Что пишут в блогах
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
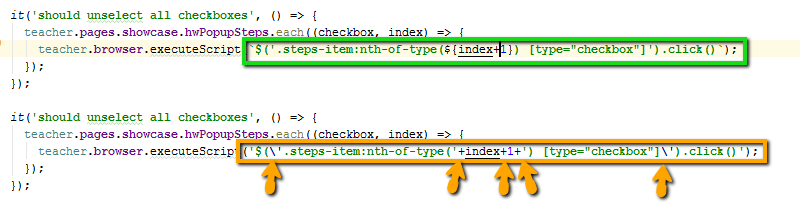
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Python для начинающихНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Азбука ИТНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
| Автотестирование: десять лайфхаков от команды Skyeng |
| 19.11.2019 00:00 |
|
Привет, я Андрей Шальнев, QA Automation Lead в проекте Skyeng Vimbox. В течение года мы с командой занимались оптимизацией процессов автоматического тестирования и сейчас вплотную подошли к ее финальной стадии. А это хороший повод выдохнуть, пересмотреть бэклог и подвести какие-то промежуточные итоги. Для Хабры я решил сделать подборку из десяти наиболее полезных и при этом простых вещей, которые помогли нам справиться с задачей оптимизации автотестов. Надеюсь, статья пригодится QA-командам в растущих компаниях, где старые процессы тестирования уже не справляются с нагрузкой, и вопрос реорганизации встает ребром.
Как у нас сейчас устроены автотесты Vimbox использует Angular для фронтенда, поэтому тесты мы пишем на довольно классическом для этого решения стеке – Protractor+Jasmine+JS/Typescript. За год мы существенно переработали сьют regression тестов. В начальном виде он был избыточен и не очень удобен – тесты по несколько сотен строк со временем прохождения 5-10 мин, при такой длине отдельного тестового сценария он очень часто не доходит до конца по причине ложного фейла. Сейчас разделили тесты на более короткие и стабильные сценарии, используем failFast, чтобы время прогона получалось приемлемым (тест, упавший в середине, не будет пытаться выполнить каждый следующий шаг и дожидаться его падения таймаутом). Кроме того, избавились от избыточных проверок: следим за тем, чтобы конкретная фича была работоспособна в целом, но не пытаемся проверять ее во всех возможных вариациях. Aвтотесты разделены по приоритетам. Небольшой набор самых приоритетных – User acceptance test (UAT) – запускается каждый час по таймеру на проде, после деплоя основных проектов и при тестировании задач на тестовых стендах. На стендах процесс выглядит так: разработчик переводит задачу в тестирование, QA деплоит ее к себе на стенд и запускает тесты – и UAT, и regression. В UAT у нас около 150 кейсов, regression – около 700 тестов, он постоянно дополняется. Большинство кейсов, относящихся к важным и критичным, этот сьют покрывает примерно на 80% и запускается на каждой итерации. Десять лайфхаков
Делитесь своими лайфхаками и мыслями в комментах!!! |