Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Азбука ИТНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Python для начинающихНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Инженер по тестированию программного обеспеченияНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
-
Bash: инструменты тестировщикаНачало: 1 октября 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 1 октября 2026
-
Docker: инструменты тестировщикаНачало: 1 октября 2026
-
SQL: Инструменты тестировщикаНачало: 1 октября 2026
-
Git: инструменты тестировщикаНачало: 1 октября 2026
| Создание самовосстанавливающихся автоматизированных тестов с ИИ и Playwright |
| 12.03.2025 00:00 |
|
Автор: Шрай Шарма (Shray Sharma) ВведениеТест-автоматизация жизненно важна для результативного тестирования ПО в постоянно меняющихся условиях. Создание тест-автоматизации для непрерывной разработки – приоритет большинства компаний, располагающих отдельными командами обеспечения качества. Меня часто спрашивают, как снизить затраты времени и сил на поддержку тест-автоматизации. Правда, здорово бы было вообще избавиться от этой поддержки, или хотя бы максимально ее сократить? Возможно ли это? Да, возможно! Эта статья о том, как совместить Playwright, библиотеку тест-автоматизации с открытым исходным кодом, с языковыми моделями ИИ вроде Groq, Llama и Mistral, чтобы:
Что предлагает ИИ для оптимизации тест-автоматизации?
Тест-автоматизация – это теперь стандарт в тестировании. Одна из целей хорошей тест-автоматизации – это снижение необходимости вмешательства человека и поддержки. На практике так не бывает. Как только скрипты автоматизации написаны, их требуется регулярно поддерживать, что приводит к дополнительным задачам, отнимающим время у необходимых проекту разработки и тестирования. Тут в игру и вступает ИИ. Интеграция языковых ИИ-моделей с Playwright может создать мощный самовосстанавливающийся фреймворк. Надежная интеграция позволяет языковым моделям использовать разнообразные возможности инструментов тест-автоматизации вроде Playwright не только для верификации кода, но и для взаимодействия с текущим состоянием браузера. Эти стратегии дают моделям богатый контекст, а в результате точность их предложений увеличивается. Преимущества интеграции:
Работа с языковыми моделями: максимизация преимуществ и решение распространенных проблемЯзыковые модели дают значительные преимущества тем, кто пытается разрешить проблемы поддержки тест-автоматизации. Инженерам-автоматизаторам модели предлагают:
И в конце концов эти мощные возможности можно скомбинировать в самовосстанавливающееся решение для тест-автоматизации. Однако для разработки качественного решения нужно справиться с рядом распространенных проблем языковых моделей. Устаревшая информацияПроблемаВы можете изо всех сил стараться обучать вашу модель, используя последние данные из репозиториев. Однако эти данные со временем устаревают. К примеру, вашей автоматизации может требоваться последняя версия Java, а модель знает только о более старой версии. Возможные решенияРегулярное переобучение языковых моделей:
Интеграция с активными источниками данных:
Гибридные подходы:
Как мы справились с проблемой устаревших данныхСм. раздел с подробным обзором ниже. ГаллюцинацииПроблемаЕсли результат работы языковой модели неверен или не имеет смысла, это называют галлюцинацией. Это происходит, когда модель предсказывает что-то невалидное и не имеющее значения в конкретном контексте. Возможные решенияЧтобы справиться с галлюцинациями, можно добавить высококачественные данные, использовать инжиниринг подсказок с учетом контекста, и тонко настроить модель под конкретную доменную область. Можно также создать службу верификации, которая осуществит возвратный вызов модели, чтобы исправить проблему. Как мы с этим справилисьСм. раздел с подробным обзором ниже. Длительное ожидание ответаПроблемаЭто время, которое модель затрачивает на обработку запроса и генерацию ответа. Длительное ожидание ответа может выматывать, ограничивая полезность и простоту ассимиляции языковой модели в процессы высокого темпа. Модели ресурсозатратны, но самовосстанавливающаяся автоматизация требует быстрых ответов. Возможные решенияОптимизация производительности модели:
Улучшение железа и инфраструктуры:
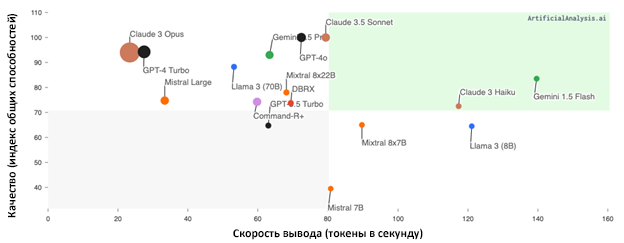
Как мы с этим справилисьНаше решение не требовало большой языковой модели. Поэтому мы выбирали скоростные модели от Mistral, Llama и Groq. В частности, у Groq есть компонент логического вывода с автоматическим выключателем нагрузки, что снижает энергозатратность нашего решения. На графике сравнение времени ответа и качества ответа различных языковых моделей.
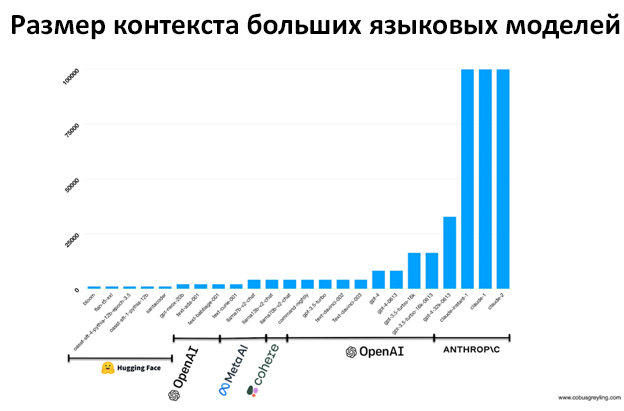
Источник: https://artificialanalysis.ai/models См. также раздел с подробным обзором ниже. Низкое качество ответа из-за ограничений контекстаПроблема«Длина контекста» относится к объему текста или кода, который модель способна распознать за раз. Адекватный размер контекста, или «контекстное окно», критически важен для генерации правильных ответов. Нам нужна возможность предоставлять достаточно контекста, чтобы модель приняла наилучшее из возможных решение. Ограниченная длина контекста может привести к менее точным или неполным предположениям, так как у модели нет доступа ко всей необходимой для принятия информированного решения информации. Возможные решенияСтратегии управления контекстом:
Источник: www.cobusgreyling.com Это значит, что для расширения контекстного окна управляемым способом нужно улучшать возможности железа. Как мы с этим справилисьСм. раздел с подробным обзором ниже. Наше решение: подробный обзорКакой поддержкой наше решение занимается самостоятельно?1. На первом уровне упавшие тесты проверяются языковой моделью, исправления тоже вносит она. 2. Изменения в кейсах автоматически адаптируются в тест-скрипты. Что еще требует вмешательства человека?
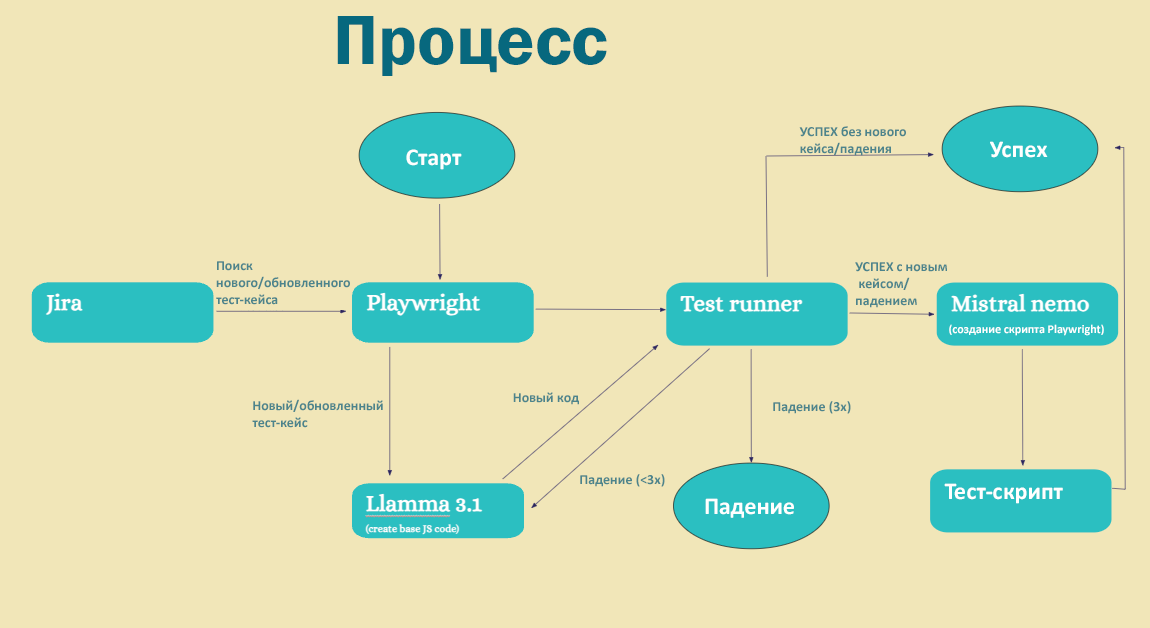
Краткий обзор нашего решения
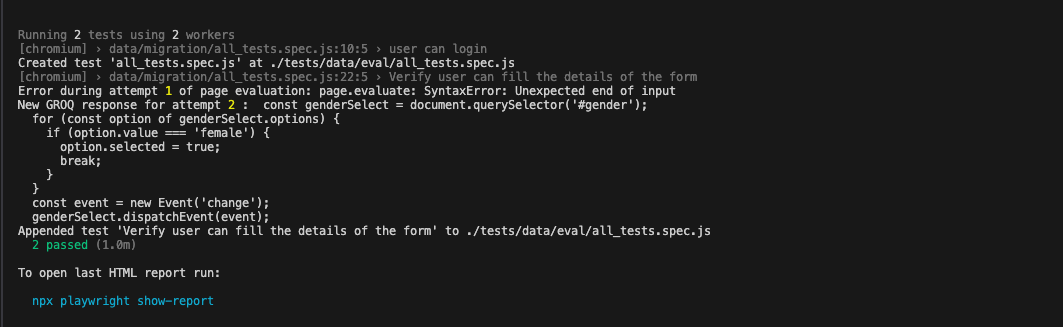
1. Наши кейсы живут в Jira, и мы используем Zephyr Scale для управления тестами. При появлении новых или изменении существующих кейсов наше решение загружает их в локальное хранилище кейсов. 2. Затем Playwright координируется с Llama для генерации нужного Javascript. Система запуска тестов Playwright проверяет сгенерированный код. 3. Если эта система выдает ошибку, модель правит код, а тесты заново запускаются, максимум три раза. 4. Если сгенерированный код сработал успешно, он отправляется в Mistral, где конвертируется в скрипт Playwright. Новый код добавляется в файл тест-скрипта. 5. Предположим, что тест-скрипт актуален: если кейс падает в ходе прогона или верификации, Llama вызывается для верификации кода и понимания проблемы. Затем Llama исправляет код и отправляет тест в систему запуска для нового прогона. Если обновленный тест падает три раза подряд, процесс останавливается. 6. Если Llama не может исправить проблему после трех прогонов, то причина, возможно, в реальном баге продукта. Чтобы не тратить силы зря, Llama останавливает прогон и выдает ошибку упавшего кейса, чтобы пользователь мог с этим разобраться. Все падения и успешные срабатывания пишутся в Playwright, как при обычном прогоне. 7. После исправления кода новый скрипт заменяет предыдущий. Пришло время демонстрацииПожалуйста, посмотрите видео нашей реализации с ее пояснением. Если вам нужны субтитры, их можно включить в YouTube. Ниже я опишу решение подробнее. Что конкретно мы показываем?Один из самых впечатляющих аспектов демонстрации – это бесшовное взаимодействие языковых моделей с Playwright. Каждый инструмент задействует возможности другого, чтобы добиться оптимальных результатов. Языковые модели могут исправлять код при наличии невалидных ответов. Языковые модели анализируют тестовый скрипт, выявляют невалидные ответы и генерируют правильный код, чтобы исправить проблемы. Это динамическое взаимодействие демонстрирует потенциал для верификации и исправления кода, что снижает необходимость ручного вмешательства. На скриншоте ниже можно видеть, что языковая модель попыталась сгенерировать исправление, но при следующем прогоне тест остался неверным. Со второй попытки исправления кода тест прошел успешно, и код был принят.
Контекстное окно позволяет за раз прогонять только один кейсДругое важное наблюдение – ограничения, вызванные контекстными особенностями. Языковые модели с трудом справлялись с более чем двумя кейсами одновременно из-за ограничения длины контекста и пропускной способности. Поэтому мы разбираемся с кейсами последовательно, а не параллельно. Это можно улучшить, добавив мощностей для моделей с более крупными контекстными окнами. Но пока что реализация соответствует пропускной способности модели. Время ответа ограничено оборудованиемДемонстрация также дает понять, как ограничения оборудования влияют на производительность интегрированной системы. Инструментам понадобилась примерно минута, чтобы выявить проблемы и сгенерировать правильный код. Время ответа, хоть и приемлемое, можно значительно улучшить, улучшая оборудование. Как мы справлялись с распространенными проблемами ИИРанее в статье я описал распространенные проблемы ИИ и их возможные решения. Вот как с ними справлялись мы. Замена устаревших данныхОдной из проблем, с которыми мы столкнулись, была загрузка динамических компонентов во время прогона. Мы можем получить структуру DOM из кода в фоновом режиме, но в этом случае в ней будут отсутствовать динамические компоненты, загружающиеся во время работы, и в результате языковая модель будет реагировать на устаревшие данные. У инструментов тест-автоматизации есть информация о текущей структуре DOM – это наиболее актуальное состояние данных. Поэтому мы воспользовались возможностью Playwright извлекать текущую структуру DOM, а затем передавали ее в языковую модель с каждым запросом. const PageDOMBody = await pageDOM('body').html();
Сокращение галлюцинацийДля борьбы с проблемой галлюцинаций мы внедрили систему верификации, которая основана на возможности Playwright независимо запускать сгенерированный JavaScript-код. Мы также использовали на всю катушку возможности моделей, связанные с анализом кода, генерацией предложений и обнаружением ошибок. Мы установили максимальное количество попыток исправления – 3. Обычно модель отлавливает галлюцинации за три попытки. Если проблема сохраняется – это, возможно, баг в коде продукта, или же что-то, о чем модели не хватает информации. async function evaluateGroqCall(userInput,PageDOMBody,page){
Оптимизация времени ответаЕсли взять модели вроде OpenAI, то время ответа будет в пределах 2-3 секунд. Но нам нужно было решение побыстрее. Мы выбрали Mistral и Llama с GROQ, и стандартное время ответа измеряется в миллисекундах. Настройка подходящего объема контекстаКонтекстное окно у моделей вроде OpenAI – примерно 28 тысяч токенов, но так как наш контекст достигал 30 тысяч, нам нужна была способная на такое модель. Для решения этой проблемы мы вычислили средний размер нашей DOM – примерно 20-30 тысяч токенов максимально. Это побудило нас выбрать модель Llama's llama-3.1-8b-instant – она может обрабатывать 150 тысяч токенов в минуту, что гарантирует безопасную работу. Проще говоря, мы внедрили расширение контекстного окна, выбрав модель, способную работать с более крупным контекстом – при этом крупным ровно настолько, насколько нам нужно: модель Llama's llama-3.1-8b-instant. Как адаптировать наше решение к вашему окружениюФреймворк тест-автоматизацииУ Playwright есть функция page.evaluate(), запускающая сгенерированный языковыми моделями код. Для тех же результатов можно использовать любой инструмент. Playwright: result = await page.evaluate(groqResponse); В Selenium, используя execute_script: result=driver.execute_script(script,*args) В Cypress: cy.window().then((win) => {
Мы не ограничены каким-то конкретным инструментом автоматизации – мы просто пользуемся им, как средством запуска тестового кода, сгенерированного языковыми моделями. Языковые модели и хостингВ текущей реализации используются Llama и Mistral. Llama генерирует скрипты Playwright, а Mistral генерирует код JavaScript, который внедряется в функциональность запуска скриптов Playwright. Обе модели размещены в GROQ, что дает высокую производительность и быстрые результаты. Выберите любую нравящуюся вам модель: https://console.groq.com/docs/quickstart. При желании можно даже разместить там свою собственную. Что ждет наше решение в будущем?В будущем мы планируем исследовать другие модели, способные управляться с большим контекстом и быстрее реагирующие. К тому же по мере роста контекстного окна мы можем создавать тест-кейсы с языковыми моделями, которые знают наше решение во всей полноте, что позволит автоматизировать процесс полностью. |