Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Азбука ИТНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Python для начинающихНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Инженер по тестированию программного обеспеченияНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
-
Bash: инструменты тестировщикаНачало: 1 октября 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 1 октября 2026
-
Docker: инструменты тестировщикаНачало: 1 октября 2026
-
SQL: Инструменты тестировщикаНачало: 1 октября 2026
-
Git: инструменты тестировщикаНачало: 1 октября 2026
| Два или три тест-кейса для проверки граничных значений? |
| 04.10.2022 00:00 |
|
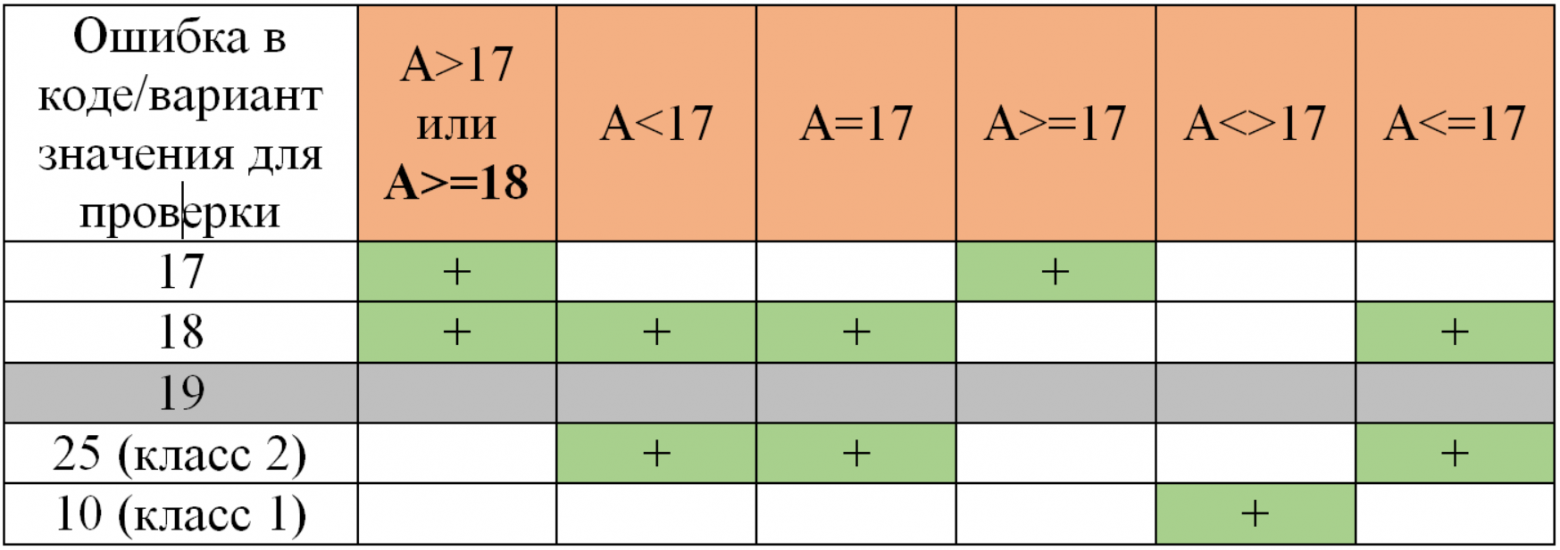
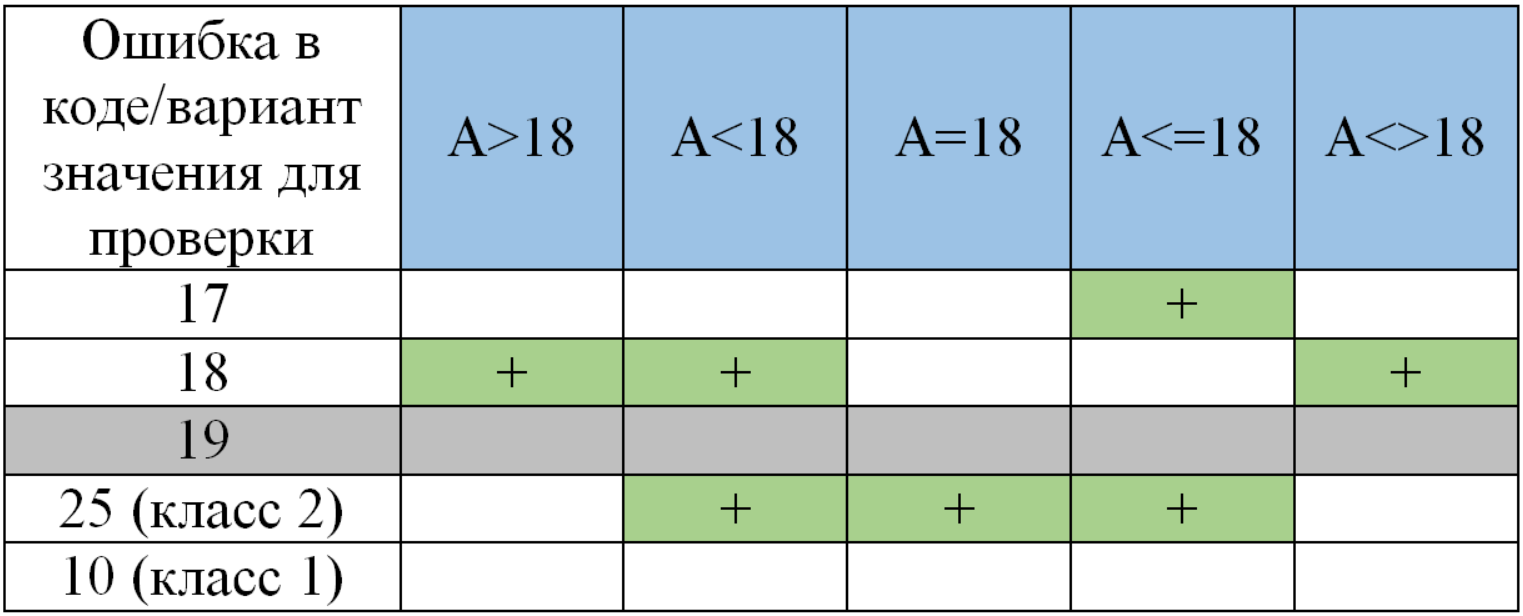
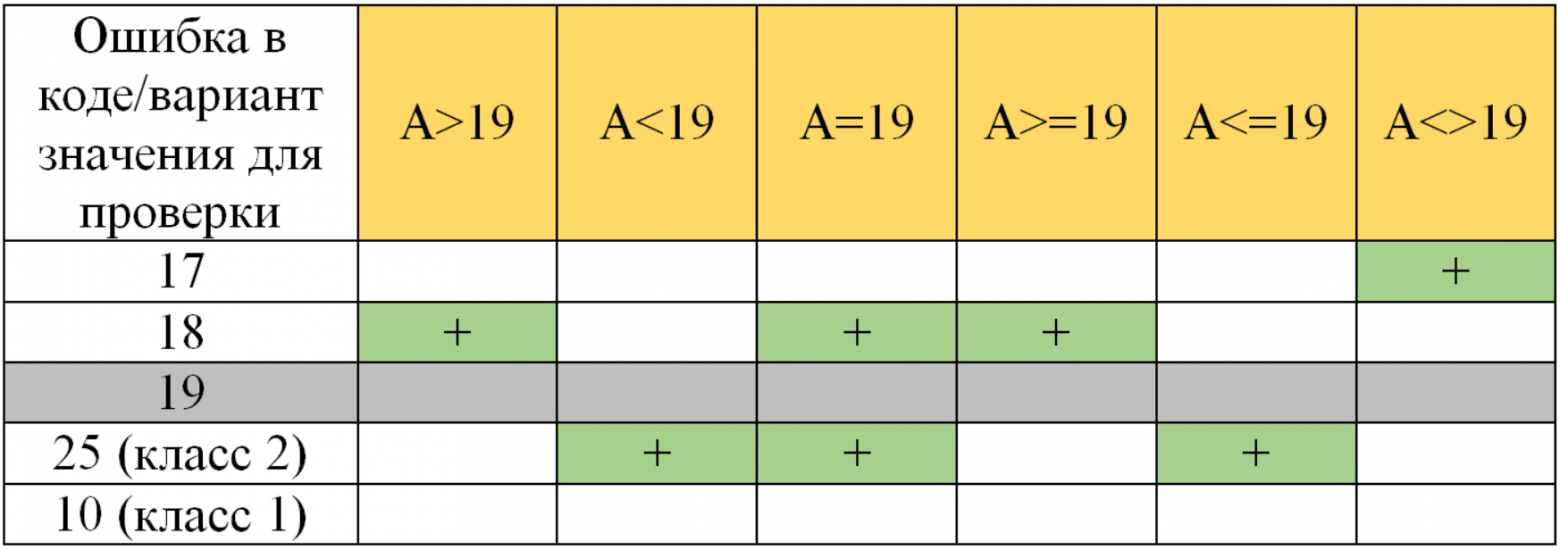
Автор: Смирнов Дмитрий Большинство тестировщиков знакомы с такими техниками тест-дизайна, как разбиение на эквивалентные классы и анализ граничных значений. Эти две техники, как и другие, призваны и позволяют значительно уменьшить количество необходимых проверок при тестировании, например полей ввода. В двух словах напомню. Эквивалентный класс – подмножество всех входных значений, которые будут обработаны приложением одинаково (из-за внутренней логики приложения), и на выходе дадут одинаковый результат. Собственно техника заключается в том, что достаточно проверить одного представителя класса вместо всех. Рекомендуется брать значение из середины класса, т.к. при этом ничто не влияет на логику обработки. Граничные значения – значения диапазона входных данных, при которых меняется поведение приложения. Это соседние значения диапазона, но относящиеся к разным эквивалентным классам. И хотя сами граничные значения являются элементами/представителями своих классов, они должны быть протестированы в дополнение к проверке значения из середины класса. Почему? Необходимость заложена из предпосылок, что при написании кода, разработчик может ошибиться при указании границ и/или логики. Перейдем к рассмотрению конкретного примера и оценки количества необходимых тест-кейсов. Вопрос: сколько тест кейсов необходимо для покрытия граничных значений и классов эквивалентности на примере доступа к функционалу приложения на основе возраста (для целочисленных значений от 1 до 100)? Здесь будут рассмотрены только позитивные сценарии без проверки границ диапазона 1 и 100 (без тестирования 0, отрицательных чисел, букв, спец. символов). ТЗ: доступ к контенту разрешен только с 18 лет (т.е. возраст >= 18 лет). Определим эквивалентные классы: 1-17 | 18-100 (1-17 – класс 1; 18-100 – класс 2). Граничные значения: 17 и 18. Классически тестируются два значения для границы (17 и 18 для нашего примера), когда при переходе от одного к другому меняется поведение (выходной результат). При этом граница не является конкретным значением, она определена граничными значениями двух соседних классов эквивалентности. Значение 18 является элементом класса 18-100, и логически, если проверка проходит на 18, то нет никакой вероятности (кроме умышленного исключения значения 19 в коде), что 19 не пройдет проверку, т.к. оно является элементом того же класса 18-100. То же самое справедливо для значения 17, если мы рассматриваем класс 1-17, нет никакой необходимости тестировать значение 16. Встречается мнение о необходимости тестирования границы с двух сторон, при этом граница определяется как конкретное значение, указанное в ТЗ (или первое, граничное значение класса). Этот подход либо не объясняется вообще (давайте на всякий случай протестируем +/- "границу"), либо тем, что программист может ошибиться в выборе границы и указать 17 (или 19) вместо 18. И в дальнейшем предлагается тестировать три значения: 17 – нижняя граница, 18 – собственно граница, 19 – верхняя граница. Составим некое подобие матрицы трассируемости/прослеживаемости (traceability matrix) для анализа покрытия случайных ошибок в коде нашими выбранными значениями. Смоделированы следующие ошибки в коде: неверное определение границ (соседние числа к «границе» значений) и/или неверная логика (вариации со знаками неравенств). В самих таблицах: + - значение покрывает тестируемую ситуацию (ошибку в коде). Если вводим значение в пределах класса, и результат FALSE (должен, а не пускает) – у нас выявлена ошибка в коде. Если вводим значение за пределами класса, и результат TRUE (не должен, а пускает) – у нас выявлена ошибка в коде. А>=18 эквивалентно A>17 с точки зрения классов и их значений.
Вывод: из таблиц видно, что тестирование значений, не являющихся граничными (19) возможно, но оно бессмысленно (лишние тест кейсы), т.к. не является уникальным для покрытия каких-либо случайных ошибок в коде. Ответ на поставленный ранее вопрос: 2 тест-кейса на каждую границу + 1 на каждый класс (для нашего примера проверяем значения 10, 17, 18, 25). |