Что пишут в блогах
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Python для начинающихНачало: 16 июля 2026
-
Азбука ИТНачало: 16 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
| Путь к метрикам |
| 08.09.2022 00:00 |
|
Статья компании SimbirSoft Метрики используют для оценки, отражения динамики и выявления слабых мест в процессе разработки. Как их внедрять и применять здесь и сейчас? А если у вас в команде проблемы с процессами, может вам и не до метрик? Раз вы видите проблемы, то, наверное, как-то их оцениваете, измеряете, пусть и условно. Как решаются проблемы и появляются метрики, на примере одного из проектов рассказывает QA-специалист SimbirSoft Виктор. Статья будет полезна для команд, в которых есть проблемы с процессом и ограничен ресурс, например, на тестирование. Из этой статьи вы узнаете, как подступиться к таким сложностям и решить их. Ведь именно для того, чтобы эффективно распорядиться ресурсом, предусмотреть риски и избежать их, нужно выстраивать процесс.
Дело было осенью. Шел четвёртый месяц работы над MVP. Все команды, забыв о квартальном планировании, трудились над срочным запуском продукта. Я подключился к проекту на этапе вывода MVP. К слову, тот запуск был образцово-показательным. Но не обошлось без потерь: по разным причинам ушли QA-специалист и скрам-мастер. Однако на проекте остались крутые и вовлеченные люди, которые приобрели и сохранили весь пережитый опыт. Что мы имели на входе?
Налицо – проблемы с тестированием, которые были не критичны на этапе запуска MVP, но могли сказаться на продукте в дальнейшем. Но известное не значит понятое. Если для QA очевидны проблемы с тестированием и даже их причины, это не значит, что они также понятны для владельца продукта, скрам-мастера и команды. Это мне и предстояло подсветить. Проблем мало не бывает — первые метрикиВ команде проекта сначала было два QA-специалиста. MVP встретил один, ожидая расширения команды. Я подключался на помощь, совмещая еще с одним проектом. Время на передачу дел съел релиз MVP и проблемы с доступами. Задач на проверку было невпроворот. Проблемы накапливались:
Для меня, как для QA, причины этого были ясны: не было фича фриза. На ретро я так и сказал: «У нас фича фриз – это не отрезок, а просто точка на планировании, одно название». По идее к его началу все доработки должны быть проверены и оформлены в релиз, то есть пройдены тесты. Но это сложно представить, если задачу на первое тестирование отдают в день старта фича фриза, не говоря уж о тех, которые всё ещё находятся в разработке. Это прямая угроза релизу. Вдобавок к этому, с выводом MVP и отсутствием квартального планирования (активность, которая предполагает приоритизацию и план от бизнеса), возник парадокс срочных релизов. На «снежный ком» чрезмерного количества задач и неточных сроков накладывалось желание команды быстрее решить проблемы пользователей. В итоге между релизами возникали промежуточные релизы отдельных доработок. В такой обстановке любая проблема пользователя могла вырасти в хотфикс, даже та, которая появилась не в результате последнего релиза. И это еще не всё...
Какие уж тут метрики? Кто их будет снимать и зачем? Первое решение – подсветить бизнесу недостаток ресурса для тестирования и потенциально большое число дефектов после вывода MVP. Это было сделано сразу. Заручившись поддержкой команды, решил бороться за фича фриз, к которому должны быть успешно проверены задачи релиза. Пришлось разъяснять, что:
На следующем шаге подсветил руководителю QA-отдела и SEM'у (Systems Engineering Manager) проекта проблемы с планированием, приоритетами и составом релизов. Например, на доске могло висеть около 50 дел, некоторые из них переходили от спринта к спринту. Это осложнялось тем, что постоянно добавлялись задачи с высоким приоритетом, а команда не понимала, сколько задач может успеть. Чтобы наладить процесс разработки, пяти разработчиков, аналитика и QA-команды не хватало.
Тем не менее, несколько метрик всё же было:
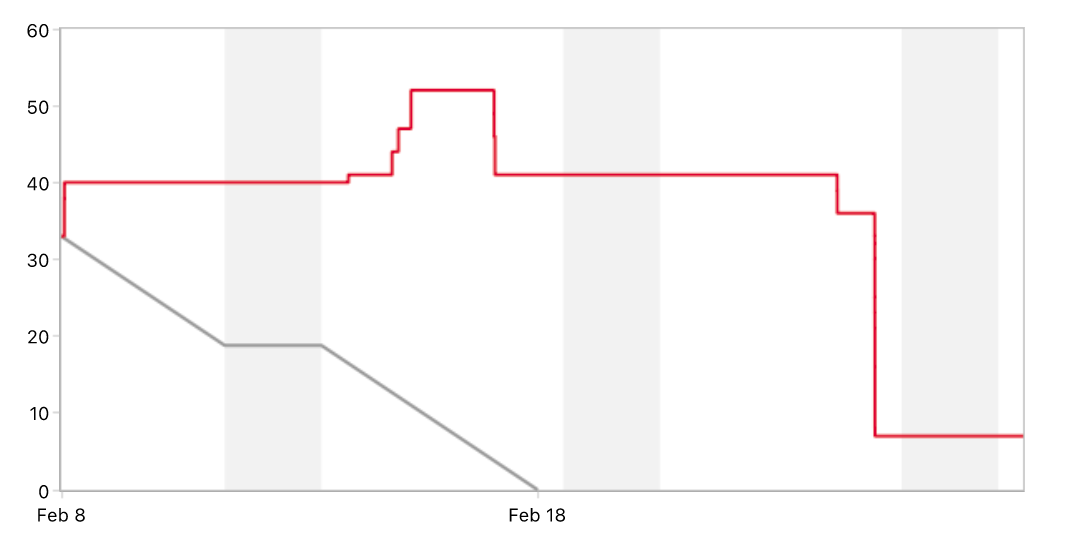
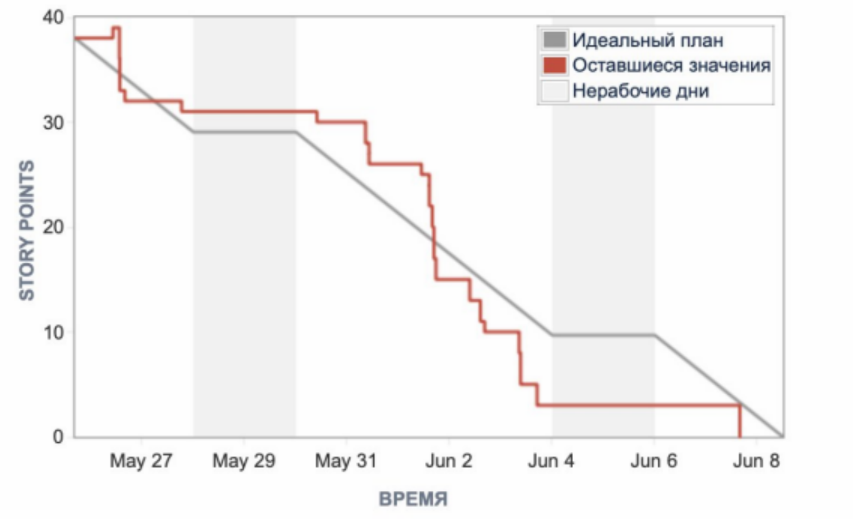
Метрики = воркфлоу Нас услышали и скрам-мастер пришел в команду. Пару спринтов это была выделенная роль — SEM подключался на командные активности. А затем появился отдельный специалист. В этот период выявили проблемы на уровне команды. Низкая предсказуемость — главная из них. А неверная работа в Jira решалась настройкой и обучением. Другие упоминать не будем, так как часто даже самые критичные вопросы решаются очень просто. Скажем только, что любые ошибки в процессах не дают перейти к более сложным и точным метрикам. Теперь команда видела свои проблемы и риски, связанные с ними. Всем было очевидно, что страдала поставка ценности. И это должно было быть исправлено. Главным артефактом, вокруг которого была построена работа по отладке процесса, стал график сгорания cпринта или «бёрндаун». В нашей версии — это был «бёрнап», поскольку именно борьбе с «ап» уделялось особое внимание.
Подготовили «общие» правила:
Но это не всё. SEM, скрам мастер, QA lead, аналитик и QA-команда провели серию встреч, чтобы разобраться с менее тривиальными вопросами. Например, как снизить число задач, которые передаются на тестирование и возвращаются на доработку после проверки приоритетного, позитивного сценария. Решили:
Отдельно расскажем про найденное решение по рефакторингу и другим техническим задачам. Ранее их брали в работу во время фича фриза и они не закрывались, стори пойнты не сгорали в спринте, так как QA были заняты проверкой релиза, и перетекали в следующий спринт. Мы стали думать, как посчитать, сколько сделано по факту в конкретном спринте, как планировать следующие. Определили, что задачи, которые могут не завершиться в спринте, нужно добавлять из бэклога, не указывая оценку. Кажется, что это противоречит предыдущим решениям: все оценивать и измерять. Но «не указывать оценку» не конфликтует с «не брать без оценки». Оценка указывается в Jira в тот момент, когда QA понимает, что в данном спринте она закроется. Таким образом:
Метрики без вычисленийСтали регулярно подсчитываться скорость, прогнозируемость и вместимость спринта. На доску заводили договорённости команды, риски, зависимости, цели спринта и цели PI (квартального планирования). Задачи делили на технические и бизнесовые, которые также разделяли на приоритетные и неприоритетные. Последние позволяли добиться менее жесткого планирования, чтобы учесть риски. Мы пришли к такому выводу, что иногда самая простая вещь, которую вся команда понимает одинаково, гораздо полезнее, чем цифры и проценты. Например, договоренности, риски и цели, заведенные на доску с задачами. Договоренность, которая находится в «TO DO», цель спринта среди задач, риск, который не сработал и перемещен в «Done», – такие метрики состояния, фокуса спринта не включишь в отчёт, но они помогают отлаживать рабочий процесс. Ошибки и нерешённые проблемы в процессеВозможно, ошибок было больше, но сейчас хочу назвать одну. Однажды брошенное по неосторожности «долг по тестированию» применительно к незавершённым задачам так прилипло, что все долги повисли на QA. На практике, конечно, проверять реализацию задачи должен не только QA, но и вся команда. И это нужно было обосновать. Мы обратили внимание, в частности, на нехватку тестового стенда, регулярные проблемы с деплоем и задачи, которые не проходят смоук. Разбор всех проблем был полезен. Но если бы «долг» не давил, то наш путь к метрикам был бы легче. Не бойтесь выполнять другую роль в команде, если не хватает людей. Например, разработчики могут тестировать (не за собой), если это поднимет производительность команды. ИтогНаш путь к метрикам занял 5 спринтов. Но результаты стоили этого:
Этот путь научил команду тому, что:
С выводом MVP, который сделали за два месяца, проект не остановился, продукт продолжили развивать. Были решены многие проблемы, накопившиеся за время работы со сжатыми сроками. Проделанная работа над ошибками позволила команде шагнуть в сторону оптимизации и эффективности. Эта работа заняла почти полгода. Немалый срок. Но всё относительно. Главное – на этом не останавливаться, поскольку впереди time-to-market. А вам приходилось выстраивать метрики на проектах? Будем рады, если вы поделитесь своим опытом в комментариях Больше кейсов и полезных материалов для владельцев продуктов - в нашем ВК и Telegram. Познакомиться с нашими проектами поближе можно здесь. |