Что пишут в блогах
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Python для тестировщиковНачало: 10 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Python для начинающихНачало: 16 июля 2026
-
Азбука ИТНачало: 16 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
| Модульное тестирование производительности в Kubernetes или Как мы выиграли время на чай и здоровый сон для НТ-инженера |
| 04.10.2023 00:00 |
|
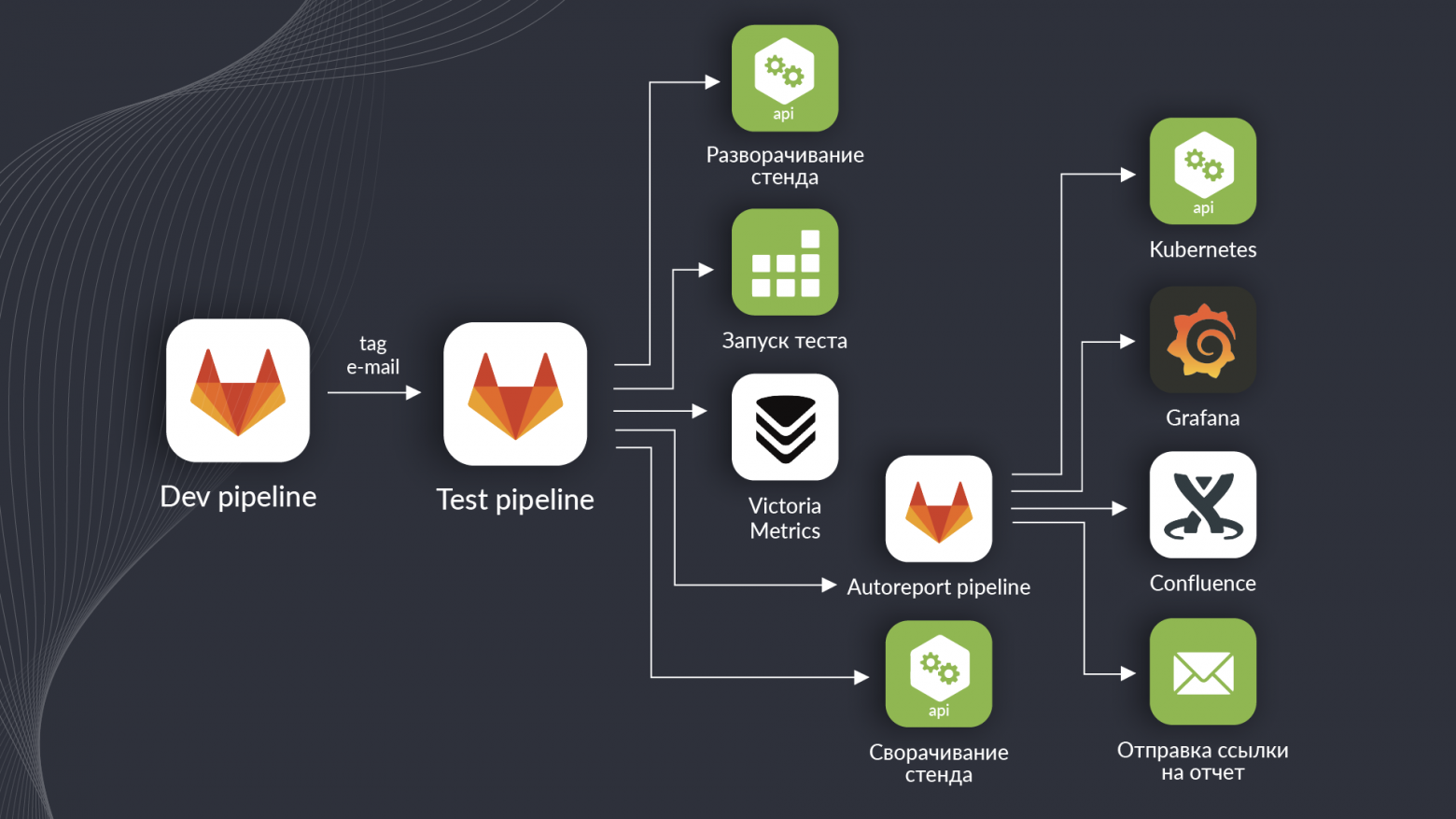
Всем привет! Меня зовут Сергей Лысов, я занимаюсь тестированием производительности платформы интернета вещей ZIIoT Oil&Gas. Если вы о ней еще не слышали, то велком сюда. А в этой статье я расскажу о том, как мы ускоряли и упрощали ее тестирование через автоматизацию контроля тестов и сборки отчетов, а также внедрение изолированных тестов. Точнее — с чего мы этот путь начали и куда примерно движемся. 5 главных сложностей тестирования производительности платформы ZIIoT Oil&Gas Стоить начать с того, что ZIIoT Oil&Gas — сложное произведение девелоперского искусства, состоящее из более чем 100 микросервисов и объединяющее почти все самые модные ИТ-технологии. Эта особенность делает тестирование производительности платформы непростой задачей. Вот пять основных проблем, от которых мы хотели избавиться полностью или хотя бы частично с помощью автоматизации: 1. Сложный и долгий запуск тестовДля запуска тестов производительности требуется подготовить стенд, выделить ресурсы нужным сервисам, запустить необходимое количество экземпляров сервисов, настроить платформу для тестирования, собрать контейнер с тестом и задеплоить его в Kubernetes. 2. Ручной контроль выполнения тестаПосле запуска теста необходимо контролировать его выполнение: отслеживать ключевые метрики, чтобы вовремя остановить тест, когда системе станет плохо. Можно подумать, что нет ничего криминального в том, что тест будет пинать уже мертвую систему. Однако помимо бесполезной траты ресурсов это еще может вызвать проблемы с системой, переполнение очередей, места для логов и прочие неприятности, для исправления которых потребуются время и нервы инженера нагрузочного тестирования (НТ), а иногда и DevOps’а. 3. Каждый тест требует много вычислительных ресурсовВ связи с тем, что мы тестируем систему большими компонентами (несколько микросервисов), которые в свою очередь используют другие компоненты, для каждого запуска теста требуется более 100 CPU, а это достаточно много. 4. Ручное формирование отчетаВ тестах обычно задействовано несколько десятков сервисов, большинство — в нескольких экземплярах. Таким образом, даже тест небольшого компонента потребует фиксации нескольких сотен метрик, а также конфигурации по ресурсам и версиям используемых компонентов. Собрать руками пару-тройку сотен графиков и оформить все это в отчет — работа для очень терпеливого инженера, и на нее требуется безумное количество времени. 5. Позднее обнаружение багов и невозможность тестировать каждую сборкуНа данный момент мы тестируем только стабильные сборки платформы. То есть, отлаживаем и актуализируем тесты, когда выходит RC-версия, зачастую отлавливаем какие-то ошибки на этом этапе и далее прогоняем тесты на стабильной сборке. При таком подходе иногда бывает недостаточно времени на исправление обнаруженных дефектов производительности. В первую очередь нам захотелось избавиться от проблем под номерами 2 и 4, так как они отнимали наибольшее количество времени, и мы автоматизировали контроль выполнения теста и формирование отчетов. Автоматизация контроля выполнения теста и формирования отчетаАвтоматизацией контроля выполнения теста мы хотели добиться того, чтобы тест автоматически останавливался, когда какая то из метрик не удовлетворяет требованиям. К решению этой задачи мы подошли следующим образом:
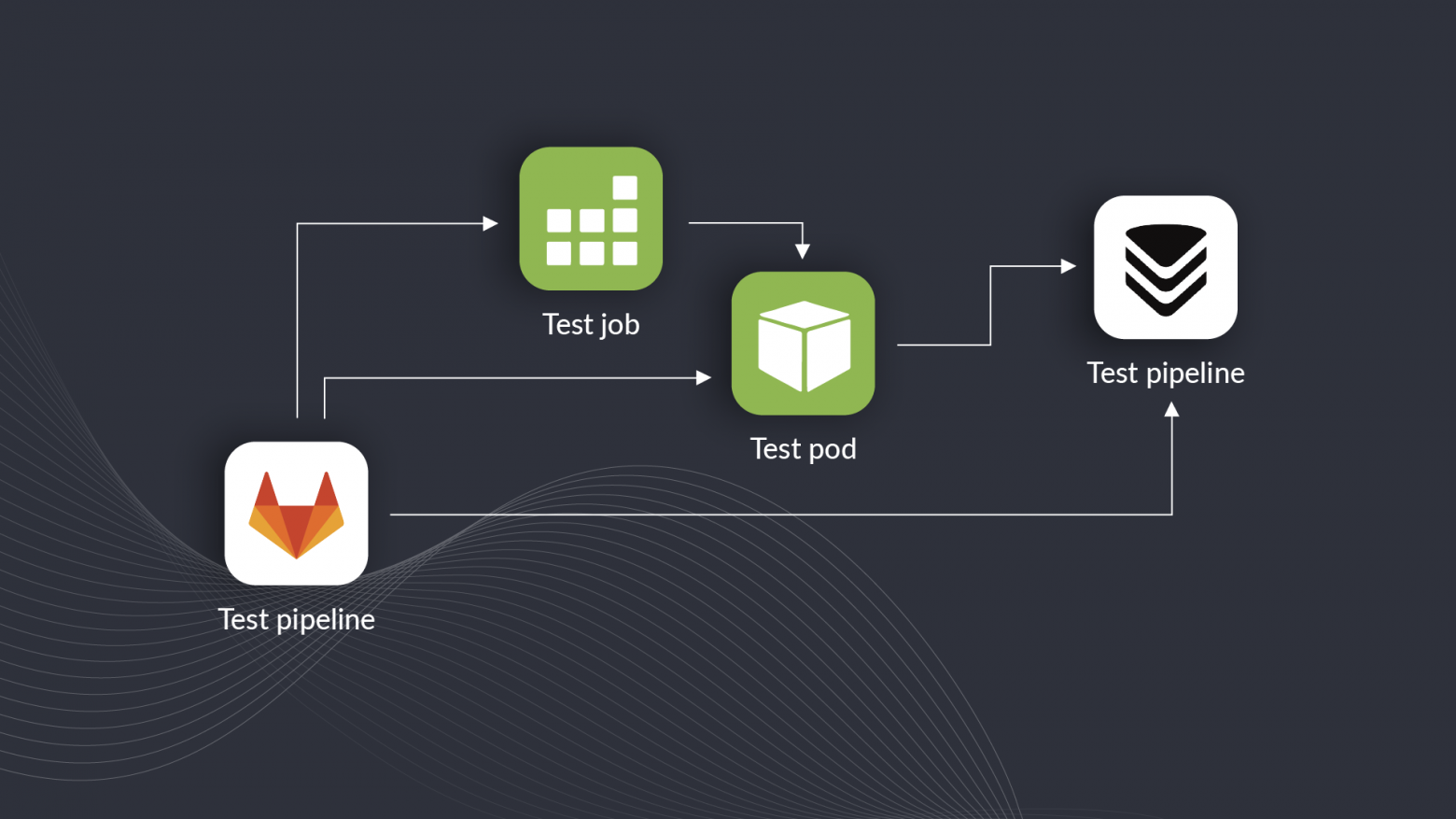
Изолированные тестыПосле того как мы поместили сборку и запуск теста в пайплайн, жить стало немного легче: не требуется контролировать выполнение теста, можно спокойно запускать тест на ночь и ложиться спать. Автоматическое формирование отчета тоже экономит уйму времени и позволяет проводить больше тестов. Очень полезным оказалось и оповещение в Telegram: получив уведомление о завершении одного тестирования, можно сразу же запускать следующее. Однако тестировать каждую сборку мы все еще не могли, но очень хотели. Да и запуск тестов по-прежнему съедал много ресурсов и требовал участия инженера НТ, а этого мы очень не хотели. Поэтому мы придумали внедрить изолированные тесты. Их суть в трех буллитах:
Кратко опишу, как это работает:
В результате мы получили быстрые сравнительные тесты без участия инженера НТ, которые не требуют много ресурсов. Обращу внимание, что тесты именно сравнительные — их результаты нельзя рассматривать как оценку производительности системы. Но они позволяют сравнивать одну версию с другой, чтобы оперативно понять влияние внесенных доработок на производительность. Что предстоит сделатьВ данной реализации нам сразу стало не хватать автоматического сравнения результатов. Сейчас требуется открыть два отчета и проанализировать их самостоятельно, чтобы сравнить одну версию с другой. В идеале хотелось бы наблюдать динамику от версии к версии на графике, а уже за подробностями переходить к отчетам. Пока мы не придумали, как это сделать, но обязательно придумаем. Еще было бы классно реализовать автоматическую проверку на соответствие требованиям, чтобы моментально получать результат — можно это релизить или нет. На этом у меня все. Если есть замечания, предложения или желание поделиться своим решением аналогичной задачи, то добро пожаловать в комментарии. |