|
Подход фаззинг-тестирования родился еще в 80-х годах прошлого века. В некоторых языках он используется давно и плодотворно — соответственно, уже успел занять свою нишу. Сторонние фаззеры для Go были доступны и ранее, но в Go 1.18 появился стандартный. Мы в «Лаборатории Касперского» уже успели его пощупать и тестируем с его помощью довольно большой самостоятельный сервис. 
Меня зовут Владимир Романько, я — Development Team Lead, и именно моя команда фаззит баги на Go. В этой статье я расскажу про историю фаззинга, про то, где и как искать баги, а также как помочь фаззинг-тестам эффективнее находить их в самых неожиданных местах. И покажу этот подход на примере обнаружения SQL-инъекций.
Немного истории Когда я первый раз услышал о фаззинге, сама идея прозвучала для меня довольно странно. Казалось, это магия, с помощью которой сторонняя программа может найти баги в моем коде.
Все встало на свои места, когда я узнал, как фаззинг появился. Поэтому свой рассказ я также хочу начать с интересной истории, которая, вероятно, ждет своего Кристофера Нолана для экранизации. В ней есть все необходимые компоненты отличного голливудского блокбастера: зловещая ночь с грозой, гениальный ученый, а также древний артефакт, который принял во всем этом участие. Забегая вперед, отмечу, что роль древнего артефакта исполнил модем на 1200 бод. В итоге случайное стечение обстоятельств привело к появлению хорошего изобретения.
Так что же произошло?
Тем ученым был Бартон Миллер. В 1988 году он работал профессором в университете и решил из дома подключиться через модем к своему любимому университетскому мейнфрейму. Он пытался выполнить команду Unix… История умалчивает о том, какая именно это была команда. Предположим, это был grep.
grep -R "hello world"
В этот момент где-то недалеко ударила молния. А старый модем если и имел код коррекции ошибок, тот оказался недостаточно эффективным. Вместо «Hello world» до мейнфрейма долетел мусор:
grep -R "hello ~3#зеШwкACh"
Который внезапно вызвал segmentation fault. И grep упал.
Бартон Миллер задумался, почему это произошло. Grep к тому времени уже был старой, надежной, многократно протестированной командой, у которой явно есть какие-то проверки ввода. Но тем не менее он упал. И ученому пришла в голову идея написать программу, которая специально будет генерировать мусор и отправлять на вход в различные unix-овые утилиты. Так появился первый фаззер.
Вместе со студентами Бартон Миллер нашел очень много ошибок в командах Unix. К этому моменту все эти команды уже использовались инженерами по всему миру в течение длительного времени, но тем не менее содержали ошибки. Такова суперспособность фаззера, за которую мы его и любим, — находить баги в хорошо протестированном коде.
Как фаззер находит багиТесты можно классифицировать по-разному. Но давайте распределим их по уровню семантического знания о коде, которое использовано при написании теста.

Больше всего знаний о тестируемом коде используется при построении тестов по тест-кейсам, например в юнит-, ручных или интеграционных тестах. Они содержат некие пред- и постусловия — конкретные проверки того, что на вход программы мы передали А, а на выходе должны получить Б. Для написания таких тестов однозначно придется изучить код и требования к нему.
Левее по этой шкале находятся property based тесты. В них уже нет конкретных входов и выходов. Данные на вход генерируются случайным образом, но проверяются определенные свойства кода (поэтому тесты и называются property based). К примеру, если мы проверяем функцию сортировки, на выходе ожидаем массив, каждый последующий элемент которого больше либо равен предыдущему.
В крайней левой части шкалы находятся фаззинг-тесты, имеющие минимальные знания о продукте. Им известно только то, что код не должен падать, зависать или отъедать какое-то безумное количество памяти. С точки зрения теста сам продукт представляет собой черный ящик.
В том, что при фаззинге используются минимальные знания, есть как плюсы, так и минусы. Если тесты по тест-кейсам позволяют находить так называемые known unknowns (т. е. проверяют неизвестное поведение в известных сценариях), то фаззинг ищет unknown unknowns (проверяет неизвестное поведение в неизвестных сценариях). Именно эта особенность позволяет фаззингу находить баги в хорошо протестированном коде — он обнаруживает сценарии, про которые разработчик никогда и не подумал бы.
Для примера приведу тесты для функции сортировки, которая принимает слайс int.

Функцию можно протестировать с помощью тестов по тест-кейсам. В этом случае на вход мы передаем (2, 1, 3) и проверяем ожидание, что на выходе будет 1, 2, 3.
В property based тестах на входе случайная последовательность, а на выходе надо убедиться, что каждый последующий элемент больше или равен предыдущему (т. е. проверяется свойство).
Фаззинг также передаст случайную последовательность, но удостоверится, что функция не упала.
Фаззинг не заменяет классическое тестирование. Он нужен, когда проверяется уже оттестированный код, а фантазия тестировщиков подходит к концу. В общем случае фаззер найдет меньше ошибок, чем тесты по тест-кейсам. Но эти ошибки будут наиболее разнообразны. Это хорошо заметно в Go-шной реализации фаззера — go fuzz, которая модифицирует корпус входных тестовых данных так, чтобы отработали все ветви кода. Стандартный фаззер Go вообще одинаково хорошо подходит как для написания property based тестов, так и для классического фаззинга. Официальная документация Go по фаззингу не делает различия между этими видами тестов.
Как помочь фаззеруДавайте рассмотрим нехитрую программу на Go.
Наш код объявляет неинициализированный нулевой указатель и что-то по нему пишет.

Если запустить этот код, он упадет с ошибкой. Проблема в пятой строке.
Чисто теоретически ее можно было бы проигнорировать и продолжить выполнение. Если кто-то помнит, в Visual Basic был такой режим: при ошибке программа не падала, а просто переходила к следующей строке кода. Получалось, что они надежны, но поведение этих программ непредсказуемо. Это никак не помогло бы фаззеру.
Вернемся к Бартону Миллеру. Что было бы, если бы grep проигнорировал обращение к невалидному указателю? Скорее всего, фаззер не нашел бы багов в команде. Команда обработала бы мусор на входе и выдала мусор на выходе. Никто не понял бы, что произошло нечто плохое. Т. е. фаззер в принципе смог найти ошибку только благодаря крэшу (программа проверила свой собственный внутренний инвариант, согласно которому нельзя обращаться к некорректному указателю, и упала, когда он оказался нарушен).
Так мы приходим к выводу: падать с ошибкой полезно.
Чем больше код проверяет своих внутренних инвариантов, тем больше фаззер может найти багов.
Вот несколько примеров с проверкой внутренних инвариантов:
- Инвариант может заключаться в том, что оба потомка красного узла в красно-черном дереве — черные. Если он нарушен, код может как-то сообщить об этом фаззеру.
- Можно проверять, что количество элементов в контейнере неотрицательно — в очереди не может содержаться «-1» элемент.
- Проверка может выявлять, что в стеке количество операций Pop меньше или равно количеству Push.
- Бизнес-логика может контролировать отсутствие превышения некоего программного лимита. Тот факт, что мы обнаружим нарушение этого инварианта, будет свидетельствовать об ошибке в бизнес-логике.
- Кэш должен отсекать повторные запросы. Это особенно актуально, если база вычисляет тяжелые запросы и нужно проверить бизнес-логику, которая хранит в памяти результаты нескольких последних запросов. В этом случае фаззер может найти ошибку в логике работы с кэшем.
- SQL-запрос не должен возвращать ошибку некорректного синтаксиса. Если же мы получаем такую ошибку, в нашем коде однозначно есть проблема. Скорее всего, мы неправильно формируем тело SQL-запроса или в это тело без какой-либо санитизации попадает пользовательский ввод (SQL-инъекция).
Все эти примеры объединяет тот факт, что если проверка сработает, это однозначно указывает на некорректно написанный код. Это никак не связано с окружением. По сути это ничем не отличается от обращения к невалидному указателю, упомянутому выше.
Инвариант мало проверить, нужно еще донести до фаззера информацию о том, что есть нарушение. Самый простой способ — кинуть panic. Это можно сделать с любого уровня абстракции.
Среди Go-феров есть предубеждение против panic, поэтому можно использовать более лайтовые варианты:
- Кидать panic не всегда, а только в специальном фаззинг-режиме: ввести переменную окружения, и если она задана, при нарушении инвариантов кидать panic. Фаззинг-режим, кстати, помогает решить проблему с «дорогими» проверками инвариантов, когда на них уходит много ресурсов.
- Можно использовать специальный уровень логирования, доступный фаззеру. Когда тот увидит запись с этим уровнем, он поймет, что нарушен некий внутренний инвариант (и сделает вывод, что код написан некорректно). Этот подход требует более сложной инфраструктуры. И важно не писать в лог на этом уровне, когда наблюдаются проблемы с инфраструктурой (например, если отвалилась сеть).
При проверке инвариантов у фаззинг-теста нет никакого ожидания относительно кода. За счет этого он более стабильный — его не нужно менять при малейших изменениях. С развитием продукта его также нужно поддерживать, но усилий на это будет уходить гораздо меньше, чем в случае с тестами по тест-кейсам. Возвращаясь к примеру с grep — если мы сменим движок обработки регулярных выражений, суть теста никак не изменится.
Фаззинг имеет смысл, если функции работают достаточно быстро. Если функция выдает ответ через несколько минут после передачи в нее начальных данных, за разумное время фаззер просто не успеет ничего проверить. А проверив слишком мало вариантов, он ничего не найдет. Возможно, в этой ситуации процесс ускорят моки, но работать с ними надо всегда очень осторожно. Также можно гонять тесты на маленьких частях кода.
Помогаем фаззеру искать SQL-уязвимостиТеперь применим этот подход, чтобы обрабатывать ошибки работы с базой данных на примере SQLite.
Предположим, у нас есть нативный код, в котором присутствует уязвимость SQL-инъекции. Мы формируем строку, и если получаем ошибку, смотрим, что это было. Если это ошибка SQLite, которая говорит, что синтаксис некорректный, и при этом включена переменная окружения FUZZING, мы кидаем panic. В ином случае мы обрабатываем ошибки стандартным путем.
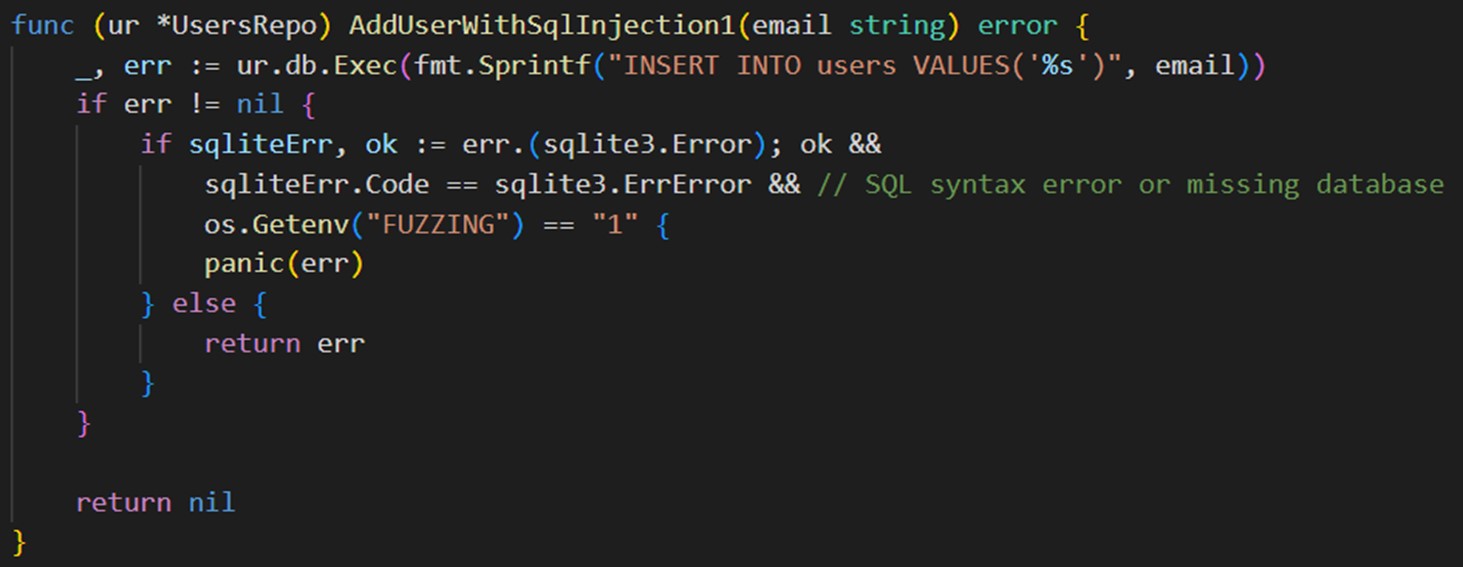
Каждый раз писать такой код неудобно, поэтому его можно разбить на вспомогательные функции и уже их использовать по всему коду.
Я бы предложил такой вариант разбиения.
Мы выделяем функцию ProcessCriticalErr, которая на вход принимает критическую ошибку (в нашем случае — нарушение синтаксиса) и кидает panic, если выставлена переменная окружения. Когда переменная окружения не выставлена, она просто возвращает ошибку.
Дополнительно нам потребуется функция, которая определяет, является ли данная ошибка критической. У SQLite есть несколько кодов ошибок, подходящих под нашу ситуацию.
Третья функция — также вспомогательная. Она принимает на вход ошибку базы данных, проверяет ее «критичность» и при необходимости вызывает процедуру обработки таких ошибок.

В этом случае наша стандартная функция работы с базой данных упрощается до такого вида:

При обнаружении критической ошибки в фаззинг=-режиме мы сообщаем об этом фаззеру, который и запоминает, что подобрал входные данные, ломающие внутреннюю логику. В данном случае фаззер помогает найти SQL-инъекцию.
Напоследок я бы рекомендовал ознакомиться с двумя ссылками:
- https://go.dev/doc/tutorial/fuzz — о том, как вообще пользоваться фаззингом в Go, конкретно go fuzz. Он подходит для написания как классических фаззинг- тестов, о которых я рассказывал, так и для property based тестов.
- https://www.fuzzingbook.org/ — очень полезный сайт, который посвящен фаззингу в целом. Это отдельный большой мир с огромным количеством способов разработки таких тестов. Рекомендую ознакомиться с информацией, которая есть на этом сайте. Если фаззинг применять «в лоб», он просто будет нагревать поверхность нашей атмосферы. Чтобы он находил баги, требуется включать голову, и этот ресурс подскажет, в каком направлении думать. Нужно просто научиться замечать в коде возможности для написания фаззинг-теста.
Обсудить в форуме |



