Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Азбука ИТНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Python для начинающихНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Инженер по тестированию программного обеспеченияНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
-
Bash: инструменты тестировщикаНачало: 1 октября 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 1 октября 2026
-
Docker: инструменты тестировщикаНачало: 1 октября 2026
-
SQL: Инструменты тестировщикаНачало: 1 октября 2026
-
Git: инструменты тестировщикаНачало: 1 октября 2026
| Способы стабилизации автотестов на backend: опыт сервиса Звук |
| 11.11.2025 00:00 | ||||||||||||||||||||||
|
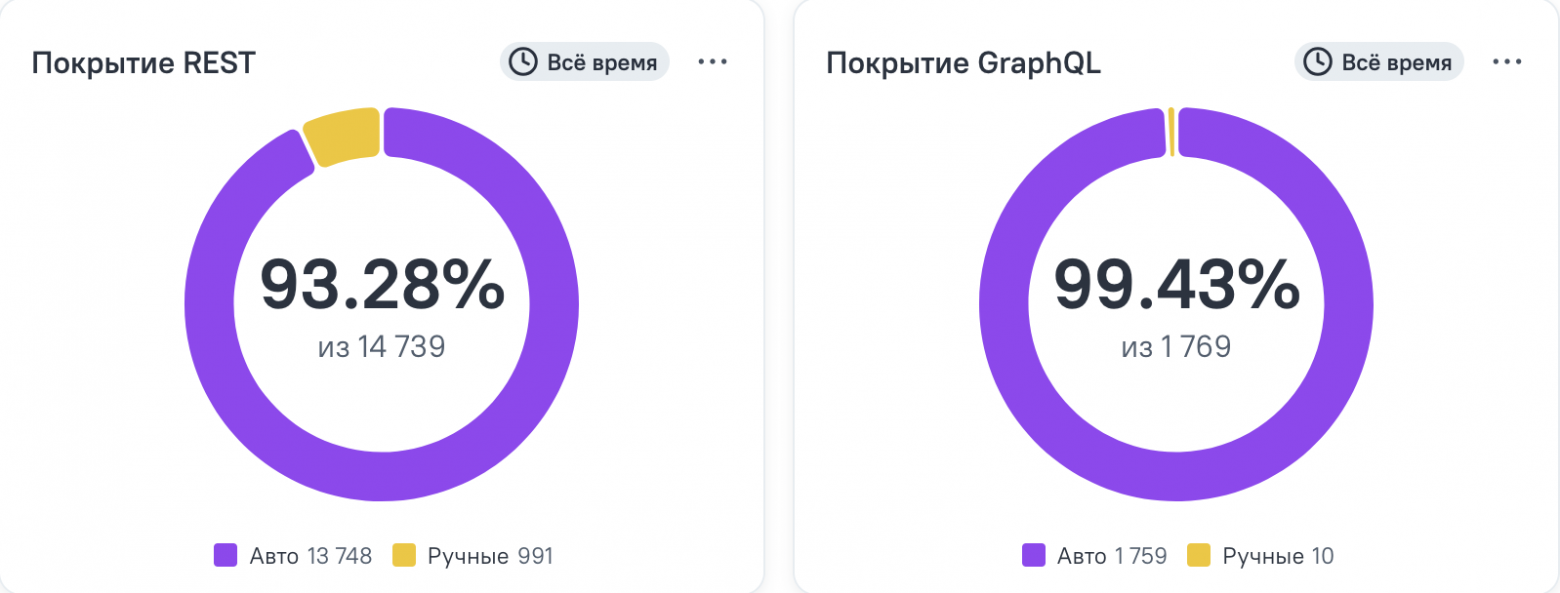
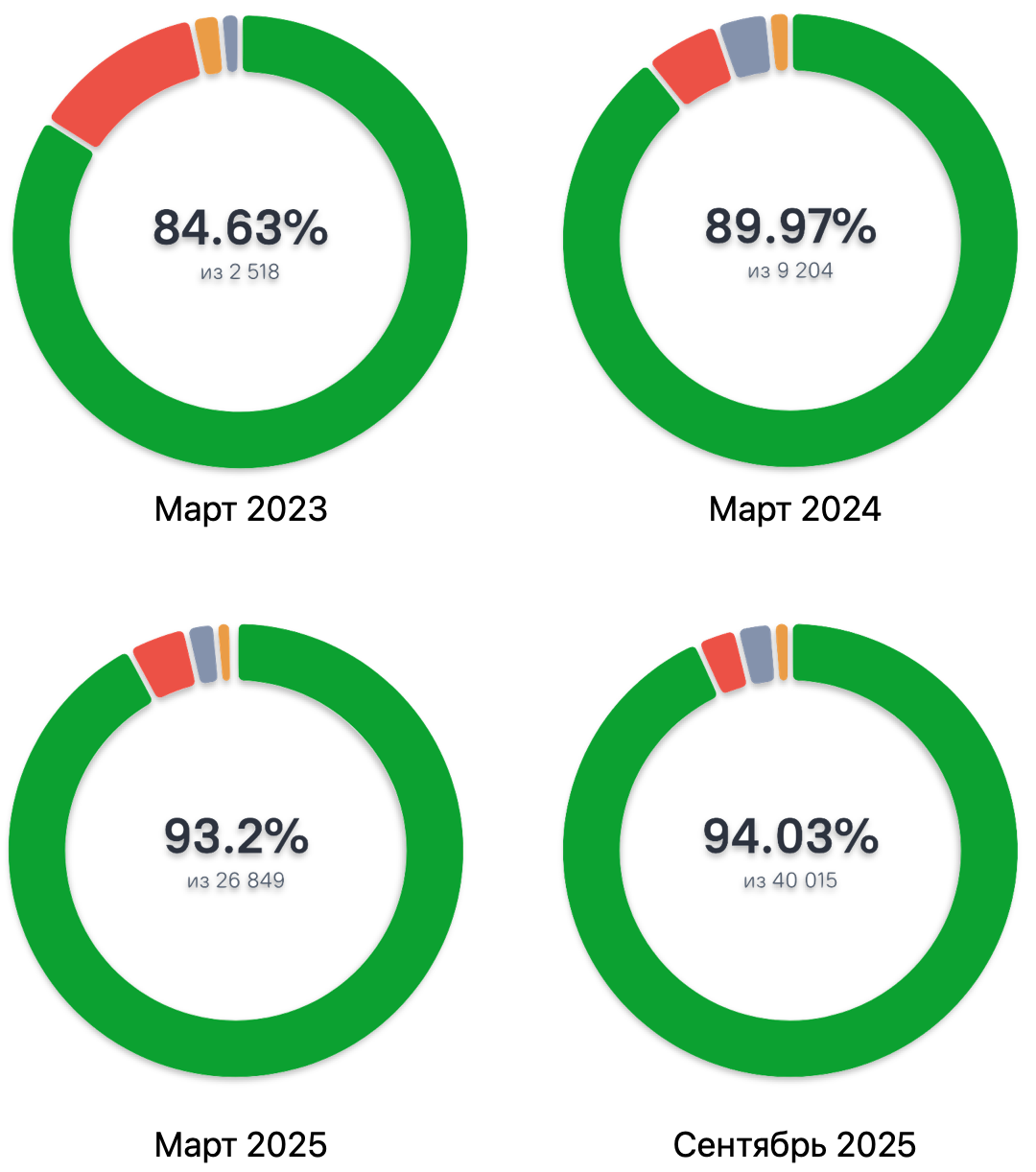
Меня зовут Надежда Буртелова, я ведущая тестировщица в музыкальном сервисе Звук. В тестировании с 2014 года, с 2022 года работаю в Звуке: тестирую backend и менторю коллег. Последние два года активно пишу автотесты. Закончила МФТИ: факультет аэрофизики и космических исследований. В статье разберу причины нестабильности автотестов на бэкенде и предложу способы их стабилизации. Расскажу, как из одного «флакающего» теста сделать три стабильных, стоит ли автоматизировать изначально нестабильные сценарии и когда лучше что-то убрать из автотестов и сохранить адекватное покрытие. Организация работы в QA-backend сервиса Звук Команда тестирования на бэкенде состоит из “ручных” и “авто” тестировщиков. “Ручные” тестировщики пишут кейсы и автотесты, команда автоматизации пишет автотесты по ручным кейсам и развивает наш проект автотестов. Мы пишем автотесты на Kotlin. На сентябрь 2025 у нас больше 15 тысяч автотестов без учёта параметризации и свыше 39 тысяч — с ней.
Как ТМС мы используем Testops. Он позволяет просматривать данные по запускам, хранит данные запросов и ответов из тестов неделю, а статистику прохождения тестов условно вечно. Мы ежедневно следим за актуальностью наших тестов:
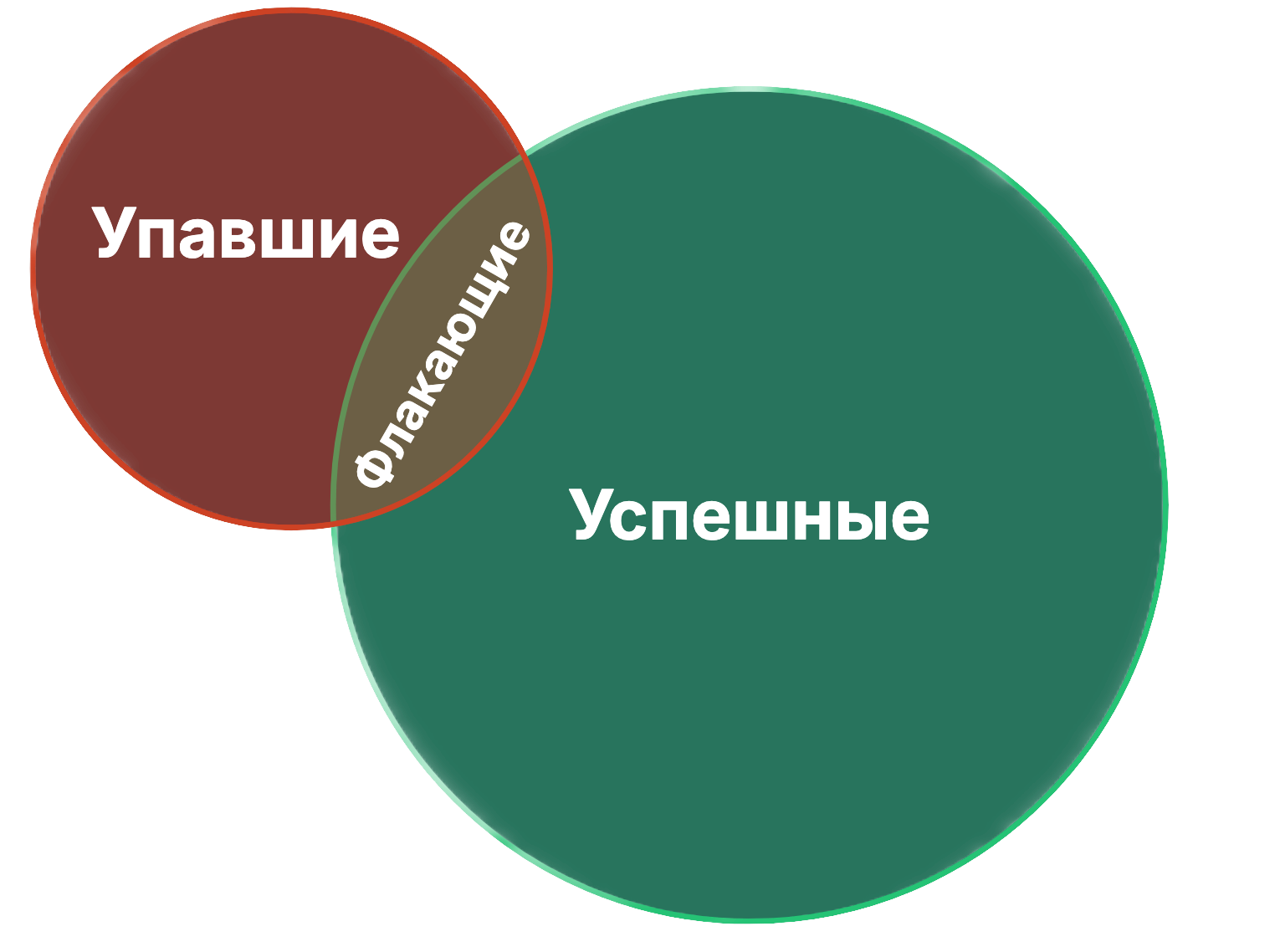
Флакающий тестДля начала давайте разберемся, что такое флакающий тест. Если мы посмотрим на абстрактную тестовую модель в любой момент жизни, то там будут стабильно зеленые тесты (которые каждый раз проходят успешно), стабильно красные тесты (которые каждый раз падают) и те, которые никуда стабильно не попадают - флакающие. Флакающий (нестабильный) тест – это такой тест, который в условно одинаковых обстоятельствах выдает разный результат. Если говорить бытовым языком, то это тот тест, который надо перезапустить 3 раза, чтобы быть уверенным в его результате. Тест может быть нестабильным как из-за плавающего бага, так и из-за того, что в тесте что-то не учтено.
Как определить к какой категории относится тест:
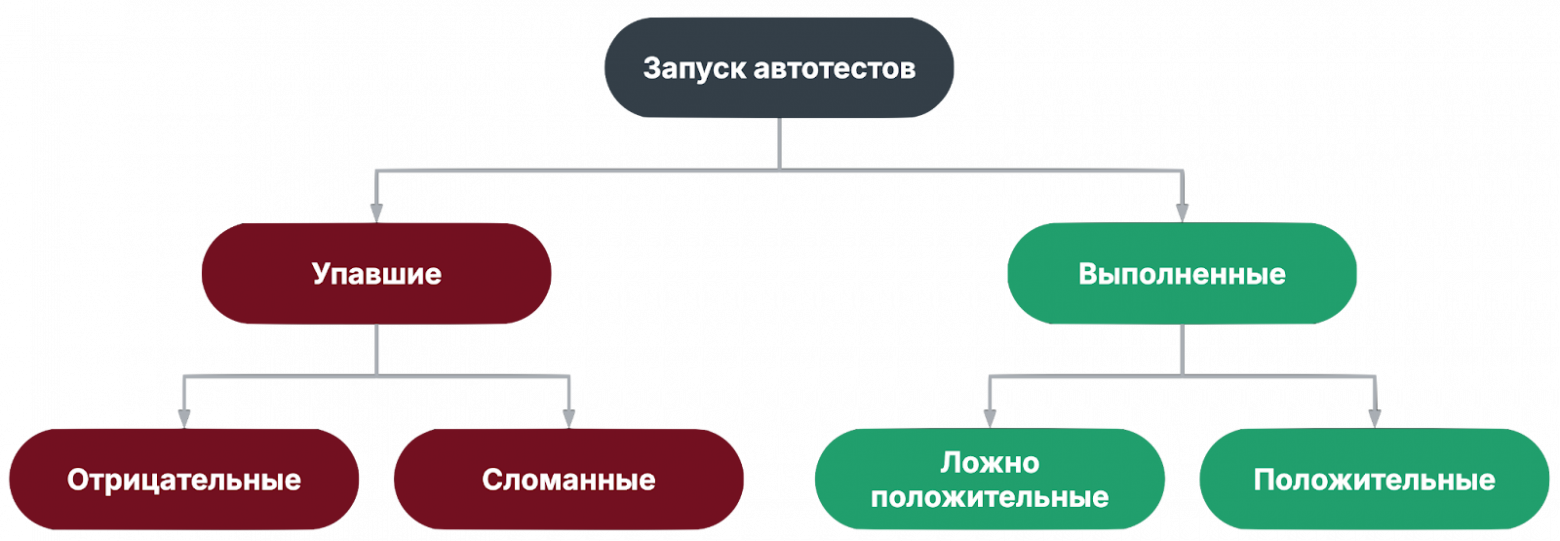
Классификация тестов в запускеТеперь взглянем на тесты в разрезе конкретного запуска.
Если посмотреть на любой прогон автотестов, все тесты можно разделить:
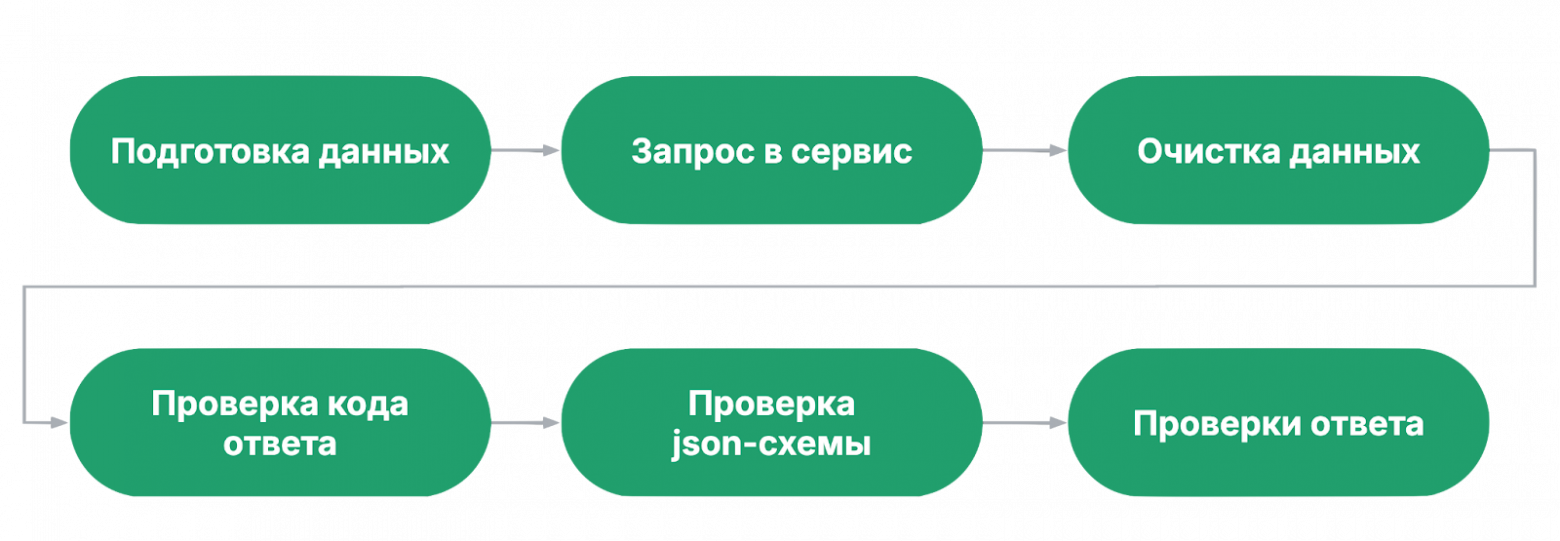
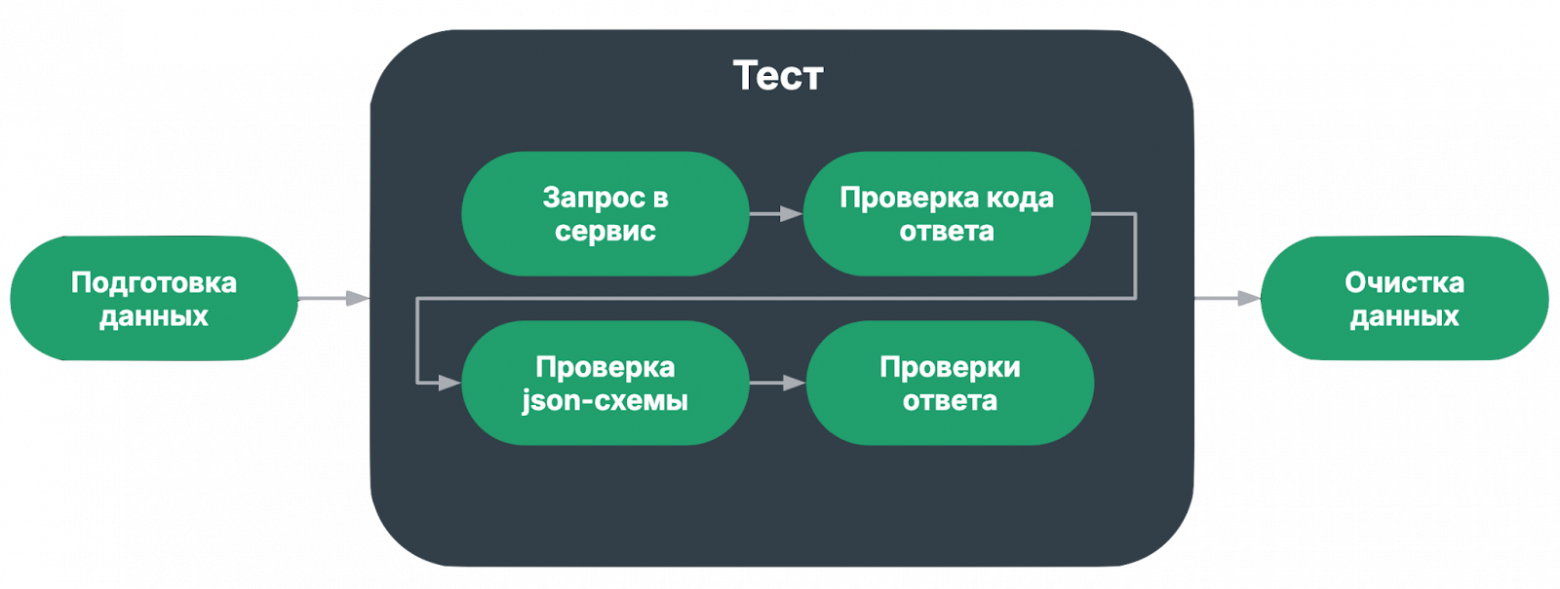
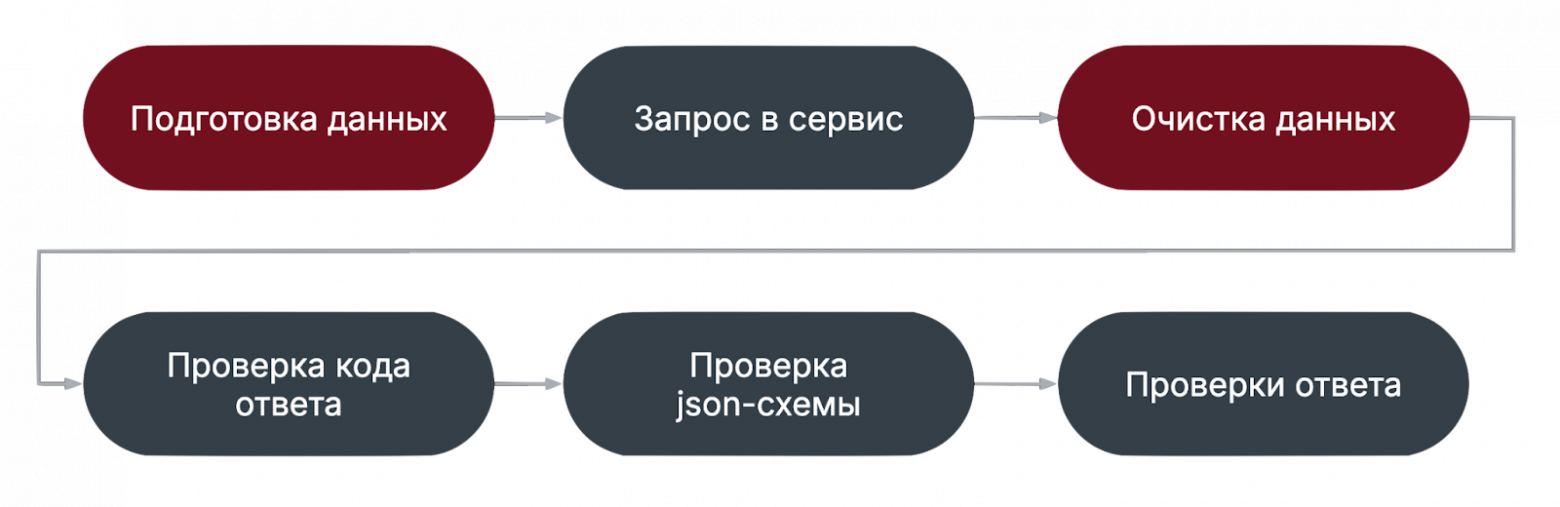
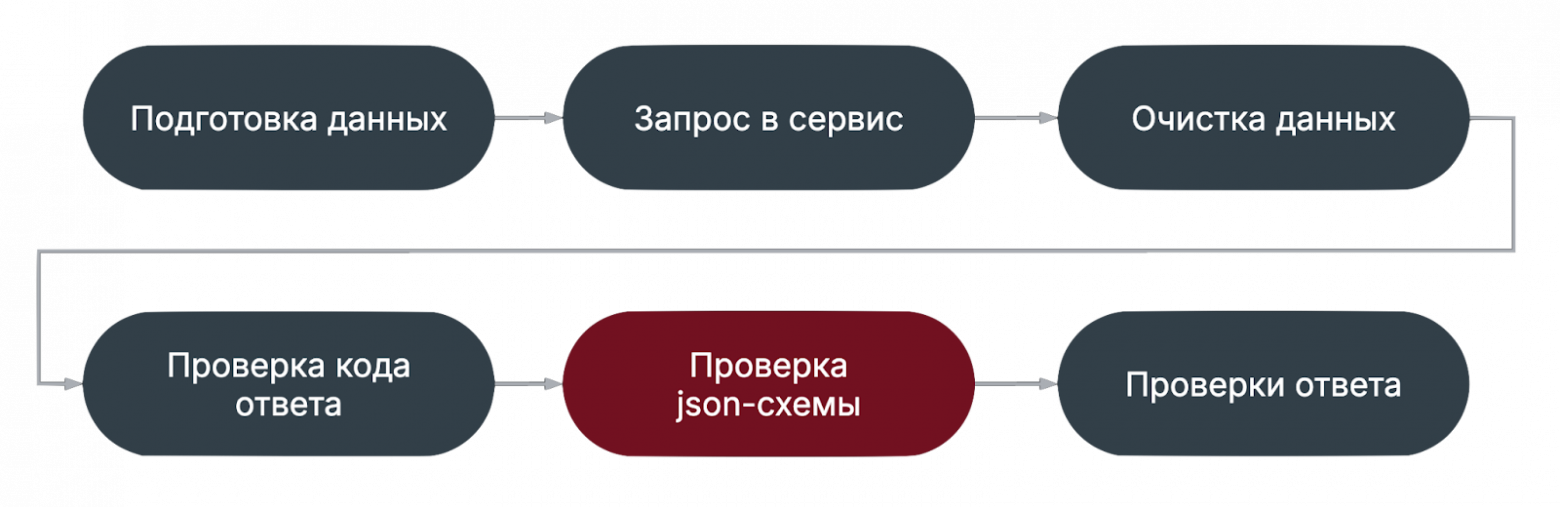
При этом флакающие тест могут попадаться во всех категориях. Тут я хочу заострить внимание на том, что важно чинить сломанные и флакающие тесты, и анализировать покрытие, чтобы вычислять ложноположительные тесты. Такие тесты не только ничего не проверяют, но и могут скрывать под собой дефекты. Состав автотестаДальше я буду локализовать причины нестабильности по этапам теста, поэтому рассмотрим состав типичного автотеста:
Что важно заметить в данной конфигурации? Очистка данных идет раньше всех проверок. Это значит, что даже если тест упадет на проверках, тестовые данные не будут загрязнять окружение. Второй вариант типичного автотеста: подготовка и очистка данных вынесены за пределы теста.
Обе конфигурации имеют право на существование. Мы используем обе и даже их комбинацию. Теперь рассмотрим некоторые этапы чуть подробнее. Способы подготовки данныхВ подготовке данных можно выделить четыре подхода:
В принципе, эти паттерны могут использоваться и на других этапах теста. Также хочется подсветить, что если в тесте предполагается модифицировать чувствительные данные, которые могут поломать всё окружение, то такой автотест лучше не писать. Проверки ответаТеперь рассмотрим внимательнее проверки ответов.
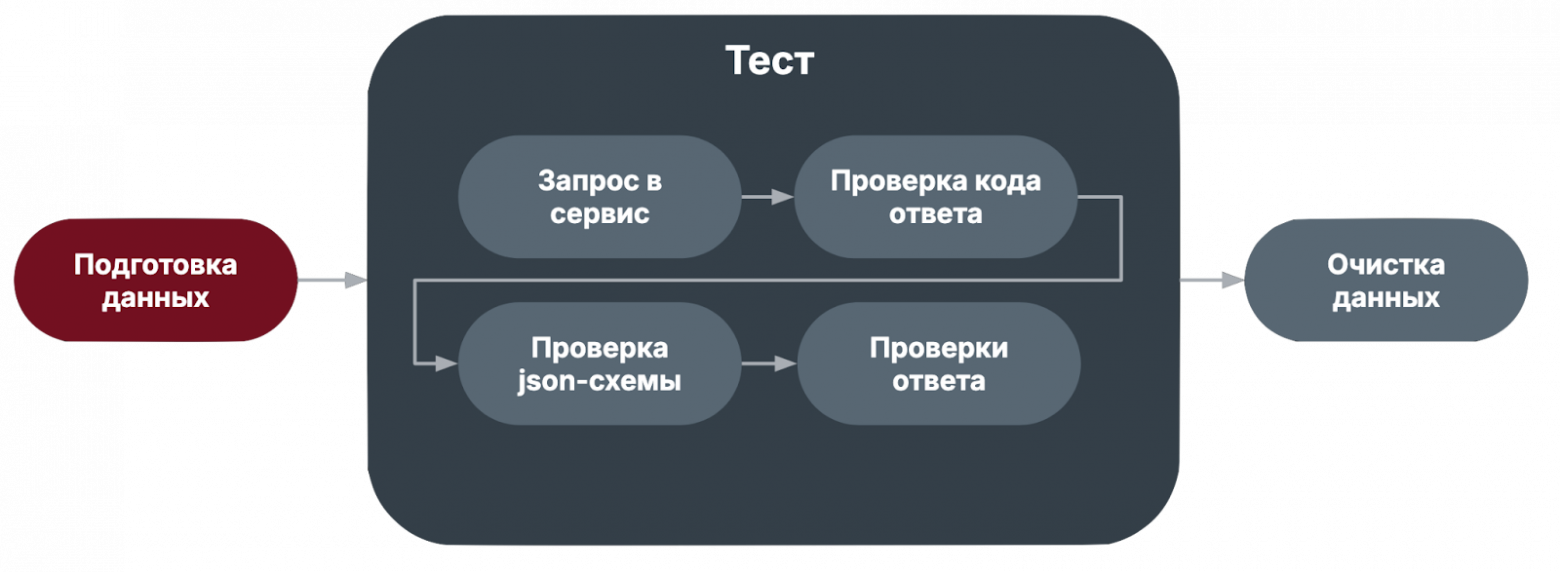
Для начала обратим внимание на порядок проверок:
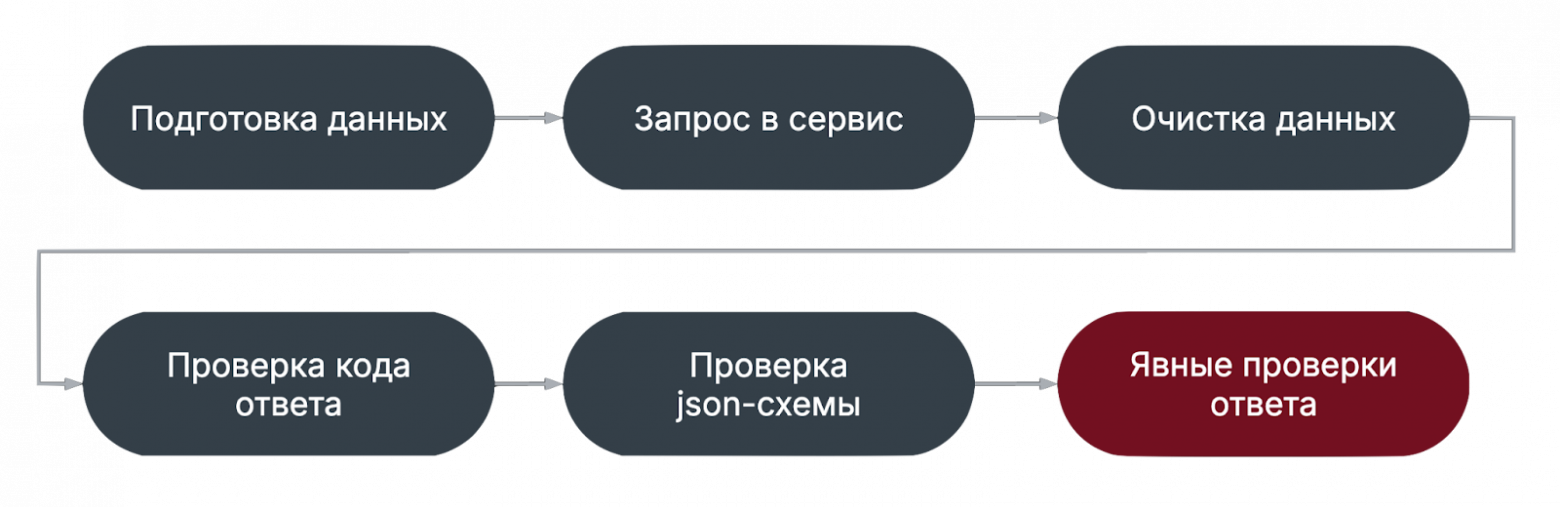
Мы движемся от простой проверки к более сложным. Грубо говоря, если код ответа не ожидаемый, то дальше проверять смысла нет. Проверка json-схемы ответаНа этапе проверки схемы проверяются следующие вещи
Явные проверки ответа
Основные причины нестабильности тестовМожно выделить три группы причин нестабильности тестов.
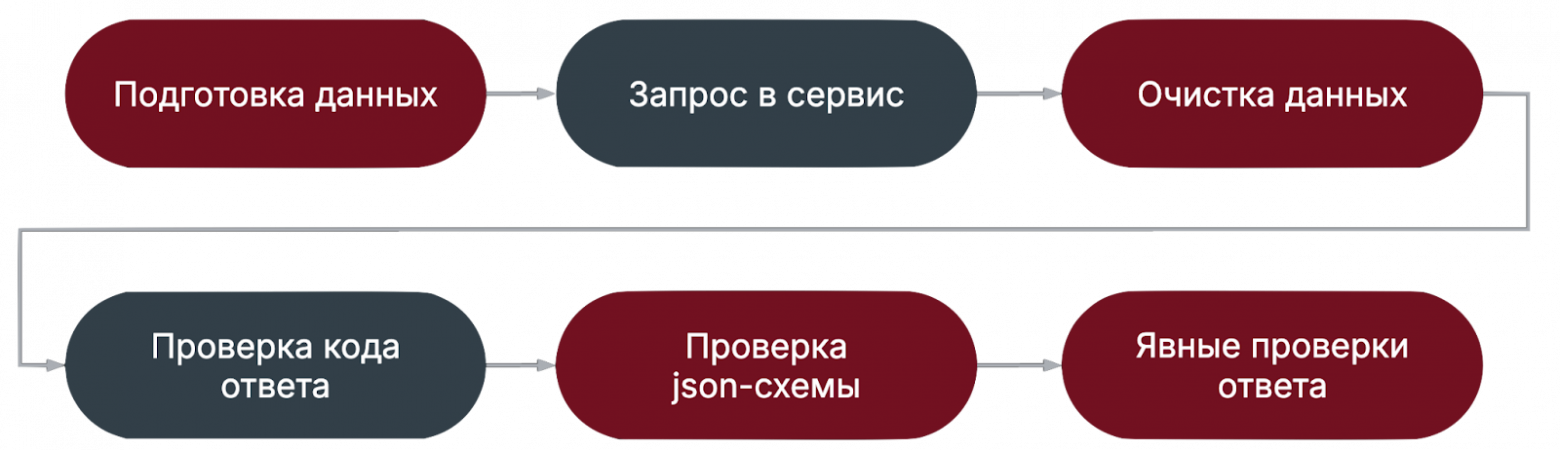
Далее мы подробнее рассмотрим причины непосредственно связанные с автотестами. Места нестабильности автотестовПосле вступления мы можем выделить на схеме основные проблемные места – этапы подготовки и очистки данных, проверка схемы ответа и явные проверки ответа.
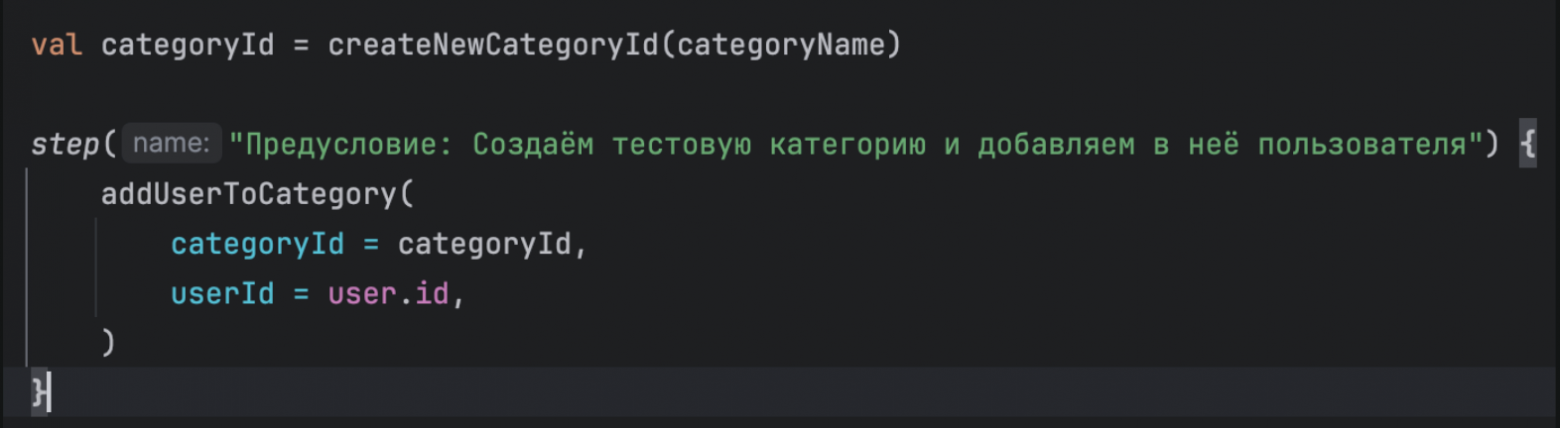
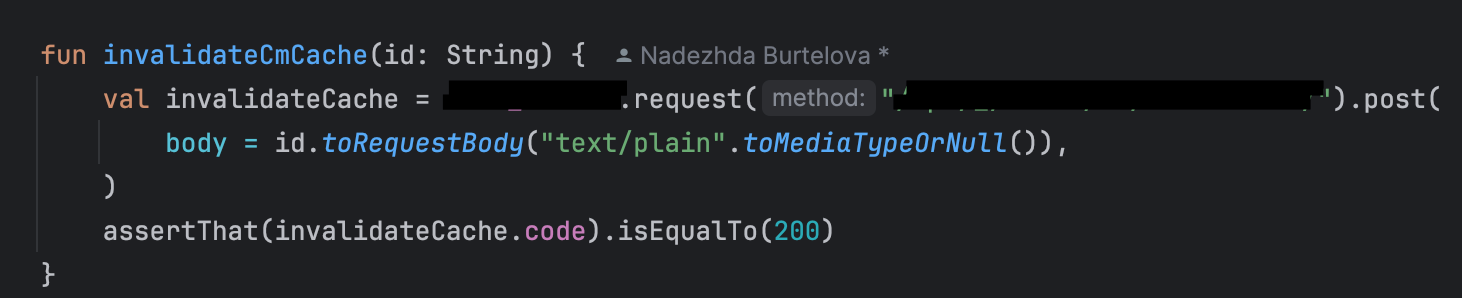
Некорректно обозначенные шагиДля начала обсудим проблему, которая может быть на любом этапе теста: некорректно обозначенные шаги. СимптомМы смотрим на упавший тест через ТМС или через ИДЕ при локальном запуске: тест падает на определенном шаге. Мы погружаемся в код и проблема оказывается гораздо выше. Пример некорректного и корректного обозначения шаговПриведу пример кода с некорректно обозначенными шагами
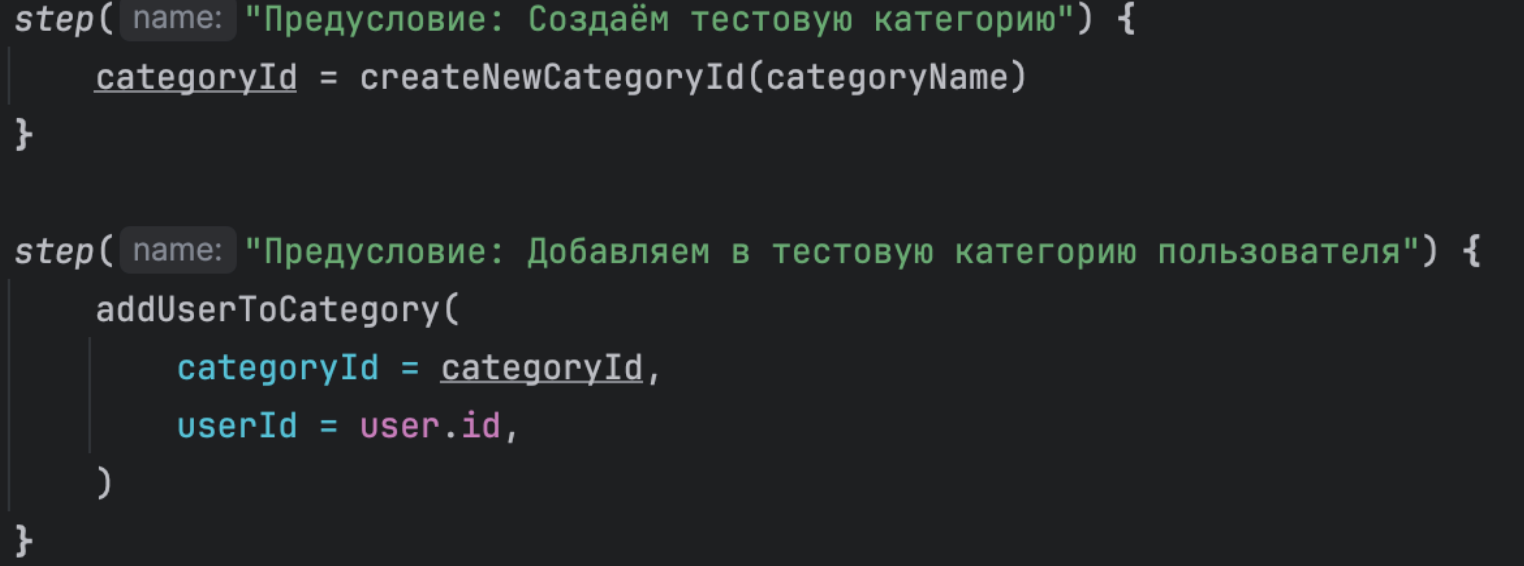
А как бы следовало обозначить шаги:
Решение:
Обозначенные шаги позволяют:
Проблемы на этапе подготовки и очистки данных
Теперь рассмотрим внимательнее проблемы, которые происходят на этапах подготовки и очистки данных. Отсутствие ленивой инициализации данныхНачнем с конфигурации, где подготовка и очистка данных вынесены за пределы теста.
ПроблемаЕсли данные готовятся в начале класса и не используются ленивая инициализация данных (паттерн
РешениеИспользовать паттерн Для тестов из класса, которые не зависят от этих данных:
Теперь перейдем к проблемам, которые не зависят от места подготовки данных. Использование хардкодаНа мой взгляд, основная проблема хардкода в автотестах – потеря контекста. Пока ты писал тест, ты помнил, почему захардкодил этот idшник. Но через время контекст данных теряется, а тест с этими данными почему-то перестает выполняться. Поэтому по возможности заменять хардкод получением данных из БД или генерацией данных.
Но бывают ситуации, когда хардкод неизбежен. Пример такой ситуации у нас – “горячий пользователь”. Это пользователь, который имеет много лайков и прослушиваний на регулярной основе. Быстро такого пользователя не создать. Поэтому мы хардкодим его в тестах, но в комментариях описываем причину хардкода, и как его воссоздать в случае потери. Если хардкод неизбежен, писать развернутый комментарий:
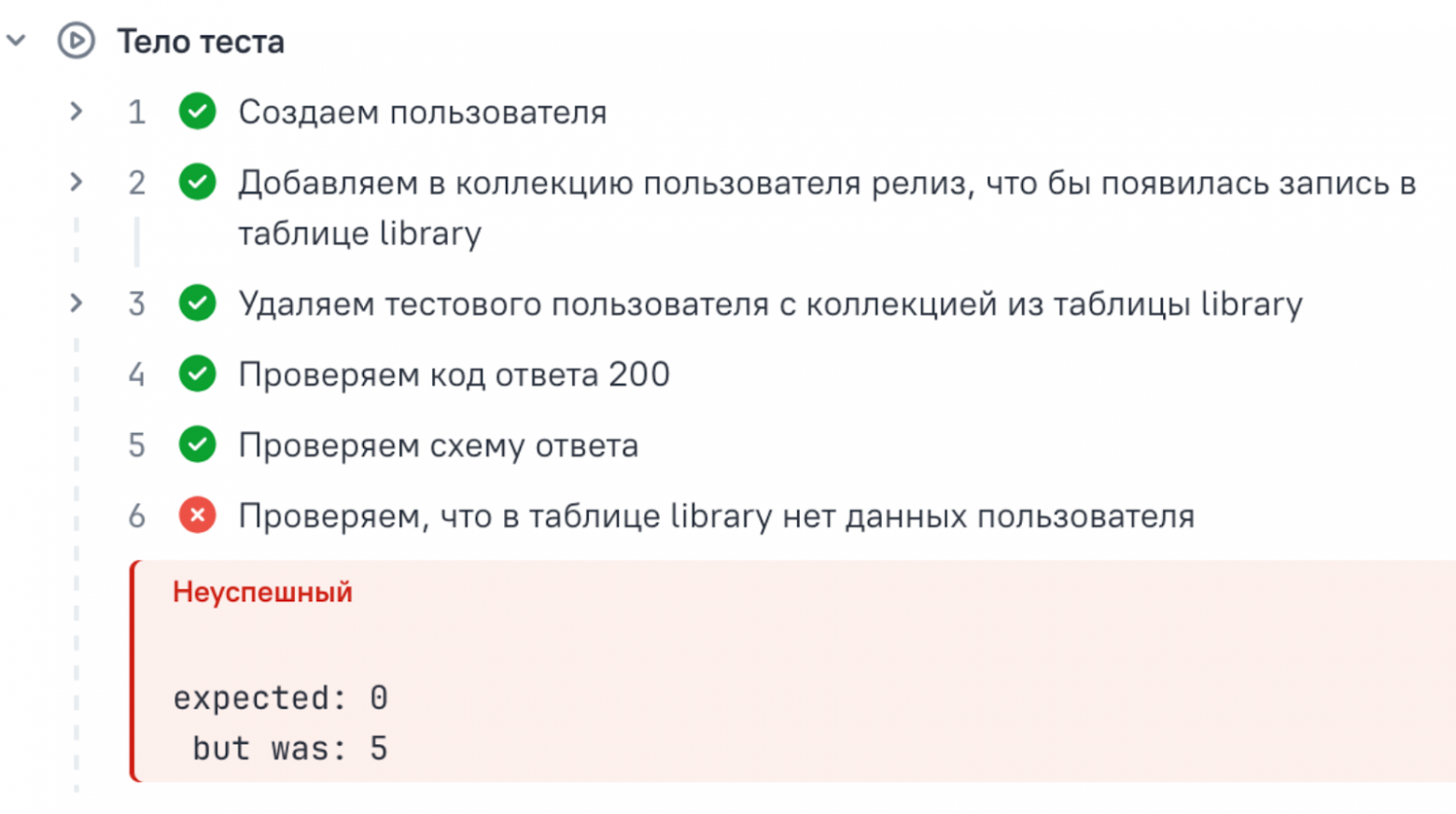
Неточный запрос в БДСледующая проблема может возникнуть после того, как мы заменили хардкод запросами в БД, но сформулировали запрос недостаточно точно. Пример ситуацииУ нас была задача от бизнеса: если у артиста нет фото, то отображать обложку релиза. Мы запрашивали из БД любого артиста без фотографии. А тест периодически падал. Я стала изучать данные, с которыми тест проходил и падал. В итоге разделила один флакающий тест, на три стабильных:
Решение:
Модификация одних и тех же данных в разных тестах Симптом: Тест хорошо работает, когда запускается один, но падает при массовом запуске Пример ситуации: У нас был класс, где пользователь создается в начале класса. В классе была два конкурирующих теста:
Второй тест работал стабильно в одиночестве. Но если первый тест выполнялся раньше второго, то второй падал. Мы стали создавать отдельного пользователя для каждого из тестов. Решение:
Отсутствие проверки генерации данныхНачну с ситуации, которая проиллюстрирует эту проблему. У нас был функционал, который превращал профиль обычного пользователя в профиль артиста. Функционал убрали, тесты на него удалили. Но где-то в закромах проекта остался метод, который “продолжал использовать этот функционал”. А этот метод использовал тест на другой сервис. Этот тест “успешно” выполнялся до тех пор, пока мы не добавили проверку кода во все сервисные функции. Из данной ситуации мы можем выделить несколько проблем:
Во все сервисные функции необходимо добавлять:
Проблемы на этапе проверки схемы
На моменте проверки схемы могут возникнуть две проблемы
Проблему неожиданных данных мы разобрали выше. Поэтому теперь обсудим слишком жесткую схему. Рассмотрим пример с типом данных. Мы написали тест на получение профиля пользователя и ожидаем, что у него в профиле будут телефон и почта. То есть, в схеме мы ожидаем:
Однако в реальности у нас есть пользователи, у которых указаны только телефон или только почта. Но не существует пользователей без телефона и без почты. Что можно сделать, чтобы получить стабильный тест?
Ситуация с обязательными и опциональными полями решается аналогичным способом. Проблемы на этапе основных проверокТеперь перейдём к проблемам, которые возникают на этапе основных проверок
Тест не готов к состоянию кэша Эта проблема актуальна для тестов на сервисы с кэшированием данных. Тест хорошо работает при первом одиночном запуске. Но падает при повторном запуске или массовом запуске тестов этого же сервиса. Решение: - Чистить кэш сервиса по ключу перед запуском теста. Сделать это этапом подготовки данных. - Отключать параллельный запуск тестов и регулировать очередность запуска тестов. Тест со слишком большим числом проверок Эта проблема возникает, когда в маниакальном эпизоде вы написали тест, который проверяет ВСË. Такой тест включает очень много шагов, и может каждый раз падать на новом месте. Статистику с его падениями очень сложно интерпретировать. Что же можно сделать с таким тестом?
Конструкция soft assert не останавливает прохождение теста, если какая-то проверка падает. Тест доходит до конца и подсвечивает упавшие проверки. Для иллюстрации разберем пример: при первом запросе профиля пользователя происходит кэширование, кэш хранится час. Если профиль обновить, то кэш очищается.
При этом, я не говорю, что тесты с большим числом проверок не имеют права на существование. Могут быть ответы, где все поля жестко взаимозависимы и нет никакого смысла разделять проверки на несколько тестов. Слишком жесткие проверкиНачну разбор этой проблемы с иллюстрации. Мне нужно было написать тест, который проверяет, что заполняется дата регистрации пользователя. В первой итерации теста я брала системные дату и время и сравнивала с данными из ответа. При локальном запуске одного теста все работало замечательно. Но уже при каких-то мелких задержках время расходилось и тест падал. Что можно сделать в этой ситуации?
В таблице я предложила варианты более мягких проверок для нашего примера:
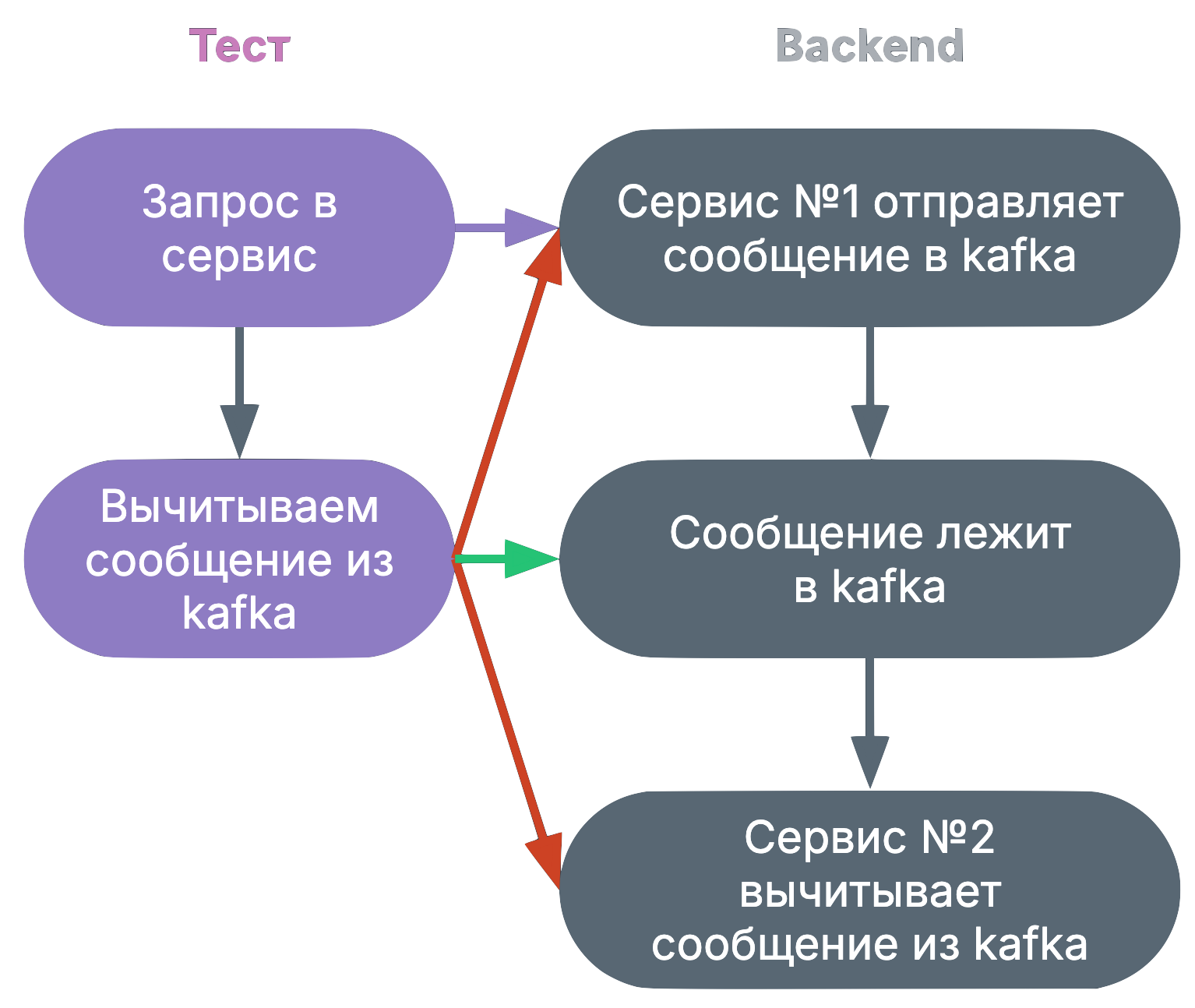
Стоит ли автоматизировать нестабильные сценарииМы с вами разобрались с техниками стабилизации автотестов, но бывают такие сценарии тестов, где результат фактически зависит от скорости, ловкости и острого взгляда QA, и поэтому может быть изначально не очень стабильными. Примером такой ситуации может служить гонка состояний. Наш тест отправляет запрос в сервис и проверяет, что этот сервис отправил сообщение в Kafka. Тест должен проверить наличие сообщения. Проблема в том, что сообщение должно быть вычитано в промежуток времени, после того, как проверяемый сервис его отправил, но до того, как другой сервис его вычитал.
В этот промежуток времени не так легко попасть, и поэтому такой тест изначально нестабильный. Когда нужно автоматизировать нестабильные сценарии?
Причем в ручную проверку в данной ситуации включается не только чистое время проверки, но и когда вы вспоминаете пароли, ищете нужные ссылки и тому подобное. Тест из примера можно сделать стабильнее следующим способом:
Используя эти техники нужно следить, чтобы время выполнения теста было разумным. И если тест по прошествии этого времени не выполнился, то он должен упасть. Ну и если мы знаем, что тест нестабильный, то нужно не бояться перезапустить его несколько раз. Также можно внутри теста можно сохранять данные сообщения и потом допроходить его руками. Ложноположительный тест Когда я рассказывала от тестах в разрезе конкретного запуска, я ввела термин “ложноположительный тест”, но не раскрыла его. Как мне кажется, причины нестабильности тестов и их решения, которые мы обсудили выше помогут раскрыть вопрос ложноположительного теста глубже. Ложноположительный тест – тест, который не проверяет ничего или проверяет не то, что от него ожидалось. Обычно ложноположительный тест обнаруживается двумя способами:
Рассмотрим, как он может проявиться:
При большом тестом парке вычислить все существующие ложноположительные тесты невозможно. Поэтому основной метод борьбы – не писать такие тесты. При написании и отладке тестов можно использовать следующие самопроверки:
Выводы
 Спасибо, что прочитали статью. Буду рада вашим вопросам и комментариям! |