Что пишут в блогах
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?
- Software Engineering Happiness Index 2025
- От вебинаров до биллинга: что нужно тестировать в EdTech на самом деле
- Штат, гибрид или аутсорс тестирования: честный разбор экономики QA-команд в 2026
- Как нагрузочное тестирование защищает бизнес от убытков?
- Исследовательское тестирование и UX‑аудит для интернет-магазина
- Юзабилити‑тестирование без розовых очков: почему идеальный функционал не спасёт от провала?

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Школа тест-менеджеров v. 2.0Начало: 24 июня 2026
-
Python для начинающихНачало: 25 июня 2026
-
Азбука ИТНачало: 25 июня 2026
-
Школа для начинающих тестировщиковНачало: 25 июня 2026
-
Тестирование веб-приложений 2.0Начало: 26 июня 2026
-
Тестирование REST APIНачало: 29 июня 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 29 июня 2026
-
Школа Тест-АналитикаНачало: 1 июля 2026
-
Bash: инструменты тестировщикаНачало: 2 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 2 июля 2026
-
Git: инструменты тестировщикаНачало: 2 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 2 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 2 июля 2026
-
Применение ChatGPT в тестированииНачало: 2 июля 2026
-
SQL: Инструменты тестировщикаНачало: 2 июля 2026
-
Docker: инструменты тестировщикаНачало: 2 июля 2026
-
Программирование на C# для тестировщиковНачало: 3 июля 2026
-
Организация автоматизированного тестированияНачало: 3 июля 2026
-
Техники локализации плавающих дефектовНачало: 6 июля 2026
-
Логи как инструмент тестировщикаНачало: 6 июля 2026
-
Charles Proxy как инструмент тестировщикаНачало: 9 июля 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 9 июля 2026
-
Регулярные выражения в тестированииНачало: 9 июля 2026
-
Тестирование GraphQL APIНачало: 9 июля 2026
-
Программирование на Python для тестировщиковНачало: 10 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
| Все ругают самописные тестовые фреймворки. А мы своим довольны |
| 27.03.2019 00:00 |
|
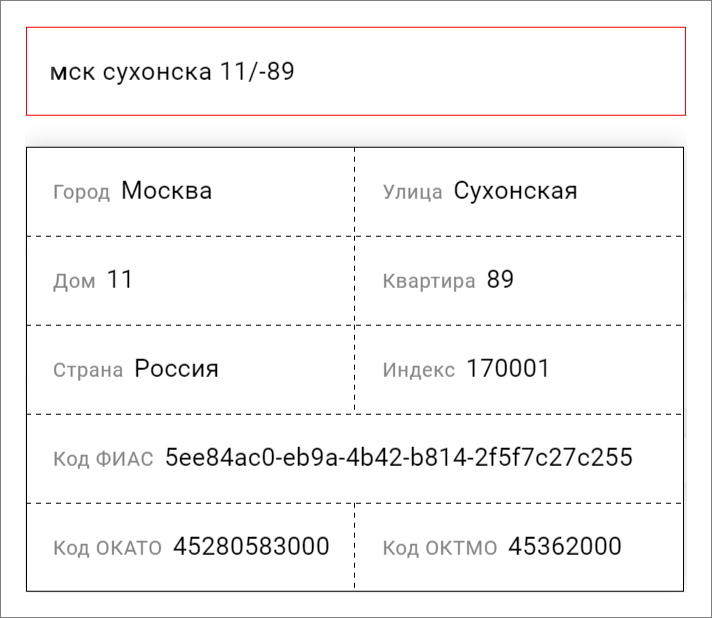
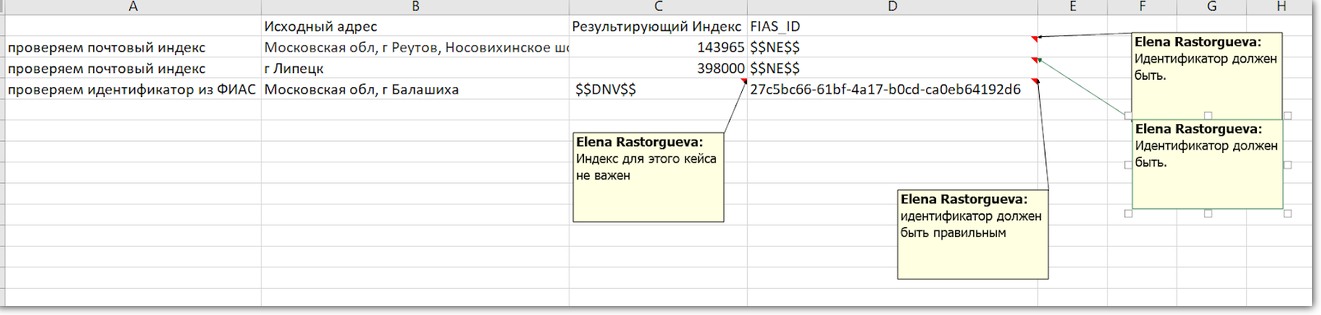
Что за продукт такой — «Фактор»«Фактор» чистит данные в базах с миллионами клиентов: убирает опечатки в ФИО, телефонах и емейлах, проверяет паспорта, делает еще кучу всего. Самое сложное — исправлять почтовые адреса. Начинали с ручной проверки и автотестов
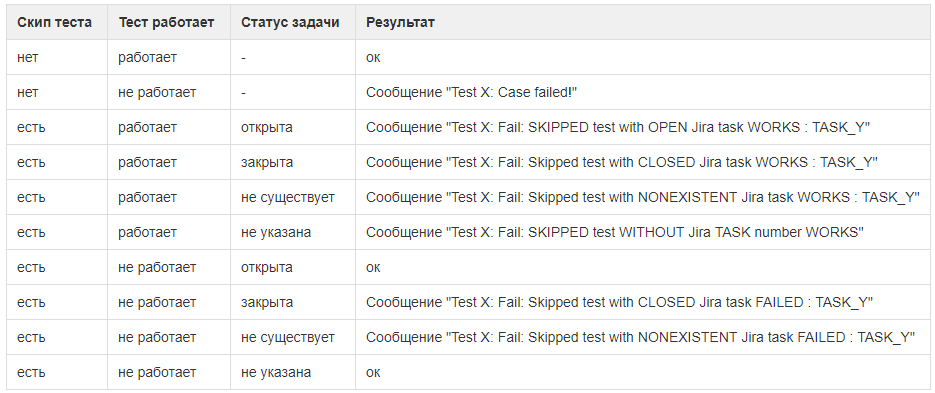
Создали свой фреймворкВ традиционных юнит-тестах данные и код идут вперемешку, выискивать нужные участки тяжело.
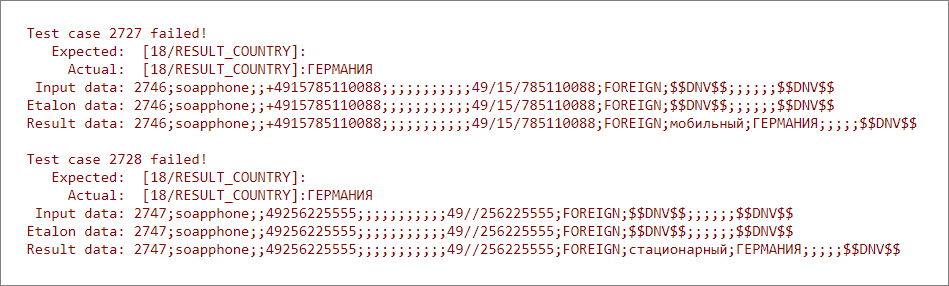
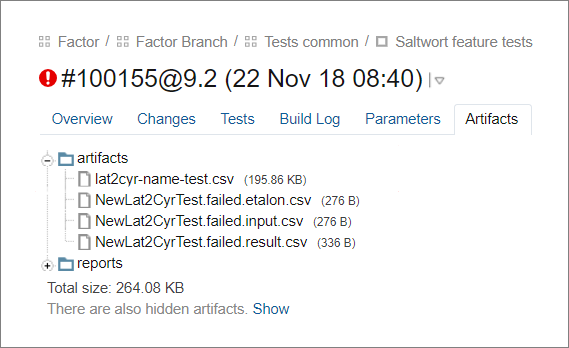
Доработали фреймворк под себяС тех пор прошло 12 лет. За это время фреймворк оброс возможностями, которых нет в стандартных решениях.
Самописный фреймворк удобнееПоэтому я совсем не считаю создание собственного фреймворка глупой затеей. Не создай мы собственный инструмент, не получили бы столько новых возможностей и такую гибкость. |