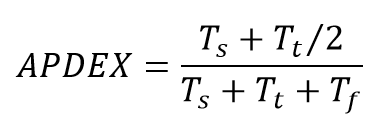Что пишут в блогах
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Python для тестировщиковНачало: 10 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Python для начинающихНачало: 16 июля 2026
-
Азбука ИТНачало: 16 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
| Применение APDEX в нагрузочном тестировании |
| 06.02.2024 00:00 | ||||||||||||||||||||||||||||||
|
Автор: компания Simbirsoft При автоматизации нагрузочных тестов специалисты рано или поздно приходят к мысли о том, как сравнивать результаты проводимых тестов. И не только сравнивать, но и демонстрировать результаты команде и бизнесу. Часто сравнение результатов нагрузочных тестов напоминает игру «найди 10 отличий» на почти одинаковых картинках. И если для специалистов в тестировании производительности это не проблема, то для коллег, не погруженных в теорию, это может стать таковой. Тут необходим какой-то простой и наглядный индикатор, который легко позволит определить — показатели стали лучше или хуже в процессе работы над проектом.
Меня зовут Олег, я инженер по исследованию производительности в SimbirSoft. Для обобщения результатов тестов я предлагаю рассмотреть использование индекса APDEX (Application Performance inDEX). Если поискать упоминание APDEX в Рунете, то чаще всего его используют для оценки производительности 1С. Мы же внедрили этот индекс в нагрузочное тестирование. Причин для выбора APDEX было несколько. Во-первых, простота расчета и легкая адаптация под использование результатов тестов. Во-вторых, наглядность результата и легкость интерпретации. Статья будет полезна специалистам по нагрузочному тестированию, а также SDET и автоматизаторам тестирования. Начнем с описания стандарта APDEX. По сути это будет изложение официальной документации, и в том или ином виде оно встречается в любой статье, посвященной APDEX. Так что если вы уже знакомы с методикой расчета, то можете пропустить следующий раздел и сразу переходить к реализации расчета APDEX, иначе можете испытать легкое чувство дежавю. Содержание: Что такое APDEXAPDEX — открытый стандарт, разработанный с целью формирования объективной оценки показателей производительности корпоративных информационных систем. APDEX расшифровывается как Application Performance inDEX, и если первоначально этот индекс использовался для оценки производительности систем, то сейчас его применяют в различных областях для оценки практически любых значений — от времени отклика приложения до качества продуктов питания, результатов хирургических операций или времени на восстановление после них, а также времени для налива пива (примеров последнего не нашел, но на официальном сайте есть такая информация). APDEX — это по сути число от 0 до 1, где 0 — всё настолько ужасно, что лучше даже и не представлять ситуацию, когда у нас будет такой результат, а 1 — все отлично, пользователи довольны и рукоплещут разработчикам (ну или мы что-то не учли при настройке тестов). Расчет APDEXДля расчета мы будем брать времена ответов тестируемого сервиса, и это будет единственным фактором, влияющим на значение индекса. Основная идея APDEX заключается в том, чтобы преобразовать сложные данные о производительности в простой числовой индекс. Он основан на разделении всех запросов на три группы:
Граница между «отличными» и «удовлетворительными» ответами обозначается буквой Т, а граница, за которой начинается зона «плохих» ответов, обозначается буквой F. Обычно стараются придерживаться соотношения F=4T. У нас значение F взято из требований к системе и составляет 5 секунд. По идее значение T должно быть 1,25 секунды, но так как спецификация рекомендует, а не обязывает использовать такое соотношение, то мы взяли 1,5 секунды. После этого производится расчет APDEX по формуле:
где Ts - число запросов, попавших в зону Satisfied Time, Tt - число запросов, попавших в зону Tolerating Time, Tf - число запросов, попавших в зону Frustrated Time. Из формулы очевидно, что APDEX всегда будет принимать значения в интервале от 0 до 1. Реализация расчета APDEXВ силу простоты формулы можно реализовать расчет легко на любом ЯП, которым вы владеете, и он есть под рукой. В моем случае первая версия скрипта была написана на Bash. Сразу могу предупредить, что так делать можно, но не нужно. Скрипт работает значительно медленнее, чем реализация на Python или Java. Для часового теста на нашем проекте расчет шел примерно полчаса. Кстати, JMeter из коробки умеет рассчитывать APDEX и включает его в отчет. За подробностями добро пожаловать в официальную документацию. Мы не стали использовать штатный отчет по нескольким причинам. Во-первых, заставлять Jmeter формировать огромный отчет, чтобы потом из него парсить одно значение, выглядит как-то странно. Во-вторых, было интересно самому реализовать расчет индекса. В дальнейшем расчет APDEX был включен в шаблон нашего отчета, который собирается по итогам всех тестов и использует много данных, отсутствующих в родном отчете JMeter. Интерпретация результатов APDEXПо результатам теста идет расчет индекса APDEX. В классических случаях используют таблицу с оценками для определенных диапазонов значений индекса. Но применительно к нагрузочным тестам мы сравниваем значения индекса для разных тестов. Конкретное значение у нас используется при оценки прохождения теста в TeamCity для отображения статуса теста. В этом случае мы берем значение 0,85 (не спрашивайте, почему именно такое — так исторически сложилось). Вот примеры из тестов для разных значений индекса. Первый тест выполнялся на нагрузке больше, чем система может выдержать. По графику времен ответов (синий график и правая ось) видно, что есть запросы, время ответа которых превышает F:
По итогам этого теста мы получили следующий результат:
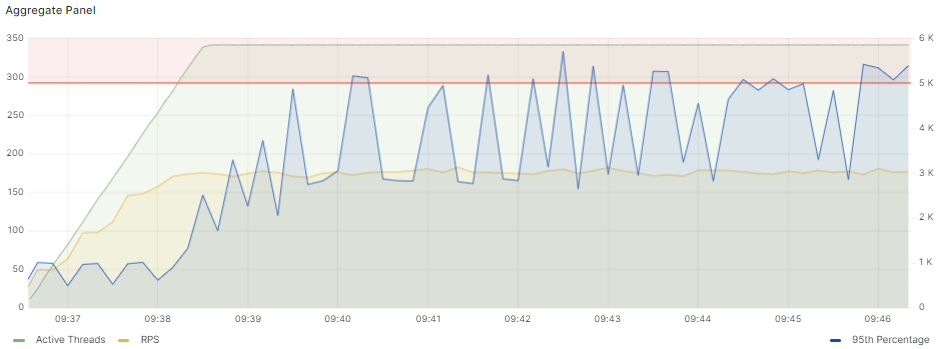
Второй тест выполнен с нагрузкой, близкой к максимальной, и по графику времен ответа видно, что на протяжении почти всего теста значения превышают T, а ближе к завершению превышают F:
По итогам этого теста мы получили следующий результат:
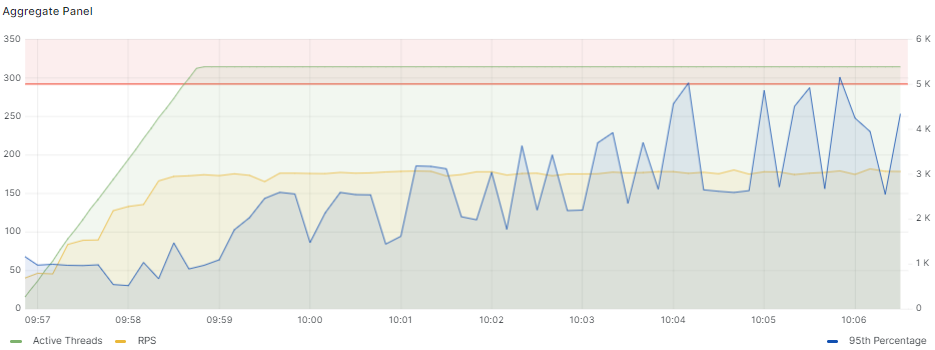
Третий тест выполнен с нагрузкой в зоне комфорта системы и по графику времен ответов видно, что значения времен ответа не выходят за границу T:
По итогам этого теста мы получили следующий результат:
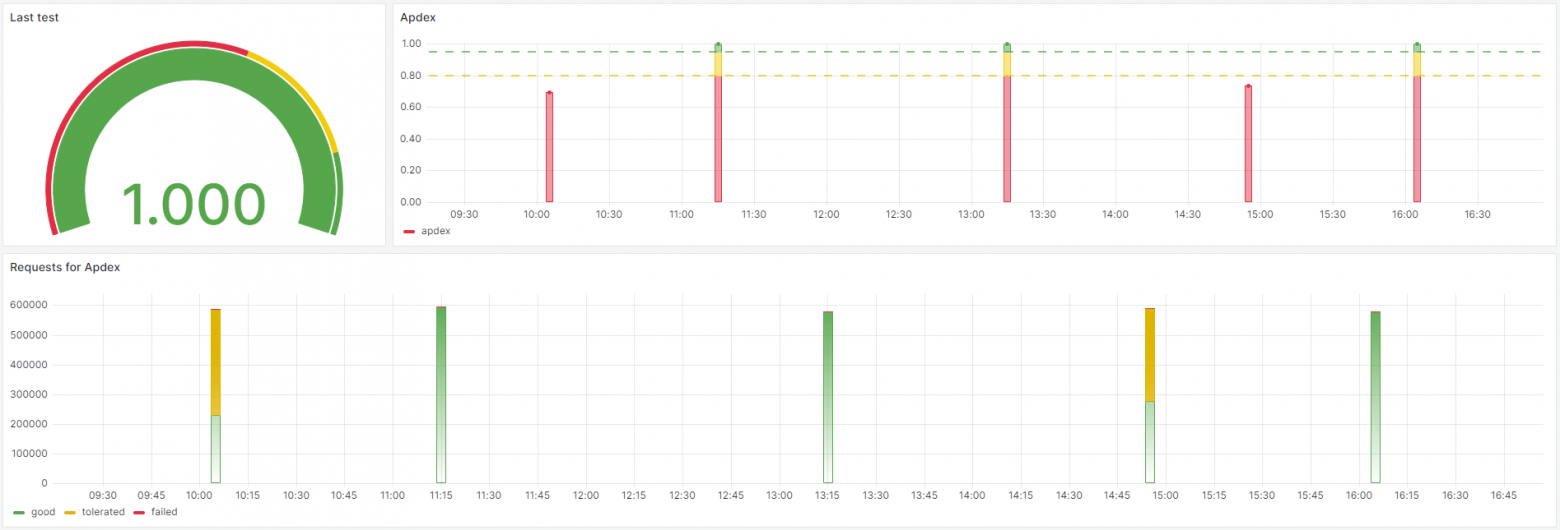
Визуализация результатовПо результатам тестов в отдельную таблицу записываются все параметры проведенного теста — число запросов, попавших в разные группы, параметры запуска теста, такие как: тестируемая сборка, уровень нагрузки, параметры, с которыми запускался скрипты и так далее. Для визуализации результатов тестов сделан простой дашборд в Grafana. В этой панели отображается результат последнего теста, а также данные предыдущих тестов — индекс APDEX и значения, которые используются для его расчета. Так же сделаны фильтры, которые позволяют выделить тесты по уровню нагрузки или номеру сборки.
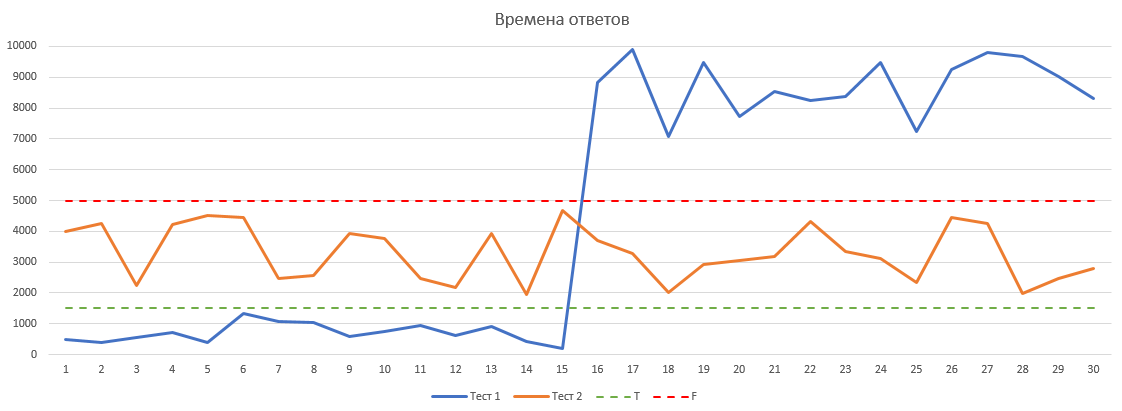
Опыт использования, проблемыИндекс APDEX нельзя использовать без оглядки на общую картину. Как и в случае с квартетом Энскомба, индекс может принимать одинаковые значения в тестах, где распределение времен запросов будет кардинально отличаться. Рассмотрим несколько вариантов тестов: Тест 1 до середины шел успешно, времена ответов не превышали Т, но в середине что-то сломалось, и времена ответов улетели в космос, то есть превысили порог F. В этой ситуации значение индекса будет равно 0,5. С самого начала Теста 2 времена ответов превысили Т, но не пересекли порог F. По итогам этого теста значение индекса будет также равно 0,5.
В обоих тестах значение индекса одинаковое, но картина происходящего отличается и без учета дополнительных данных индекс не даст нам никакой информации об успешности или неуспешности проведенного теста. Индекс удобно использовать в случае регрессионного тестирования, когда мы хотим сравнить значение индекса с результатами предыдущих тестов и определить улучшение или ухудшение результатов. Важно при этом помнить, что нельзя изменять значения T и F между тестами, так как мы не сможем сравнить результаты. Как побочный эффект — регулярные тесты могут помочь с определением проблем в инфраструктуре. Например, у нас нагрузочные тесты запускаются каждую ночь. И однажды значение индекса резко упало. Оказалось, что тест запустился с агента, который использовал проблемное хранилище. Но из-за того, что с него раньше нагрузочные тесты не запускались, никто не обращал внимания на низкую скорость хранилища. Также опыт использования показал, что использовать APDEX в тестах с растущей нагрузкой смысла нет, так как там значения индекса отличаются даже для одних и тех же условий. Еще отдельный момент, с которым мы столкнулись на практике — APDEX можно использовать для сравнения результатов нагрузочных тестов, когда нагрузка близка к максимальной. В этом случае индекс будет принимать значения меньше 1, и тогда сравнение будет иметь смысл. На минимальной нагрузке значение индекса всегда будет равно 1, и сравнение потеряет смысл. Это можно обойти подбором значений T и F, но зачем? Мы же все-таки занимаемся нагрузочным тестированием. ЗаключениеПодытоживая все вышеописанное, можно сказать, что APDEX — это дополнительный инструмент (а если быть точным, то метрика) в руках тестировщиков, который позволяет объединить количественные и качественные аспекты оценки производительности. В силу универсальности его легко адаптировать для оценки практически любых показателей, используемых в тестах. Однако не стоит использовать этот индекс как универсальную линейку для оценки производительности системы. Обратная сторона простоты — отсутствие детализации. Важно не забывать, что это только один из множества инструментов. Полезные ссылкиСпасибо за внимание! |