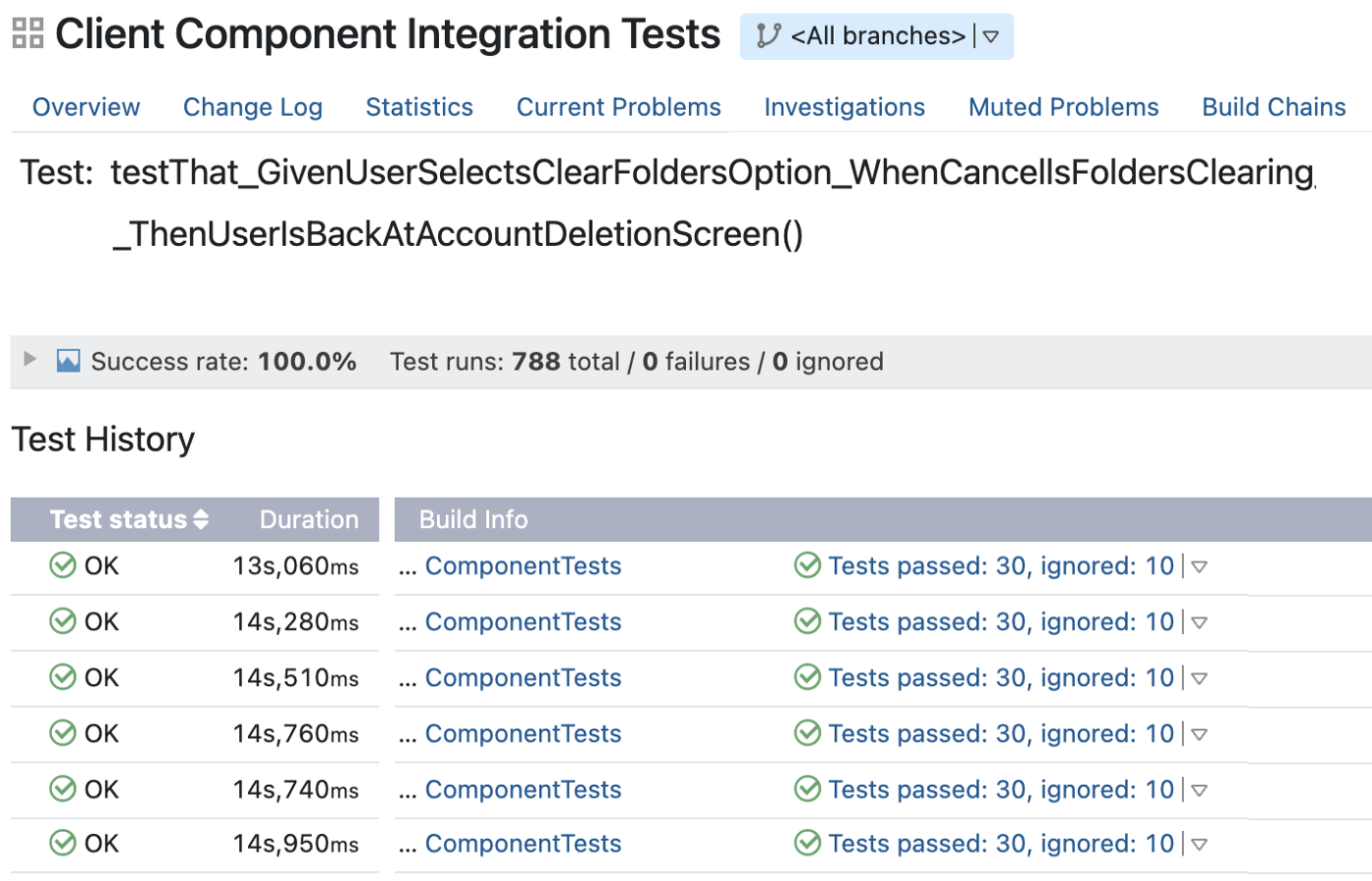
Помимо заметного ускорения тестов, нужно отметить и повышение стабильности благодаря улучшению изоляции за счёт вышеупомянутых заглушек для серверных и сетевых взаимодействий.
Заключение
Мы пишем тесты разных типов, чтобы убедиться в том, что приложение функционирует как нужно. Неважно, над каким приложением вы работаете, — при оптимизации покрытия лучше всегда стремиться к поддержанию правильной формы тестовой пирамиды. Но необходимо, чтобы все в команде это понимали и разделяли такой подход. Учитывая тестовую пирамиду, вы должны подумать о том, куда направить свои усилия: хотя сквозные тесты очень важны, они также самые дорогие в написании и поддержке, а ещё самые медленные. Очень важно обсуждать план тестирования до начала разработки функциональности.
Мы всё ещё активно улучшаем тестовое покрытие и добавляем тесты на все уровни пирамиды. Наша главная цель — разместить нужные тесты на нужных уровнях. Мы обсуждаем миграцию имеющихся сценариев на два или даже на три уровня вниз. Вполне может случиться так, что однажды после переработки сквозной сценарий попадёт в набор тестов визуальной регрессии. Или компонентный тест может быть заменён модульным.
Самостоятельно погрузившись в компонентное тестирование, я прочувствовал его особенности. Кроме того, я гораздо больше узнал о возможностях, устройстве и ограничениях фреймворка XCTest. Теперь я лучше понимаю нашу систему компонентных тестов и могу поделиться своими знаниями с QA-командой.
Надеюсь, это поможет нам эффективнее планировать тестовое покрытие, а также будет полезно в обслуживании, поддержке и миграции тестов.