Что пишут в блогах
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Азбука ИТНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Python для начинающихНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
| Как заставить API самому себе писать тесты: практика генерации тестов на основе спецификации API. Часть 1 |
| 03.02.2025 00:00 |
|
Тестирование API — неизменная задача при разработке продуктов. Проблема, с которой сталкиваются многие компании, — большой ручной регресс. Появляется автоматизация, но покрытие огромного количества API‑методов требует ресурсов, которых часто нет. Кроме того, в большинстве случаев написание API‑тестов — монотонная работа, которой никто не любит заниматься. Как решить эти проблемы? Меня зовут Елизавета Андреева. Я инженер по автоматизации тестирования в ОК.Tech. Мы с коллегами в ОК разработали и внедрили автогенерацию API‑тестов, благодаря которой мы сокращаем ручную работу и время на написание однотипных автотестов, оставляем QA‑инженерам для покрытия только кейсы на бизнес логику. И в этой статье (которая станет первой в серии из двух частей) я начну рассказ о том, как мы реализовали наш генератор и каких результатов нам удалось достичь. Немного контекста: автотесты в ОК ОК — соцсеть с большим бэкендом, который состоит из множества сервисов. Для отслеживания работоспособности всех компонентов социальной сети мы стараемся покрыть всё тестовыми сценариями, а ручные проверки по возможности заменяем автоматизированными. У нас есть 5 ключевых платформ, на каждую из которых мы пишем автотесты. По всем платформам насчитывается более 10 тысяч автотестов, если смотреть по классам, некоторые из которых содержат набор тестовых методов:
Автотесты мы запускаем каждый день, и все сразу, и разными наборами, а самое главное, что обновление у нас невозможно выполнить без участия автотестов. Поэтому нам особенно важно следить за их актуальностью и качеством. По количеству вызовов и приоритету платформа номер один для нас — API. Это связано с тем, что API используется как всеми платформами, так и внешними разработчиками. Соответственно, покрытие API для нас является первоочередной задачей. Но ОК — не только большой, но и активно развивающийся проект. Так, чтобы соответствовать требованиям пользователей и создавать для них комфортную среду для общения и отдыха, мы непрерывно дорабатываем и улучшаем соцсеть на всех платформах. Это создает ряд трудностей с точки зрения тестирования.
Как решение, мы в ОК внедрили автогенерацию тестов, которая одновременно позволяет:
Теперь перейдем непосредственно к тому, как нам удалось реализовать такую автогенерацию от общего к частному. Ключевые компонентыВ нашей системе есть три ключевых компонента:
Примечание: Мы работаем с REST API, но реализованное нами решение подойдет и для других современных API. «Симбиоз» проектов работает следующим образом:
Теперь остановимся на каждом из ключевых компонентов по отдельности. Проект с нашим APIНачнём с нашего проекта с API, с помощью спецификации которого мы смогли генерировать тесты. Проект написан на Java. В нем находится наш API‑клиент. Мы не используем готовые решения и не собираемся от него отказываться, потому что у него есть ряд достоинств:
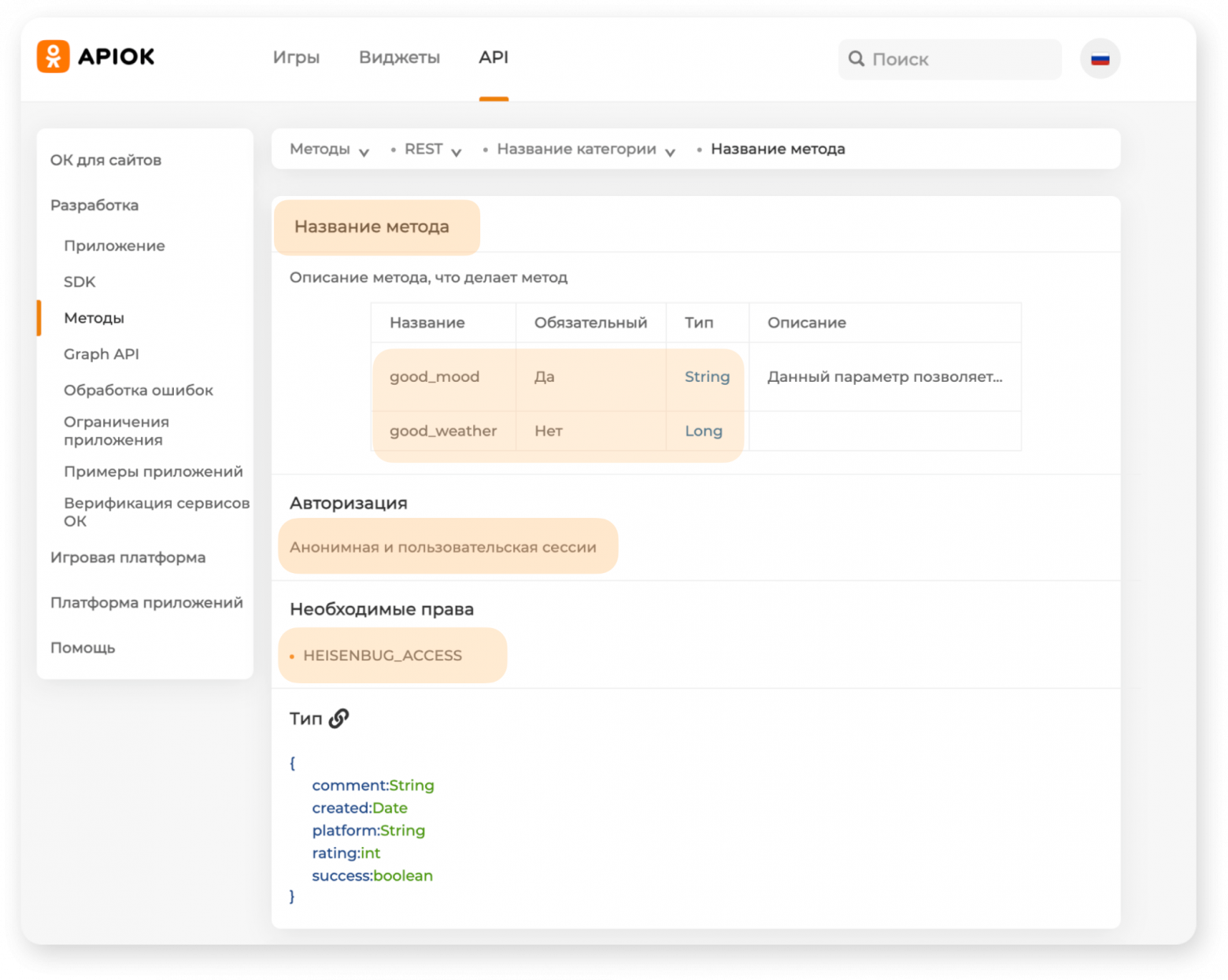
Также наличие специальных аннотаций дает возможность генерировать документацию на основе спецификации из них. Для этого используется Reflection API. Мы собираем список методов API по известным аннотациям и создаем шаблоны, которые содержат название метода, параметры, их обязательность, тип разрешений, необходимые сессии и так далее.
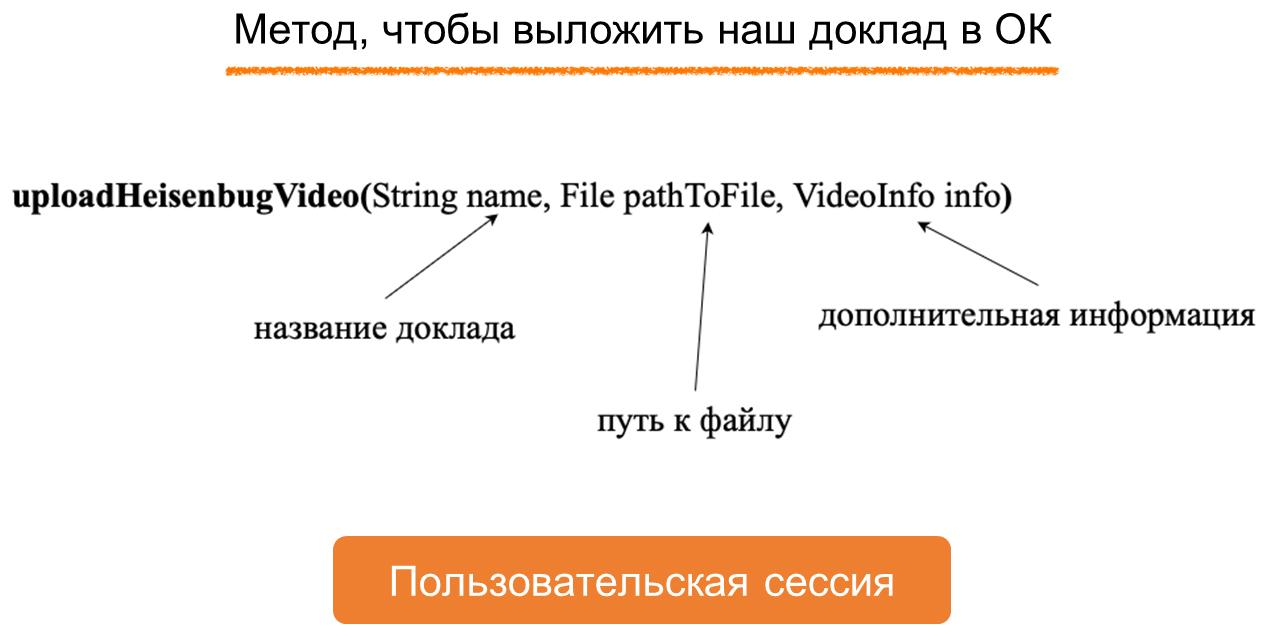
Таким образом, благодаря специальным аннотациям, мы имеем довольно большой объем метаинформации. Это позволило нам задуматься над тем, чтобы реализовать автоматическое создание не только документации, но и самих тестов, поскольку для этого у нас тоже достаточно данных. Давайте рассмотрим более подробно, как устроено наше описание спецификации API, которое позволяет нам получать столько информации. API-методыДля начала разберемся, как в нашем проекте описываются методы. Для наглядности сделаем это на условном примере. Допустим, у нас есть Вася, пользователь ОК, который выступил на конференции и захотел выложить видео доклада на портал, чтобы поделиться им с друзьями. Для загрузки доклада в ОК придумаем метод, например
Он будет получать в параметры:
Поскольку Вася хочет, чтобы доклад был выложен на его странице и друзья могли его увидеть в своей ленте, нам необходимо залогиниться, следовательно метод будет вызываться из пользовательской сессии. Теперь давайте попробуем реализовать этот метод в нашей спецификации. Как добавить API-метод?Чтобы добавить в наш API‑проект новый метод, разработчику нужно выполнить довольно простой чек‑лист. Надо:
Примечание: В отдельных ситуациях также бывает необходимым добавить новые типы данных. Это несложно, но нюанс всё же есть. Так, при генерации тестов кастомные типы данных сложнее заполнять, поскольку они не из стандартной Java‑библиотеки и их дефолтные значения неизвестны. Давайте пойдем по пунктам нашего чек‑листа:
Нам сразу необходимо указать тип возвращаемых данных. В нашем случае типом данных является ответ API‑метода, который нужно описать. Рассмотрим Задаётся он просто — описываем переменные и методы для работы с ними. В рамках примера будем возвращать значение булеановской переменной Далее метод мы помечаем нашей специальной аннотацией Мы бы могли просто написать привычный эндпоинт, но вместо этого используем константы, в которых, кроме пути к методу, храним ещё и дополнительные данные. Так, например, здесь есть тип сессии, который нужен для вызова метода, и флаги, например, флаг
Возвращаемся к описанию метода и далее хочется обратить внимание на то, как мы описываем параметры метода. Каждый параметр мы «оборачиваем» в аннотацию Аннотация содержит множество полей. Ключевые из них — название параметра и его обязательность. Если указать, что параметр обязательный — проверка его наличия при вызове метода будет выполняться на уровне фреймворка. Так, например, будет описан обязательный параметр со строчным названием доклада. Таким образом мы выполнили все пункты для добавления нового API‑метода в проект с нашим API. Но все еще непонятно, где Васе взять метод для загрузки видео в ОК. Ответ прост — для этого у нас есть специальный интерфейс API‑клиента, в котором перечисляются все серисы: гейзенбаг, фото, видео и т. д. Этот интерфейс мы уже и инициализируем в наших проектах с тестами. Таким образом, чтобы вызвать наш метод в проекте с тестами, нужно:
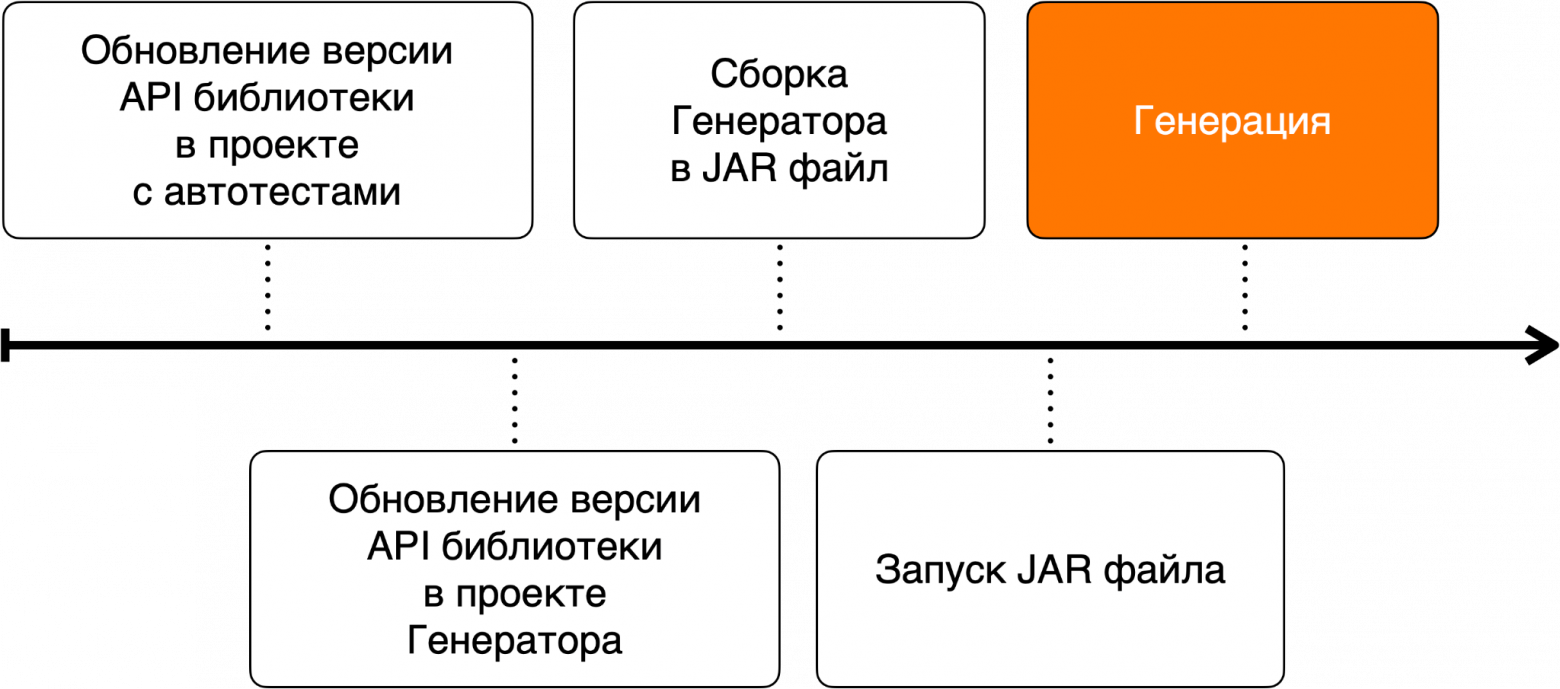
И в коде это будет выглядит примерно так: Проект API-тестовТеперь разберемся с тем, что из себя представляет проект с автотестами на наше API. Этот проект существует также достаточно давно, вместе с появлением самого кастомного клиента, и тесты здесь писали QA-инженеры. Наши сгенерированные тесты создаются по тем же правилам Code Style, используют тот же стек технологий, что и наши автотесты, написанные вручную, поэтому мы решили положить их в этот же проект. Шаги генерации в CI/CDМы не только автоматизировали генерацию тестов, но еще и автоматизировали сам этот процесс, включив его в единый пайплайн с апдейтом нашей API-библиотеки. Все шаги реализованы в TeamCity (далее TC), в сервисе, который мы используем в качестве основного инструмента для CI/CD (вы можете использовать любой другой). Схематично это выглядит так:
Давайте подробнее рассмотрим шаги:
Цепь вызовов выстроена через триггеры, которые ожидают успешного билда в указанной задаче.
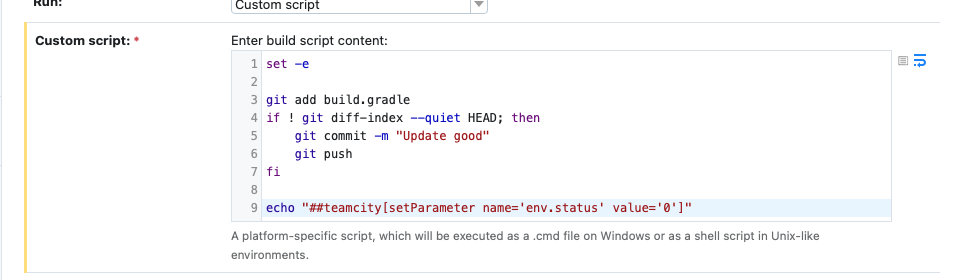
За исключением задач по созданию и запуску JAR‑файла. Вторая опирается на Snapshot Dependencies и Artifact Dependencies. Последний нам нужен, чтобы забрать созданный JAR‑файл из задачи, которая соответственно создает JAR‑файл. Мы указываем, какой файл забрать из артефактов другой задачи и куда положить (например, в папку target), а также, что необходимо забирать его из одной цепи сборки, поэтому тут подключается Snapshot Dependencies настройка, и каждый раз, когда мы запускаем исполнение JAR‑файла, будет сначала запускаться его сборка в другой задаче и мы будем ждать оттуда артефакт. Если на каком‑нибудь из шагов в цепи всех наших задач билд упал, то следующие задачи запущены не будут, а нашему дежурному по автотестам придет уведомление, что необходимо поправить билд и после запустить с того шага, где все остановилось. Уведомления о падении в каждой задаче свои, добавляются самым последним шагом, который будет выполнен только если что‑то упало. Эти шаги опираются на переменную (в нашем случае env.status), которую мы задаем в последнем шаге задачи, необходимым по нашему замыслу для её успешного выполнения.
Например, если мы говорим про обновление нашей API-библиотеки, то последний шаг — commit и push в удаленный репозиторий.
Чаще всего проблемы возникают на первом шаге, где мы обновляем версию API-библиотеки в проекте с тестами, потому что могли измениться сигнатуры методов. Генератор не так давно был запущен, но мы уже получили результаты:
В данной статье мы разобрали, как устроена наша спецификация и процесс генерации в CI/CD, а также, каких результатов нам удалось достичь. И еще давайте рассмотрим, как мы реализовали сам проект по автогенерации тестов на основе спецификации. И об этом уже во второй части нашей статьи. Она — здесь. |