|
Автор: Артем Сидорук
Вы пишете автотесты? Ваш проект с автотестами огромен и монструозен, и добавление каждого нового сервиса в него приносит нестерпимое желание все удалить и написать заново? У вас есть базовый класс на 3000+ строк с методами на все случаи жизни? Или, возможно, вам приходилось исправлять множество тестов, чтобы добавить одну и ту же строчку в каждом из них?

Если хотя бы на часть вопросов вы ответили положительно, если в целом они знакомы вам не понаслышке или же вы просто давно хотите оптимизировать свой тестовый проект, но не знаете, с чего начать — эта статья для вас! Сегодня я хочу поговорить про паттерны и прочие сложные вещи, о которых тестировщики часто совсем не задумываются.
Все примеры в этой статье будут на C#. Но изложенные идеи применимы и к любому другому языку. То, что я буду разбирать в статье, есть на моем GitHub в двух вариациях — «как было» и «как стало». Вы можете ознакомиться с результатом или же взять начальный вариант и попробовать пройти путь, описанный в данной статье, самостоятельно.
На примере котиков автосервисаПрежде чем переходить к сути, предлагаю аналогию, на примере которой я буду разбирать сложные кейсы.
Представим некий автосервис:
- В этот автосервис, как и в любой другой, привозят автомобили, чтобы что-то в них починить (поменять тормоза, заклеить колесо и тому подобное).
- В автосервисе работают сотрудники, которые занимаются этими задачами по ремонту.
- Сотрудники используют какие-либо инструменты для выполнения задач.
Если провести аналогию с тестовым проектом, то получится:
- Автосервис — это проект в целом.
- Каждый автомобиль — отдельно взятый класс с автотестами.
- Задачи на ремонт — собственно, сами автотесты.
Тестовый проектПредположим, у нас есть вот такой тестовый проект.

В нем есть классы с тестами, а также классы сервисов, с помощью которых мы будем что-то тестировать. В терминах предложенной выше аналогии это «инструменты», то есть ключи, приборы и так далее, с помощью которых в автосервисе чинят автомобили.
Для примера посмотрим на один из классов сервисов — MyServiceUserApi.
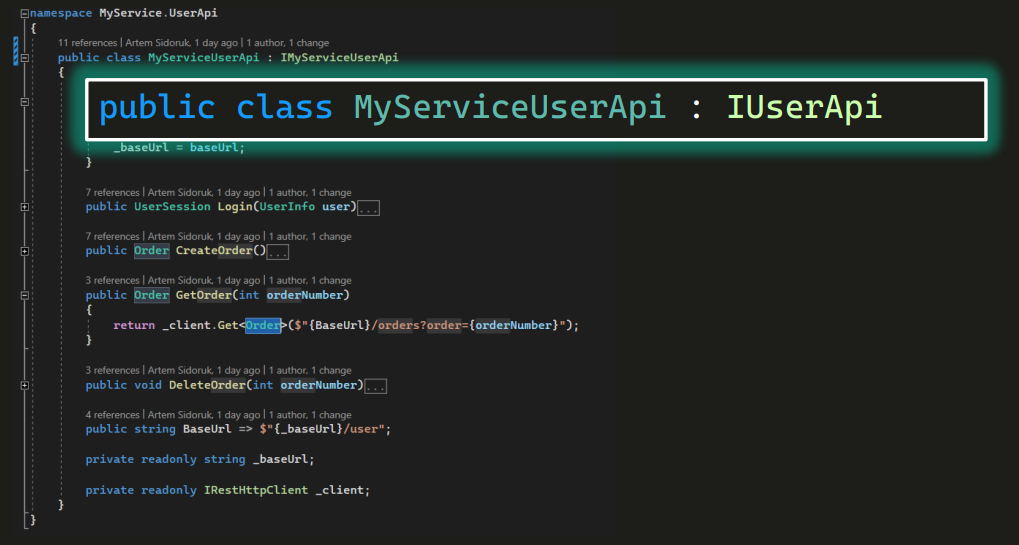
Он имплементирует интерфейс IUserApi. У него есть конструктор, в который передается http-клиент и URL. Раз мы видим http-клиент, это будут API-тесты, то есть для тестирования предстоит кидать REST-запросы (GET, POST и так далее).
Разумеется, здесь есть публичные методы, например:
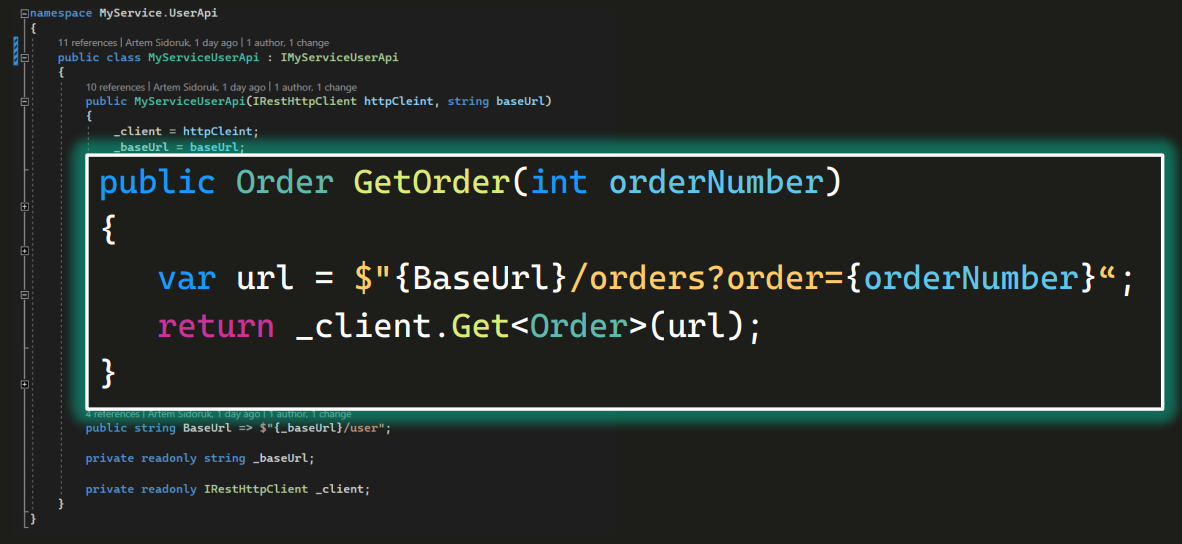
Вероятно, метод возвращает заказ по номеру с помощью GET-запроса.
Таких сервисов будет несколько:
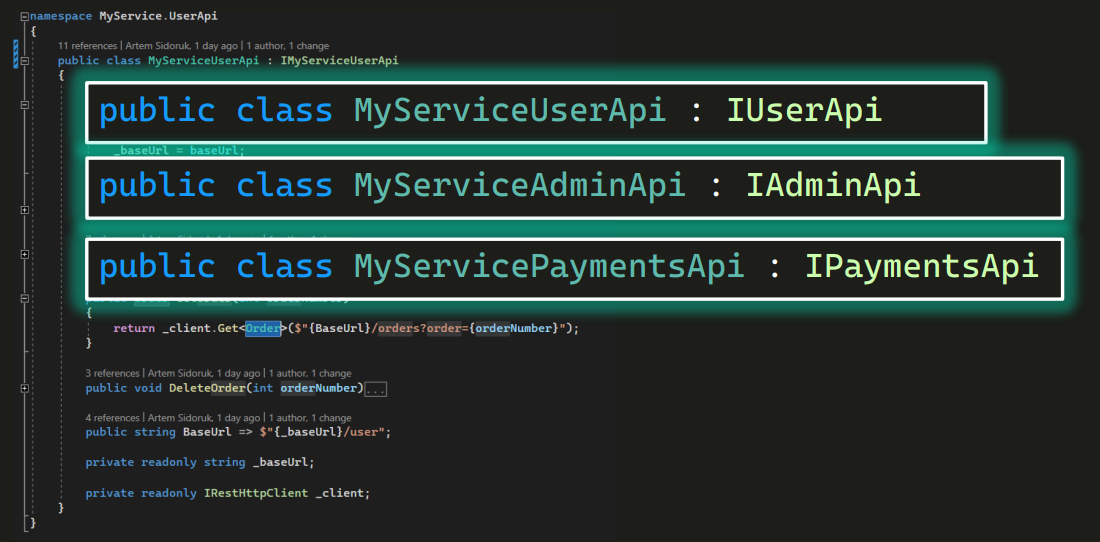
Давайте договоримся, что для представления реального положения вещей все, что я покажу здесь, в этом выдуманном тестовом проекте, мы будем умножать на 10. То есть в реальном проекте будет не три сервиса, а все 30. Просто примеры удобнее рассматривать на небольших проектах. Итак, у меня 3 — у вас 30!
Теперь посмотрим на тесты.
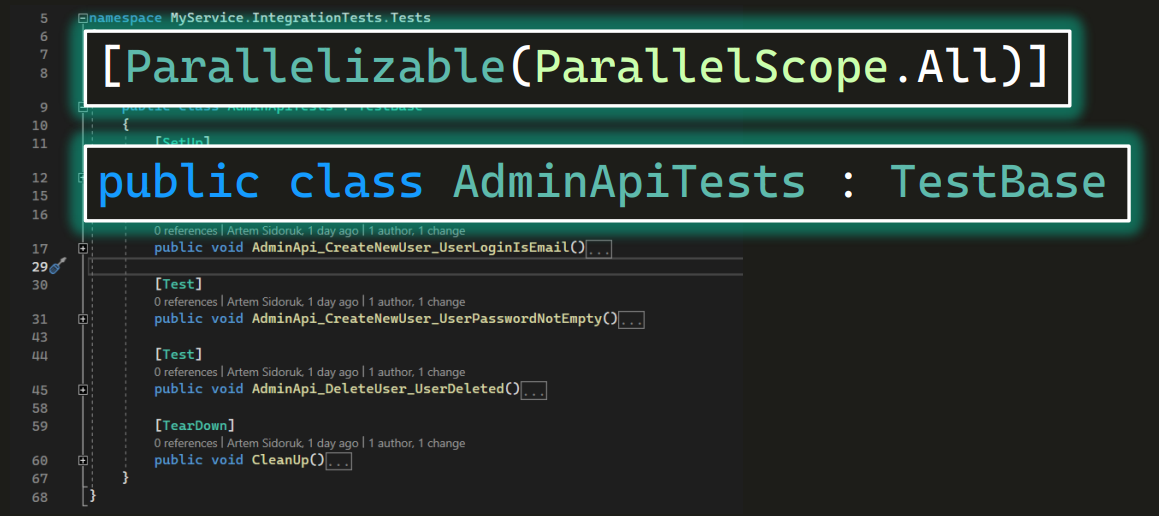
У нас есть четыре класса с автотестами (хотя на картинку влезло только три) — тесты на заказы, оплату, логин и админку.

Рассмотрим класс AdminApiTests. Это тесты на методы, которые будет вызывать админ компании. Иными словами, есть какой-то API-интерфейс — админка, через которую можно управлять выдуманным интернет-магазином. Соответствующий тестовый класс наследуется от некого TestBase, и на нем висит атрибут параллельности. Причем .All в данном случае говорит, что параллелиться будут вообще все тесты во всем Solution (насколько хватит потоков).
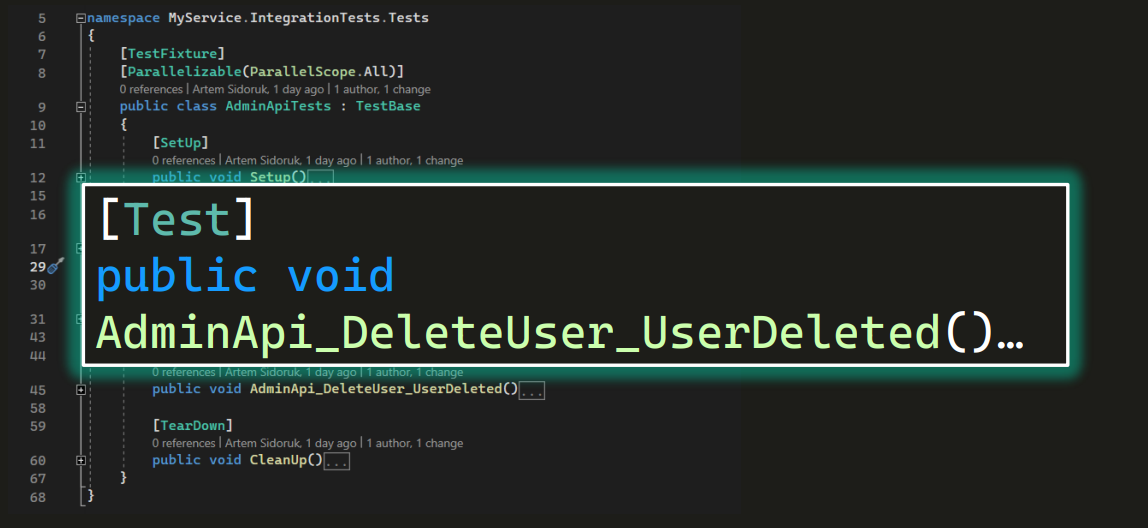
В тестовом классе, разумеется, есть тесты, или тестовые методы. Например, с помощью такого метода (теста) мы проверим, что когда админ будет удалять юзера, он действительно удалится:
Также в тестовых классах иногда есть методы, помеченные атрибутами SetUp и TearDown (он же CleanUp):
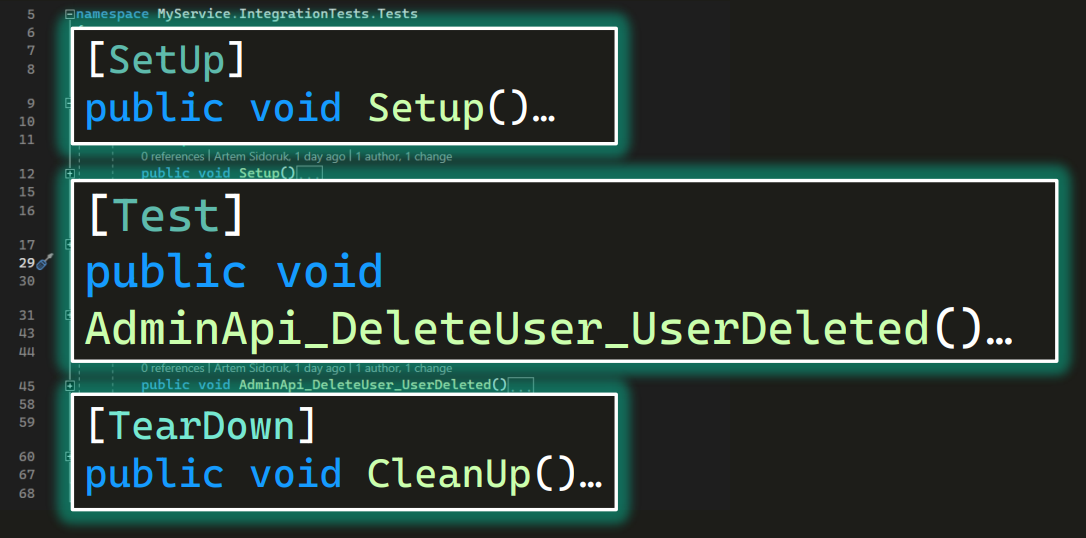
Они запускаются соответственно перед каждым тестом в классе и после него.
Посмотрим какой-нибудь конкретный тест. Например, UserApi_CreateNewOrder_OrderCreated. Через UserAPI можно создать заказ и проверить, действительно ли он создан:
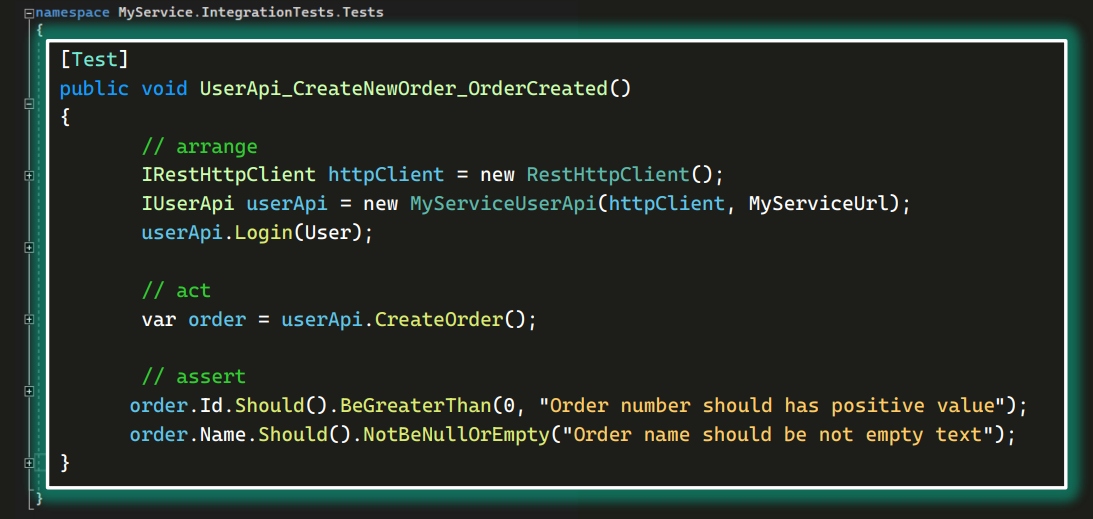
Этот тест написан в типичной парадигме для автотестов: arrange — act — assert.
В блоке подготовки находится создание объекта httpClient, и с его помощью — userApi:
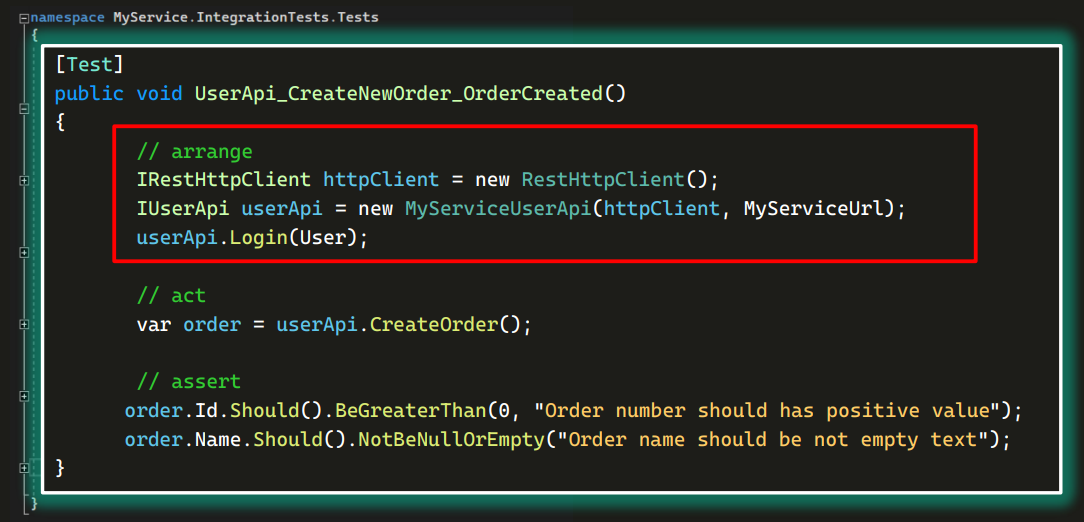
Далее в тесте создается заказ:
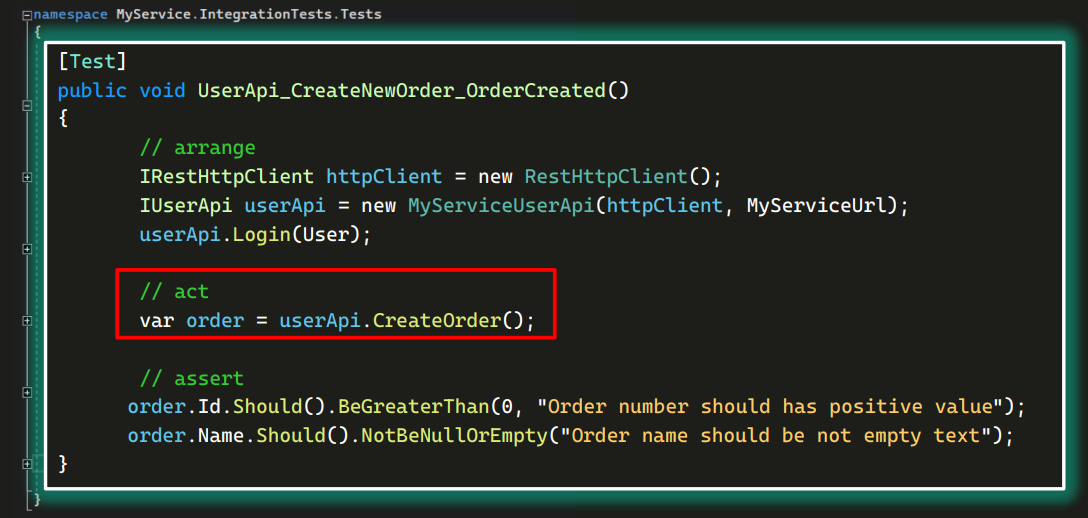
А после проверяется соответствие некоторым данным:
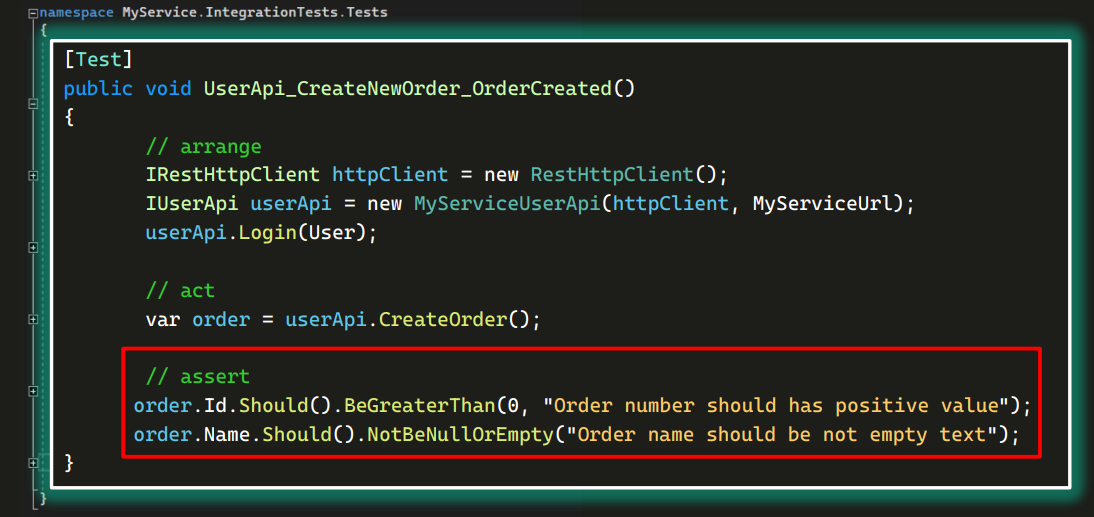
В данном случае неважно, хорошие это тесты или нет. Важно понимать структуру, как это все выглядит.
В целом здесь видно все, что будет происходить при запуске теста. Разве что присутствуют непонятно откуда взявшиеся User и какой-то ServiceUrl. В тесте их никто не создавал:
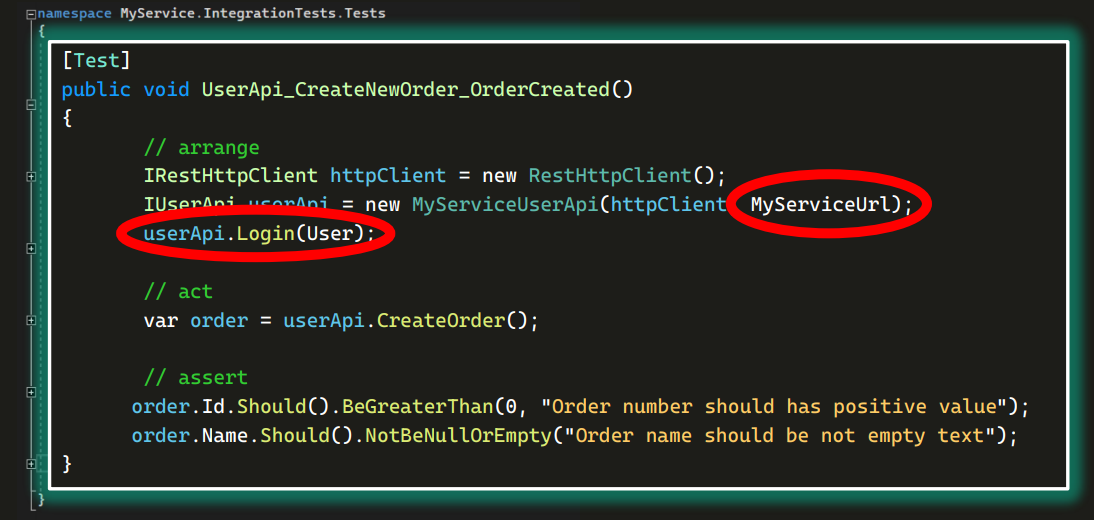
Раз их нет в тесте, посмотрим, что есть в методе Setup, то есть в том, что запускалось до теста. Тут и правда есть такая строчка. Получается, здесь и создается User, используемый в тесте.
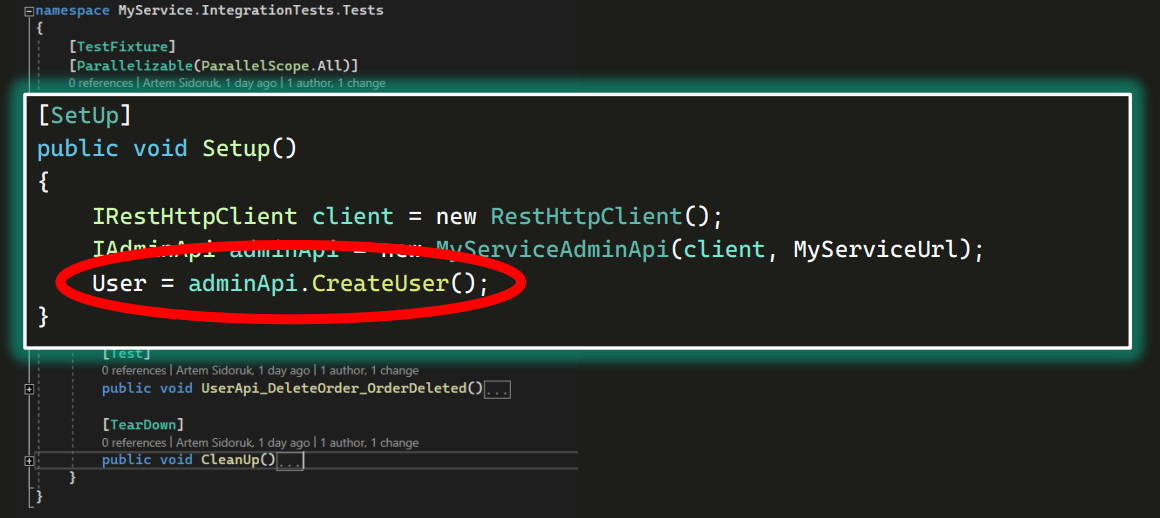
Вот еще один тест для примера.
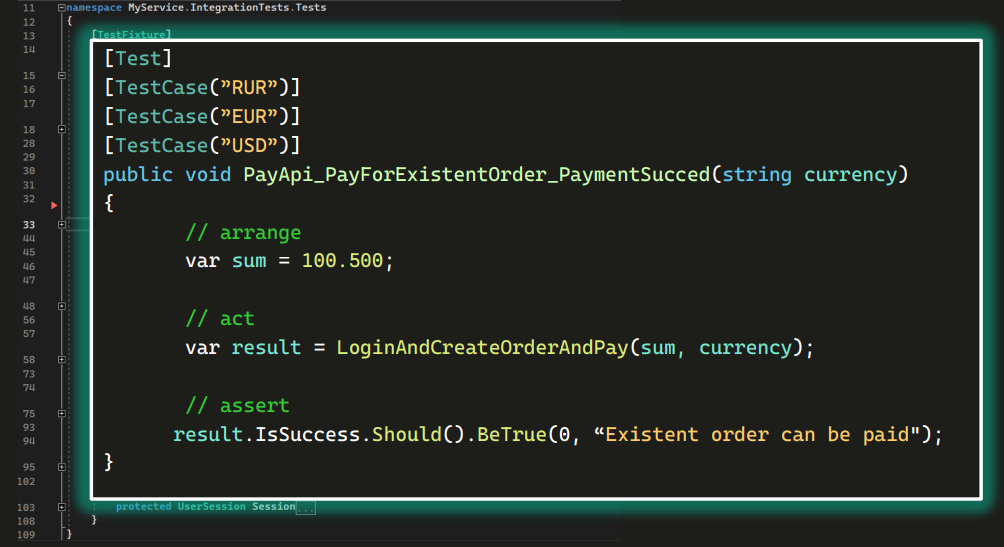
Структура такая же. Можно даже сказать, что это три теста, потому что описаны три тест-кейса. Здесь мы проверяем, проходит ли оплата по существующему заказу во всех трех валютах.
В этом тесте есть не очень понятная конструкция — длинный метод с нечитаемым названием:
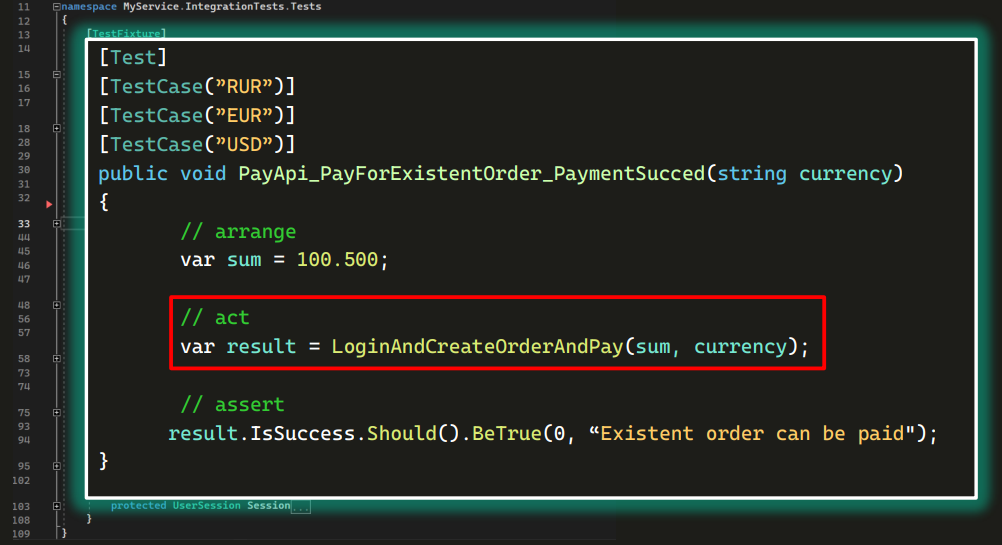
Мы не знаем, что там внутри — реализация от нас скрыта. Судя по названию, там и логин, и создание заказа, и оплата.
Прежде чем мы перейдем к сути, осталось посмотреть еще одну вещь — базовый класс, от которого наследуются все тестовые классы.

Этот класс абстрактный, то есть в нем ничего не создается. Он нужен только для того, чтобы раздать наследникам какие-либо общие методы и объекты.
В классе есть protected-свойства:
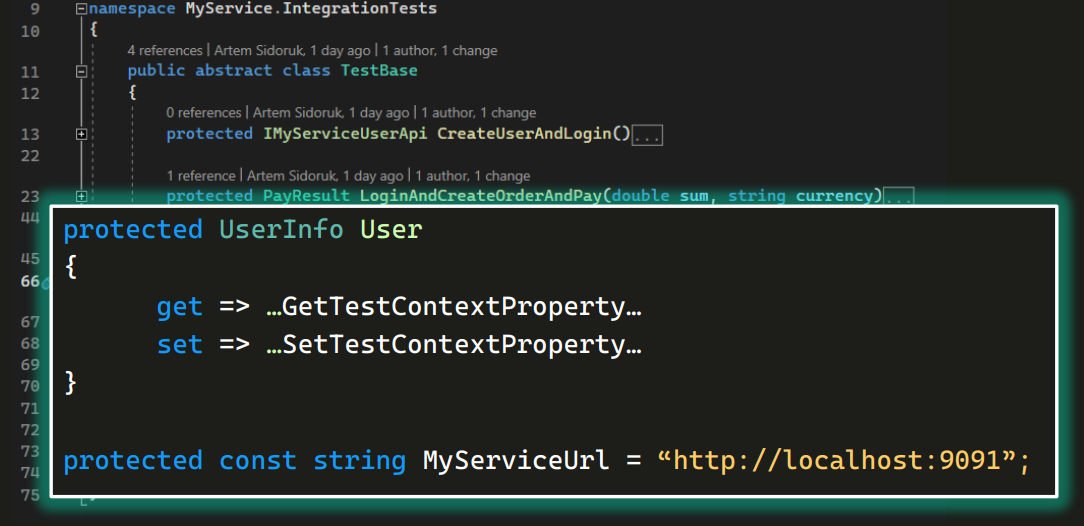
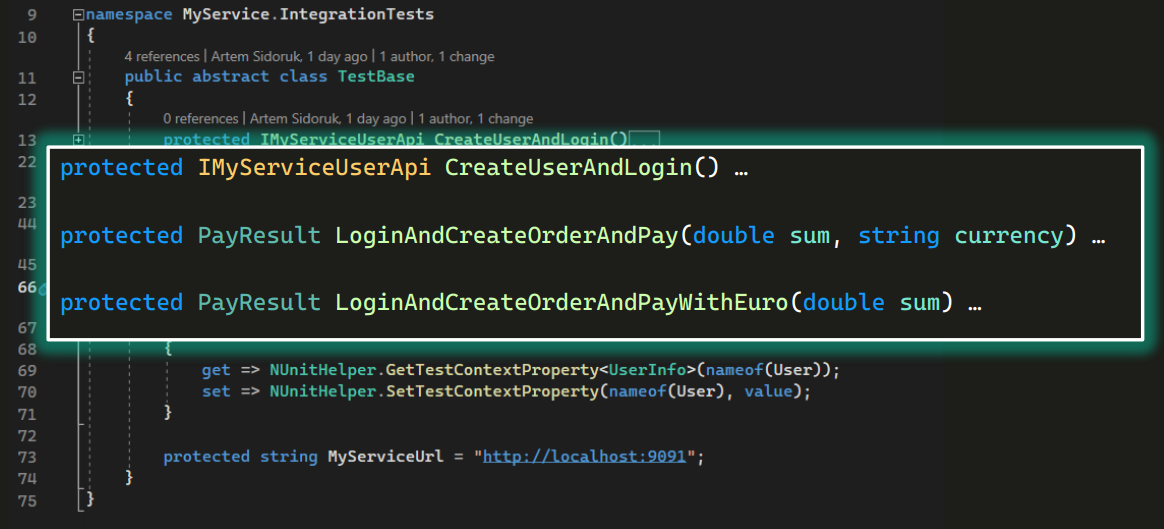
Также в нем есть методы, тоже protected. Использование одного из них мы уже видели выше.
Если мы запустим тесты, увидим, что все работает, тесты проходят:
К чему все это?Итак, тесты вроде работают, выдуманный автосервис чинит машины. Все прекрасно! Есть ли о чем говорить?
Но если копнуть глубже, окажется, что в соседнем автосервисе машины чинят быстрее.
А когда мы берем какую-то задачу на автотестирование, получается, что сидим с ней весь день. Время уходит на какие-то мелочи — целый день реально работаем, не отлыниваем, но в итоге всего два теста на выходе. Как так получается?
Если на эту работу посмотреть со стороны свежим взглядом, можно найти некоторые проблемы. На примере нашего выдуманного автосервиса можно было бы задаться вот таким вопросом:
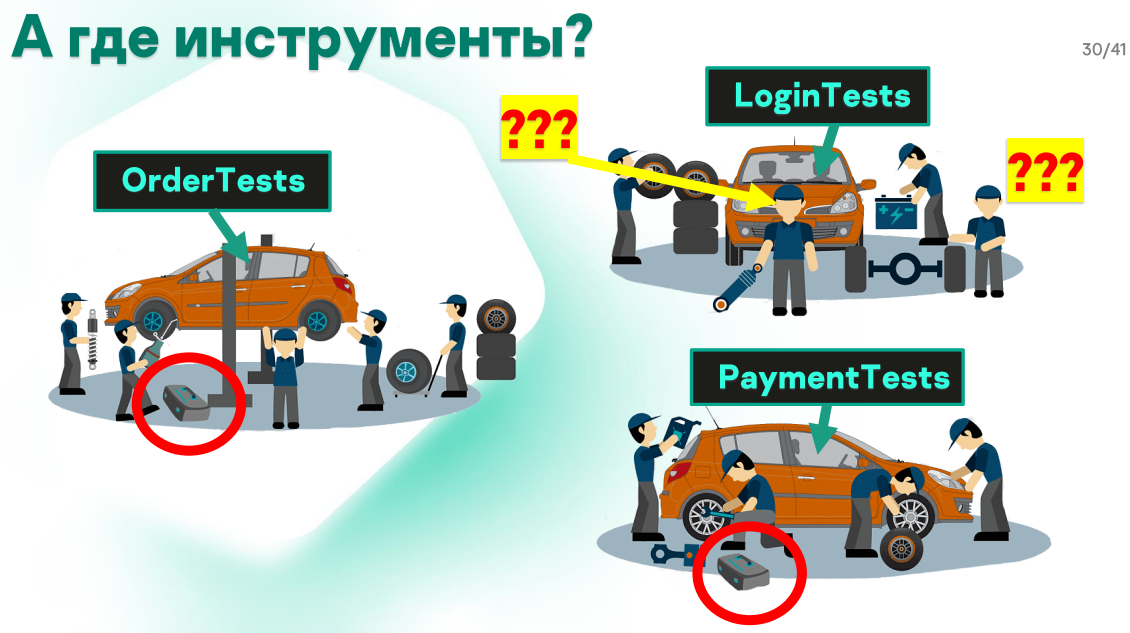
На картинке есть ящики с инструментами, но их всего два, а машины в ремонте три. Возле третьей машины стоит сотрудник и понятия не имеет, где взять нужный ключ, чтобы прикрутить деталь. Ему предстоит бродить по автосервису, искать ящики и ключ.
Возле другой машины справа снизу стоит сотрудник и держит фару одной рукой. Он сейчас поймет, что забыл отвертку. Ему придется все бросить и идти за инструментом, и только потом продолжить работу.
Все это мелочи, каждая занимает пару минут, но в итоге работа идет медленно, на нее тратится больше времени, чем должно.
В автосервисе эту проблему можно было бы решить вот так:

Можно нанять замечательного нового сотрудника — таксу, которая сама придет туда, куда позовешь, и принесет инструмент. Не надо ничего искать — все придет само, а ты продолжишь работать.
Аналогично можно поступить и с тестами. Рассмотрим подробнее, что происходит в тестах.
Оптимизация явных вызовов конструкторов
В методе Setup создается RestHttpClient, а потом AdminApi, в который передается этот клиент. Затем с помощью adminApi создается User.

А теперь посмотрим на тест. В нем также создается RestHttpClient, передается в UserApi, и с помощью него создается заказ.

А теперь TearDown, где снова создается RestHttpClient, после чего создается adminApi и удаляется User:
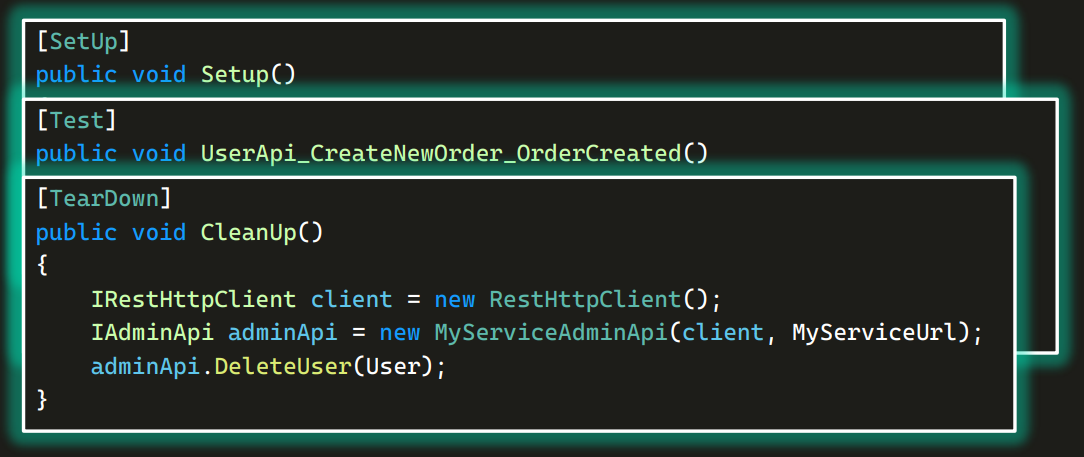
Есть такой принцип — DRY (Don’t repeat yourself). Во всех трех местах мы видим одну и ту же конструкцию:

Создаем один объект, затем другой. В терминах автосервиса — мы каждый раз выплавляем себе ключ, чтобы решить какую-то задачу. Но зачем? Так быть не должно, ведь инструмент лежит в ящике готовый. Тесты не должны создавать сами себе объекты. Как решить эту проблему?
Dependency injection
Процесс, когда мы создаем один объект (RestHttpClient в нашем примере) для того, чтобы передать его во второй объект, называется «внедрением зависимости» (dependency injection). В данном случае у MyServiceUserApi есть зависимость от IRestHttpClient.
Поговорим про dependency injection подробнее.
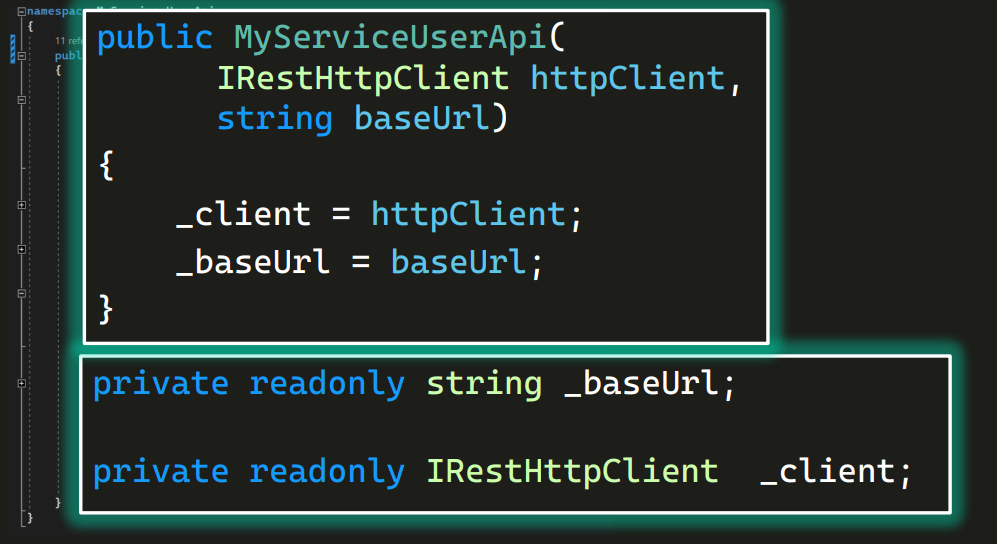
Предположим, у нас есть сервис, в который передавались и как-то в нем сохранялись (чтобы создавать в тестах объекты) httpClient и baseUrl.
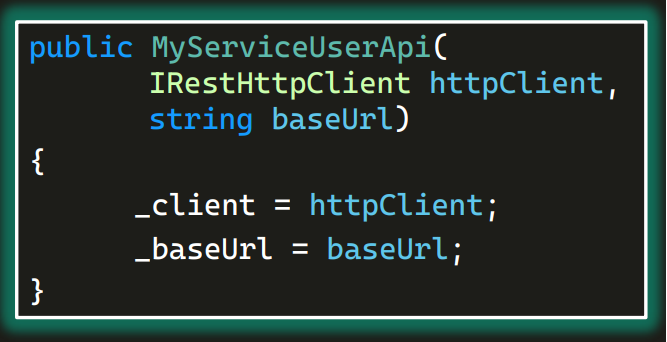
Чтобы каждый раз не писать первую строчку, мы могли бы сделать так:
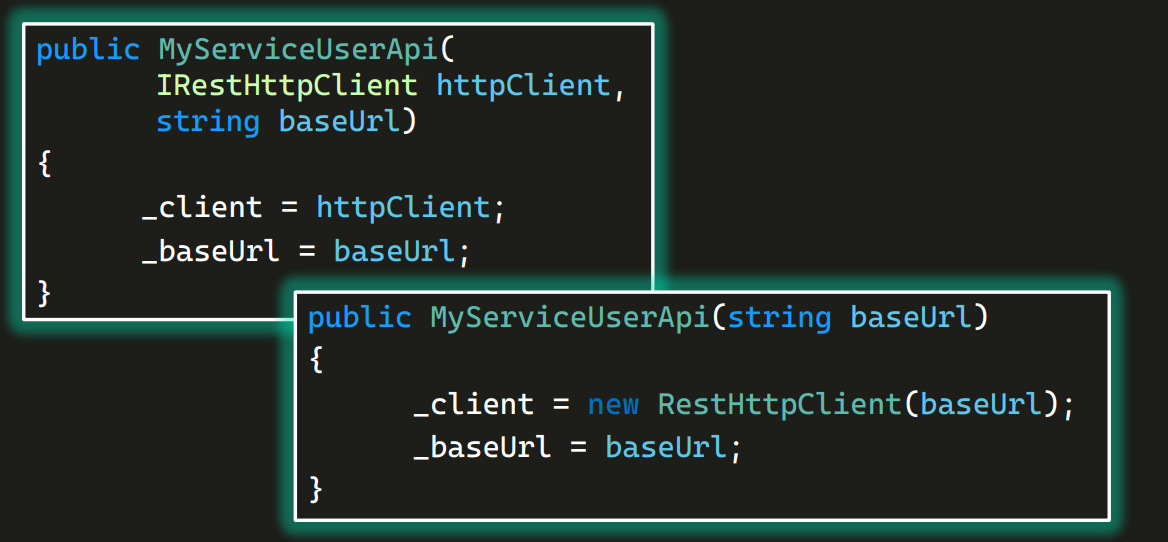
То есть прямо внутри класса создать себе RestHttpClient.
Работать будет. Но это не очень хорошая идея. Что, если завтра наш сервис окажется за прокси и надо будет передавать еще и логин/пароль для него? Тогда придется через каждый вызов конструктора UserApi, AdminApi и PaymentsApi передавать еще два параметра (и повторять это в каждом тесте). Можно вспомнить еще много причин, но в любом случае создавать объекты внутри класса всегда хуже. Снаружи можно слепить себе такой RestHttpClient, какой нужен, и уже потом передавать его готовым.
Переход от «создания объектов внутри» к «созданию снаружи» называется инверсией контроля (inversion of control). Пока объекты создавались внутри, мы их контролировали сами. Теперь же кто-то снаружи создает и передает их внутрь готовыми — мы «инвертировали контроль». А сам процесс создания снаружи и передачи внутрь — это внедрение зависимости (dependency injection).
В контексте dependency injection (DI) нельзя не сказать про такую штуку, как DI-контейнер, или IoC-контейнер (inversion of control). Иногда про него говорят как про service locator, но это не одно и то же (позже к этому вернемся). DI-контейнер — это место, где и должны внедряться зависимости из одного объекта в другой.
В большинстве случаев совсем не нужно выдумывать собственную реализацию DI-контейнера с нуля. Существует миллион реализаций на самых разных языках:
- dependency_injector — на Python;
- container — на Go;
- bottlejs — на JavaScript;
- Castle.Windsor, Autofac, Ninject — на C#;
- Butterfly Container, Guice, Picocontainer — на Java (и в Spring’е тоже есть).
Фактически для каждого языка есть реализации DI-контейнеров, или, как говорят разработчики, паттерна RRR (Register, Resolve, Release). Не нужно ловить волка и выводить новую породу собаки, чтобы заставить ее гулять по автосервису с инструментами.
Я буду показывать примеры с использованием библиотеки Castle Windsor, но в целом паттерн везде одинаков. Хочу отметить, что для C# существует и нативная библиотека — Microsoft.DependencyInjection. Но нам в команде не хватило ее возможностей.
Как будет выглядеть реализация с Castle WindsorПодключаем библиотеку к нашему проекту, после чего можем объявить некоторый класс, назовем его ContainerInitializer:
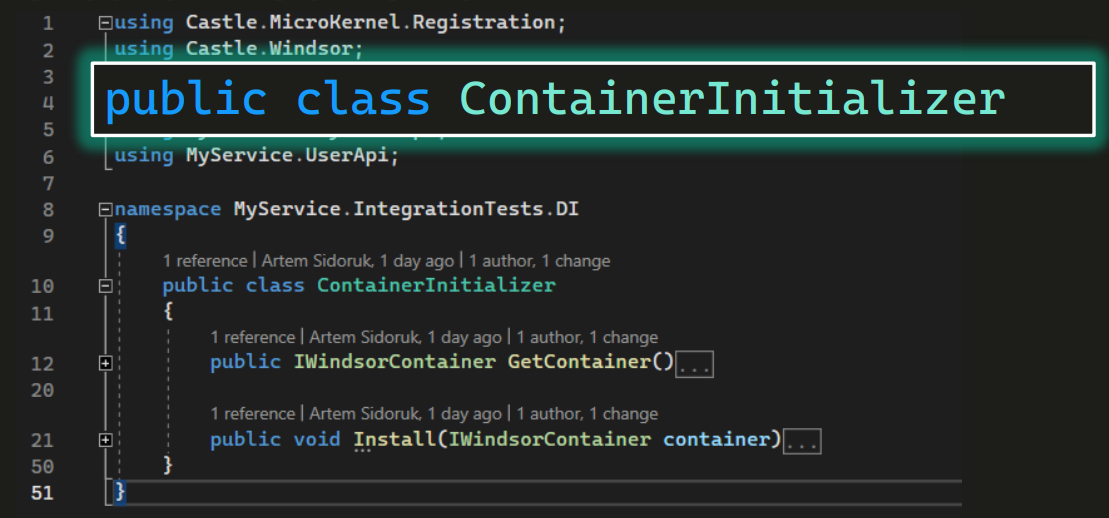
Объявим в нем метод — допустим, GetContainer:
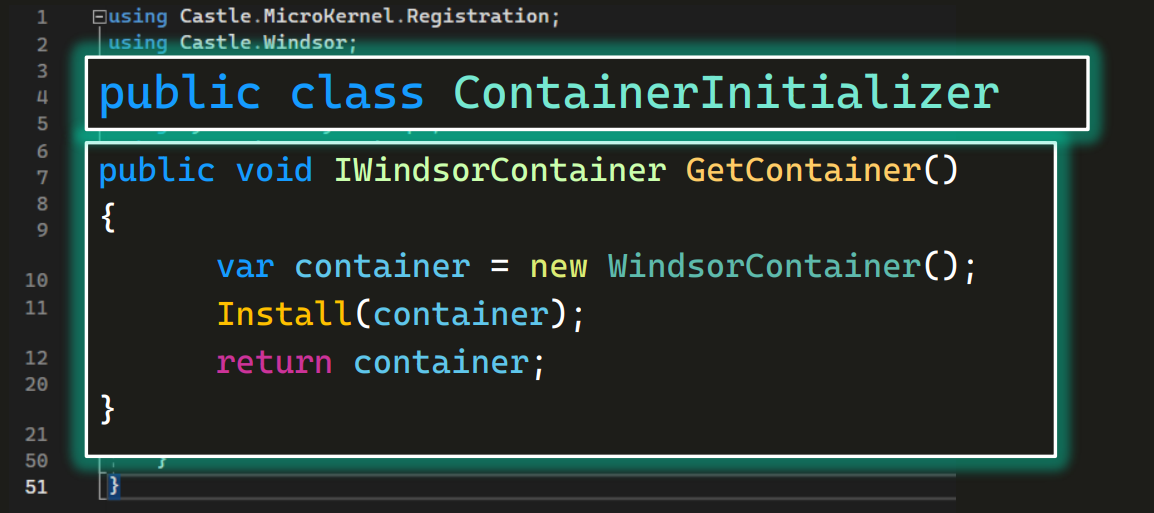
Внутри мы опишем три простых действия:
- создадим контейнер (найдем ту самую таксу);
- выполним Install (наденем на нее костюм, разложим по нему ключи);
- Return container (выпустим таксу гулять по автосервису).
Объявим приватный метод Install:
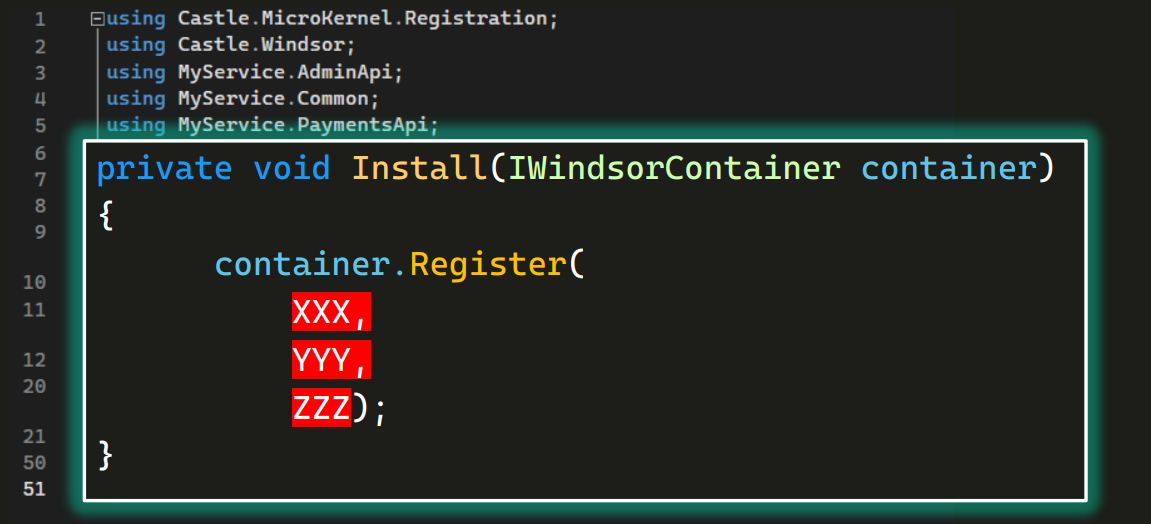
В методе напишем всего одну конструкцию с первым словом объяснения паттерна — container.Register. Внутри через запятую перечислим все то, что хотим положить в костюм таксе, — те самые инструменты, которые она должна нам приносить.
Подробнее каждая регистрация будет выглядеть так:
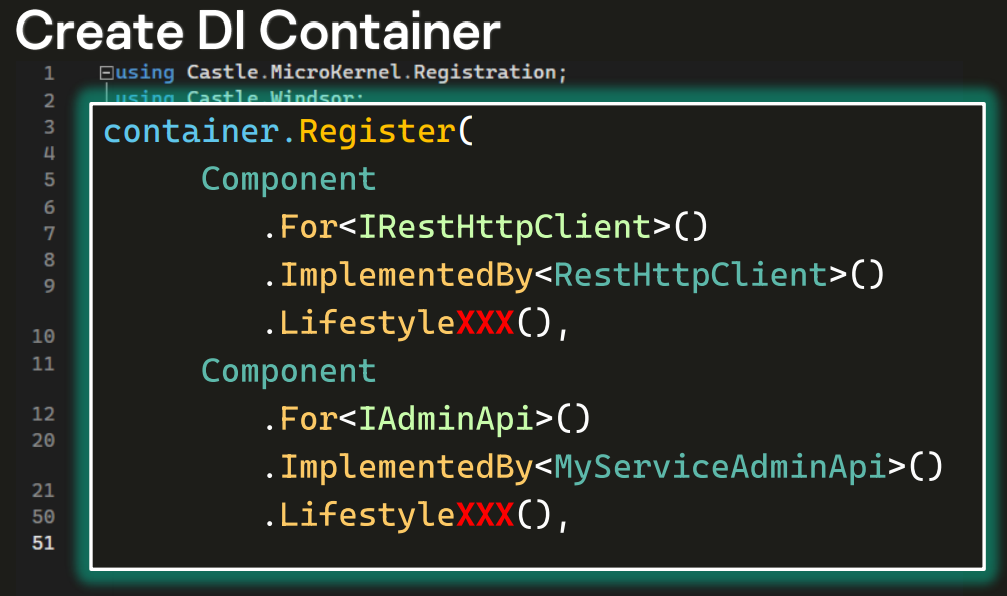
Для каждого инструмента будем писать:
- Component
- .For — указываем интерфейс для инструмента.
- .ImplementedBy — указываем класс, который имплементирует этот интерфейс.
- .LifeStyle — об этой строчке поговорим чуть позже.
Аналогичные блоки повторяем для всех инструментов, которые должны находиться в контейнере: IAdminApi, IUserApi, IPaymentsApi.
Формат записи может быть и иным, но данный пример — максимально простой для понимания.
Осталось выпустить таксу. Логично было бы сделать это в самом начале рабочего дня.
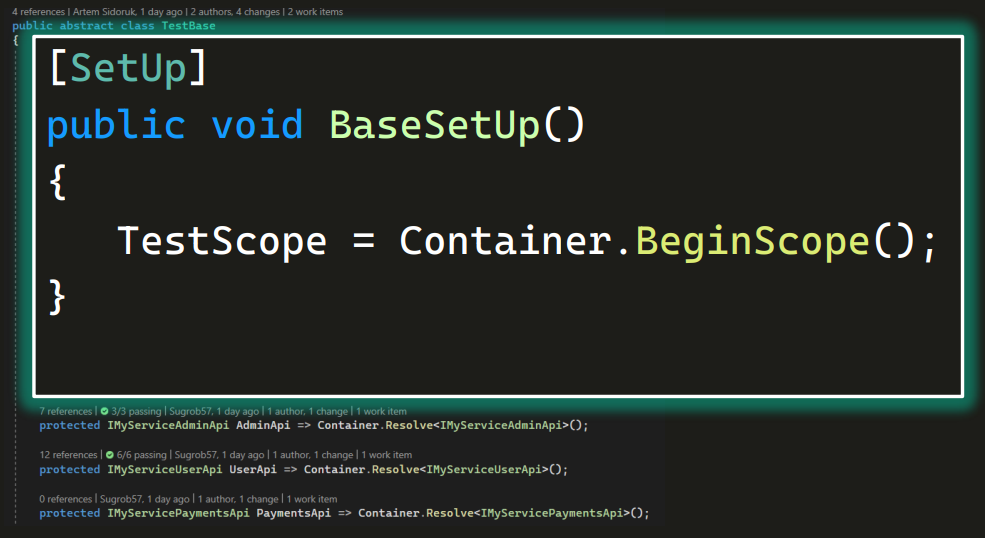
В программировании есть термин Сomposition Root — место, где начинается выполнение кода (первое место, где хоть что-то выполнилось). В данном проекте с автотестами таким местом будет класс TestBase. Именно с кода, описанного в нем, начнется выполнение. А раз так, объявим контейнер в нем.

Контейнер мы сделаем приватным и статичным. А чтобы он был только один, реализуем паттерн Singleton — то есть добавим проверку, и если контейнер уже существует, тогда вернем существующий. Если нет, создадим новый вызовом того самого метода GetContainer, который объявили выше.
Остается выйти в центр автосервиса и сказать: «МужикиТесты, если вам понадобится инструмент под названием молоток IAdminApi, позовите таксу сделайте Container.Resolve() из любого места в автосервисе в проекте.»
И то же самое с UserApi и PaymentsApi.

Напомню, что конструкция «=>» — это еще не выполнение, а лишь инструкция. При создании класса тестов эти строки не выполнены. Но как только кто-то к ним обратится, инструкция выполнится и произойдет вызов Container.Resolve(). И дальше контейнер сам разберется, что там в зависимостях, загрузит все в конструктор, создаст и вернет готовый объект.
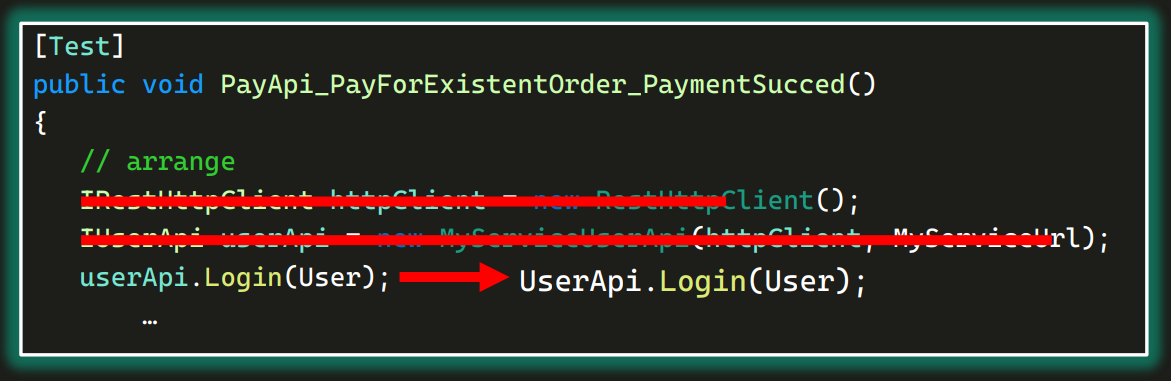
Теперь можно пойти во все тесты и удалить вот эти две строки:

А вместо третьей, которая использовала приватный объект, написать UserApi c большой буквы. И все будет работать.
Корректное хранение объектовДавайте еще раз посмотрим на то, что раньше было в SetUp и TearDown:
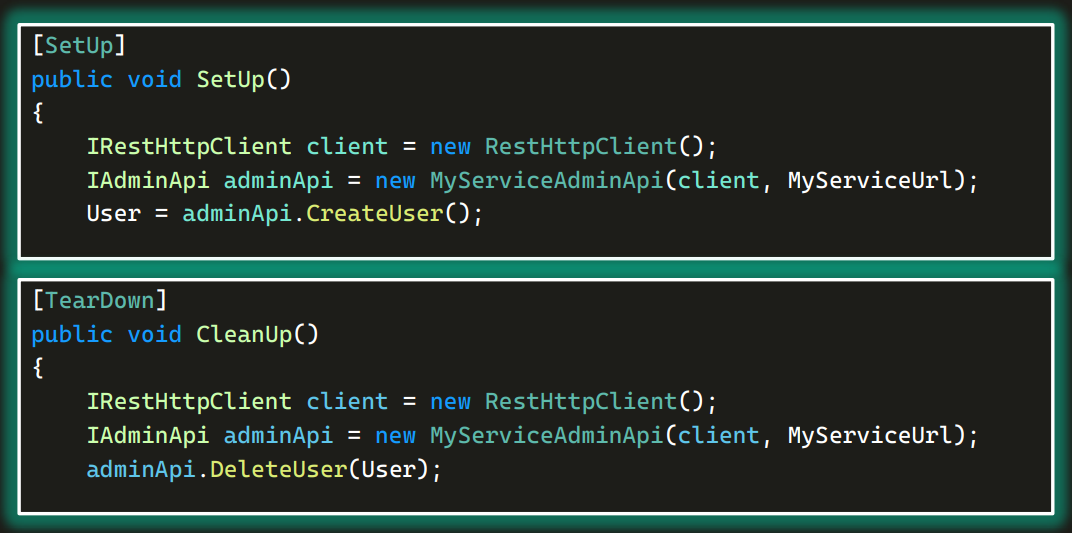
И там и там мы создавали AdminApi. Но зачем нам два AdminApi? В интернет-магазине вряд ли будет много админов. Скорее всего, он там один на тысячу заказов. Возможно, тестируемый сервис вообще не готов к такому: когда мы запустим 50 тестов, они создадут 100 сессий в AdminApi, и он упадет от нагрузки (мы же не нагрузочные тесты пишем, а функциональные). Наверное, стоит AdminApi создавать всего один раз, а потом переиспользовать.
С другой стороны, существуют иные объекты, например PaymentsApi, которые каждый раз хочется получать новыми, чтобы не было cookies, каких-либо авторизаций и тому подобного.
Так вот, когда мы говорим о том, что нужно продумать, какие объекты создать, а какие сохранить и переиспользовать из переменной, мы на самом деле говорим о хранении объектов. С помощью DI-контейнеров здесь также можно сильно упростить себе эту задачу — через LifeStyles.
LifeStyles проще пояснить на примере с таксой:
- Singleton. Представим, что наша такса, гуляя по автосервису, носит еще и колонку с Алисой/Марусей/Салютом (нужное подчеркнуть), которая играет музыку. Любой из мастеров может подозвать ее и переключить трек, сделать громче или тише, поставить на паузу. При этом музыку слышат все одновременно. Такой стиль существования объектов, когда он доступен всем сразу и присутствует в единственном экземпляре, называется Singleton.
- Transient. Предположим, такса начала приносить не только ключи, но еще и болты. Если мы возьмем у таксы болт, мы его куда-то вкрутим и, вероятно, уже не открутим обратно. Такса отдает этот объект и забывает про него — за ним не надо следить, возвращать обратно. Как с одноразовой салфеткой — руки вытер, выкинул в урну и забыл. Такие объекты называются Transient’ами.
- Scoped. Представим, что какому-то мастеру понадобился паяльник — соединить какие-то два провода, проводку починить. Он подзывает к себе таксу, она приносит паяльник, и он втыкает его в розетку. Чуть позже мастер снова зовет собаку и просит подать паяльник. И тут она ему приносит другой паяльник, новый и холодный. Но мастеру же нужно было другое — чтобы паяльник был не новый, а тот, что все это время стоял и разогревался. Такой стиль существования объектов, когда они существуют и не пересоздаются в рамках какого-либо процесса (Scope), называется Scoped.
- Pooled. И еще один вариант. Допустим, у нас есть ровно три ключа одного размера. Если одновременно четырем работникам понадобится такой ключ, то четвертому он не достанется. Он будет вынужден ждать, пока кто-то освободит инструмент. После чего такса заберет ключ и принесет четвертому. Такой стиль существования объектов называется pooled.
Стилей, конечно, намного больше. Но другие, как правило, в тестах не нужны.
Теперь, зная эти четыре стиля, мы можем прописать их нашим сервисам. Там, где регистрировали компоненты:
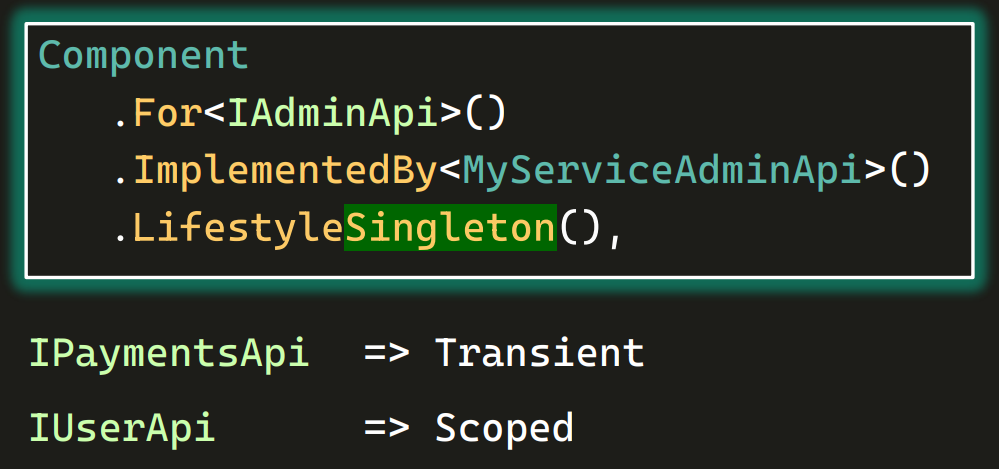
Для AdminApi пропишем LifeStyleSingleton, потому что мы хотим, чтобы админка существовала только в одном экземпляре, сколько бы тестов к ней не обращалось.
Для PaymentsApi мы можем написать LifeStyleTransient, то есть каждый раз мы хотим получать новый объект и с нуля заполнять его. UserApi — как паяльник, его нужно сначала прогреть залогинить, а потом уже, имея куку авторизации, кидать запросы. Поэтому он должен быть Scoped. Возможно, где-то также понадобится Pooled (например, где есть фиксированное количество учеток или настоящих банковских карт).
Важно, если у нас есть хотя бы один Scoped-объект, не забыть объявить в базовом классе такой метод:

Пометим его атрибутом SetUp, чтобы он запускался перед каждым тестом, потому что для нас scope — это каждый тест (у каждого теста свой процесс). И таким образом мы сообщим контейнеру, что «здесь начинается scope» — тот самый процесс, в рамках которого не следует пересоздавать scoped-объекты.
Так мы решаем еще одну проблему.
Мы можем один раз подумать про хранение объектов и больше не держать это в голове, прописав правильные LifeStyles.
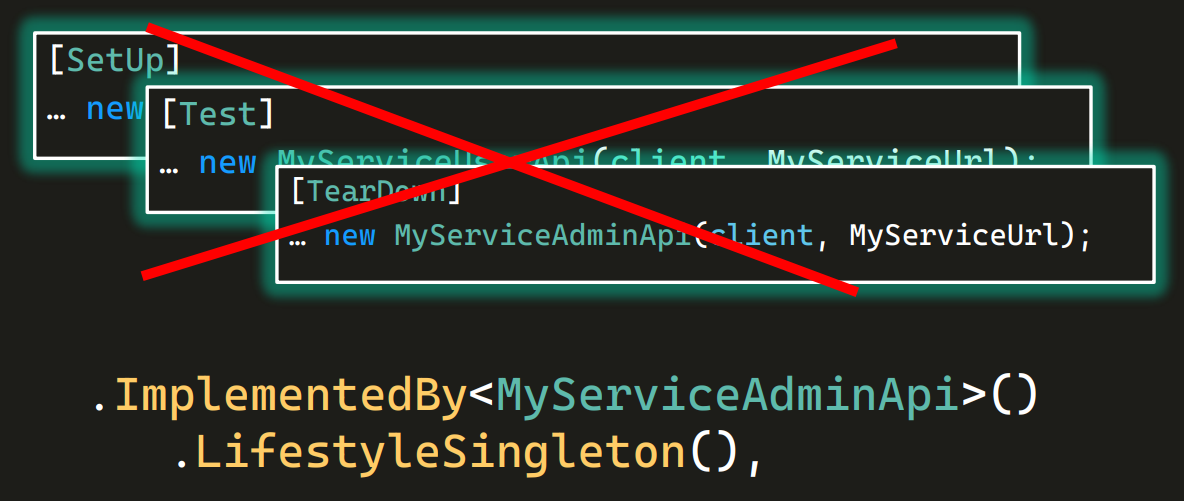
Все подряд в базовом классе
Посмотрим еще раз на базовый класс и на его методы:
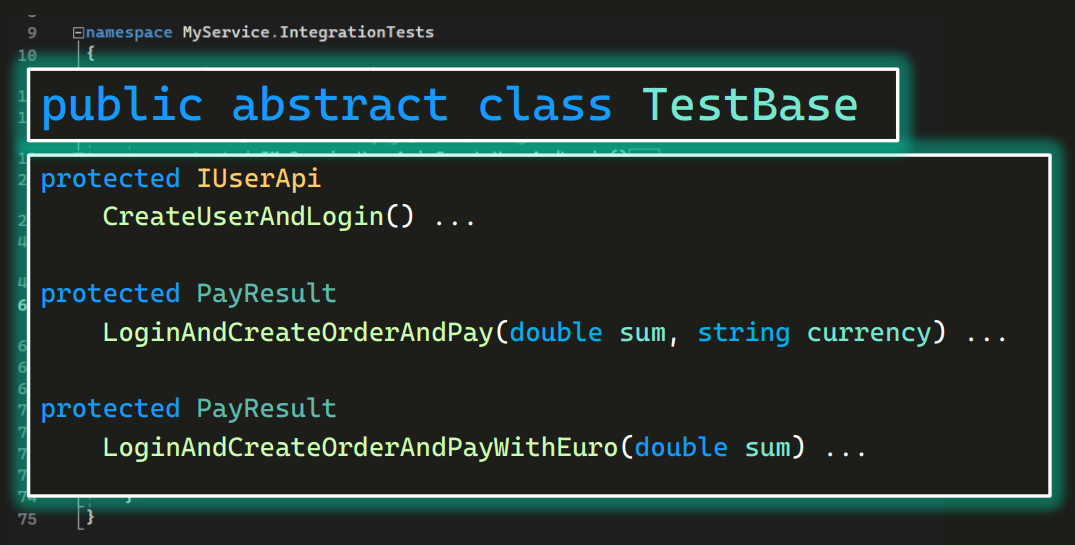
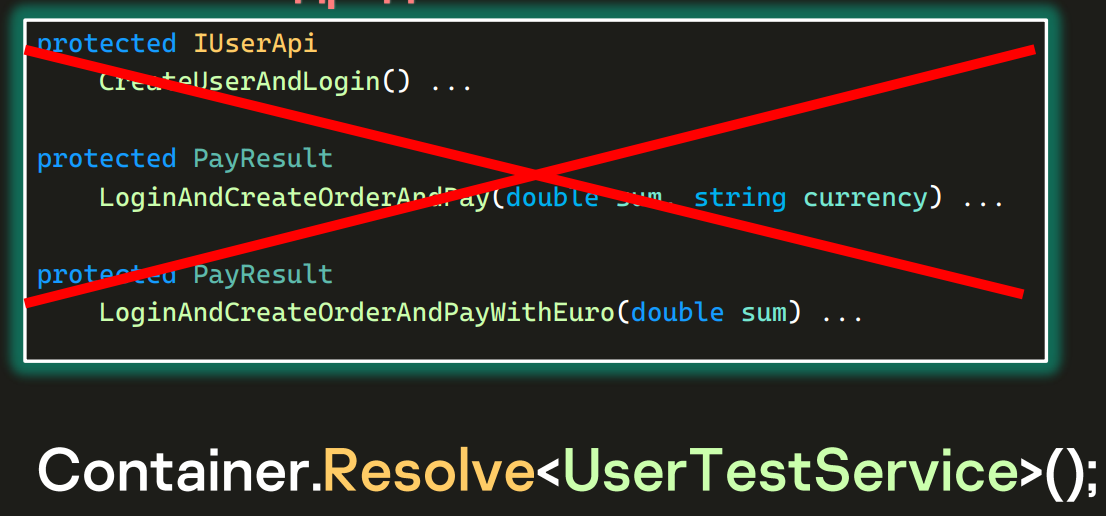
В базовом классе напихано все, что только можно. Два метода на экране очень похожи между собой, просто один из них работает только с евро. Да и в целом базовый класс превращен в помойку — в нем лежит очень много самых разных методов, тысячи строк кода. Методы могут даже дублировать друг друга. Пришел новый тестер, не нашел старый метод и написал свой, тоже в базовом классе (а потом где-то еще и переиспользовал его). Такое в реальности случается сплошь и рядом.
Эту проблему можно и нужно решать. На скриншоте выше — пара методов про оплату. Давайте создадим PaymentsTestService и перенесем в него из базового класса все то, что касалось оплаты.
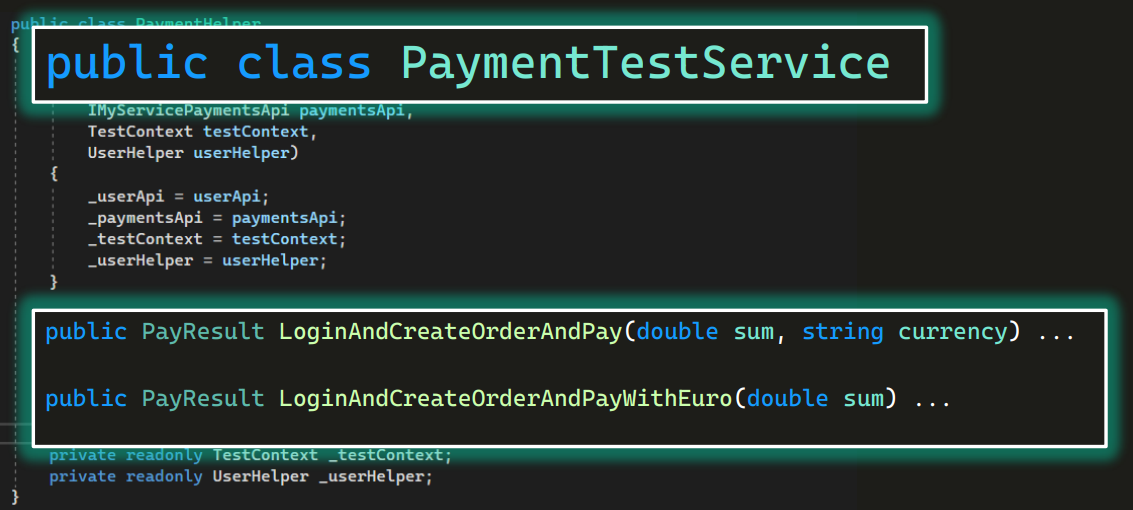
Этим методам нужны были какие-то зависимости — UserApi, PaymentsApi, — соответственно, объявляем конструктор, который их передаст:
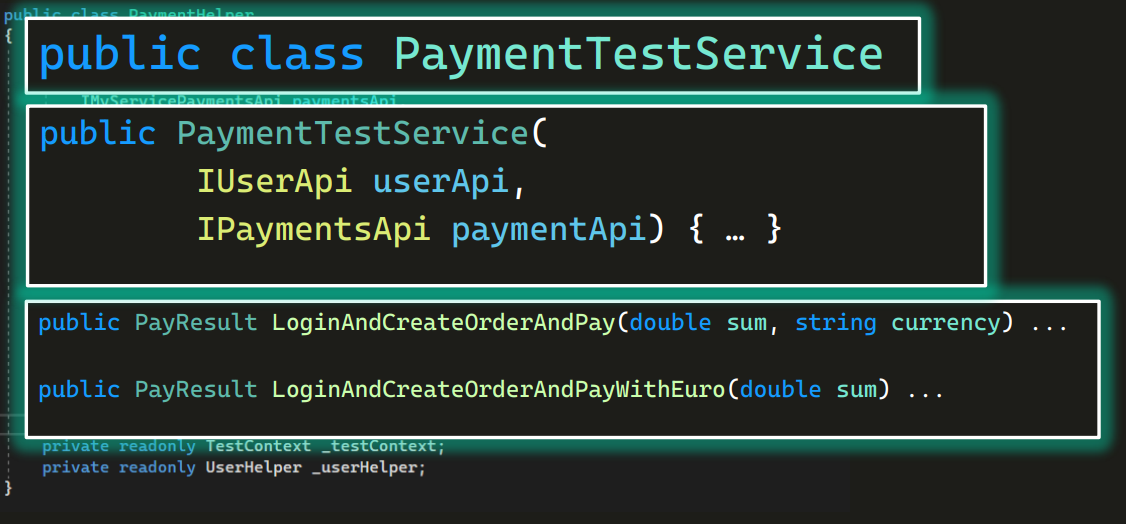
Точно так же можно поступить и с другими методами, создав UserTestService, OrderTestService и так далее. Разумеется, их тоже регистрируем в контейнере.
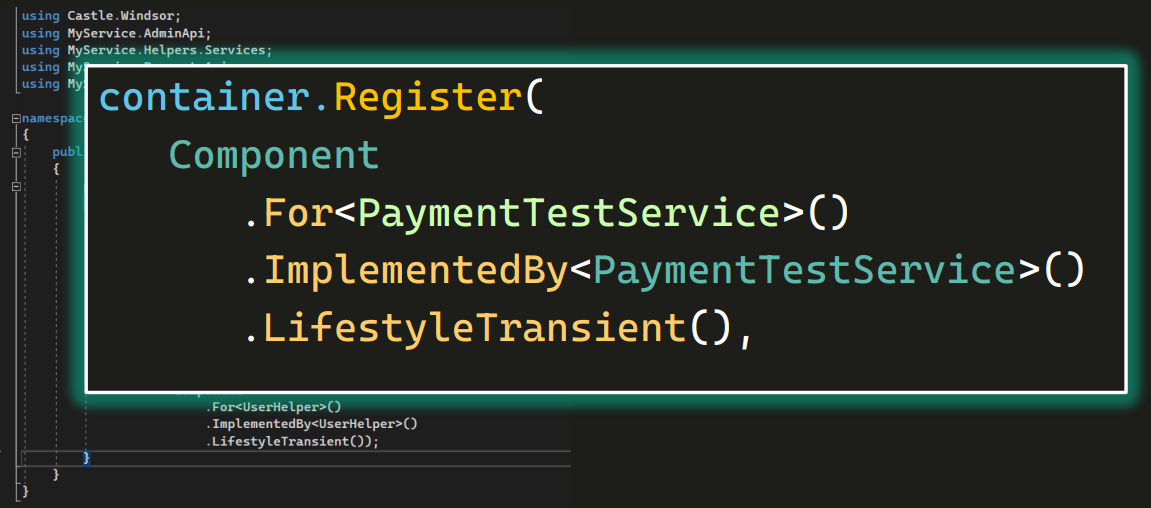
Если мы подойдем к процессу обдуманно — не просто перевалим все из базового класса в другие, а сделаем это аккуратно, — у нас будет порядок в проекте. Методы будет легко искать. Когда все однотипные методы окажутся в одном выделенном классе, вы обязательно заметите, что среди них есть несколько одинаковых. И даже новым людям будет проще с этим всем управляться.
Не везде выполняется очистка
Часто бывает, что после теста нужно что-нибудь очищать. Например, удалять пользователя, которого мы создали до или во время теста, или разлогиниваться, чтобы не копились сессии. Иначе какой-нибудь 200-й тест не сможет запуститься, потому что все предыдущие не разлогинились.
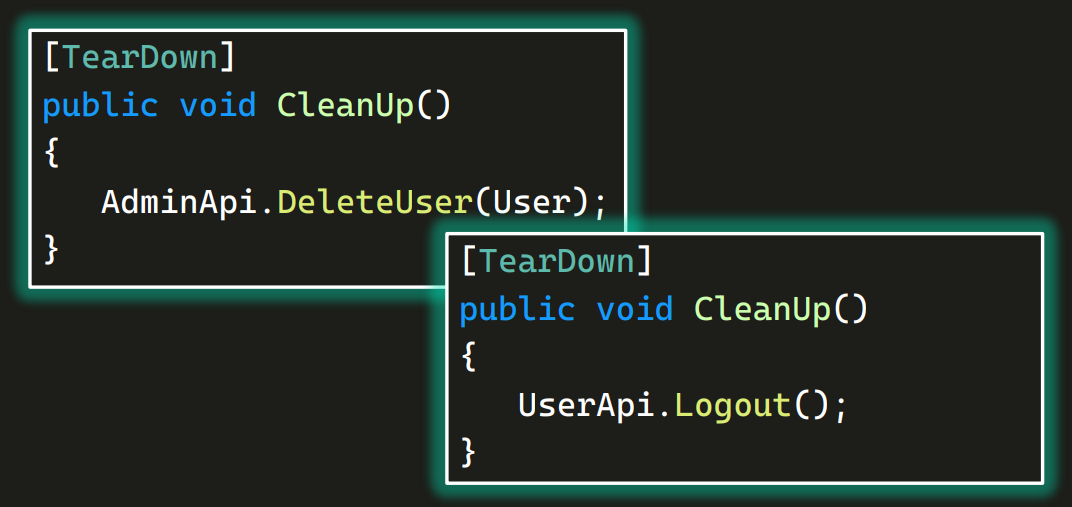
Представьте себе ситуацию: мы создали девять классов с тестами, в которых все будет нормально (пользователь создается, а в конце некий метод TearDown его удаляет), а в десятом забыли все очистить. А потом напишем еще 90 других тестовых классов. В итоге у нас уже огромный проект, и только в одном классе забытый TearDown. Через полгода мы обнаружим, что потихоньку пухнет база — не чистятся создаваемые тестами юзеры. Но найти тот единственный класс, в котором мы когда-то забыли правильно почистить за собой, будет довольно сложно, ведь проект разросся.
Вопрос чистки также можно решить с помощью DI-контейнеров.
Объявляя LifeStyles и описывая scope, мы забыли один момент. Метод BeginScope на самом деле возвращает значение. Запишем его в некоторую переменную:
И положим ее в приватные базового класса:
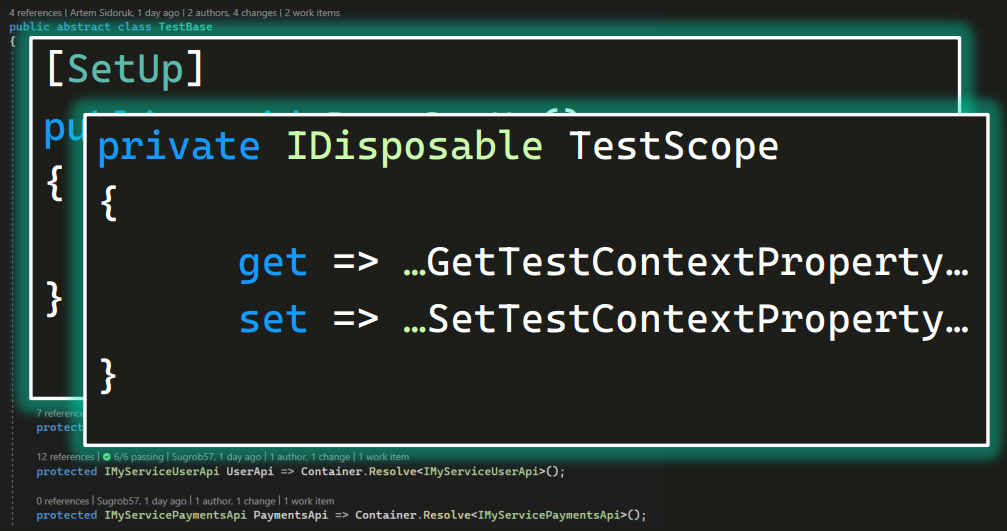
Она будет иметь тип IDisposable. Это общеизвестный интерфейс, и говорит он о том, что у этого объекта точно есть метод Dispose() — метод очистки. То есть данный объект знает, как его правильно очищать.
Если мы хотим, чтобы scoped-объект очищался где-то в конце нашего процесса (теста), мы можем в TearDown базового класса задать метод, в котором и сделаем вызов метода TestScope.Dispose().

Теперь контейнер знает, когда заканчивается scope (до этого он знал только, когда он начинается). Надо отметить, что в этот момент ничего особенного не произойдет — container просто найдет все scoped-объекты и отдаст их garbage collector-у. Но нам было нужно не это. Однако мы можем объяснить контейнеру, как правильно чистить наши объекты.
Возьмем класс MyServiceUserAPI (как раз scoped) и добавим ему интерфейс IDisposable.
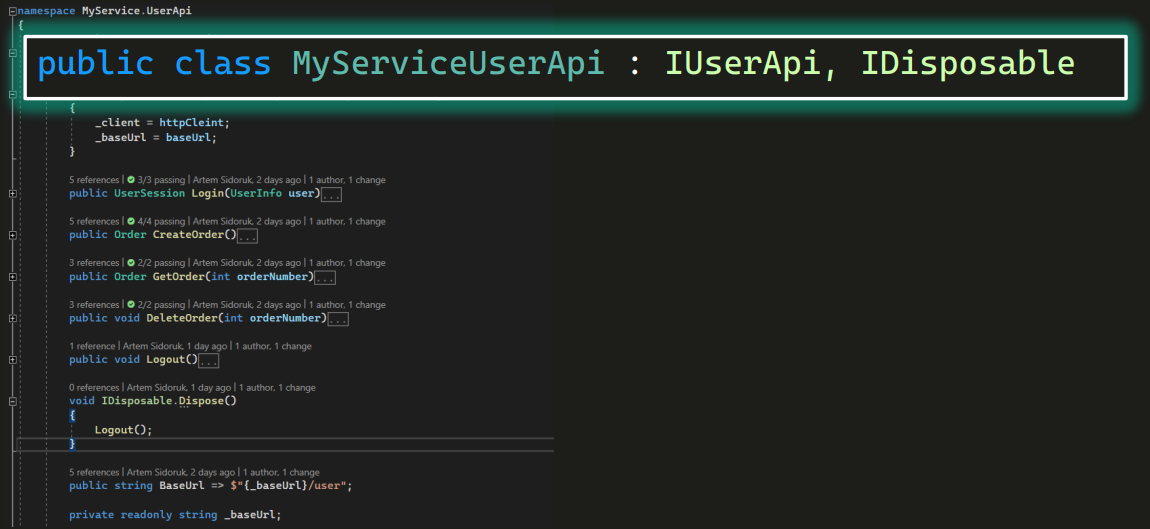
Это обязывает нас имплементировать метод Dispose(), внутри которого мы можем описать то, что нам нужно. Например, если кто-то создает UserApi, ему нужно разлогиниваться.
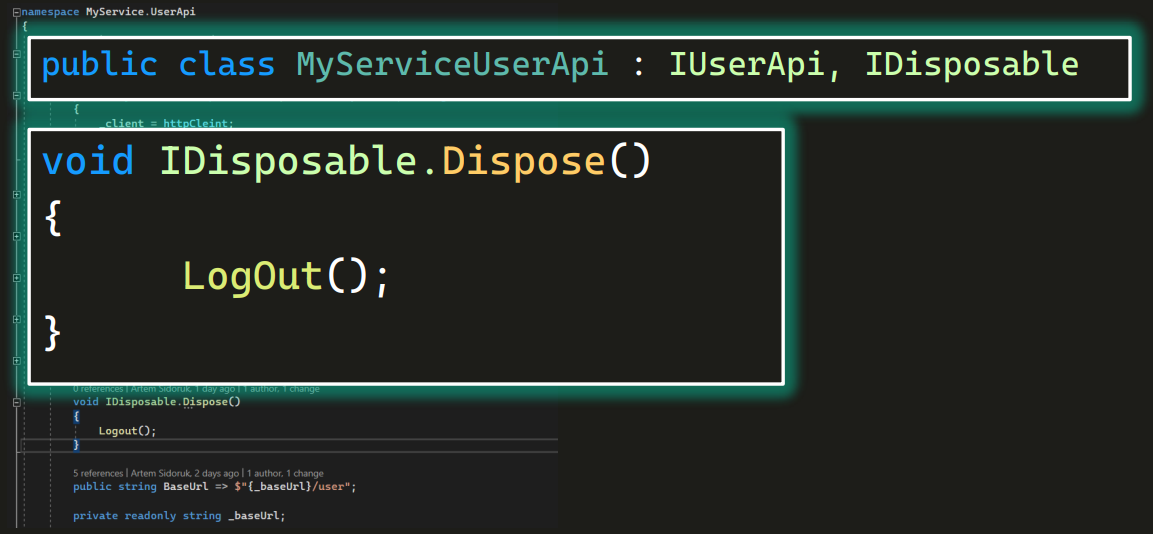
Конечно, мы можем тут построить конструкцию из If: если был один логин, тогда сделай логаут (второго логаута не надо). Но в целом суть в том, что мы можем в методе dispose явно описать, что и как почистить. Аналогично мы можем задать удаление пользователя для adminApi:
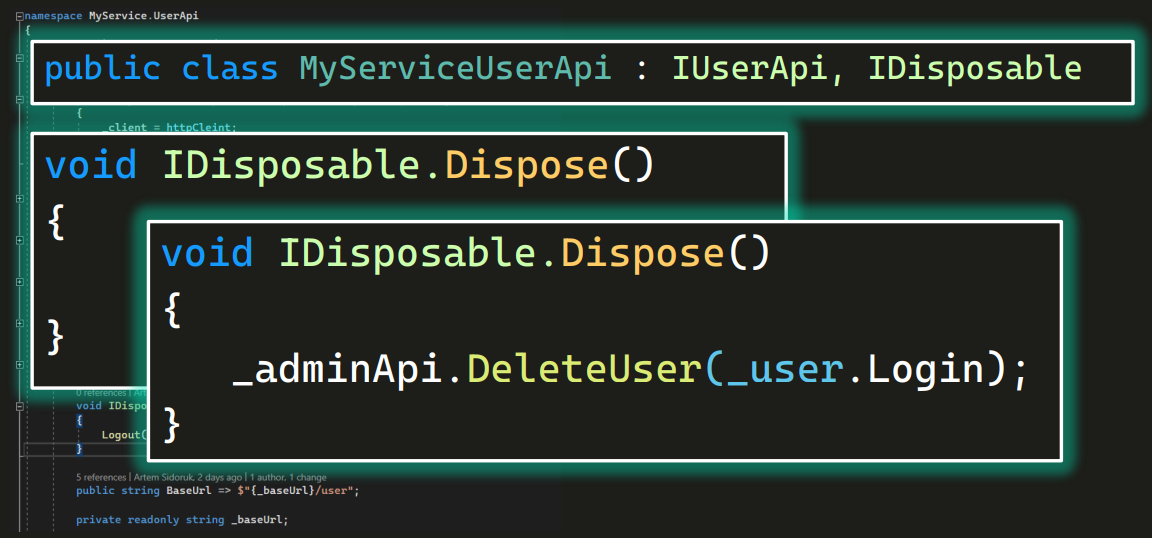
С этого момента мы можем взять методы, помеченные атрибутом TearDown, и если в них ничего специфичного для класса нет, удалить.
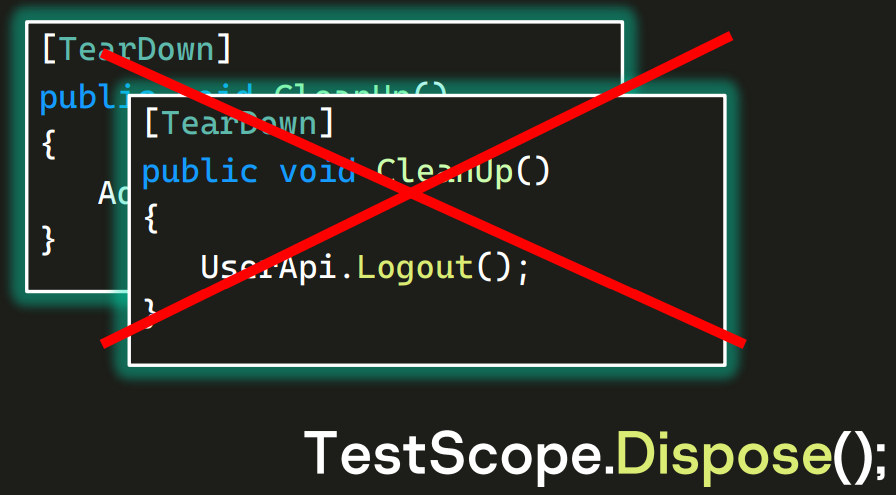
Поскольку мы делаем TestScope.Dispose, контейнер:
- Поймет, что здесь закончился процесс.
- У него были scoped-объекты, он найдет их — UserApi, UserTestService и тому подобные.
- И если они окажутся IDisposable, значит, у них есть метод Dispose() и нужно его вызвать. Соответственно, выполнятся все логауты, удаления пользователей и тому подобное. Причем явно их вызывать нам уже не придется. Контейнер все сделает за нас. И даже в том классе, про который мы когда-то забыли, выполнится очистка — просто потому, что контейнер не сделает исключений.
После всех этих переделок тесты снова можно прогнать. И они снова будут зеленые. Более того, немного улучшится ситуация по утилизации памяти (прирост будет за счет того, что чистятся scoped-объекты).
DI Container != Service LocatorНапоследок хочу кое-что добавить.
Есть понятие «Dependency Injection-контейнер». Это довольно сложная вещь, про которую я попытался рассказать выше. По факту она реализует подход register resolve release:
- register — мы регистрировали компоненты, то есть раскладывали ключи по таксе;
- resolve — просили у контейнера объекты, он их создавал;
- release — утилизировали объекты.
Есть похожий паттерн, который называется ServiceLocator. По сути, это ведро с ключами, которое стоит в центре автосервиса и к которому нужно постоянно бегать, а также целенаправленно складывать эти ключи туда, самому их собирать и так далее… То есть это очень глупая такса, которая сама ключи не собирает, ничего не делает, только прибегает.
Использование ServiceLocator’ов может сделать ваш проект на самом деле хуже, чем он был без DI — просто потому, что есть соблазн сделать вот так:

Написать на той статической переменной контейнера public static. И тогда кто-нибудь обязательно рано или поздно сделает TestBase._сontainer. То есть обратится к торчащей статической переменной напрямую. Возможно, это будет работать. Но нет никаких гарантий, что контейнер там действительно есть (и это не null-объект), что scope начался и какие-то объекты уже созданы, и что там была хоть какая-то регистрация объекта. Проверить все это и поймать ошибки можно будет только в рантайме. Что «очень не очень» (с).
О том, почему так делать не стоит, можно говорить долго (добро пожаловать в комменты, если хотите). Но давайте просто запомним, что никаких паблик-статиков для контейнеров использовать нельзя:
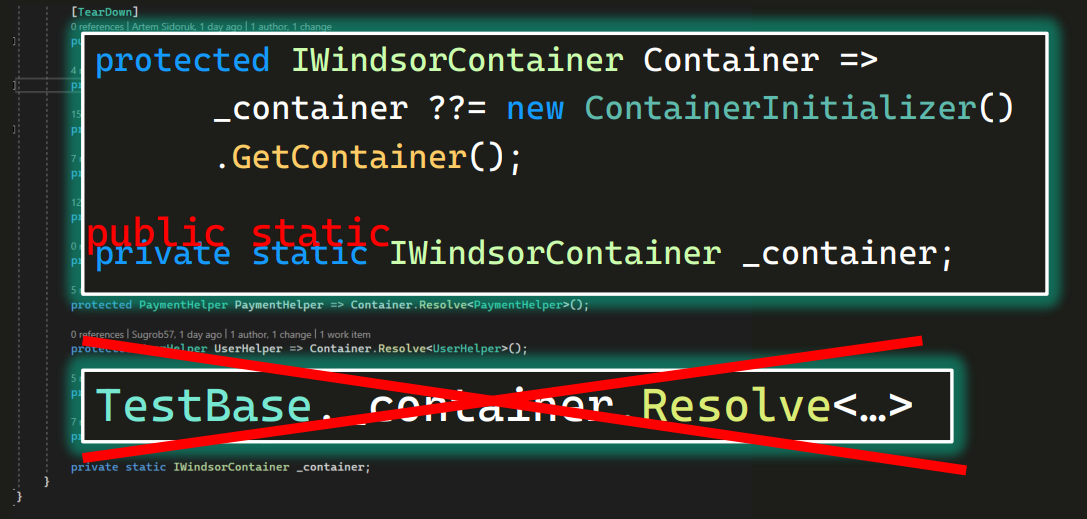
Чем меньше методов и классов знает про существование контейнера, тем лучше. Потому что он должен быть только в базовом классе и нигде больше. Тогда вы не придете к антипаттерну и не реализуете сильную связанность проекта. И не доведете до того момента, когда будет проще переписать заново, чем распутать этот клубок. Поэтому private, и только private. А для инструментов — protected (чтобы были доступны из тестов в классах-наследниках), потому что мы не хотим, чтобы наша такса ходила в соседние автосервисы, откуда нам могут и не вернуть инструмент.
Вместо выводовИтак, мы посмотрели на некоторый тестовый проект, убрали из него явные вызовы конструкторов. Кода стало меньше, и нам теперь не нужно заниматься тем, чем мы не должны заниматься в тестах. Тесты теперь только готовят данные, валидируют их и проверяют экшены. Кстати, контейнеры отлично справляются даже в тех ситуациях, когда у интерфейса есть несколько имплементаций, — я просто не стал усложнять повествование (см. вызов .Named(“MyServiceApi2”)).
Мы всего один раз продумываем, как правильно хранить компоненты. Мы один раз описали LifeStyles, а дальше контейнер сам разберется. Вместе с тем у нас появилась возможность убраться в базовом классе. Это, конечно, очень длинная история, там нужно тщательно все раскладывать. Но контейнеры дали шанс понемногу разобрать базовый класс, а не превращать его в огромного нечитаемого монстра.
Напомню, что все разобранные примеры можно найти на моем GitHub. А если вдруг вам понравится спектр задач и подходы, которые мы используем, приходите к нам в Kaspersky на позицию SDET. У нас много разных команд, которые занимаются внутренними инфраструктурными направлениями и флагманскими продуктами. Здесь всегда есть над чем подумать! Обсудить в форуме |



