Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Азбука ИТНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Python для начинающихНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Инженер по тестированию программного обеспеченияНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
-
Bash: инструменты тестировщикаНачало: 1 октября 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 1 октября 2026
-
Docker: инструменты тестировщикаНачало: 1 октября 2026
-
SQL: Инструменты тестировщикаНачало: 1 октября 2026
-
Git: инструменты тестировщикаНачало: 1 октября 2026
| Принципы юнит-тестирования. Часть первая |
| 29.08.2022 00:00 |
|
Автор: Владимир Четвериков
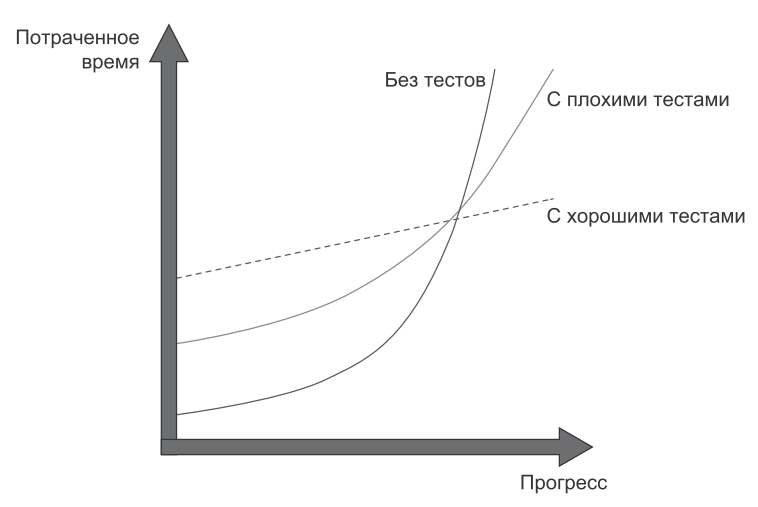
Привет! Меня зовут Владимир, я разработчик команды продукта «Сервис персонализации» в SM Lab. В этом посте я хотел бы рассказать (а в комментариях — обсудить) один очень важный и полезный инструмент разработчика — юнит-тесты. Вы наверняка уже много про них знаете, особенно если они составляют часть ваших рабочих обязанностей. Информации в сети много, проблема в том, что она не всегда полная и недостаточно хорошо структурирована. Мой рассказ будет состоять из двух частей. В этой части я расскажу, что такое юнит-тестирование и для чего это нужно, что такое покрытие тестами, как оно считается и какие есть подводные камни, рассмотрю подходы к изоляции в юнит-тестах и виды зависимостей, а также вопросы, связанные с эффективностью юнит-тестов. Эта статья для всех – кто слышал про них, но не видел, кто приступает к написанию юнит-тестов, и кто их пишет уже давно. Надеюсь, каждый из вас найдет что-то полезное для себя. При подготовке материала очень помогла книга Владимира Хорикова (@vkhorikov ) «Принципы юнит-тестирования». Рекомендую ее всем, кто хочет еще глубже погрузиться в эту тему. Итак, поехали. Что такое юнит-тестирование и для чего оно нужно Приведу одно из устоявшихся определений: юнит-тестирование – это процесс, который позволяет проверить работоспособность отдельных частей исходного кода программы. Зачем мы пишем юнит-тесты? Во-первых, это способ проверить работу нового функционала, который мы пишем. Также в процессе развития программного продукта код периодически нужно рефакторить. В этом случае юнит-тесты позволяют проводить рефакторинг без опасений, что существующая функциональность будет сломана. Помимо этого, юнит-тесты позволяют облегчить обнаружение ошибок и локализовать их поиск. Другое полезное свойство юнит-тестов в том, что, читая их, можно понять, как работают части системы и как их нужно использовать. Это документация, которая живет и меняется вместе с кодом. Какими качествами должен обладать юнит-тестТаких качеств всего три, и они достаточно общие. Юнит-тест должен проверять правильность работы небольшого фрагмента кода – юнита, должен делать это быстро и поддерживать изоляцию от другого кода. По поводу «делать это быстро». В области юнит-тестирования достаточно тяжело определить какие-то границы. Если взять тест, который выполняется за секунду - быстро это или медленно? Всё зависит от того, что это за тест, какие требования к нему. В нашей команде мы опираемся на субъективное восприятие скорости – если, по нашему мнению, тесты проходят быстро – этого достаточно. Как тесты влияют на разрабатываемые нами продуктыДавайте взглянем на следующий график:
Горизонтальная ось «Прогресс» — своего рода жизненный путь разрабатываемого продукта во времени, где нулевая точка - начало разработки этой системы. В начале жизни продукта развивать его достаточно просто: еще не приняты неудачные архитектурные решения, нет кода, который нужно поддерживать или рефакторить. Поэтому в начале мы можем увидеть, что разработка без тестов, если мы будем сравнивать с другими кривыми, требует минимального времени. При дальнейшем развитии, когда продукт обрастает кодовой базой и становится сложнее, скорость разработки начинает замедляться, мы тратим больше времени на одинаковый объём доработок. И по графикам видно, что с хорошими тестами увеличение времени достаточно линейно. С плохими тестами или без тестов рост времени нелинеен, и иногда даже наступает такой момент, когда проще отказаться от текущей реализации системы и переписать ее заново, чем пытаться в неё что-то внести. Исходя из этого, стоит оценивать покрытие кода тестами с точки зрения его жизненного цикла. Если продукт одноразовый, маленький, короткий, который мы написали и потом через какое-то время он будет не нужен, то и, возможно, уровень покрытия тестами нужен достаточно низкий. Тесты имеют хорошее свойство выступать индикаторами низкого качества кода, которое обычно проявляется в высокой связанности, когда части кода плохо изолированы друг от друга, и это создаёт сложность с раздельным тестированием этих частей. Поэтому сложность покрытия юнит-тестами – это хороший негативный признак. Если тяжело писать тесты, то, скорее всего, покрываемый тестами код низкого качества. Правда, это работает только в одну сторону. Мы не можем сказать о том, что если легко писать тесты на код, то он хорошего качества. Также хочу предостеречь от попыток тотального покрытия кода тестами. Стоит помнить о том, что тесты так же, как и основной код, имеют свою стоимость. Это можно увидеть на предыдущем графике – разность по вертикальной оси между началами графиков – без тестов и с тестами. Эта дельта времени и есть стоимость тестов на старте. Тесты требуют как разработки, так и поддержки. Плюс к этому, чем больше кода написано, тем больше потенциальных ошибок там может быть. На тесты мы не пишем тесты, поэтому большой объём тестового кода может содержать ошибки. Также увеличивается время прохождения тестов и уменьшается желание их часто запускать. Как измерить покрытие кода тестамиДля этого есть две чаще всего используемые метрики – процент покрытия строк (code coverage) и процент покрытия логических ветвей (branch coverage) кода.
Как и с легкостью покрытия кода тестами, это хороший негативный признак, но плохой позитивный. Если покрыто всего десять процентов кода, это хороший признак того, что тестов слишком мало. Но даже стопроцентное покрытие тестами не гарантирует хорошего качества тестов. И вот почему. Эти метрики не отражают некоторые важные детали, такие как наличие и полноту проверок (asserts). Мы можем написать тест, который не имеет проверок вообще. То есть он будет запускать наш основной код, но по факту не будет иметь никакой ценности. И ещё, эти метрики не оценивают код во внешних библиотеках. Они оценивает только тот код, который написали мы. Вот короткий пример:
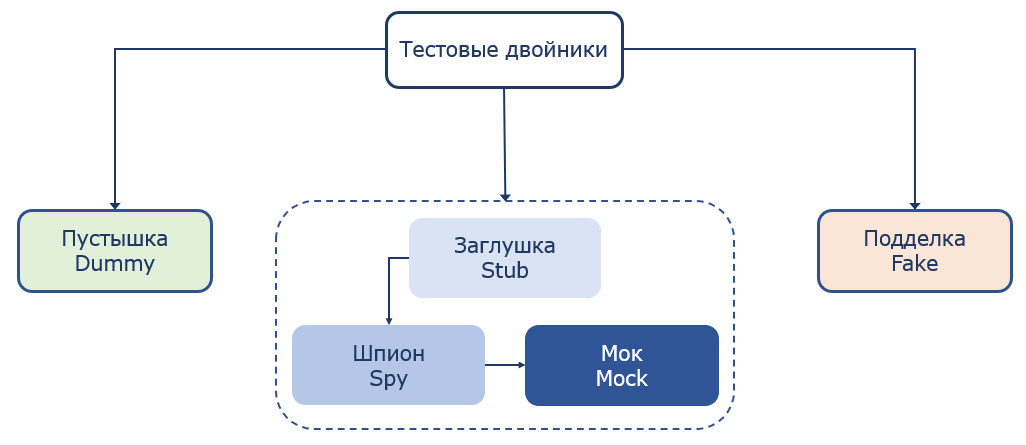
Есть метод, который принимает строку и превращает её в число. Очень простой метод. На него написан простой тест, который передаёт строку со значением «5» и сравнивает число 5 с тем, какое число возвращает метод. Если мы посмотрим на этот тест и попробуем оценить метрики покрытия, мы увидим, что для этих метрик покрытие будет 100%. Но, к сожалению, если мы заглянем в библиотечный метод parseInt, мы увидим, что на самом деле мы проверили только один из четырех вариантов. Поэтому с одной стороны у нас покрытие 100%, но с другой стороны мы покрыли по факту только 25% кода. Поэтому на эти метрики стоит ориентироваться, но не слепо им доверять. В нашей команде мы ориентируемся на уровень в 80% покрытия кода. Тестовые двойникиПомощниками в тестировании выступают «тестовые двойники» (test doubles). Их выделяют 5 видов.
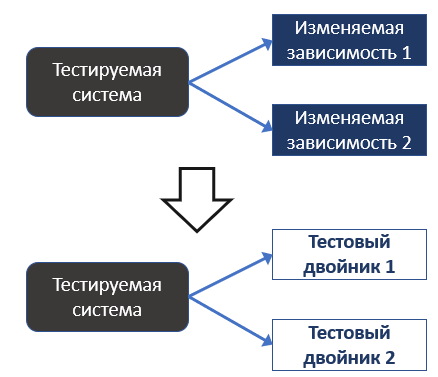
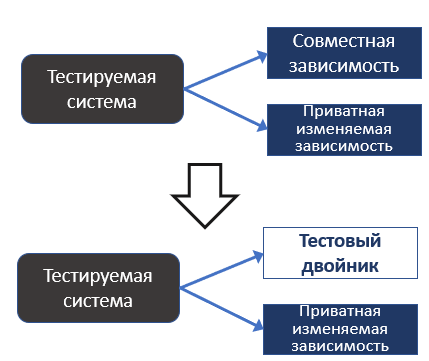
Пустышка (Dummy). Такой двойник не содержит поведения и используется в качестве заполнителя параметров. Никогда реально не вызывается. Подделка (Fake). Это реально написанная реализация, которая имеет более простую логику, чем реальный аналог. Есть ещё три вида похожих между собой тестовых двойников. Но есть и различия. Заглушка (Stub) - имеет заранее подготовленные ответы на вызовы методов. Практически не имеет логики. Шпион (Spy). Более сложная система. Это гибрид реального объекта и мока. Он имеет поведение реального объекта, но может записывать определенную информацию о вызове его методов. Также можно переопределить поведение некоторых методов. Мок (Mock). Самый сложный из тестовых двойников, но дающий наибольший контроль. Может иметь сложную логику ответов, зависящих от параметров вызовов, их количества, генерировать исключения при вызове методов с неопределенным поведением и имеет другой, полезный для тестирования функционал. Все тестовые двойники, за исключением fake, в основном создаются с помощью фреймворков, с которыми мы часто работаем. Для Java это Mockito, для Kotlin – MockK, для других языков такие фреймворки тоже есть. Изоляция и виды зависимостейЧто такое зависимость? Класс чаще всего не существует изолированно в коде. Он использует какие-то другие части программы. Зависимости – это то, что использует класс для своей работы. Это могут быть другие классы, базы данных, файловые системы, сторонние сервисы и прочее. Зависимости с точки зрения изменяемости делятся на изменяемые – те, состояние которых может изменить тест, например, переменные или база данных, и неизменяемые – например, константа или неизменяемый объект. Зависимости с точки зрения возможности влияния тестов друг на друга делят на совместные и приватные. Совместные зависимости (shared). Через такие зависимости тесты могут влиять на результаты друг друга. Например, статические изменяемые поля класса, база данных. Это изменяемые зависимости. Приведу пример - два теста работают с одной и той же таблицей в базе данных. Если такие тесты будут запущены параллельно, то может получиться ситуация, что один тест добавит данные в таблицу, а другой сразу после этого может очистить таблицу. Первый тест попытается прочитать данные из таблицы, и, не обнаружив нужных данных, завершится ошибкой. Приватные зависимости (private). Это зависимости, не являющиеся совместными. Они могут быть как изменяемыми, так и неизменяемыми. Та же база данных может быть как совместной, так и приватной зависимостью. Совместной она может выступать, когда все тесты работают с одной базой. Приватной зависимостью база данных может выступать в случае, когда для каждого теста поднимается отдельная база данных, например в docker-контейнере. В этом случае тесты не смогут повлиять друг на друга через базу. Есть два подхода (школы) к пониманию изоляции: так называемые классическая и лондонская школы. Лондонская школа понимает изоляцию тестируемого кода как изоляцию от его изменяемых зависимостей. Все изменяемые зависимости (совместные и приватные) заменяются на тестовые двойники – «мокируются».
В этом подходе есть следующие плюсы:
Есть и минусы. Основной - то, что в этом случае тесты чаще привязываются к деталям имплементации тестируемой системы, что вызывает хрупкость тестов. Также при большом количестве зависимостей настройка моков может быть достаточно трудоемкой. Мы в команде чаще всего используем этот подход. Классическая школа подразумевается изоляция не тестируемого кода, а тестов друг от друга. Если тесты через зависимость могут влиять друг на друга при параллельном запуске, то эта зависимость меняется на тестовый двойник. Все остальные зависимости, даже если они изменяемые, используются как есть. То есть при таком подходе зачастую тестируется одновременно несколько связанных классов.
У этого подхода также есть плюсы и минусы. Для тестирования необходимо выстраивать граф классов, это становится достаточно сложным, когда используется много зависимостей. С другой стороны, не скрываются проблемы плохого дизайна кода и его высокой связанности. При таком подходе юнитом является не класс, как в Лондонской школе, а единица поведения, и она часто не ограничивается одним классом. При изменении одного из классов падают тесты и всех зависимых классов. Иногда тяжело понять причину массового падения тестов. Для упрощения отладки стоит чаще запускать юнит-тесты, что поможет понять, какие изменения в коде повлияли на тесты и локализуют поиск. Это также позволяет понять, какие классы наиболее важные и на какие нужно обратить особое внимание. Эффективность юнит-тестовЧтобы формально как-то измерить эффективность наших тестов, мы можем представить ее как произведение четырёх параметров.
Пусть каждый из параметров будет числом от 0 до 1. В соответствии с этим можно понять, что если какой-то из параметров равен нулю, то и, соответственно, вся эффективность, насколько бы высокими ни были другие параметры, будет также равна нулю. Давайте рассмотрим следующие отношения между поведением тестируемого кода и теста:
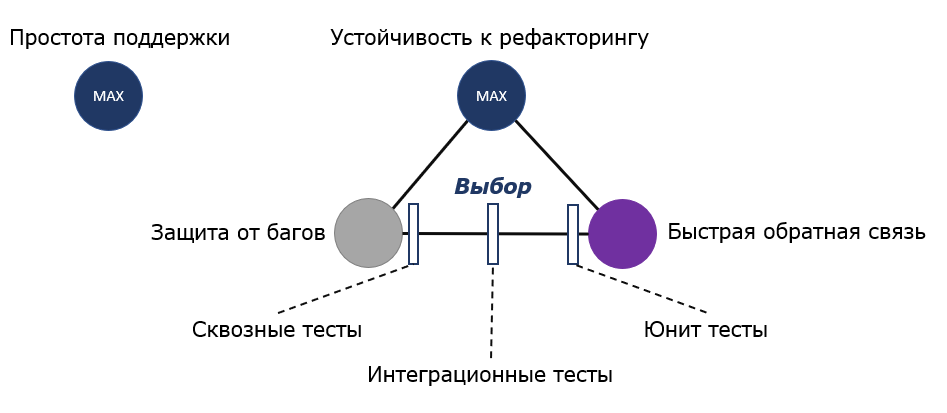
В случаях, когда функциональность работает правильно и тест проходит (отрицательное срабатывание) или функциональность работает неправильно и тест не проходит (истинное срабатывание) – это ожидаемое поведение теста. В этом случае можно считать, что тест работает правильно. Есть ещё и две другие области. Ложное срабатывание - функциональность работает правильно, но тест не проходит. Это значит, что тесты, имеют низкую устойчивость к рефакторингу. Чаще всего это означает, что тесты завязаны на детали имплементации и будут падать при изменении реализации тестируемого кода без изменения функциональности. Низкая защита от багов – случай, когда тест проходит, но функциональность работает неправильно. Из четырех атрибутов для юнит-тестов один должен быть высоким – это простота поддержки, потому что иначе на тесты будет потрачено недопустимо много времени из-за их большого количества. Простота поддержки – характеристика независимая. Оставшиеся три – взаимосвязаны.
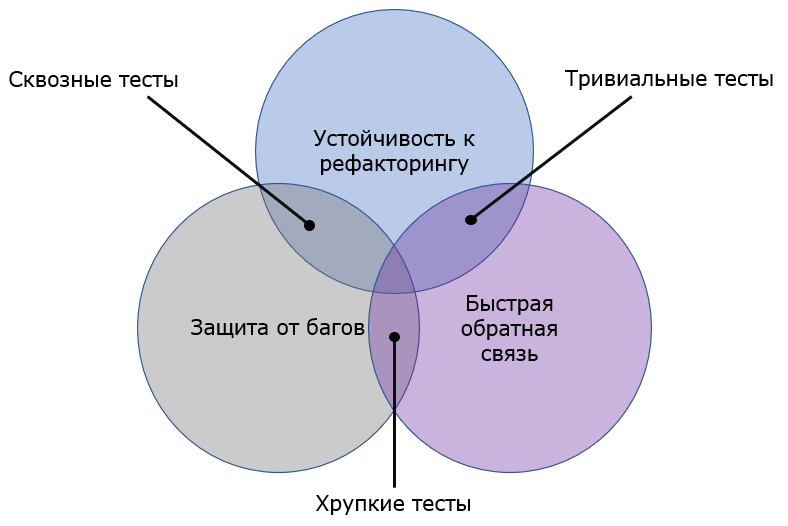
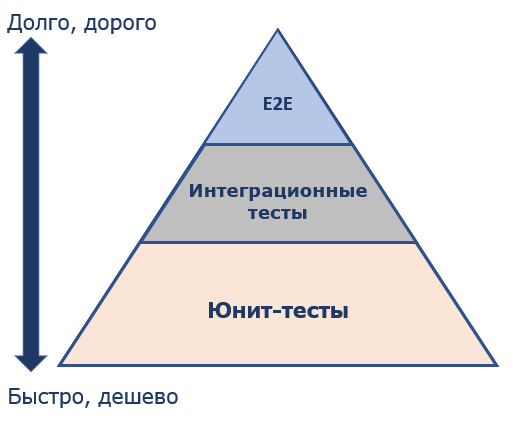
Сквозные тесты (e2e-тесты) задействуют большой объём кода, проходя через цепочку тестируемых элементов или систем, поэтому имеют хорошую защиту от багов. Такие тесты устойчивы к рефакторингу, так как ориентируются на внешний интерфейс – API, и ничего не знают про детали реализации. Такие тесты достаточно медленные - и с точки зрения написания, и с точки зрения прохождения. Тривиальные тесты могут быть устойчивы к рефакторингу и иметь быструю обратную связь. Например тест, написанный на getter – метод получения значения приватного поля. Такой тест переживет рефакторинг getter-а (если такой вообще будет) и будет быстро проходить. Но пользы от такого теста не будет. Можно написать тест, который будет хорошо защищать от багов, иметь быструю обратную связь, но при любом малейшем рефакторинге тестируемой системы будет падать. Он будет падать даже тогда, когда тестируемая функциональность работает правильно. Сначала на такие тесты перестают обращать внимание, потом их отключают или удаляют. Пользы от таких тестов тоже мало. Это хрупкие тесты. Перед тем как разобраться, на какие из характеристик стоит ориентироваться при написании различных тестов, напомню про всем известную пирамиду тестирования
Участки пирамиды подразумевают количество необходимых тестов данной категории. Чем больше площадь, тем больше необходимо тестов. Чем ниже находятся на пирамиде тесты, тем:
Перечисленные факторы влияют на выбор между устойчивостью к багам и быстрой обратной связью. Устойчивость к рефакторингу желательно держать максимальной, поэтому что это величина достаточно бинарная – тесты либо устойчивы к рефакторингу, либо нет. Защита от багов и быстрая обратная связь – более эластичны, поэтому выбор идет между ними.
Сквозных тестов меньше всего – они довольно медленные и не всегда отличаются простотой в поддержке. Но они задействуют большой объем кода и покрывают в основном критичную функциональность, поэтому у них высокая защита от багов. Юнит-тестов в основном самое большое количество, поэтому для них важна скорость выполнения. Количество интеграционных тестов меньше, чем юнит-тестов, но больше, чем сквозных, поэтому они занимают промежуточное положение между защитой от багов и быстрой обратной связью. На этом первая часть закончена. В следующей части будет рассмотрена структура юнит-теста, поделюсь тем, какие подходы используются у нас в команде. Расскажу про стили юнит-тестирования, принципы рефакторинга для эффективных юнит-тестов, рассмотрю некоторые антипаттерны при написании тестов. |