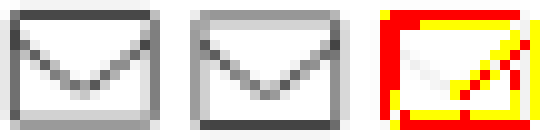Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Азбука ИТНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Python для начинающихНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Инженер по тестированию программного обеспеченияНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
-
Bash: инструменты тестировщикаНачало: 1 октября 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 1 октября 2026
-
Docker: инструменты тестировщикаНачало: 1 октября 2026
-
SQL: Инструменты тестировщикаНачало: 1 октября 2026
-
Git: инструменты тестировщикаНачало: 1 октября 2026
| Как писать визуальные автоматизированные тесты UI при помощи графики, а не сложных локаторов |
| 07.04.2025 00:00 | ||||||||||||||||||||||||
|
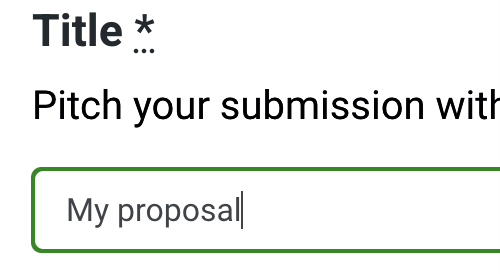
Представьте на минутку, что вы тест-робот, задача которого – тщательно следовать тест-скрипту. Ваша ключевая проблема – это выполнить текстовую инструкцию в графическом интерфейсе пользователя. Если вы тестируете веб-приложения, то ваши инструкции могут выглядеть, как строка CSS – нечто вроде ".posts:n-th(3) button:has(.pencil)." Это можно интерпретировать, как кнопку редактирования третьей записи, но в структуре приложения зависимость более глубокая. Разработчики часто предпочитают текстовые описания, создавая юнит-тесты. Они неявно проверяют однородность наименования элементов на любимом веб-разработкой языке программирования. Проблемы начинаются, когда разрыв между разработчиками и тестировщиками увеличивается. Представьте, что вы тестируете интеграцию ряда приложений – наверное, не стоит полагаться на идентификационную схему каждого участника. Вы хотите, чтобы компьютер говорил на вашем языке, а не наоборот. Самый простой способ показать, чего вы ожидаете от приложения – это скриншот. Это позволит быстро верифицировать тестируемую фичу. Сообщения об ошибке будут сразу считываться как две различающиеся картинки. Отчеты о падениях будут выглядеть, как зримые артефакты – тестировщики смогут взглянуть на них и исправить, даже не зная внутренней структуры. Вы получите то, что на экране. Поэтому давайте взглянем на тестирование UI на основе графики. Организация изображений Используя изображения в описаниях тестов, мы создаем документ, содержащий как текстовый код, так и встроенные изображения. Когда я писал эту статью, я использовал текстовый редактор, у котором вставить изображение можно без проблем. Просто копируешь и вставляешь. При создании автотестов мне также нужна подсветка синтаксиса и возможность рефакторинга, а они доступны только в чисто текстовых окружениях, не поддерживающих изображения. Когда ваш тест разрастается до тысяч шагов, количество изображений, которые нужно хранить в отдельных файлах, неминуемо возрастает. Почему нужно обязательно выбирать между современной поддержкой кода и встроенными изображениями? Взгляните на последовательность действий, описанную так, как будто она взята из руководства пользователя. Эти шаги теста легко читаются, и там отмечены и нюансы цветовых эффектов при наведении курсора, и цветная рамка вокруг активного элемента.
Рис. 1: Удобочитаемая последовательность тест-шагов, включая интерактивные элементы и графические эффекты. Блок кода ниже показывает, как эти шаги будут выглядеть в Playwright, инструменте автоматизированного тестирования с визуальными возможностями. Схожая картина будет в Cypress и Selenium. Так как реальный код тестов не показывает изображения напрямую, описание теста использует их неоптимально. Однако там есть веб-интерфейс, визуализирующий изображения – он позволяет установить новый эталон, если изменения приняты. Для вызова метода нужно указать название эталонного изображения. Оно будет автоматически создано при первом прогоне теста или изменении эталона. Эталон сохраняется для каждого размера экрана и каждого браузера. Регион сравнения можно сузить, но он должен располагаться в том же участке экрана. Чтобы проверить, соответствует ли текущий экран ранее сохраненной версии, можно воспользоваться командой вроде cy.compareScreenshot.toMatchImageSnapshot(<ваш файл>) в Cypress или expect(page).toHaveScreenshot(<ваш файл>) в Playwright. test('MoT proposal' , async ({ page}) => {
Пример кода 1: Шаги теста со сравнением изображений в Playwright. Фреймворк автоматически сохраняет эталонные изображения при первом прогоне, или если меняется эталон. Активно использовать изображения, описывая выполнение теста, можно в Appium. В экосистеме мобильного тестирования часто требуется кликать по элементам, у которых отсутствуют вменяемые ID или текстовые локаторы. Иногда нужно применять жесты на безымянных областях экрана. Вышеуказанные шаги теста можно написать на Python, используя фреймворк Appium, как показано ниже. Внутри Appium использует метод сравнения шаблонов OpenCV, сканирующий весь скриншот в поиске сохраненных эталонных изображений. Преимущество этого кода в том, что можно искать элементы по их внешнему виду, не нуждаясь в текстовых локаторах. Чтобы это работало, надо самостоятельно заниматься хранением изображений. Это может стать проблемой при больших тестах – нужно поименовать, версионировать и поддерживать актуальность все большего и большего количества картинок. Поиск изображения-локатора не зависит от размера экрана – следовательно, файлы можно использовать для любых типов устройств и размеров экранов, если сам элемент не масштабируется пропорционально доступному пространству. Для поиска элемента вызывается функция find_element – с изображением вместо текстового локатора. driver.find_element(AppiumBy.IMAGE, "images/avatar.png").click() Пример кода 2: Шаги теста, написанные в Appium, и дающие возможность использовать изображения для поиска интерактивных элементов. Это также неявно проверяет их внешний вид. Поиск различийОрганизовав ресурсы, хранящие эталонные изображения, нужно решить, будем ли мы допускать потенциальные отклонения. Мы, люди, понимаем, что значит «одинаковое». Сравнивая два изображения, мы можем сконцентрироваться на важных областях, понять общие концепции центровки, а также локальные различия в правописании и пунктуации. Чтобы у компьютера тоже была такая возможность, понадобится инструмент визуального сравнения. Очевидная идея – порыться в визуальных алгоритмах. К сожалению, результаты вызывают уныние. Что пошло не так? Компьютеры не детерминированы. Может, 30 лет назад они такими и были – тогда ежемесячные обновления безопасности были единственным изменением, а все макеты позиционировались по абсолютным пикселям. Сейчас все не так. При отрисовке постоянно меняется множество слоев. У браузеров выходят новые версии, меняются метрики шрифтов, а операционные системы тестируют новые методы отрисовки, балансируя скорость и точность. Эти постоянные перемены усложняют определение точного эталонного изображения, при совпадении с которым тест должен успешно сработать. Область компьютерного зрения невероятно продвинулась. ИИ превзошел людей в распознавании почерка и ряде других задач по обнаружению объектов. Современные большие языковые модели еще лучше обрабатывают изображения. Растет количество приложений, состояние которых ИИ может определить лишь по скриншоту. Возможно, наступит день, когда изменение разрешений экрана и результирующий пересчет элементов, зависящий от доступного места на экране, будет тестируемым. До сих пор тесты, как правило, требовали фиксированного разрешения, и для разных размеров экранов им нужно было снова сохранять эталоны. Даже при таком ограничении есть большой разрыв между тем, что возможно, и тем, что доступно. Рассмотрим технологические основы существующих решений. Проблема сверки пикселейPixelmatch – это библиотека сравнения изображений, которой по умолчанию пользуются Cypress и Playwright. Ее алгоритм сравнивает изображения попиксельно. Это широко используемая техника, которая выдает схожие с коммерческими инструментами результаты и редко меняется. Appium использует очень похожий OpenCV-метод. В плане артефактов особой разницы между OpenCV и Pixelmatch нет. Это верно и для менее распространенной библиотеки odiff. Она совместима с Playwright и Cypress, но тесты ниже ей тоже не по зубам. В нашем следующем примере рассмотрим две версии иконки конверта. В стандартном разрешении вам понадобится орлиное зрение, чтобы увидеть разницу между ними. Результат сравнения от pixelmatcher показан красным. Разница в 55 пикселей. Сравнение с чисто белым изображением выдаст только 50-пиксельную разницу. Это значит, что слегка смещенный конверт даст больше отклонений, чем полностью отсутствующий. Проблема смещения на полпикселя часто вызвана ошибками округления в динамической верстке вроде сеток CSS. На пиксельном уровне цвета отличаются кардинально, а стоит чуть прищуриться – и для человека они будут абсолютно одинаковыми.
Рис. 2: Библиотека pixelmatcher нашла огромную разницу между изображениями, которую люди при стандартном разрешении не заметят. Следующий пример – противоположный сценарий, когда люди сразу заметят колоссальную разницу, но pixelmatcher ее практически не найдет. Это большая проблема. Стандартный подход к низкой толерантности к отклонениям изображений - это поправить допустимый порог различий. Пример ниже сообщает, что разница всего в 5 пикселей – а на самом деле 8 превратилось в 5. Если это часть скриншота покрупнее – это пройдет незамеченным. Люди тратят годы детства на то, чтобы научиться бояться неточных чисел. Однако pixelmatcher даже не моргнет, если числа не равны.
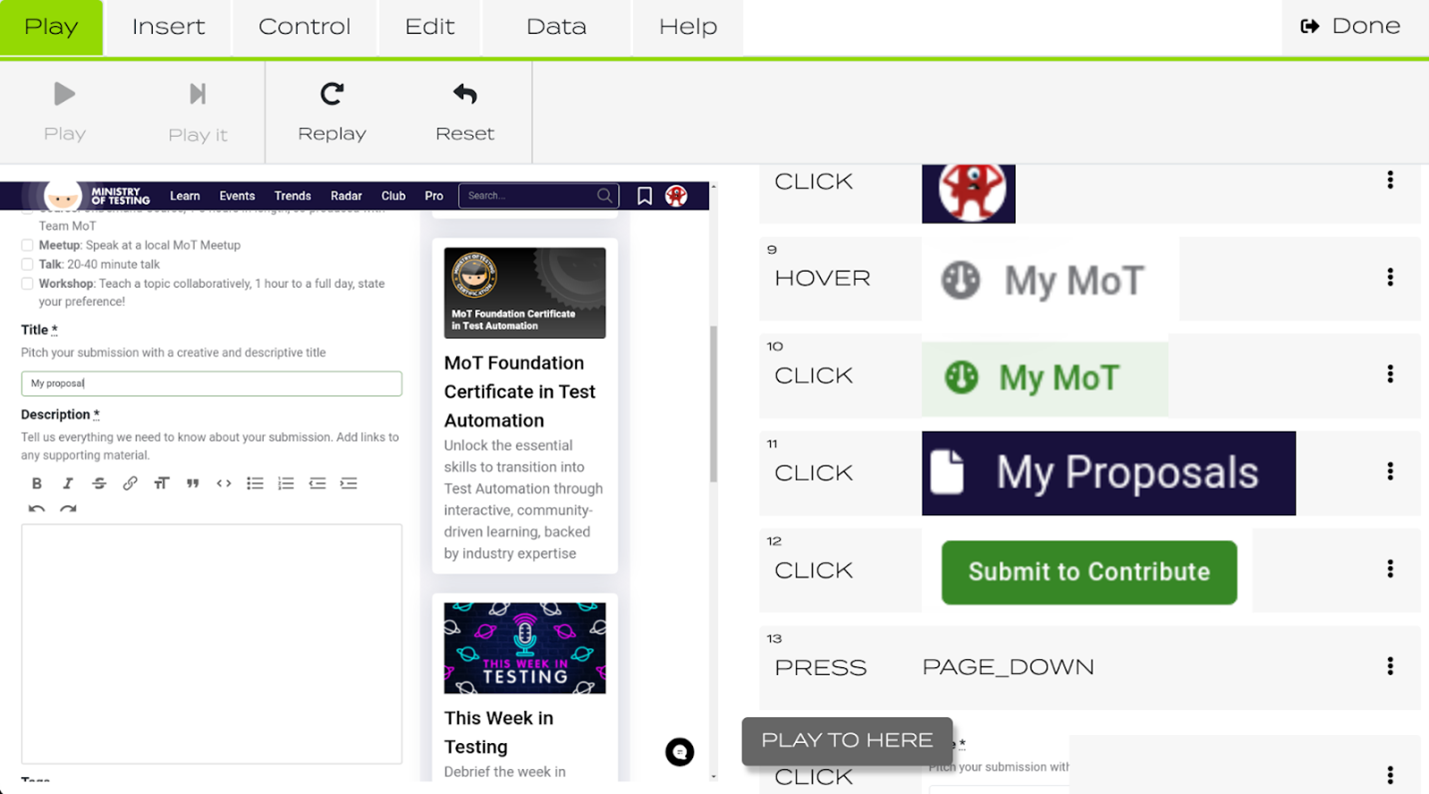
Рис. 3: Библиотека pixelmatcher не понимает важность мелких изменений в пикселях, если это часть важного значения. В отличие от людей, она не умеет концентрироваться на числах, как на важном источнике информации. Подведем итог – ясно, что инструменты с открытым исходным кодом требуют значительных усилий по тонкой настройке, иначе они не дадут достоверных и надежных результатов тестирования изображений. Для людей эта задача была бы элементарной – как минимум при решении проблемы качества сравнения пикселей. Свободно доступные алгоритмы полагаются на очень простые правила и не используют современные достижения компьютерного зрения и ИИ. Для прогресса им надо решить две проблемы одновременно: сравнение изображений должно стать умнее, а организация большой коллекции изображений – гораздо проще управления файловой системой. Коммерческие решенияПрименение визуальных методов в тест-автоматизации можно разделить на пассивные и активные сценарии использования. Пассивное сравнение изображений проверяет только визуальный регресс, не оценивая влияния на выполнение теста. Активное сравнение оценивает возможность продолжать тест на основании вида и расположения элементов на экране. У обоих подходов есть свои преимущества в определенных ситуациях. Пассивный подход позволяет поддерживать текущую логику автоматизации и полагаться на изображения лишь как на дополнительный источник данных. Активный подход полезен, если элементы нельзя описать при помощи текстовых локаторов, что вызвано или неструктурированной отрисовкой, или отсутствием стабильных схем назначения имен. Applitools – лидер рынка инструментов пассивного визуального тестирования. Его алгоритм сравнения изображений обещает применить современный ИИ для определения разницы между картинками. Да, он успешно справится с обоими примерами выше. Естественно, у него есть графический интерфейс, позволяющий изучить и одобрить любые отклонения. Как и прочие фреймворки пассивного визуального тестирования, он запускает тест поверх существующей автоматизации, не требуя перемен в уже имеющихся процедурах. В большинстве коммерческих бескодовых инструментах тест-автоматизации поддерживается активное визуальное тестирование. На то, что изображения – не первое, на что опираются тесты, есть практические причины, несмотря на теоретическую выгоду. Во-первых, операции с изображениями затратны в смысле расчетов. Простые алгоритмы подвержены нестабильности, если сравнение слишком жесткое. Дорогие алгоритмы могут чересчур замедлить тестирование, и поэтому берегутся для исключительных случаев. К примеру, Katalon Studio может использовать изображения, ссылаясь на файл с изображением, но пользователи должны самостоятельно организовать эти файлы в системе. Tricentis Tosca поддерживает изображения в качестве сигналов для взаимодействия, но пользователям нужно прокликать несколько всплывающих окон, чтобы создать, а затем увидеть или обновить изображение.
Рис. 4: Пользовательский интерфейс бескодового инструмента тест-автоматизации testup.io полностью сконцентрирован на изображениях для определения точек взаимодействия. На изображении выше – скриншот testup.io, нишевого поставщика услуг тест-автоматизации. Он полностью построен вокруг концепции изображений, определяющих объекты. Все точки взаимодействия задаются относительно визуальных маркеров. Это делает тест читабельнее, но также ограничивает его графическими взаимодействиями. ЗаключениеВ статье обсуждалось пассивное и активное применение изображений в тест-автоматизации. При пассивном сценарии использования проверяются визуальные изменения в дополнение к в остальном самодостаточной тест-процедуре. Бесплатные инструменты зачастую чересчур чувствительны к артефактам отрисовки или требуют сложной настройки толерантности – удовлетворительного решения тут нет. Этой области нужно крупно обновляться, потому что современные ИИ-инструменты помогут решить их проблемы. Потенциальная выгода тут огромна. Тест-скрипты будут в основном состоять из изображений и читаться, как комикс. Ошибки всегда будут выглядеть, как различия между изображениями, а ресурсами тестов можно будет пользоваться для разных типов устройств. Сейчас это довольно скромно поддерживается, особенно для бесплатных инструментов. Активный сценарий использования поддерживается бесплатным фреймворком Appium для мобильного тестирования. Подход позволяет взаимодействовать с участками экрана, у которых нет внутренних идентификаторов, или же их текстовые локаторы сложно найти. Проблема этого подхода, помимо нестабильного сравнения изображений, в организации изображений в файловой системе. Тест-определения растягиваются на несколько файлов, и их трудно читать и поддерживать. Поддержка изображений у коммерческих бескодовых инструментов посильнее. Это дает преимущество менее подкованным технически пользователям – им проще понять источник ошибок, увидев его своими глазами. |