


Что пишут в блогах
- Почему без реальных пользователей вы тестируете не продукт, а иллюзию?
- QA-агенты. Автономные системы меняют экономику тестирования
- 1 тест = 1 проверка. Чем хорош принцип атомарности в автотестах в Postman
- DevOps не едет? 4 системных затыка в delivery и как QA возвращает ему скорость
- Новый функционал? Подождем до последнего. Как банки к АУСН подключались
- Хочешь ещё быстрее?
- Какие метрики в тестировании в 2026 году действительно влияют на релиз и бизнес
- ИИ в тестировании: экзоскелет для инженера или быстрый способ слить бюджет?
- Мы незаметно перескочили странную границу
- Бережливый 2026, или как баги снижают продажи

Что пишут в блогах (EN)
- AI and Testing: Improving Retrieval Quality, Part 3
- AI and Testing: Improving Retrieval Quality, Part 2
- AI and Testing: Improving Retrieval Quality, Part 1
- Requirements lead into worse testing?
- AI and Testing: Contextual Precision
- Benchmarking results - Human, Human with AI, AI with Human and where we land
- AI and Testing: Faithfulness
- So, You “10x’d” Your Work…
- AI and Testing: Answer Relevancy
- AI and Testing: Evaluation and DeepEval
Онлайн-тренинги
-
Chrome DevTools: Инструменты тестировщикаНачало: 12 марта 2026
-
SQL: Инструменты тестировщикаНачало: 12 марта 2026
-
Git: инструменты тестировщикаНачало: 12 марта 2026
-
Азбука ИТНачало: 12 марта 2026
-
Bash: инструменты тестировщикаНачало: 12 марта 2026
-
Регулярные выражения в тестированииНачало: 12 марта 2026
-
Python для начинающихНачало: 12 марта 2026
-
Школа для начинающих тестировщиковНачало: 12 марта 2026
-
Docker: инструменты тестировщикаНачало: 12 марта 2026
-
Автоматизация функционального тестированияНачало: 13 марта 2026
-
Тестирование REST APIНачало: 16 марта 2026
-
Техники локализации плавающих дефектовНачало: 16 марта 2026
-
Логи как инструмент тестировщикаНачало: 16 марта 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 17 марта 2026
-
Школа Тест-АналитикаНачало: 18 марта 2026
-
Тестирование GraphQL APIНачало: 19 марта 2026
-
Инженер по тестированию программного обеспеченияНачало: 19 марта 2026
-
Применение ChatGPT в тестированииНачало: 19 марта 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 19 марта 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 19 марта 2026
-
Charles Proxy как инструмент тестировщикаНачало: 19 марта 2026
-
Создание и управление командой тестированияНачало: 19 марта 2026
-
Тестирование веб-приложений 2.0Начало: 20 марта 2026
-
Автоматизация тестирования REST API на JavaНачало: 25 марта 2026
-
Тестирование безопасностиНачало: 25 марта 2026
-
Тестирование мобильных приложений 2.0Начало: 25 марта 2026
-
Автоматизация тестирования REST API на PythonНачало: 25 марта 2026
-
Программирование на C# для тестировщиковНачало: 27 марта 2026
-
Selenium IDE 3: стартовый уровеньНачало: 3 апреля 2026
-
Программирование на Python для тестировщиковНачало: 3 апреля 2026
-
Аудит и оптимизация процессов тестированияНачало: 3 апреля 2026
-
Практикум по тест-дизайну 2.0Начало: 10 апреля 2026
-
Тестирование производительности: JMeter 5Начало: 10 апреля 2026
-
Школа тест-менеджеров v. 2.0Начало: 15 апреля 2026
-
Программирование на Java для тестировщиковНачало: 17 апреля 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 11 мая 2026
-
Организация автоматизированного тестированияНачало: 15 мая 2026
| Что такое XML |
| 13.11.2020 00:00 | ||||||||||||||||||||||||||
|
Автор: Ольга Назина (Киселёва) Если вы тестируете API, то должны знать про два основных формата передачи данных:
Сегодня я расскажу вам про XML. В списке доп литературы будет ссылка на книгу по XML, у меня нет цели ее дублировать, но я расскажу про этот формат тем, кто XML еще в глаза не видел. А дальше уже гуглим сами )) XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде. Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных! См также:
Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.

Содержание
Как устроен XMLВозьмем пример из документации подсказок Дадаты по ФИО:
И разберемся, что означает эта запись. 
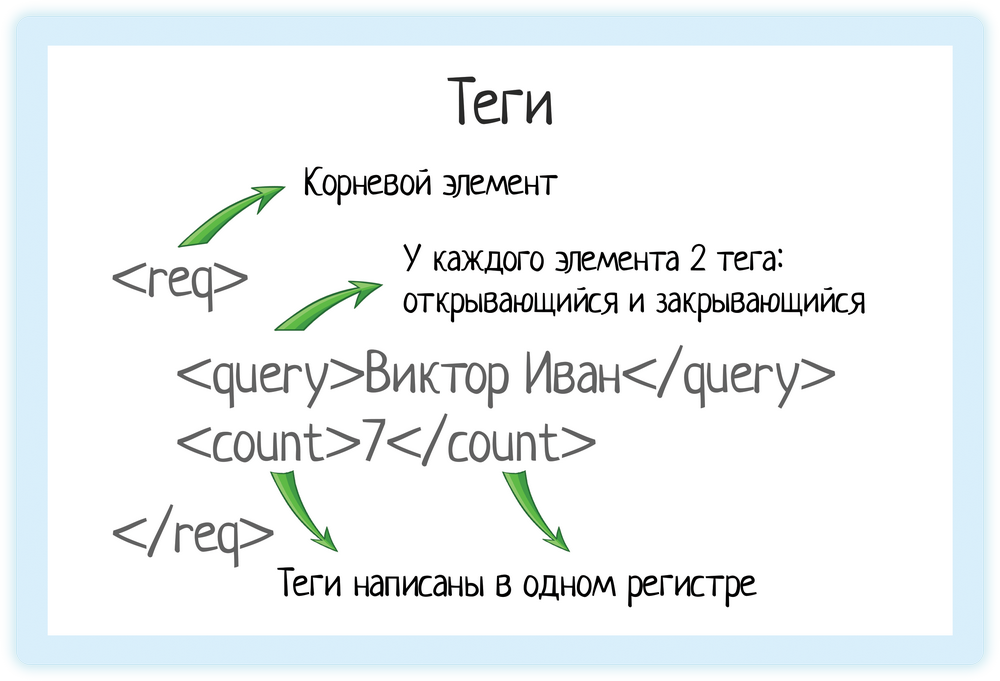
ТегиВ XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки: <tag>. Текст внутри угловых скобок — название тега. Тега всегда два:
 Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже! С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки: — На въезде в город написано его название: Москва — На выезде написано то же самое название, но перечеркнутое: Москва* * Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный! 
Корневой элементВ любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает. Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».  Он мог бы называться по другому:
Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых. Значение элементаЗначение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги! Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.  Внутри — значение запроса.  Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):  Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги. Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».  Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Обратите внимание:
Но оба значения идут без кавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется). Атрибуты элементаУ элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
название_атрибута = «значение атрибута»
Например:
 Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло. Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>
А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
<party type="PHYSICAL" sourceSystem="AL" rawId="2"> <field name=“name">Олег </field> <field name="birthdate">02.01.1980</field> <attribute type="PHONE" rawId="AL.2.PH.1"> <field name="type">MOBILE</field> <field name="number">+7 916 1234567</field> </attribute> </party>
Давайте разберем эту запись. У нас есть основной элемент party.  У него есть 3 атрибута:

Внутри party есть элементы field.  У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.  Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д. Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ): — есть элемент party; — у него есть элементы field; — у каждого элемента field есть атрибут name, в котором хранится название поля. А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода: — При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален. — Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо. В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое. Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:

У элемента attribute есть атрибуты:
 Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов… Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато… А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента. XML прологИногда вверху XML документа можно увидеть что-то похожее: <?xml version="1.0" encoding="UTF-8"?> Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа. UTF-8 — кодировка XML документов по умолчанию. XSD-схемаXSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML. Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней». Если мы создаем SOAP-метод, то указываем в схеме:
Теперь, когда к нам приходит какой-то запрос, он сперва проверяется на корректность по схеме. Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных… Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.  Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец! 
А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть. 
Итого, как используется схема при разработке SOAP API:
А теперь давайте посмотрим, как схема может выглядеть! Возьмем для примера метод doRegister в Users. Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
<xs:element name="doRegister "> <xs:complexType> <xs:sequence> <xs:element name="email" type="xs:string"/> <xs:element name="name" type="xs:string"/> <xs:element name="password" type="xs:string"/> </xs:sequence> </xs:complexType> </xs:element> А в WSDl сервиса она записана еще проще: <message name="doRegisterRequest"> <part name="email" type="xsd:string"/> <part name="name" type="xsd:string"/> <part name="password" type="xsd:string"/> </message> Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы: <xsd:complexType name="Test"> <xsd:sequence> <xsd:element name="value" type="xsd:string"/> <xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/> <xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/> <xsd:element name="user" type="USER" minOccurs="0"/> </xsd:sequence> </xsd:complexType> А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач. См также: XSD — умный XML — полезная статья с хабра Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать Язык описания схем XSD (XML-Schema) Практика: составляем свой запросОк, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация! 
Что, если я хочу, чтобы мне вернуть только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender. Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:
Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример ))) Попробуй сам! Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи. Well Formed XMLРазработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный. Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами. В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос. Правила well formed XML:
 Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались? См также: Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках 1. Есть корневой элементНельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна. И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
2. У каждого элемента есть закрывающийся тегТут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента. Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/> Это тоже самое, что передать в нем пустое значение
<name></name> Аналогично сервер может вернуть нам пустое значение тега. Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.  Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце. Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимыКак написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось. А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
|




|
НЕТ |
ДА |
|
<fio>Иванов <name>Иван</fio> Иванович </name> |
<fio>Иванов ИванИванович</fio> <name> Иван </name>
|
|
<fio>Иванов <b> <name>Иван</name> Иванович</fio></b>
|
<fio>Иванов <name>Иван</name> Иванович</fio>
|
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:
<query attr1=“123”>Виктор Иван</query>
<query attr1=“атрибутик” attr2=“123” >Виктор Иван</query>
Для тестирования пробуем передать его без кавычек:
<query attr1=123>Виктор Иван</query>
Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.
Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.

Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Изучаем XML. Эрик Рэй (книга по XML)
PS — это выдержка из моей книги для начинающих тестировщиков, написана в помощь студентам моих курсов — по автоматизации в Postman и по тестированию REST API