Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Азбука ИТНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Python для начинающихНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Инженер по тестированию программного обеспеченияНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
-
Bash: инструменты тестировщикаНачало: 1 октября 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 1 октября 2026
-
Docker: инструменты тестировщикаНачало: 1 октября 2026
-
SQL: Инструменты тестировщикаНачало: 1 октября 2026
-
Git: инструменты тестировщикаНачало: 1 октября 2026
| Метод бисекционного деления в тестировании |
| 21.10.2019 00:00 |
|
Автор: Назина (Киселева) Ольга (автор тренинга Школа для начинающих тестировщиков)
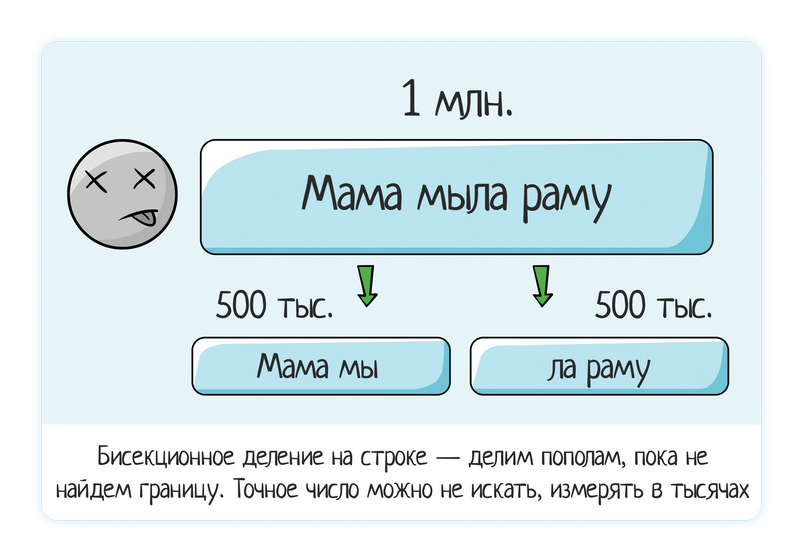
Иногда баги сами нас находят. Вот мы впихали большую строку данных — и система подвисла. Это она из-за 1 млн символов упала? Или ей какой-то конкретный не понравился?
Как найти минимальные данные для воспроизведения бага? Если есть какие-то подсказки в логах, применяем их. Если подсказок нет, то самый оптимальный метод — метод бисекционного деления (также известный как метод «деления пополам» или «дихотомия»). Описание метода Метод применяется для поиска точного места падения:
Применение тестировщикамиСтрока данных Загрузили строку в 1 млн данных — система зависла. Файл Загрузили файл — упал! Как, почему? Сначала пытаемся сами проанализировать, что могло повлиять, что проверял наш тест? В этом фишка главного правила «сначала позитив, потом негатив». Если не пытаться запихивать в один тест все и сразу:
Вот тут будет тяжело локализовать. А если разделять проверки:
То уже примерно понятно, в чем причина. Например, падает на большом количестве строк — от 100 тысяч. Ок, ищем более точную границу с помощью бисекционного деления:

Этот баг нашли студенты в Дадате. Туда можно грузить файлы с данными, система эти данные обработает и стандартизирует: исправит опечатки, определит недостающую информацию по справочникам (код КЛАДР, ФИАС, геокоординаты, район города, индекс...). Но помним, что свою теорию тоже надо тестировать. Правда ли, что проблема именно в количестве строк, а не данных внутри файла? Проверить это очень легко — создаете файл на 5000 строк с одним-единственным «позитивным» значением. Тем значением, которое точно работает, которое вы уже проверяли ранее. Если падения нет, значит, тут дело нечисто =)) Похоже, теория о количестве строк была ошибочная и дело в самих данных. 

В итоге вместо бага «Падает файл, хз почему, вот в аттаче файл на 2гб» вы ставите продуманный и локализованный баг: «Падает файл, если внутри дата формата ДД/ММ/ГГГГГ». И тогда вам не нужен уже файл на 2гб, вам хватит файла на одну строку и одну колонку! Применение разработчикамиНа большом объеме данных тестировщик не ищет четкую границу, потому что это неразумно делать вручную. А вот разработчики применяют метод бисекционного деления в коде и всегда могут найти конкретное место падения. Ведь делить до победного будет система, а не человек! 

Так что мозг надо включать везде — как на ручном тестировании, так и при написании программного кода. Всегда надо понимать, когда остановиться. Только в случае ручного тестирования это будет «примерно найти границу», а в разработке «остановиться, если падений много». РезюмеМетод бисекционного деления применяется для поиска точного места падения и локализации бага.

|