Что пишут в блогах
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Python для начинающихНачало: 23 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Азбука ИТНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
| ПОДЗАПРОСЫ |
| 11.05.2021 12:09 |
|
Автор: Роман Буданов, тренер курса “Первый Онлайн ИНститут Тестировщиков” (компания “Лаборатория Качества”)
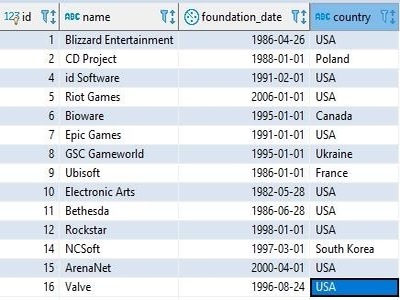
Всем доброго времени суток, мои маленькие (и не очень) любители (и не очень) SQL! На курсе ПОИНТ мы с нуля разбираем построение запросов, обучаемся основным операторам, работе с разными типами данных, но сейчас я хочу с вами поговорить про один из полезных инструментов, увы, оставшихся за рамками ПОИНТ — сегодня я хочу рассказать вам про такую полезную штуку, как подзапросы и показать несколько вариантов их приготовления. 1. Что такое подзапросы?А начать свой рассказ я хочу с объяснения того, что же такое этот ваш (наш) подзапрос — по сути своей, это запрос внутри запроса, с результирующей выборкой которого вы можете творить очень много разных вещей — от вытаскивания из неё всех данных (блок FROM) до задания условий на её основе(блок WHERE). То есть сначала у вас выполняется подзапрос, возвращает свою результирующую выборку, а уже потом, основываясь на результатах работы подзапроса, формируется результирующая выборка основного, “внешнего”, запроса. Впрочем, на словах не особо понятно, давайте покажу на примерах. Примеры я буду приводить, основываясь на учебной базе данных ПОИНТ. Её схема выглядит вот так: 2. Места для использования подзапросаa. Блок FromСамый банальный и бесполезный, на первый взгляд, метод применения подзапросов — когда результирующая выборка копирует собой результирующую выборку подзапроса. Пример: Запрос SELECT * FROM company вернёт нам вот такую результирующую выборку:
А запрос SELECT * FROM (select * from company) c … вернёт нам абсолютно такую же результирующую выборку!
Чудеса, да и только. Как это работает:
Казалось бы — абсолютно бесполезная штука, лишняя трата времени, нервов и ресурсов. Так оно, в принципе, и есть… До тех пор, пока не придёт осознание того, что в блоке FROM есть еще и такая полезная штука, как, например, JOIN - да, джоинить с подзапросом тоже можно! И вот тут-то мы начинаем понимаааааааать. Но еще не до конца. Поэтому давайте разберём пример: допустим, мы ищем покупки всех пользователей, у которых логин заканчивается на букву “а”. Можно написать так: select t.*, a.id, a.login from transactions t join account a on t.account_id=a.id where a.login like '%a' и этот запрос нам вернёт такую результирующую выборку (выполнялся 3мс).
А можно написать так: select * from transactions t join (select id, login from account where login like '%a') a on t.account_id=a.id и этот запрос вернёт нам абсолютно такую же результирующую выборку,
но сделает это втрое быстрее — за 1 мс! Да, понятно, что выигрыш в 2 мс очень не солидно смотрится — но вы учтите, что у нас учебная база в 5 таблиц и, суммарно, 200 записей. А если представить, что записей не 200, а, допустим, 20000, а то и все 200000 (а такое часто бывает на “боевых” проектах — там просто ОГРОМНЫЕ базы), то выигрыш в 3 раза смотрится уже не так плохо, а? Давайте теперь подумаем, почему второй вариант работает быстрее. Как работает первый запрос, с обычным джоином?
Как работает второй запрос, с “подзапросным” джоином?
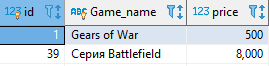
То есть если в первом случае мы джоиним таблицу в 256 записей с таблицей в 20 записей, то во втором случае мы джоиним таблицу в 256 записей с таблицей в 3 записи. А ведь внутри подзапроса можно точно так же использовать джоины… Так что прирост быстродействия — налицо! b. Блок WHEREА сейчас начнётся самое зрелищное — условия формирования результирующей выборки внешнего запроса, основывающиеся на результате работы подзапроса! Как это может быть? Да очень просто, на самом деле: давайте представим, что нам нужно вывести логины пользователей, купивших самую дорогую игру. Для этого нам сначала нужно сделать что? Правильно, эту самую игру надо определить. Делаем так: select max(price) from game находим цену самой дорогой игры. Нашли, отлично. Получилось 8000. Дальше что? Можно, конечно, ручками вбить эти самые 8000 в другой запрос и получить искомое, да. Но это будет справедливо для текущего “наполнения” базы данных. А БД штука такая непостоянная… Я сейчас серьёзно — база, как правило, постоянно обновляется, получая “свежие” записи. Поэтому нам нужно сделать так, чтобы в одном запросе и самая дорогая игра находилась, и люди, её купившие. Здесь-то нам на помощь и приходит наш верный друг — подзапрос. Заручившись его помощью, мы идём писать. Пишем, пишем и получаем вот, что: select a.login from account a join transactions t on a.id=t.account_id join game g on t.game_id=g.id where g.price=(select max(g1.price) from game g1) получаем
То есть для начала мы находим цену самой дорогой игры, а потом, через список транзакций, находим людей, которые купили игры, чья цена равна максимальной. Если вы принципиально хотите цепляться к айдишнику, а не к цене, то можно поизвращаться и сделать несколько по-другому: select a.login from account a join transactions t on a.id=t.account_id join game g on t.game_id=g.id where g.id= ( select id from game g1 where g1.price=(select max(price) from game g2) ) На выходе получаем абсолютно то же самое:
Да, глаза вас не обманывают — вы увидели именно то, что увидели — это подзапрос внутри подзапроса. Да, так тоже можно было. Почти уверен, что вы сейчас задались — вопросом: “А насколько глубока кроличья нора?”, поэтому сразу отвечу: “Имя им легион”. Вложенным подзапросам, я имею в виду. Т. е. вы можете плодить столько вложенных друг в друга подзапросов, сколько вашей душе (и здравому смыслу) угодно. И это действительно бывает полезно! Как это работает: как я и говорил, разворачивать “матрёшку” из подзапросов мы начинаем с самого “дна” — с последнего вложенного подзапроса, то бишь:
Думаю, вы уже задались вопросом: “А почему нельзя было в одном подзапросе вывести и цену самой дорогой игры, и её айдишник, а не городить один подзапрос в другом?”. А всё потому, дамы и господа, что оператор max(), как и любая уважающая себя агрегатная функция, нормально работает только по одному полю — т. е. если написать так: select id, game_name, max(price) from game то в результате мы увидим вот такую красоту: Казалось бы - всё ок, да? Вывелся айдишник игры, вывелось её название и цена, как заказывали. Но, вот незадача — это неправильные данные. Проверяем: select id, game_name, price from game where id=1 or price=8000 Если бы подвоха не было, то этот запрос вернул бы нам одну-единственную запись — ту же, что и предыдущий запрос. А мы получаем вот это: то есть мы видим, что поля id и game_name у нас запрос вывел от первой (по порядку) записи в таблице, а в поле price — самую большую цену, как и заказывали. Вот такой вот обман. MySQL просто вежливый и не стал нам говорить: “Что за ты бред несёшь, я это выполнять не буду” (как сделала бы почти любая другая СУБД), а взял и выполнил тот бред, что мы написали. Это первый пункт ответа на вопрос “А почему нельзя было в одном подзапросе вывести и цену самой дорогой игры, и её айдишник, а не городить один подзапрос в другом?”. Второй пункт заключается в том, мы используем оператор математического сравнения — а в этом случае подзапрос должен возвращать только одно значение (одно поле, одна запись), чтобы MySQL не растерялся и не спросил: “А с чем именно в подзапросе мне сравнивать значение g.id?”. Вы же не пишете в реальной жизни a=b,c,d,e,f ? Нет, вы пишете a=b — одно значение слева от знака равенства, одно - справа, чтобы не возникло путаницы. Так и здесь — запрос должен возвращать одно-единственное значение, и тогда всё у вас будет работать верно. 3. Основные операторы взаимодействия с подзапросами в блоке WHEREa. Операторы сравненияРаз уж я начал рассказывать про операторы сравнения, давайте ими и продолжу — особенно если учесть то, что, по сути, всё основное я уже рассказал. К вышесказанному добавить хочу только то, что сравнивать можно не только знаком “равно” = , но и всеми остальными логическими операторами: больше > (находим всех пользователей, которые купили игры, стоящие дороже самой дорогой игры): select a.login from account a join transactions t on a.id=t.account_id join game g on t.game_id=g.id where g.price>(select max(g1.price) from game g1) меньше < (находим всех пользователей, которые купили игры, стоящие дешевле самой дорогой игры): select a.login from account a join transactions t on a.id=t.account_id join game g on t.game_id=g.id where g.price<(select max(g1.price) from game g1) и не равно != (находим всех пользователей, которые купили игры, стоящие дороже или дешевле самой дорогой игры): select a.login from account a join transactions t on a.id=t.account_id join game g on t.game_id=g.id where g.price!=(select max(g1.price) from game g1) b. Операторы вхождения во множествоПомните, выше мы с вами писали прекрасный запрос на поиск людей, купивших самую дорогую игру? Тот, который напоминал капусту — с двумя вложенными подзапросами? Вот он, красавец: select a.login from account a join transactions t on a.id=t.account_id join game g on t.game_id=g.id where g.id=(select id from game g1 where g1.price=(select max(price) from game g2)) Он, конечно, всем хорош, но, увы, как и все в этом мире, неидеален. В чём же заключается его неидеальность, вполне резонно спросите вы? А в том, что запрос этот будет работать только в том случае, когда у нас в базе всего одна “самая дорогая” игра. А может у нас быть в базе несколько игр с одинаковой самой высокой ценой? Да запросто, как два байта переслать! И в этом случае у нас запрос споткнётся. Угадаете, почему? Прааааавильно, потому что “внешний” подзапрос вернёт больше одного значения. Что с этим делать? Обратить внимание на операторы вхождения значения в множество, IN и NOT IN. Честно говоря, за проверку вхождения в множество отвечает только один из них, IN. NOT IN делает, как вы, наверное, догадались, диаметрально противоположную проверку. Так вот, раз уж у нас “внешний” подзапрос будет выводить не одно значение, а несколько (читай — множество), то мы смело можем заменить в нашем запросе знак равенства оператором IN, вот так: select a.login from account a join transactions t on a.id=t.account_id join game g on t.game_id=g.id where g.id in (select id from game g1 where g1.price=(select max(price) from game g2)) и всё у нас прекрасно заработает. А как оно заработает? Да достаточно просто на самом деле:
Вот видите? Как я и говорил, всё достаточно просто. А если бы мы заменили в запросе IN на NOT IN, тогда бы запрос выдавал нам все транзакции, в которых НЕ участвовали самые дорогие игры. c. Операторы существования записейНе пугайтесь страшного названия, мои дорогие читатели — не так страшен чёрт, как его малюют. Сейчас я вам это докажу. Смотрите — этих операторов, как и со множествами, всего 2 — EXISTS и NOT EXISTS. И опять, как и раньше, за проверку существования записей отвечает только EXISTS. NOT EXISTS проверяет, что записей не существует. Если говорить чуть подробнее, то EXISTS проверяет, что подзапрос вернул непустую результирующую выборку. А NOT EXISTS, соответственно, пустую. Давайте пример: допустим, нам надо найти всех пользователей, у которых нет ни одной игры, вышедшей в нечётный день месяца. Запрос будет выглядеть так: select * from account a where not exists ( select t.account_id from transactions t join game g on t.game_id=g.id where day(g.Release_date)%2=1 and t.account_id=a.id ) и вернёт он нам пустую результирующую выборку. Нет, это не потому, что запрос неверный. Это потому, что подходящих записей в базе просто нет — да, и такое бывает. Теперь давайте с вами посмотрим, как это работает (для удобства объяснения давайте представим, что СУБД обрабатывает записи в таблице по очереди). Как это работает:
То есть, грубо говоря, для каждой записи таблицы account создаётся отдельный подзапрос, и СУБД проверяет, вернул этот подзапрос пустоту или нет. Как вы, наверное, заметили, здесь используется такая интересная штука, как связь между данными из внешнего запроса и данными из внутреннего запроса (то самое условие t.account_id=a.id в подзапросе) — здесь оно просто необходимо, т. к. оператор NOT EXISTS не даёт нам доступа к данным подзапроса — он только говорит нам, вернул ли запрос пустоту, как мы того ожидали, или нет, и мы не можем проверить, для какой именно записи из таблицы account этот подзапрос был создан. ЗаключениеВот, в принципе, и всё, что я хотел вам сегодня рассказать. Надеюсь, эта статья была для вас полезна и помогла вам разобраться в повадках этих грудоломов (личинок Чужих из одноименного фильма) от мира SQL. Интересных вам задач и объёмных БД, дамы и господа! |