Что пишут в блогах
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Python для начинающихНачало: 23 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Азбука ИТНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
| Как мы прикрутили прокси к автотестам |
| 28.10.2024 00:00 |
|
Автор: Пронин Дмитрий, Иви (AQA-lead клиентского тестирования) Привет! Мы в онлайн-кинотеатре Иви любим писать автотесты, особенно клиентские (Потому-что клиентские приложения - это первое, а иногда и единственное, что видят наши пользователи). У нас 4 основных платформы - Android, Web, Smarttv, iOS (Android и iOS - еще подразделяются на мобильную и tv версии). И немного про сами автотесты. В основном все они интеграционные. Мы используем почти полные копии бэка, автоматически разворачиваемые в k8s (об этом как-нибудь потом). Общее количество стремится к 7 тысячам, а среднее количество на одну платформу - к полутора. Особенность всей этой конструкции состоит в том, что мы максимально стремимся к использованию нативных фреймворков или к использованию того стэка, который лучше всего подойдет для поддержки проекта. Это заставляет агрессивно выделять общий функционал, избавляться от копипасты и держать архитектуру и подходы как можно более похожими от проекта к проекту. При таком подходе одной из основных проблем, с которой столкнулись - это работа с сетевым стэком. Первое, это конечно же, моки - поддерживать моки на все запросы может быть весьма затруднительно:
Вторая немаловажная проблема при клиентском тестировании - это то, что далеко не всегда мы можем проверить результат работы клиента на бэке "прямо сейчас". Для какой-нибудь покупки, или добавления в избранное мы можем проверить, что изменения произошли, и они корректны (можно найти свежую покупку на бэке или сходить через клиент в раздел покупок и обнаружить там искомое), но, помимо проверки простых сценариев у нас есть еще и проверки статистики. Статистика - это большое количество запросов, которые приложение шлет во время работы, и самая большая засада в том, что проверить то, что они отправлены корректно во время работы теста на стороне бэка мы никак не можем, или это очень трудозатратно. Таким образом - все проверки сводятся к тому, что нам нужно слазить в сетевой лог и посмотреть, что же отправило приложение, и в 99% случаев важен не только факт отправки, но и данные, которые были посланы. А отказаться от этих проверок мы не можем, так как:
Первая итерацияИтак, имея перед собой весь этот багаж проблем, мы начали искать решение. Для web платформ (web и smarttv) можно попробовать манипулировать сетевыми запросами через devtools. А для мобильных платформ такого инструмента найти не удалось. Значит придется внедрять что-то стороннее. Какие у нас требования:
Из всего многообразия инструментов, одним из самых популярных является mitmproxy. Она умеет все, что нам нужно:
Чего нам не хватало для запуска:
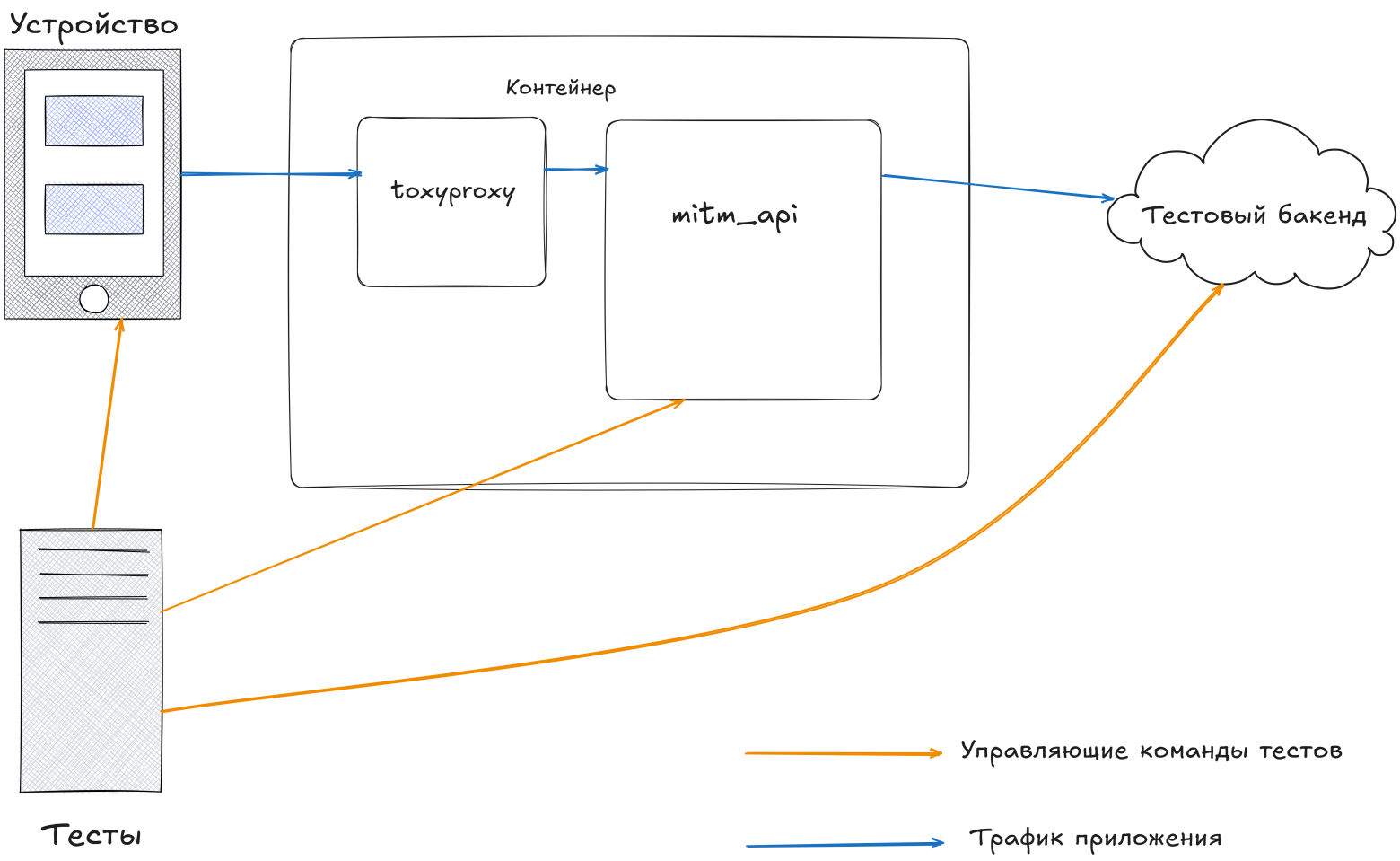
Допиливаем mitmproxyВообще говоря - это конструктор. Есть ядро, которое отвечает за низкоуровневую работу с сетью, а весь остальной функционал добавляется путем комбинирования аддонов (на сами аддоны можно посмотреть в коде проекта). Происходит это в классах, наследуемых от master. Значит, наша первоочередная задача - собрать минимальную рабочую сборку из "родных" и самописных аддонов и научиться всем этим управлять удаленно. Частично вдохновившись принципами работы mountebank и WireMock мы решили, что самое простое и эффективное решение, это прикрутить api к проксе и дальше уже общаться с ним. Что должно уметь API:
В итоге после нескольких кругов POST - задать мок DELETE - удалить мок POST - почистить моки GET - получаем логи в формате har POST - добавить хост DELETE - удалить POST - добавить редирект по хосту. ( например api.contoso.com -> api.test.contoso.com) POST - более сложный редирект, когда у какого-то сервиса, или стороннего инструмента отличается еще и url например POST - Убивать запросы, идущие на конкретный хост POST - полностью очистить все данные из прокси POST - метод для проведения манипуляций с заголовками. (Есть определенные сценарии, в которых нужно добавлять или удалять заголовки) Да, схема не очень красивая, и требует причесывания, но это не особо мешает, а самыми ходовыми методами являются - добавление мока и получение har, задание редиректов по хосту и включение отслеживания этих самых хостов. Остальные - используются очень редко. Получившуюся конструкцию мы назвали mitm_api (креативно, оригинально) и принялись прикручивать к тестам. Причем тут WebSocketВсе было бы с проксей хорошо, но есть один немаловажный нюанс. У нас куча сценариев с шагами вида "после действия n отправился запрос y" . Самый простой вариант - это пулить метод для получения логов и смотреть - появилось ли чего нового или нет, НО... метод относительно ресурсоемкий + добавляются задержки, связанные с тем, что между перезапросами надо делать какую-то паузу (классическая проблема явных и неявных ожиданий). Как можно решить данную проблему - каким-то образом добавить поток нотификаций. Самое простое и обкатанное решение - WebSocket. Для нас у него куча плюсов:
Да вот собственно и все. Поднимаем в мастере WebSocket, добавляем метод для добавления туда сообщения и все - теперь мы можем из любого аддона через глобальную переменную ctx обратиться к мастеру и раздать клиентам сообщения. Данная техника позволила реализовать надежные проверки отправки сетевых запросов после определенных действий. А некоторые команды перешли на режим работы, когда полный лог не запрашивается вовсе. Просто в начале теста мы подключаемся к вебсокету и держим соединение, сохраняя прилетевшие запросы. Портим трафикИ вот у нас все хорошо, мы мониторим запросы, делаем моки, сохраняем логи запросов. И тут приходят мобильные клиенты и команда плеера, и начинают показывать - что у нас есть еще и сценарии, где нужно замедлить скорость, внести какую-то потерю пакетов, вообщем максимально точно воспроизвести час пик в метро. Первое, что мы сделали - это добавили задержки запросам средствами mitmproxy (просто ждем заданное время, прежде чем начать посылать ответ клиенту). Часть вопросов это решило (сценарии, когда, условно, нужно вызвать лоадер, и мы точно знаем, что во время этого происходит). Но есть еще и сценарии, где нужно замедлить не 1, а много запросов - например, во время воспроизведения видео. Ставить какие-то задержки на кучу запросов неудобно, да и не получается, да и задержка эта не совсем честная - коннект просто висит пустой, а затем ему на полной скорости отдаются данные. Для проверок, связанных с видео, нужно именно замедлить скорость. В функционале mitmproxy напрямую мы таких возможностей не нашли (да и реализовывать их было не настолько удобно - пришлось бы лезть глубже в ядро, а этого не хотелось). Зато нашелся отличный инструмент от Shopify - toxiproxy, вот он как-раз позволяет "честно" различными способами подпортить сетевое соединение, что дает искомый результат. Но как подружить это все вместе? Ответ простой - нужно отступится от красивого решения "1 контейнер - 1 процесс" и запускать как корневой процесс supervisor , а в нем уже toxyproxy и mitm_api. Таким образом количество торчащих из контейнера ручек еще увеличилось (еще и api для toxyproxy торчит, его мы оставили как есть). А схема теперь выглядит так - клиент в качестве прокси использует адрес toxyproxy, которая в свою очередь ретранслирует это все в mitm_api. Была идея toxyproxy перед бэкендом, но от нее мы отказались - есть шанс, что если затормозить сеть перед mitm, то в части сценариeв оно просто будет буферизовать ответ, а потом отдавать и мы вернемся к тому, от чего пытались уйти.
Теперь поговорим о том, как нам этой проксей управлять. Для этого подумаем, что нам нужно:
Данные требования добавлялись постепенно и у нас получилась вот такая модель:
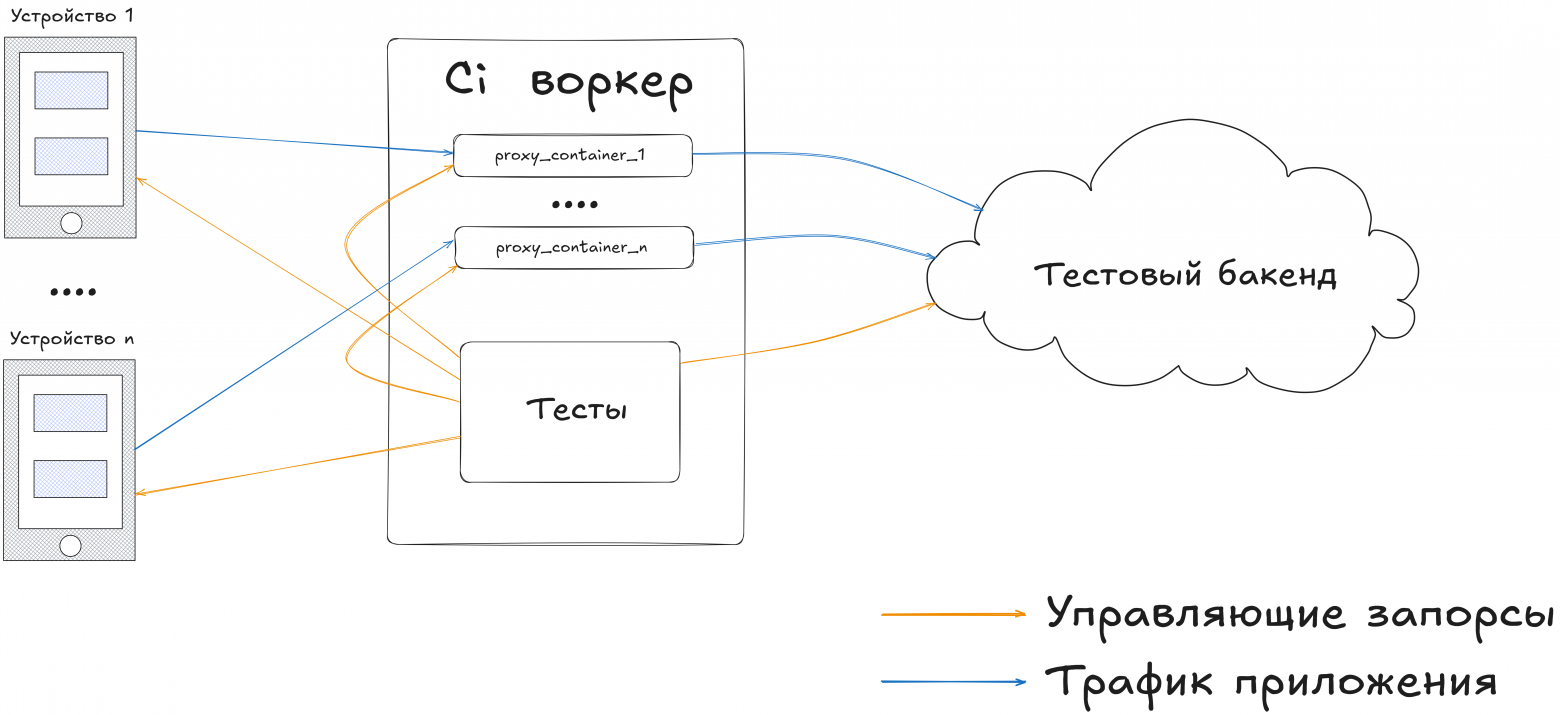
Прикручивание колеса к велосипедуС проксей более-менее разобрались (допилили аддоны, сделали дополнительный мастер на основе WebMaster (там уже прикручен tornado, поэтому не надо сильно выдумывать с вебсервером), теперь нужно как-то сдружить все это с тестами. При первом подходе было решено сделать так - в аддонах к проксе ввести понятие "сессия" и каким-то образом (уже надежно и продуманно) передавать эту сессию через клиента. На веб клиентах все прошло относительно прилично (с помощью нехитрых манипуляций с nginx и заголовками referrer Следующим шагом стал такой механизм - в начале тестов мы точно знаем, сколько у нас будет потоков, поэтому можем поднять определенное количество докер образов, сделав маппинг портов со сдвигом, а затем в каждом тесте, зная условный "номер" воркера, вычислять эти порты и коннектиться к ним. Портов у нас несколько - один для апи, второй для самой прокси и несколько служебных, поэтому появляется логика с вычислением каждого из них. Скейлим колесаПожив какое-то время с такой схемой мы поняли, что:
Имея перед глазами качественные и надежные решения типа selenoid ответ напросился сам собой - надо сделать свой селеноид, только для прокси. А что нам нужно от этого сервиса:
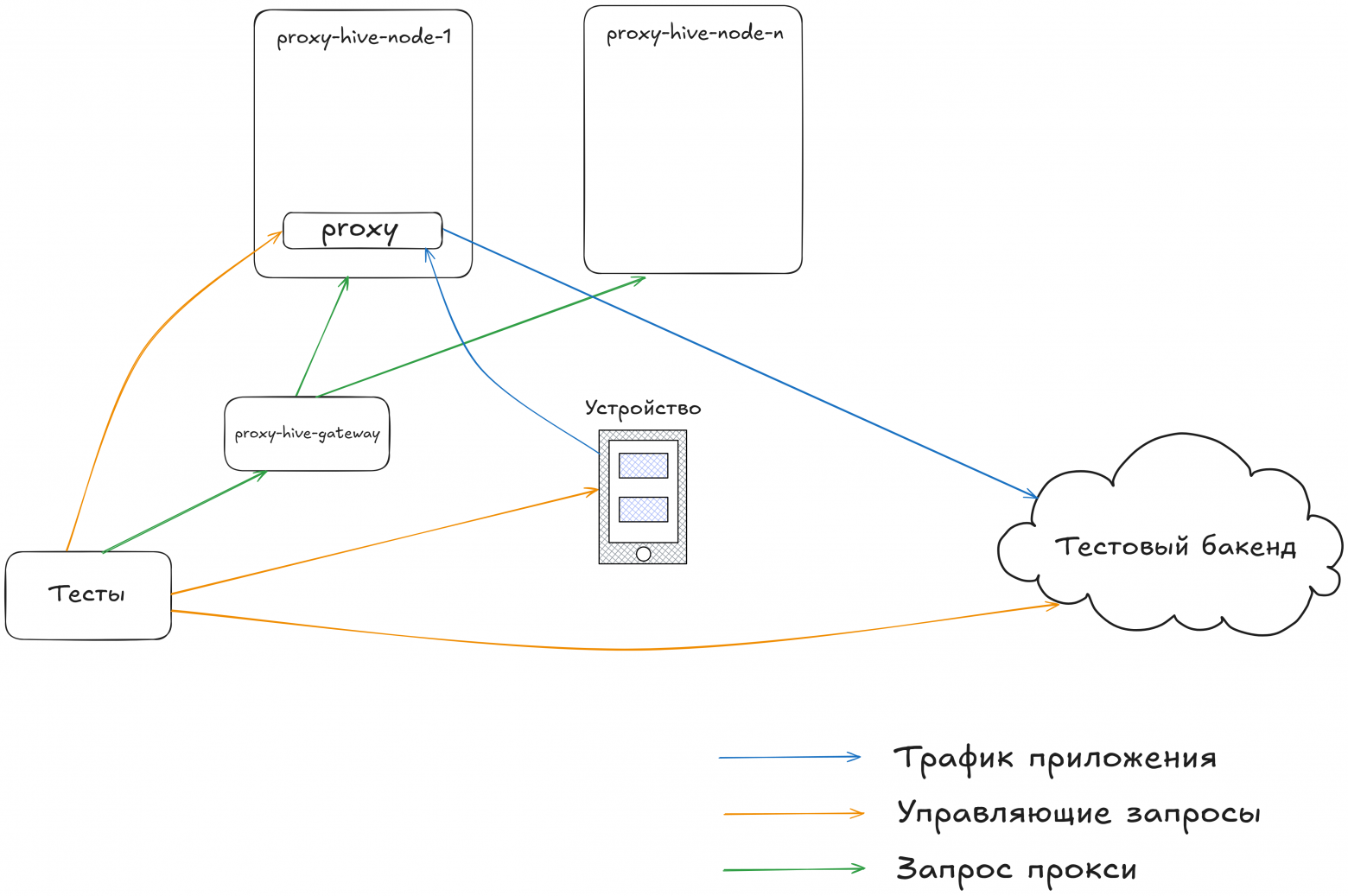
В итоге родился еще один проект proxy-hive, который может запускаться в 2 режимах - хостовом (через апи докера запускает и убивает контейнеры) и режиме балансира (Round-robin выбирает хост из списка и проксирует на него запрос, добавляя дополнительные данные, чтобы при следующем обращении понять, на какую тачку проксировать). Данные о хосте и прокси сводятся к тому, что в режиме хоста каждой проксе выдается рандомный guid, по которому можно определить в каком "слоте" (наборе портов) данная прокси запущена и вытащить id контейнера. А в режиме балансира - имена хостов кодируются в SHA1 (Version 5) UUID информация и все это конкатенируется в 1 строковый id (клиенту парсить это все не надо, а мы получаем простую в реализации и понимании систему). Следует отметить, что к проксям мы ходим напрямую (в отличии, например, от селеноида) т.к. реализация tcp проксирования:
После того, как мы все это внедрили - получили следующую картину. При старте каждого теста он сам себе запрашивает прокси, устанавливает ее в клиента, а в конце убивает, сохраняя все логи (и har и логи самого контейнера) в отчет allure. Схема получилась достаточно удачная (на наш взгляд), а об успехе свидетельствует тот факт, что иногда новички, или те, кто просто хочет начать заниматься автотестами не обращают внимания на то, как устроена работа с сетью. У них просто есть набор методов для получения запросов и установки моков.
Следующие шагиВсе ли мы реализовали, что хотели? Нет! Основное желание - научиться записывать и воспроизводить трафик для каждого теста в отдельности (хочется, чтобы была возможность отказаться от необходимости обращаться к бэку, или, как минимум, свести обращения к минимуму во время некоторых прогонов). Частично mitmproxy умеет записывать и воспроизводить дампы, но есть определенный набор проблем, которые мы сейчас решаем:
На данный момент 1 из клиентов гоняет дампы в тестовом режиме и имеет success rate порядка 80% против 98-99%% если использовать настоящий бэкенд. ЗаключениеПомогает ли нам данная конструкция - безусловно. Благодаря ей мы:
Всем ли проектам автотестов нужны такие сложные и затратные в поддержке и настройки инфраструктуры решения - нет. Если тестов не слишком много, и половина запросов не является fire-and-forget, не приходится проверять запросы от сторонних библиотек, которые не поддаются настройке (всегда ходят в зашитый url), то в целом хватит и wiremock развернутого рядом с автотестами. |