Что пишут в блогах
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Python для начинающихНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Азбука ИТНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
| Экскурс в «святая святых» ОК: как мы пишем и ревьюим код автотестов |
| 14.08.2024 00:00 |
|
На тестирование приходится значительная доля от общего времени разработки продукта или его отдельных фичей. Поэтому компании, стремясь оптимизировать эти процессы, и сократить ручную работу инженеров по обеспечению качества, занимаются автоматизацией тестирования. Но просто написать автотест — недостаточно. Надо, чтобы он был качественным и стабильным. И гарантировать это можно только тщательным ревью кода автотестов. Делимся опытом работы с автотестами в ОК: от подходов к постановке задач до схемы настройки окружения статического анализатора кода. Материал подготовлен по мотивам доклада руководителя команды автоматизации тестирования ОК Эмилии Куцаревой и младшего инженера по автоматизации тестирования соцсети Евгения Буровникова на ИТ-конференции «Стачка». Немного контекста: автотесты в ОК ОК — одна из самых популярных социальных сетей в рунете, которая представлена на всех возможных платформах (web, mobile web, API, android, iOS). Наш продукт высоконагружен, имеет сложный бэкенд и сотни сервисов. Например, у него «под капотом»: 50 тысяч Docker-контейнеров, 1 эксабайт данных и обработка данных в 7 дата-центрах. Чтобы быть уверенными в том, что такой большой и сложный механизм работает стабильно и прогнозируемо, мы стараемся обеспечить необходимое и достаточное покрытие тестами. А чтобы увеличить скорость релиза продукта и уменьшить нагрузку на специалистов — стараемся максимально заменить ручные тесты автотестами. Так, сейчас у нас более 10 тысяч автотестов:
При этом у нас всего около 50 человек в командах обеспечения качества и автоматизации тестирования. Такое соотношение количества тестировщиков к количеству автотестов задает высокие требования к качеству их написания — нам важно, чтобы с таким массивом автотестов можно было справиться доступными ресурсами команд. Поэтому мы выстраиваем эффективные процессы и используем различные инструменты для автоматизации работы. Теперь обо всем последовательно и подробно. Постановка задач на автотестыМы покрываем автотестами значительную часть нашего продукта — так мы получаем максимум контроля и прозрачности в мониторинге состояния собственных сервисов. Поэтому нам важно, чтобы для каждой выпускаемой и используемой фичи на соответствующем для этого этапе писались автотесты. Чтобы технический долг на покрытие автоматизации у нас был регламентирован, все задачи на автотесты создаются в Jira и также проходят свой workflow. Задачи на покрытие автотестам или их исправление создаются из разных источников.
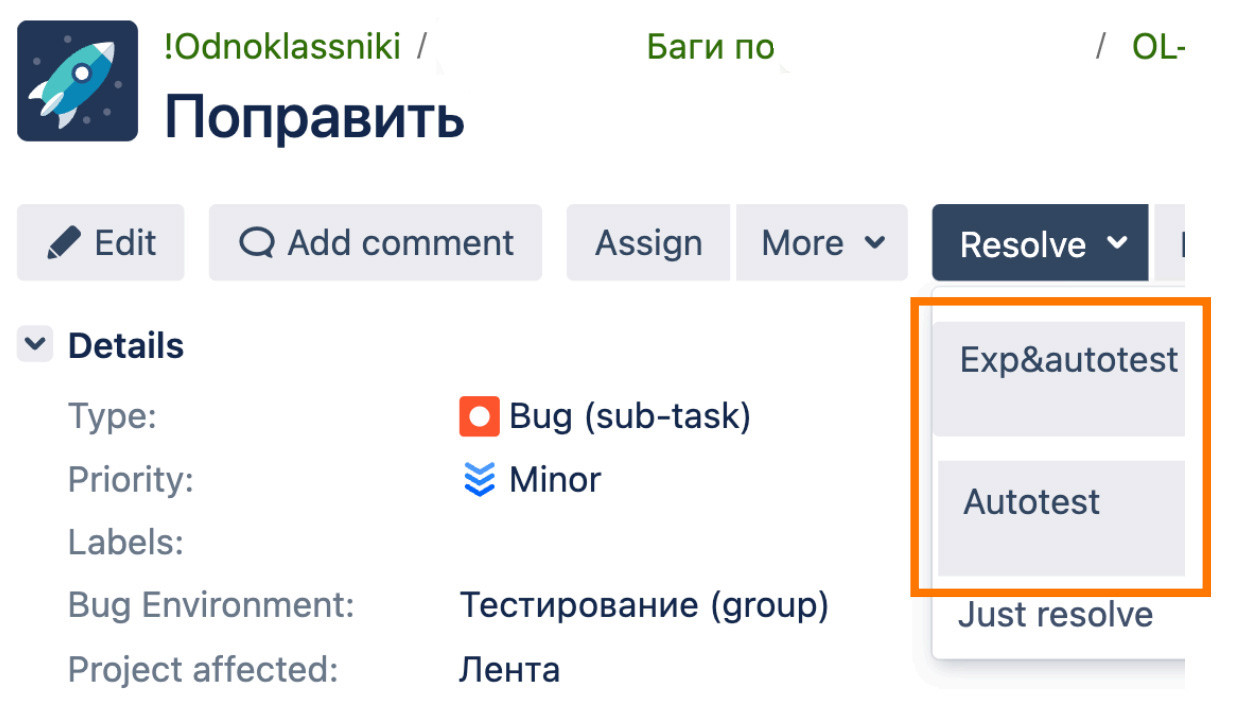
Причем из Jira, помимо основных операций с задачей, сразу можно создать задачу на эксперимент и автотест или просто автотест. Таким образом процесс можно настроить под нужды продукта.
Двухуровневое ревьюУ нас в ОК принята практика двухуровневого ревью кода автотестов. Мы внедрили её в Jira и Bitbucket. Двухуровневое ревью в JiraДля наших web, mobile web и API-платформ ревью состоит из двух этапов.
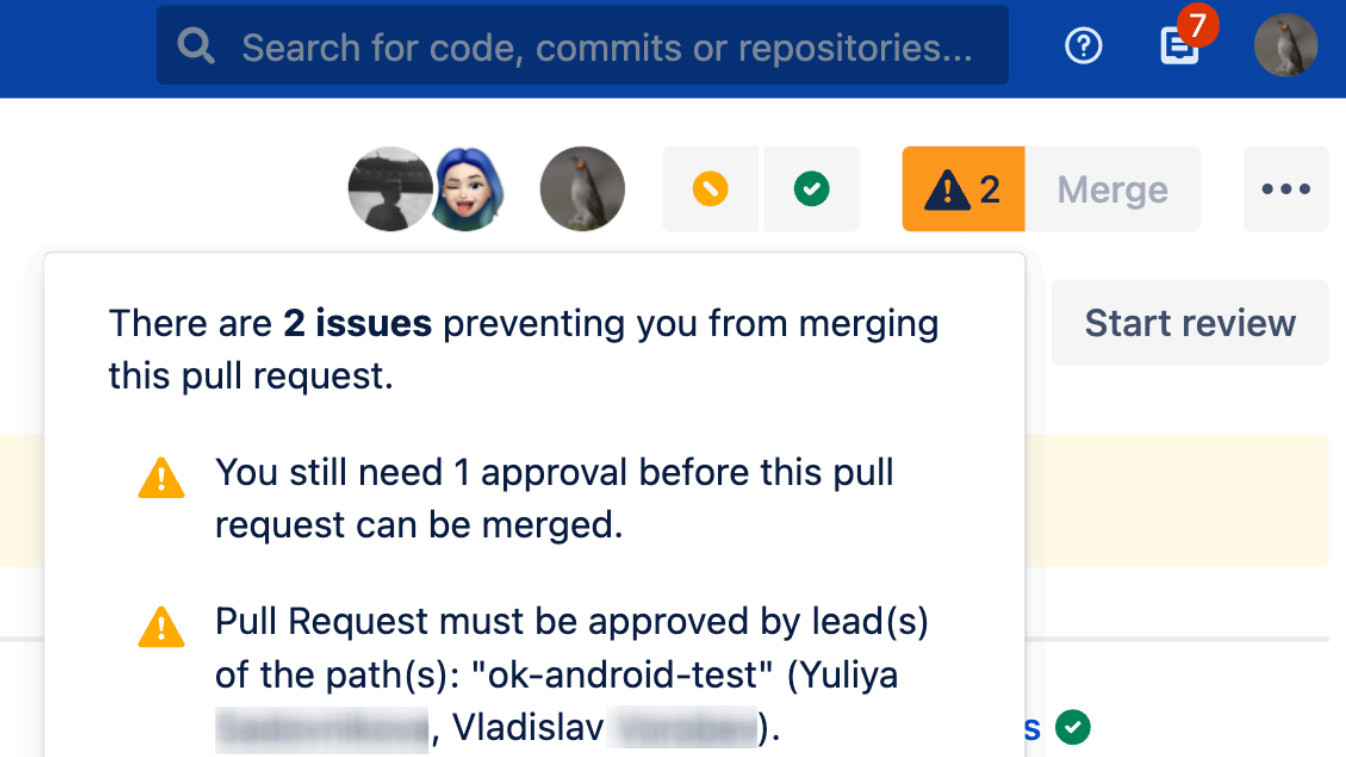
То есть здесь мы задействуем связку ревьюеров, которая не только имеет высокую экспертизу в автотестах, но и глубоко погружена в суть проверяемых фичей, понимает причину выбора в пользу той или иной реализации. При этом у нас есть отдельная группа ревьюеров в Jira, на которых скрипт автоматически распределяет задачи с учетом текущей загрузки. Таким образом, мы реализовываем ротацию ревьюеров. Примечание: Привлечение к проверкам специалистов из продуктовых команд позволяет нам сократить риски, повысив bus factor и активно развивать внутреннюю экспертизу. Двухуровневое ревью в BitbucketАналогичным образом для web, mobile web и API-платформ выстроено ревью в Bitbucket. Ревьюеры назначаются в соответствии с задачей в Jira. Также мы используем подход с мейнтейнерами по пакетам (по аналогии с разработкой). В нашем случае пакеты соответствуют продуктовым сервисам, за которые отвечают определенные QA-инженеры. Суть в том, что действия с ключевой частью кода проекта автотестов должен согласовать ответственный за эту определенную часть кода продуктовый QA — без этого залить изменения в основную ветку не получится. Так мы делаем процессы более контролируемыми и снижаем риск человеческой ошибки. На практике это выглядит следующим образом: мы видим в Bitbucket, что не можем залить изменения кода автотестов, пока не получим минимум один аппрув от неких Юлии или Владислава, так как именно они отвечают за измененную нами часть кода.
Ревью на Android и iOSРевью автотестов для Android и iOS несколько отличается, поскольку в этих командах у нас есть core QA-инженеры, которые активно участвуют в процессах автоматизации тестирования.
Таким образом, при выстраивании процессов ревью мы учитываем доступные ресурсы, экспертизу и текущую нагрузку на специалистов. Запуски автотестовМы обязательно запускаем автотесты — на платформах web, mobile web и API в pull request для прохождения ревью нужно приложить отчет об успешном запуске автотестов, код которых был задет. Причем автотесты обязательно проверяются на корректность работы как на тестовой среде, так и на прод. В этом помогает работа с облаком — благодаря масштабируемым облачным ресурсам, мы можем запускать автотесты параллельно и в большом количестве. На Android-платформе у нас в pull request автоматически запускаются все UI-автотесты на каждый commit и по результатам этого запуска происходит автоматическое разрешение или запрет мерджа. В этом также помогает облако — мы можем одновременно запускать до 750 автотестов. То есть весь объем автотестов на Android (у нас их около 1400) мы можем прогнать всего за 7-10 минут. И даже с учетом автоматических перезапусков на это нужно не более 15 минут. На iOS-платформе новые или измененные автотесты также запускаются автором: локально или на удаленной ферме. Для прогона автотестов на iOS мы используем физические машины, так что скорость и объемы прогонов ограничены их мощностями. Стиль кода автотестовЧтобы предотвратить появление распространенных ошибок в коде и упростить чтение кодовой базы, мы в ОК выработали набор правил и соглашений, касающихся принципов написания кода. Эти правила можно условно разделить на три группы:
Правила общей работы с кодом
Логика пейджей
Логика тестовых классов
Это лишь часть важных правил из всего используемого нами стиля кода — в действительности их значительно больше. Примечание: В нашем случае стиль кода автотестов для разных платформ (например, Android и iOS) отличается. Во многом это обусловлено необходимостью учитывать платформенную специфику и подстраиваться под особенности фреймворков. Статический анализатор кодаЧтобы сделать соблюдение правил написания кода более нативным, а контроль за его качеством проще, мы используем статический анализатор кода — инструмент, который сканирует код на наличие ошибок и уязвимостей, а также помогает соблюдать принятые стандарты написания. Из большого стека доступных вариантов для этих задач мы используем PMD — статический анализатор, который выявляет типичные ошибки разработки: неиспользуемые переменные, пустые блоки, создание ненужных объектов и другие проблемы. Причин в пользу выбора именно этого решения несколько:
PMD можно подключать по-разному. Например, как:
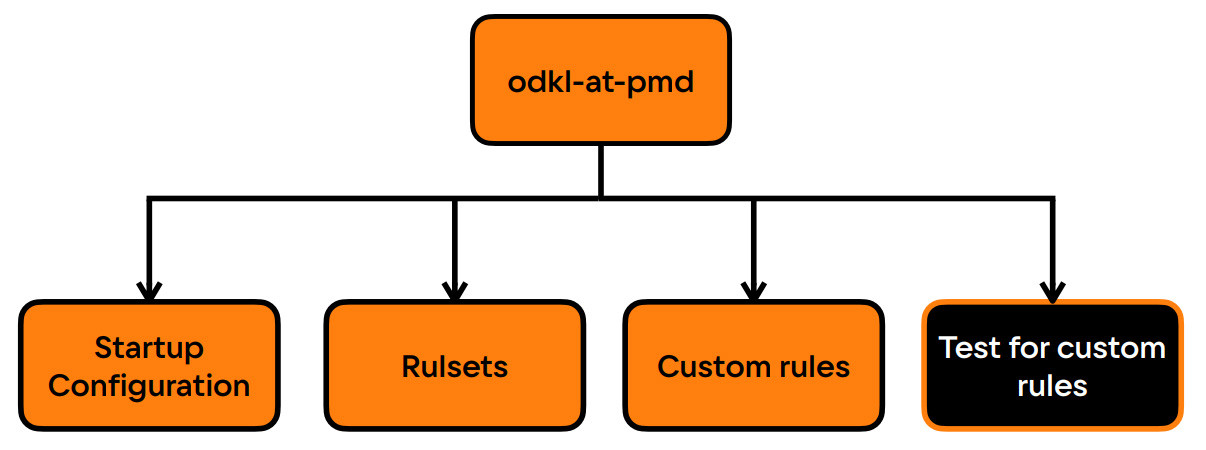
Мы используем PMD именно как зависимость для проекта. Структура PMD проектаИспользуя PMD, мы построили свой проект, который получил название ODKL AT PMD. Он состоит из четырех основных частей:
Подробнее о правилах Самое важное и интересное в нашем проекте — правила. Примечание: В статье мы приводим правила, которые актуальны для PMD версии 7.0.0. По факту они являются отображением стиля кода, только формализованы в несколько другом виде. Причина в том, что PMD понимает код не так, как разработчик, а в виде абстрактно-синтаксического дерева. Абстрактное синтаксическое дерево (AST) — дерево, отражающее структурные связи между существенными элементами исходного выражения, но не отражающее вспомогательные языковые средства (отступы, комментарии и другие). AST создается парсером по мере синтаксического разбора программы. Причем нам не приходится заботиться по поводу парсера — в AST он и так есть. На уровне кода абстрактно-синтаксическое дерево имеет примерно следующий вид:  Схема работы с данными выглядит следующим образом:
Реализация правил
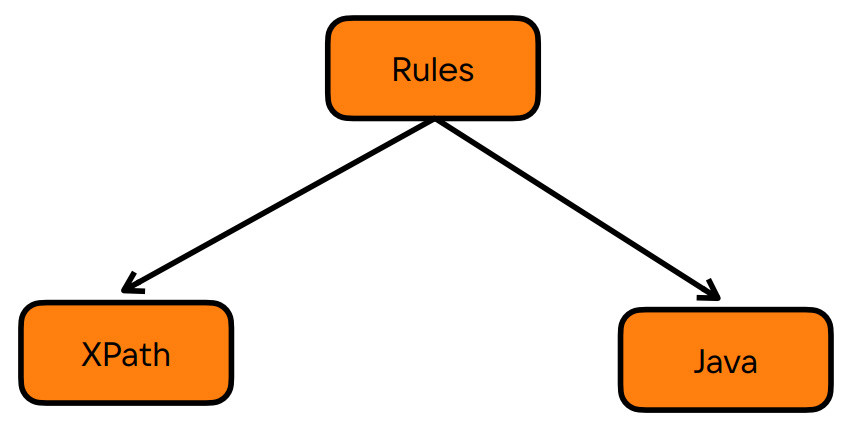
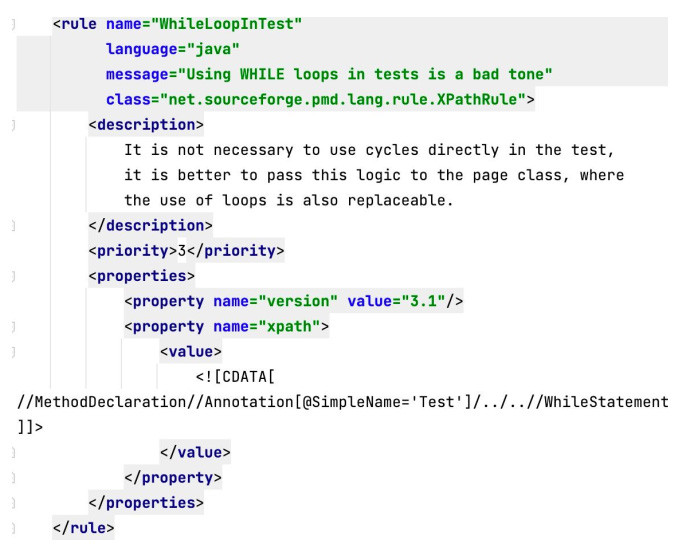
В зависимости от языка, реализацию правил можно условно разделить на две группы. Рассмотрим несколько простых примеров. Пример XPath правилаПредставим, что нам нужно найти и запретить к использованию какую-то java конструкцию, например,
Здесь мы указываем:
Пример Java правилаJava правила позволяют реализовать как простую (как в примере ниже), так и более сложную логику. Например, нам нужно, чтобы все тесты имели тег. На уровне кода соответствующее правило будет иметь следующий вид:
Здесь мы:
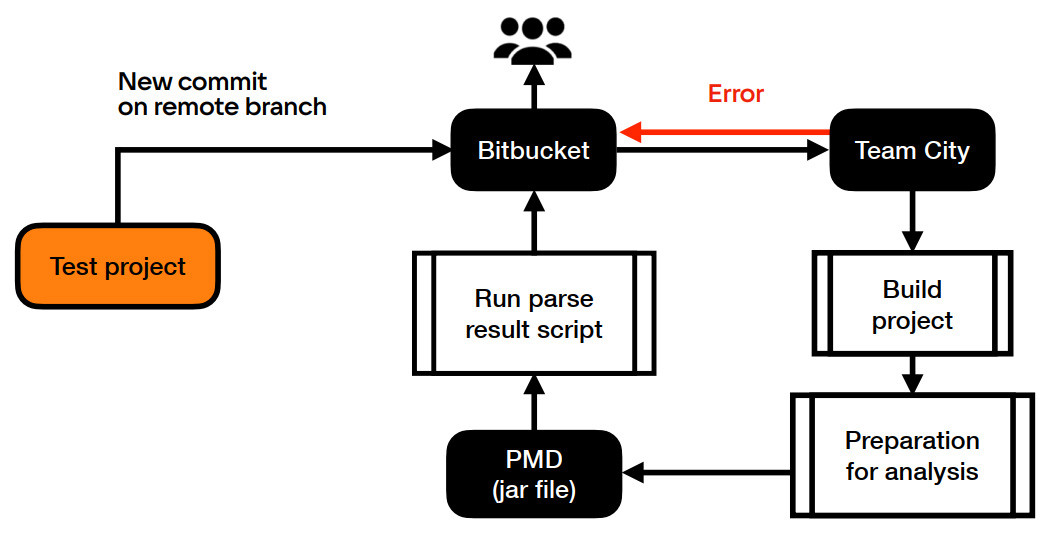
В данном случае мы проверяем, является ли класс тестовым. Если нет — завершаем анализ, если да — продолжаем анализ и переходим к узлам другого типа (например, Схема настройки окруженияТеперь подробнее о схеме настройки окружения. В нашем случае она имеет следующий вид:
В своем pull request в Bitbucket мы получаем весь массив нужной информации. В том числе полный отчет о работе линтера с приоритетами недочета, информационными сообщениями, указанием проблем и места, где было нарушено правило (если такая ошибка случилась). Преимущества PMDМы выделили несколько основных достоинств PMD конкретно для наших сценариев использования.
Вместо заключенияПовышение качества разрабатываемых продуктов напрямую зависит от качества, количества и достаточности автотестов. Поэтому в своей практике мы стараемся выстраивать прозрачные процессы постановки задач на автотесты, проводить двухэтапное ревью автотестов и четко регламентировать стиль кода. Вместе с тем, мы понимаем, что качество кода автотестов также зависит и от выстроенных процессов и качества разработанной документации, используемых технологий и инструментов, а также людей и их экспертизы. Поэтому мы стремимся уделять внимание не только разработке регламентов и выбору инструментов, но и повышению культуры работы с автотестами в целом. Чтобы добиться этого, мы ставим во главу угла специалистов: их запросы, экспертизу и ресурсы. Как результат, наш путь к улучшению кода автотестов и оптимизации работы с ними эволюционный, «не обременен излишней бюрократией» и прозрачен для всех вовлеченных специалистов. |