Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Азбука ИТНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Python для начинающихНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Инженер по тестированию программного обеспеченияНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
-
Bash: инструменты тестировщикаНачало: 1 октября 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 1 октября 2026
-
Docker: инструменты тестировщикаНачало: 1 октября 2026
-
SQL: Инструменты тестировщикаНачало: 1 октября 2026
-
Git: инструменты тестировщикаНачало: 1 октября 2026
| Автоматизируй это! Как мы улучшали интеграционное тестирование |
| 08.10.2019 00:00 |
|
В давние времена у нас было всего несколько сервисов, и выложить за сутки обновление более чем одного из них на production — было большой Приемочное end-to-end тестированиеЕщё не так давно при релизе каждого компонента прогонялись только unit- и компонентные тесты, а после этого на полноценной тестовой среде выполнялись лишь несколько самых важных end-to-end сценариев перед выкладкой сервиса в продакшен. Вместе с ростом числа компонентов стало экспоненциально увеличиваться и число связей между ними. Зачастую — совсем нетривиальных связей. Вспоминаю, как недоступность сервиса выдачи маркетинговых данных поломала регистрацию пользователей напрочь (разумеется, на короткое время). Цикл приемочного тестированияДля проведения приемочного тестирования определили такой цикл:
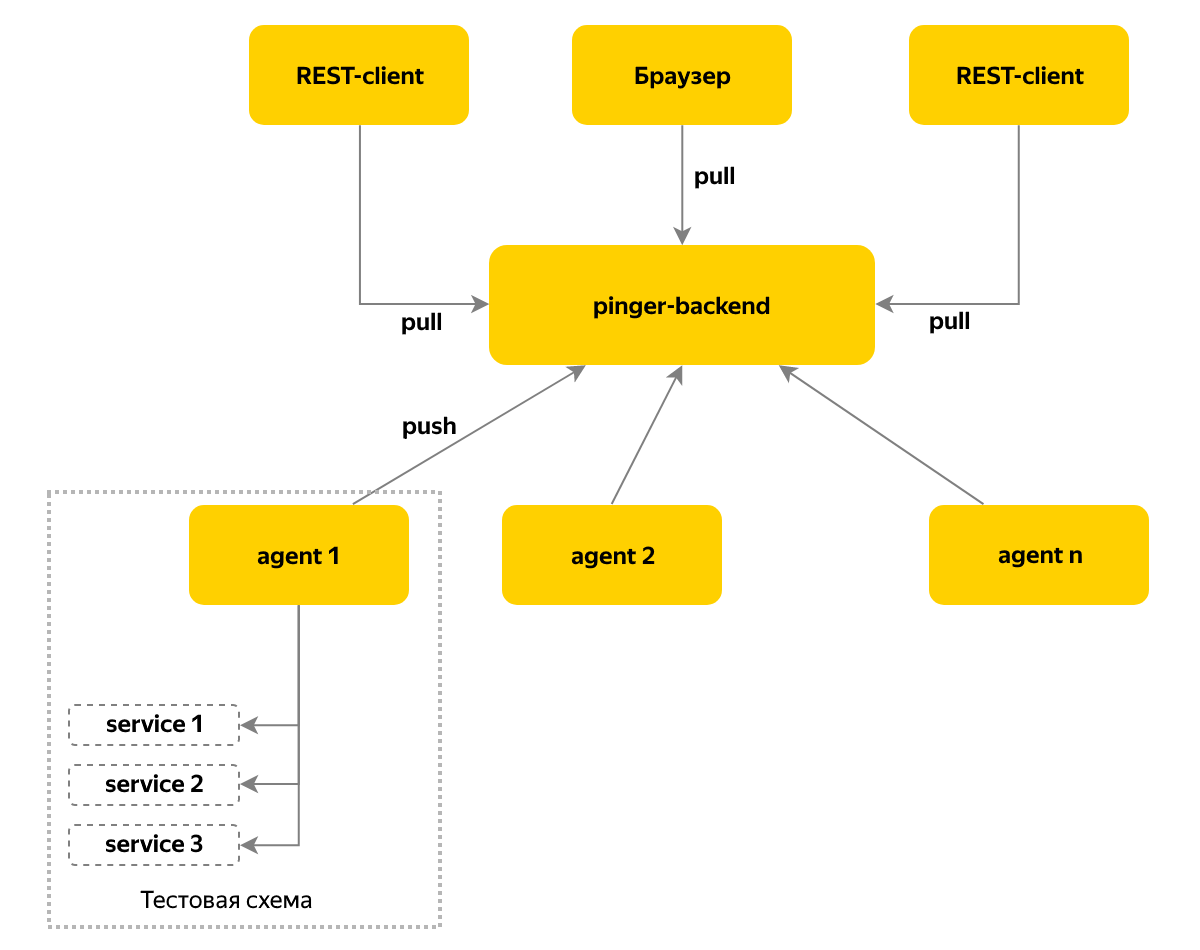
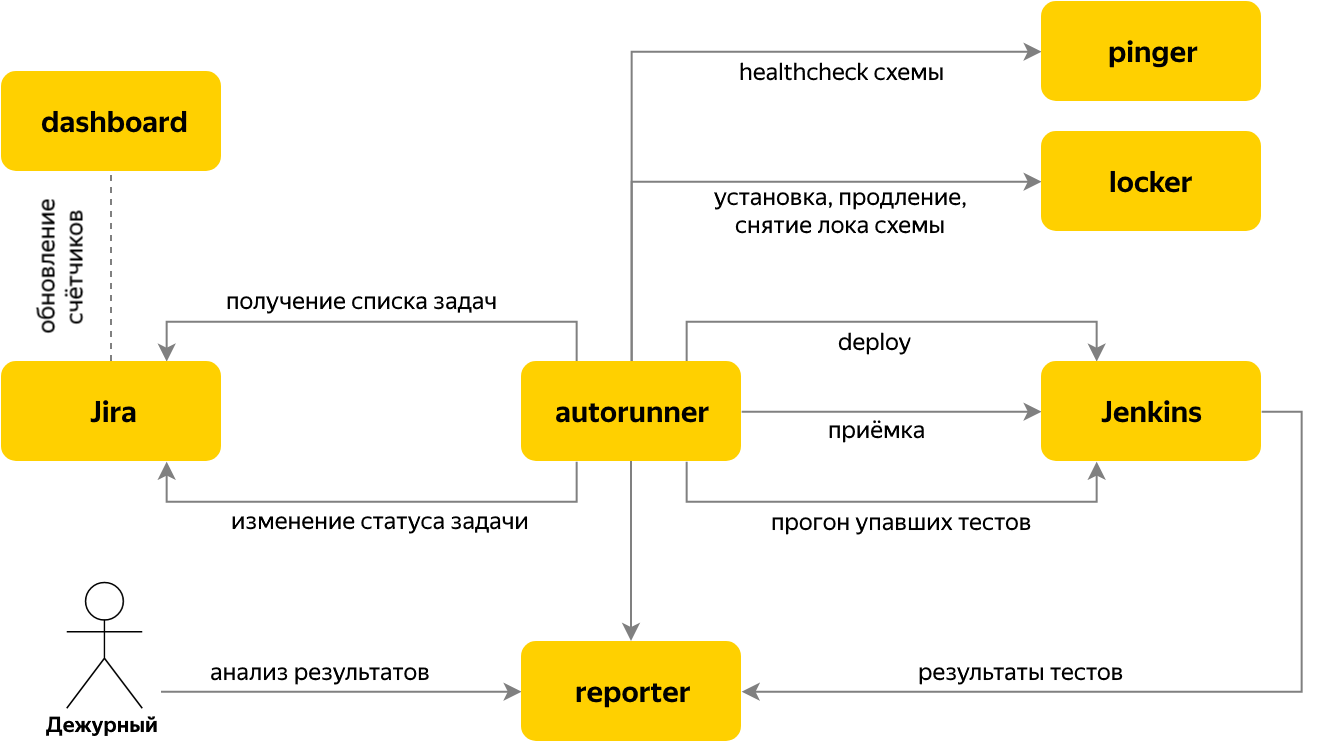
Бот-мониторщикМы поняли, что отслеживание новых задач в Jira и оповещение о них — это важные процессы, которые быстро и просто автоматизируются. Так появился бот, который этим занимается. PingerМы решили упростить проверку того, что во время развертывания в тестовой среде не случилось ошибок сборки или установки и что поднялась именно нужная версия компонента, а не какая-то другая. Свои версию и статус компонент отдает по протоколу HTTP. И проверка того, что сервис возвращает корректную версию, оказалась бы простой и понятной, если бы разные компоненты не были написаны на разных языках — какие-то на Node.js, какие-то на C#. Вдобавок наши самые массовые сервисы на Java тоже отдавали версию в разном формате. LockerПришло время более сложных задач — автоматического обновления компонентов и запуска тестов. На тот момент у нашей команды уже было 3 тестовых стенда в OpenStack для проведения приемочных испытаний, и сначала нужно было решить проблему управления ресурсами тестовых стендов: будет неприятно, если при прогоне тестов на систему «покатится» обновление следующего релиза. Ещё бывает, что тестовый стенд отлаживают, и тогда не стоит использовать его для приёмки. ДежурствоЧтобы равномерно распределить между членами команды нагрузку по разбору результатов прогонов тестов, мы придумали ежедневные дежурства. Дежурный работает с задачами на приемочное тестирование релизов, разбирает упавшие автотесты и репортит баги. Если дежурный понимает, что не справляется с потоком задач, он может попросить помощи у команды. В это время остальные члены команды занимаются задачами, не связанными с релизами. ReporterОдна из задач, с которой мы столкнулись, когда ввели дежурства, — необходимость передачи знаний от одного дежурного к другому, например, о падающих на новом релизе тестах или специфике обновления какого-то компонента.
Так появился сервис Reporter. В него мы пушим результаты прогона тестов в реальном времени в процессе тестирования. В сервисе организована база известных проблем или багов, которые слинкованы с конкретным тестом. Также была добавлена публикация на wiki-портале компании сводного отчета по результатам прогона из репортера. Это удобно для менеджеров, которые не хотят погружаться в технические детали, которыми изобилует интерфейс Reporter или Allure. AutorunДалее мы перешли к автоматизации запуска тестов, когда в issue tracker приходит задача на приемочное тестирование релиза. Для этой цели был написан сервис Autorun, который проверяет, есть ли в Jira новые задачи на приёмку, и если да, то определяет имя компонента и его версию на основании контента задачи.
Переключения между этапами организованы по принципу конечного автомата. Каждый этап сам знает условия перехода к следующему. Результаты этапа сохраняются в task context, который является общим для стейджей одной задачи. Quick-blockПолучившаяся система приемочного тестирования позволила нам проводить больше 60% релизов без участия человека. Но что делать с оставшимися? При необходимости дежурный создает багрепорт на тестируемый компонент или задачу на исправление тестов в команду разработки. Иногда — оформляет баг конфигурации тестового стенда в отдел эксплуатации. ИтогиМы прошли путь от приемок релизов в ручном режиме до практически полностью автоматического процесса, который способен провести через приемочное тестирование более 50 релизов в день. Это помогает компании сократить время выкладки изменений, а нашей команде — находить ресурсы для экспериментов и развития инструментов тестирования. |