Что пишут в блогах
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Азбука ИТНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Python для начинающихНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
| Как мы выстроили процесс нагрузочного тестирования в KISLOROD |
| 25.02.2026 00:00 | ||||||||||||||||||||||||||||||
|
Меня зовут Эдуард, я руковожу отделом DevOps в компании KISLOROD. В этой статье расскажу про подход к нагрузочному тестированию, который сформировался у нас. Мы постоянно дорабатываем процессы, поэтому буду рад конструктивным комментариям и обмену опытом. Зачем вообще нужно нагрузочное тестированиеНагрузочное тестирование — это способ проверить, как система ведет себя при росте числа пользователей и соответствует ли ее поведение ожиданиям. По сути, это имитация реальной активности: пользователи заходят на сайт, просматривают страницы, добавляют товары в корзину, оформляют заказы.
Почему это важно? Потому что узнавать о проблемах на пике трафика — худший сценарий. Например, в одном из проектов мы тестировали интернет-магазин перед крупной распродажей. Сайт начинал «падать» уже при нагрузке на 150 % выше обычной. После оптимизации проект выдерживал в 3–4 раза больше, чем до тестов. Без этого этапа компания рисковала потерять не только продажи, но и доверие покупателей. Что дает нагрузочное тестирование:
Виды нагрузочного тестированияРазные сценарии тестирования отвечают на разные инженерные вопросы: где граница производительности, когда начинаются отказы и как система поведет себя через сутки под нагрузкой? На эти вопросы отвечают три типа нагрузочных тестов: 1. Load Testing (классическое нагрузочное).Цель: понять, как система ведет себя при ожидаемой и повышенной нагрузке. Как проводится: нагрузка постепенно растет — от 100 % до 300 % текущего пикового значения. На каждом этапе фиксируются метрики: время отклика, использование CPU, RAM и диска. Что дает:
2. Stress Testing (стрессовое тестирование).Цель: довести систему до предела и зафиксировать момент, когда она перестает справляться. Как проводится: нагрузку увеличивают до 150–300 % и удерживают в течение длительного времени (до 12 часов). Так выявляют утечки памяти, ошибки обработки, деградацию производительности при нехватке ресурсов. Что дает:
3. Stability Testing (тестирование стабильности).Цель: проверить, выдерживает ли система длительную работу под стабильной нагрузкой. Как проводится: система работает 24 часа и больше при уровне нагрузки 100–120 % от среднего. Наблюдаем за утечками памяти, зависаниями и постепенной деградацией сервисов. Что дает:
Как мы проводим нагрузочное тестирование:Этап 1. Сбор и анализ данныхНагрузочное тестирование начинается с аналитики. Нужно понять, как система работает в данный момент и какие сценарии реально отражают пользовательское поведение. Что анализируем:
По итогам анализа определяются текущие показатели системы.
Этап 2. Подготовка тестового стенда.Чтобы результаты нагрузочного тестирования имели смысл, стенд должен быть идентичен продакшну — полностью совпадающим по конфигурации. Какие данные должны совпадать:
Перед запуском тестов проверяем базовое состояние среды: свободное место на дисках, загрузку CPU и RAM в состоянии покоя, наличие фоновых процессов, которые могут повлиять на результаты. Если проект работает на 1С-Битрикс, дополнительно используем встроенную диагностику и отключаем все, что может исказить картину:
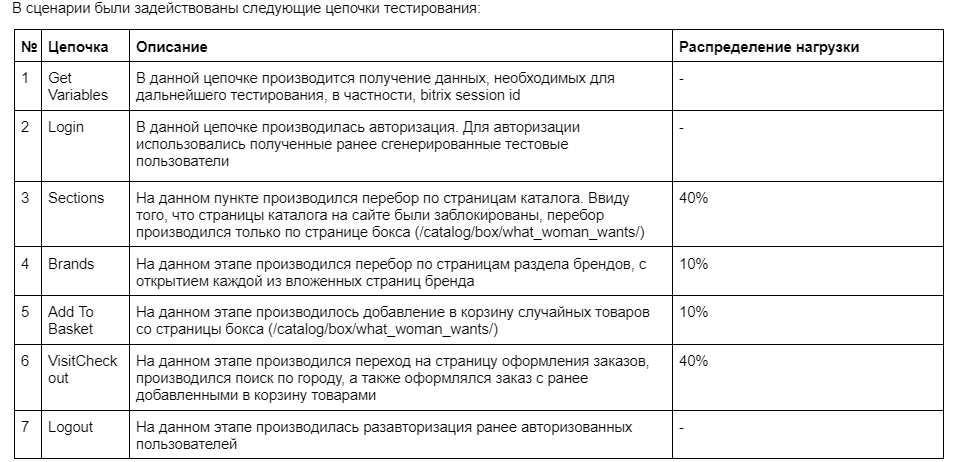
Для имитации реальной активности готовим тестовые данные в формате CSV: свойства для оформления заказов, параметры фильтрации, список тестовых пользователей. Этап 3. Создание сценариев тестирования.Сценарии — основа нагрузочного тестирования. Именно они определяют, насколько точно тест имитирует реальное поведение пользователей. В зависимости от целей моделируем разные ситуации:
Цели формулируем конкретно. Ставим задачу, например: «сайт должен выдержать 500 000 одновременных посетителей», «время отклика базы данных не выше 300 мс при RPS = 1000». Сценарии всегда подстраиваются под проект. Охватить все варианты за один тест невозможно, поэтому движемся поэтапно — от базовых пользовательских путей к стрессовым ситуациям. Важно включать не только успешные кейсы, но и негативные сценарии, например, неверные данные в формах, поиск по несуществующим товарам или попытки доступа к закрытым страницам. Минимальный набор цепочек:
Чтобы определить приоритеты, используем:
Сценарии реализуем в JMeter. Каждая цепочка — это набор HTTP-запросов с параметрами, задержками между действиями, куками и сессиями. Так удается максимально приблизить нагрузку к поведению живых пользователей.
Этап 4. Прогрев системыПеред основным тестом систему нужно прогреть. Этот этап часто пропускают, но без него результаты будут искажены. Мы выдерживаем стенд под нагрузкой не менее часа — примерно на уровне 75 % от планируемого пика RPS. На этом этапе важно не менять код и конфигурации, даже если находим ошибки. Любые исправления вносятся только после завершения тестирования и повторного анализа метрик. После запуска нагрузки проверяем, что система работает в штатном режиме: сервисы откликаются, ресурсы не на пределе, а поведение приложений соответствует ожидаемому. Этап 5. Запуск тестовДля проведения тестов используем связку инструментов:
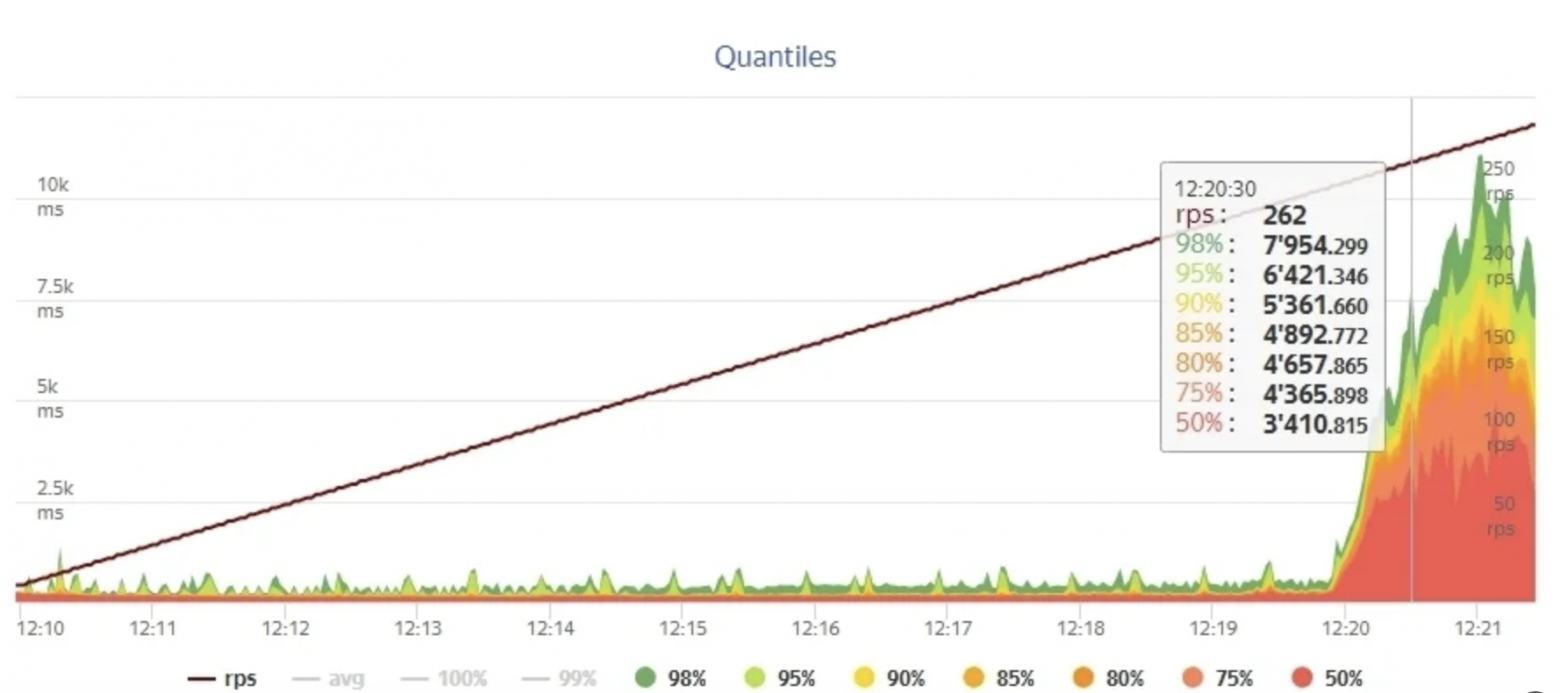
Процесс:
На реперных точках (100 %, 200 %, 300 % от номинальной нагрузки) вручную проверяем работоспособность сайта. Автоматические проверки не всегда замечают «мягкие» деградации — страница может возвращать 200 OK, но часть контента не загрузится. Тест останавливаем по достижении целевой нагрузки или при отказе системы. Этап 6. Анализ результатов и формирование рекомендаций.После завершения тестов переходим к анализу данных. Основное внимание — на время отклика, долю ошибок и число медленных запросов. Результаты оформляем в виде графиков (Zabbix, Grafana) и сводных таблиц. Задача — понять поведение системы: что именно стало узким местом и при каких условиях. Пример интерпретации: при нагрузке 250 RPS среднее время отклика выросло с 300 мс до 1,5 с. Анализ показал: узкое место — запрос к таблице товаров. По итогам формируем список рекомендаций для оптимизации — с приоритизацией по влиянию на производительность. После внедрения изменений тест повторяем, чтобы подтвердить эффект. Инструменты нагрузочного тестирования: краткий обзорКаждый инструмент в нагрузочном тестировании хорош по-своему. Мы собрали короткий обзор, чтобы проще было выбрать под задачу:
Мы используем проверенную связку инструментов:
Такой набор позволяет контролировать весь процесс — от генерации нагрузки до разбора причин просадок производительности. Более подробно читайте в нашем блоге. Как это работает на практике: реальный кейс, как мы подготовили интернет-магазин к Черной пятницеКлиент готовился к масштабной акции. Текущий пик нагрузки — 150 RPS, прогноз после запуска рекламы — до 500 RPS. Что сделали:
Результаты:
После теста:
В повторном тестировании система выдержала 500 RPS со временем отклика <400 мс. В итоге Черная пятница прошла без сбоев и деградации производительности. Чек-лист: что нужно для успешного нагрузочного тестирования
Нагрузочное тестирование показывает, как система ведет себя в реальных условиях — под наплывом пользователей, на пиках продаж, в моменты, когда все должно работать без сбоев. Это инструмент, который помогает заранее увидеть слабые места и подготовиться, пока не начался аврал. Потраченное время окупается уверенностью: в день Х система не подведет ни команду, ни бизнес. Буду рад вашим вопросам и историям в комментариях — обмен опытом всегда полезен! |