Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Азбука ИТНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Python для начинающихНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Инженер по тестированию программного обеспеченияНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
-
Bash: инструменты тестировщикаНачало: 1 октября 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 1 октября 2026
-
Docker: инструменты тестировщикаНачало: 1 октября 2026
-
SQL: Инструменты тестировщикаНачало: 1 октября 2026
-
Git: инструменты тестировщикаНачало: 1 октября 2026
| Анализ результатов нагрузочного тестирования |
| 21.08.2020 00:00 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Автор: Рогожников Максим (Тинькофф) С каждым днем в мире становится все больше и больше инструментов для проведения нагрузочного тестирования. Собственно, и сам интерес к этой теме начинает возрастать.
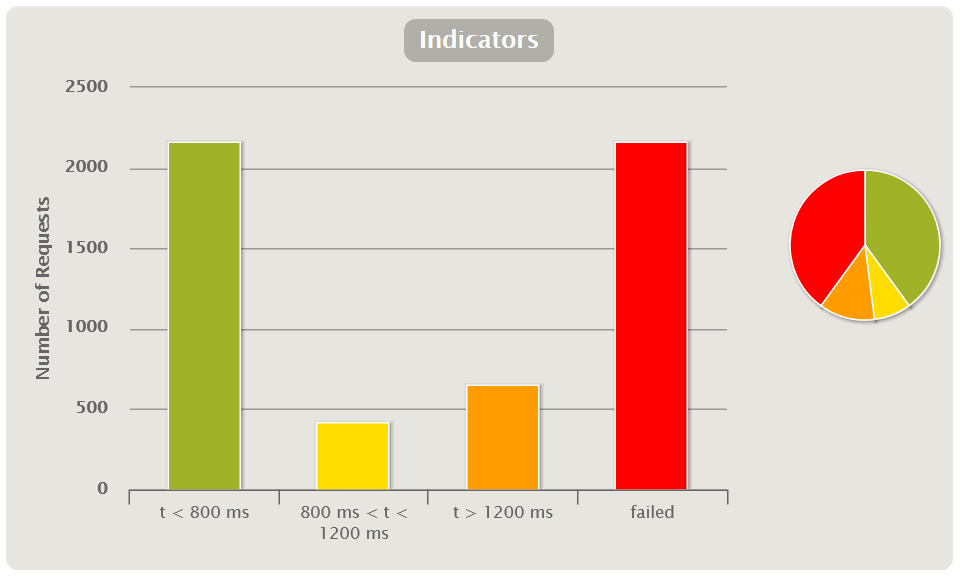
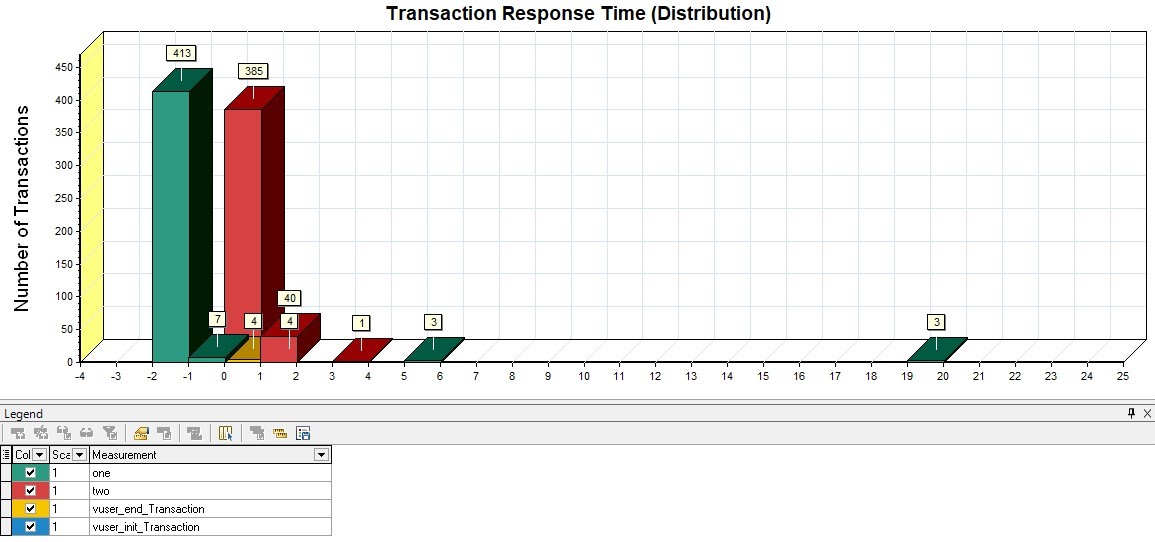
Основная задача инструмента нагрузочного тестирования — подать заданную нагрузку на систему. Но кроме этого есть еще одна, не менее важная задача — предоставить отчет о результатах подачи этой нагрузки. Иначе мы проведем тестирование, но ничего не сможем сказать о его результате и не сможем достаточно точно определить, с какого момента началась деградация системы. Прежде чем писать любой отчет, нужно понять, для кого мы его пишем и какую цель преследуем. Нет никакого смысла добавлять множество графиков времени отклика приложения в отчет по каждой операции, если ваша цель — определить, есть ли утечки памяти, зафиксирована ли нестабильная работа во время теста надежности, или если вам нужно сравнить два релиза между собой в рамках регрессионного тестирования. Для ответа на эти вопросы вам хватит всего пары графиков, если, конечно, вы не зафиксировали проблемы и не хотите в них разобраться. Поэтому, прежде чем создавать отчет, подумайте, а точно ли вам нужно добавить все графики в него или лишь наиболее показательные и дающие ответ на цель тестирования. Также набор графиков и их анализ для отчета зависят от выбранной модели нагрузки — закрытой или открытой, так как разные модели дадут разные фигуры на графиках. Основные метрикиИндикаторыПоказывают количественное и процентное распределение времени отклика запросов по группам. Графики этого типа удобно использовать, чтобы дать быструю предварительную оценку результатам тестирования без более глубокого анализа остальных графиков.
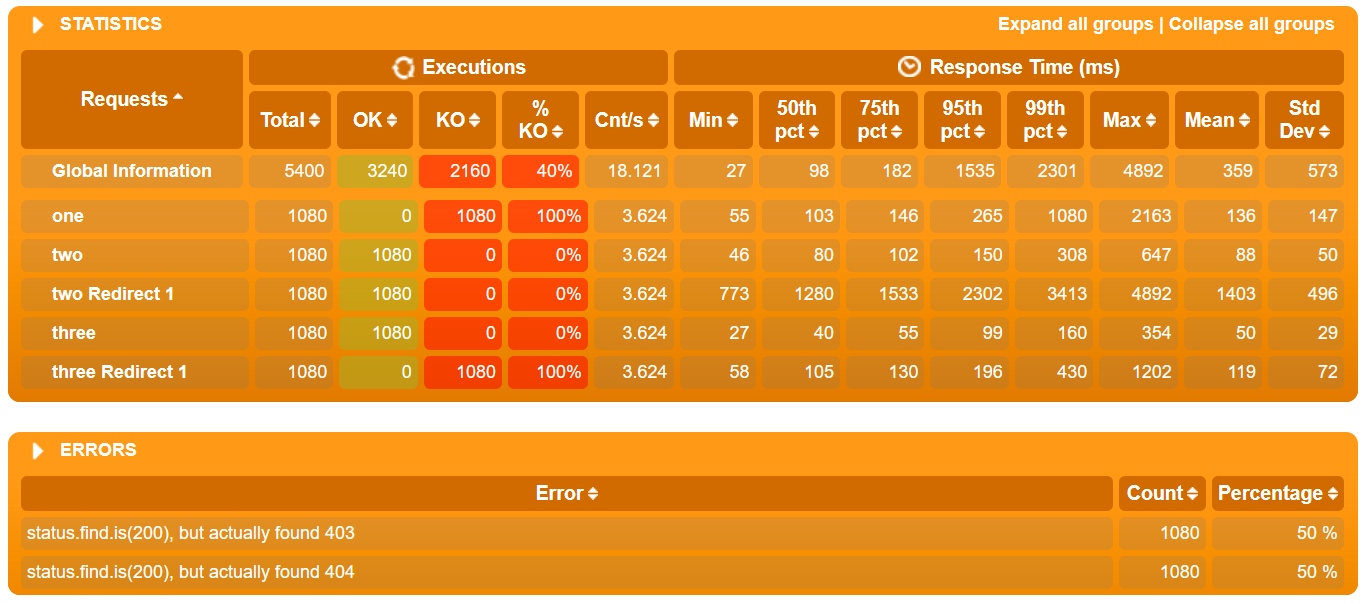
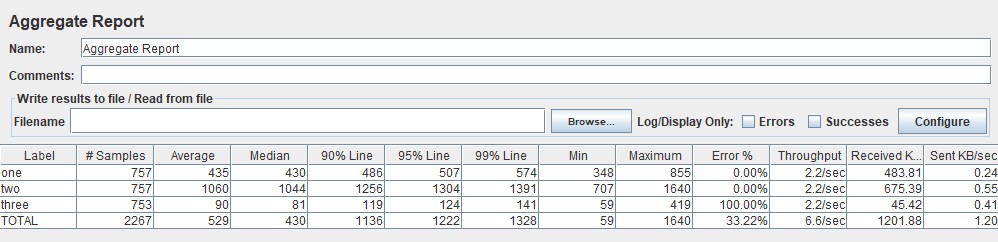
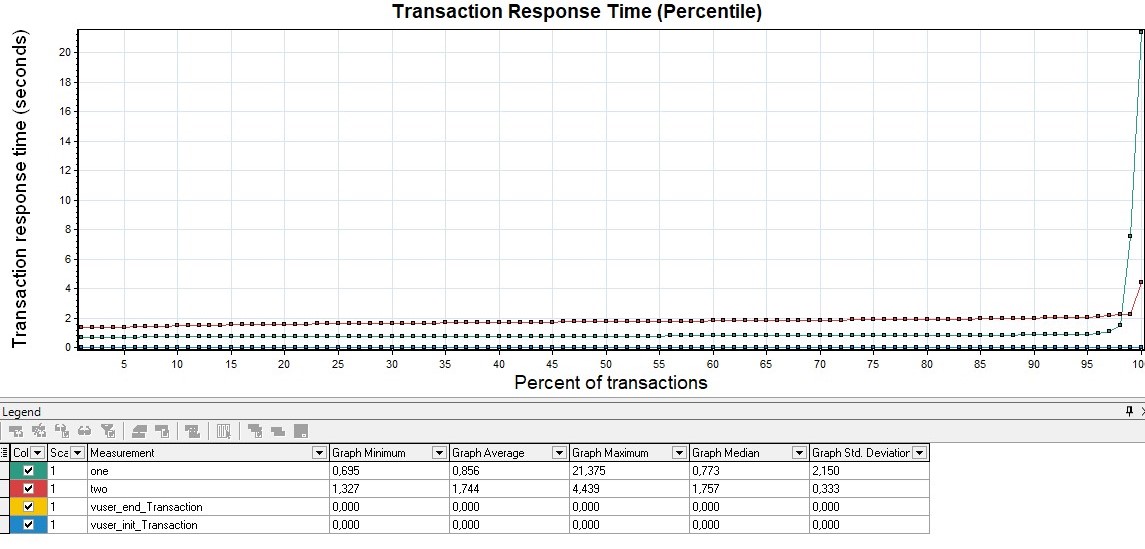
В Gatling вы сами можете настроить пороги для перехода из группы в группу и их количество в файле gatling.conf. Графики такого типа лучше строить на основе методики. APDEX (Application Performance Index) Таблица с временем откликаПо умолчанию Gatling строит таблицу по перцентилям, среднему и максимальному времени отклика, а также по ошибкам. По ней отслеживается выход за пределы SLA (превышение нефункциональных требований). Обычно в SLA указывают перцентили 95, 99 и процент ошибок. Таким образом таблица позволяет получить быструю оценку результатов тестирования.
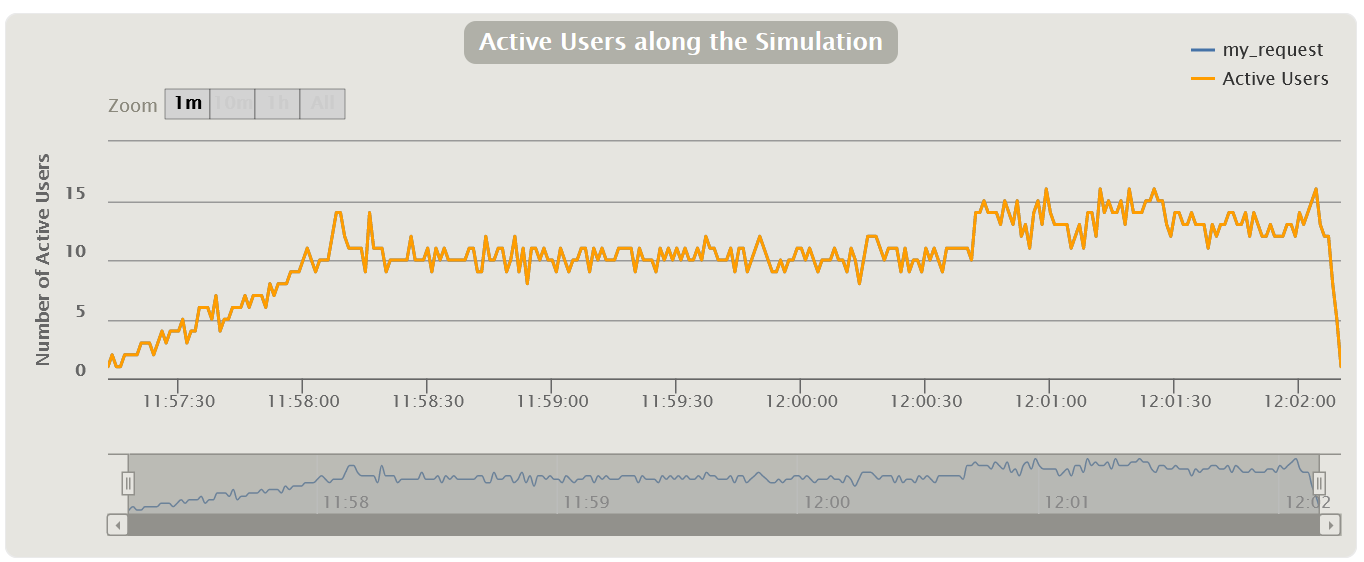
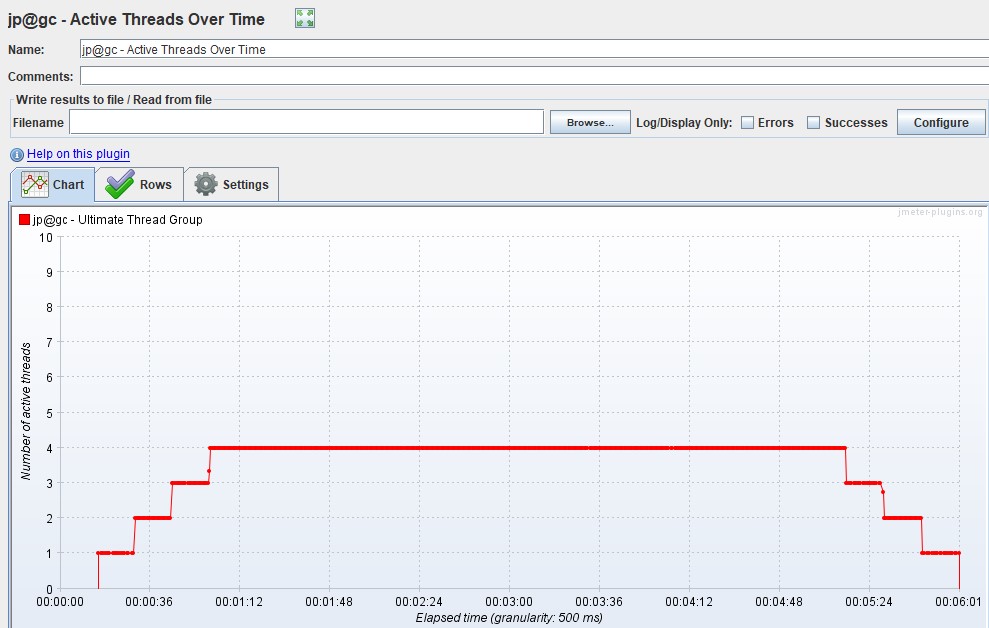
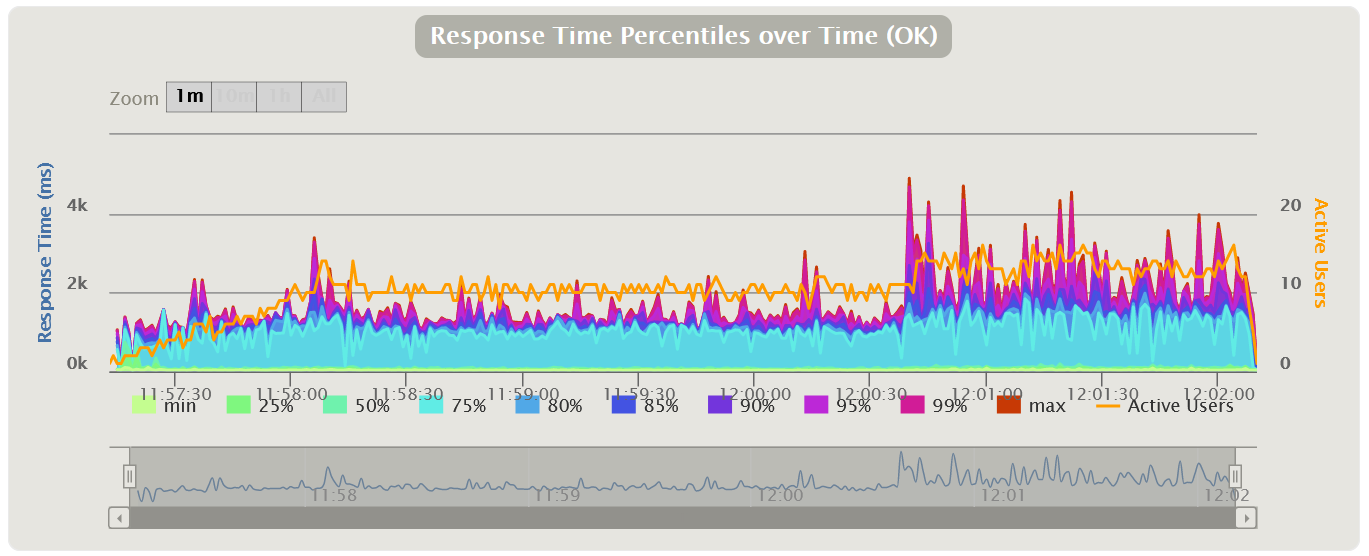
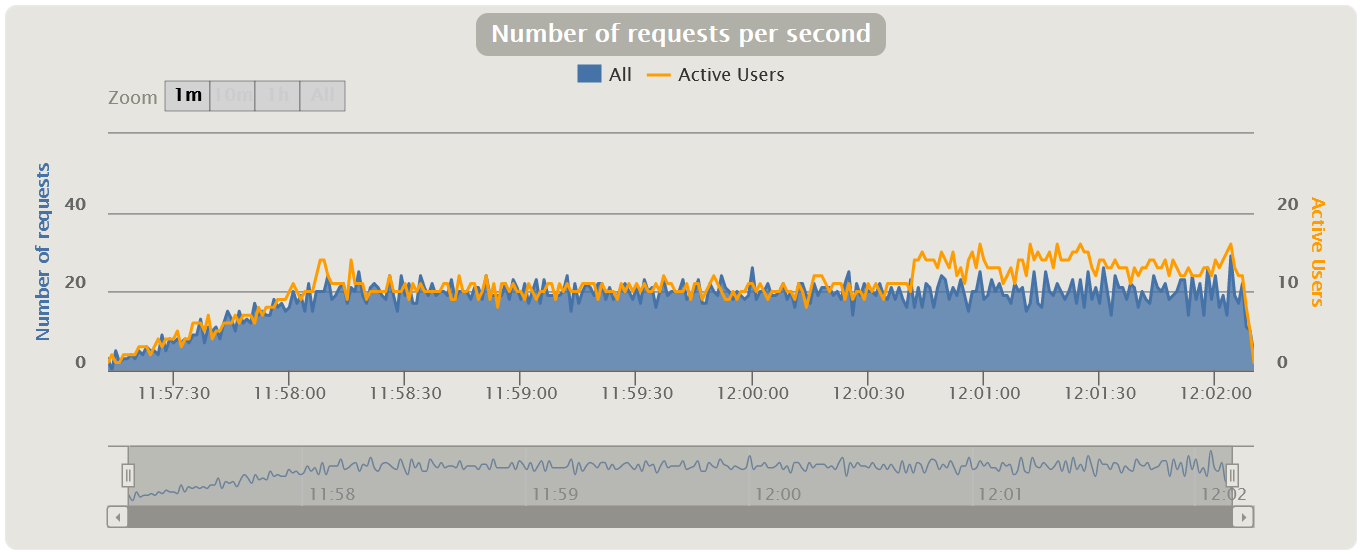
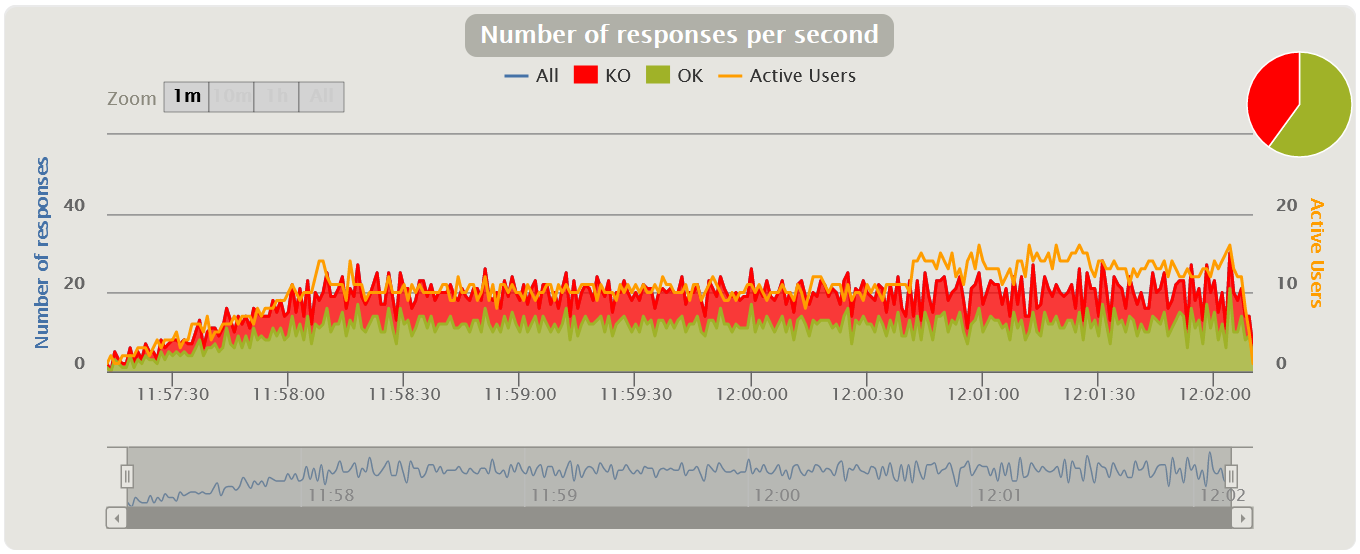
График Virtual Users Обычно измеряется в штуках и показывает, как пользователи заходят в приложение, тем самым иллюстрируя реальный профиль нагрузки. Стоит сразу оговориться, что для MF LoadRunner и Gatling эти графики показывают количество Virtual Users, а для Apache JMeter — количество Thread.
Вид графика также зависит от модели нагрузки:
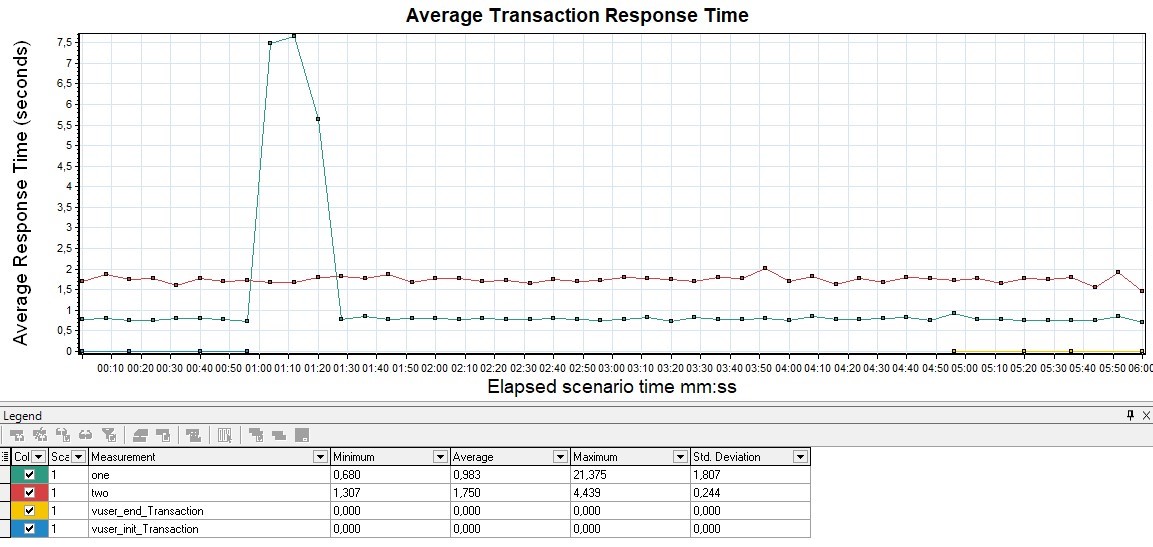
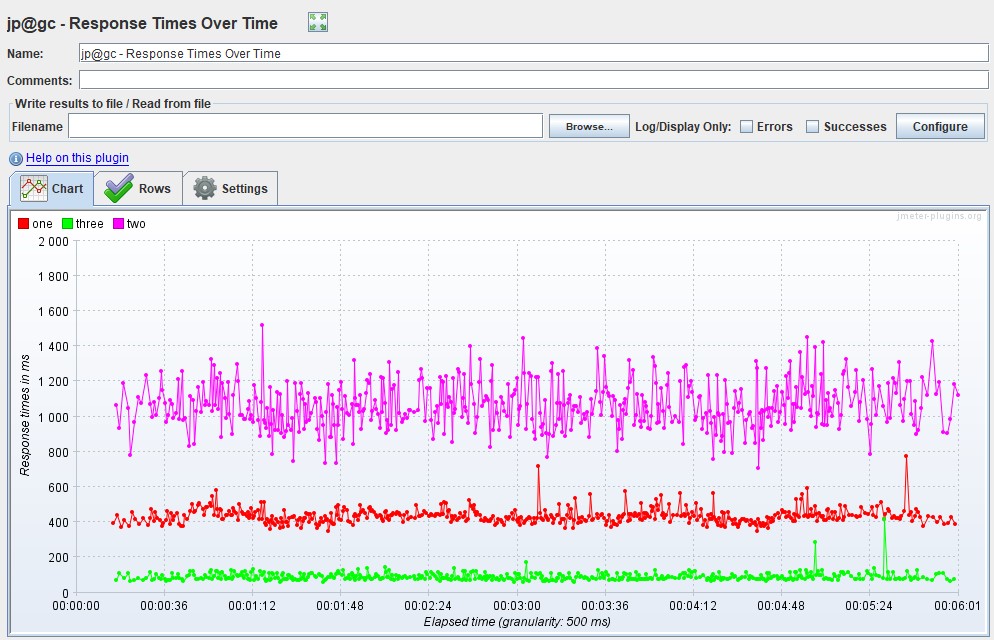
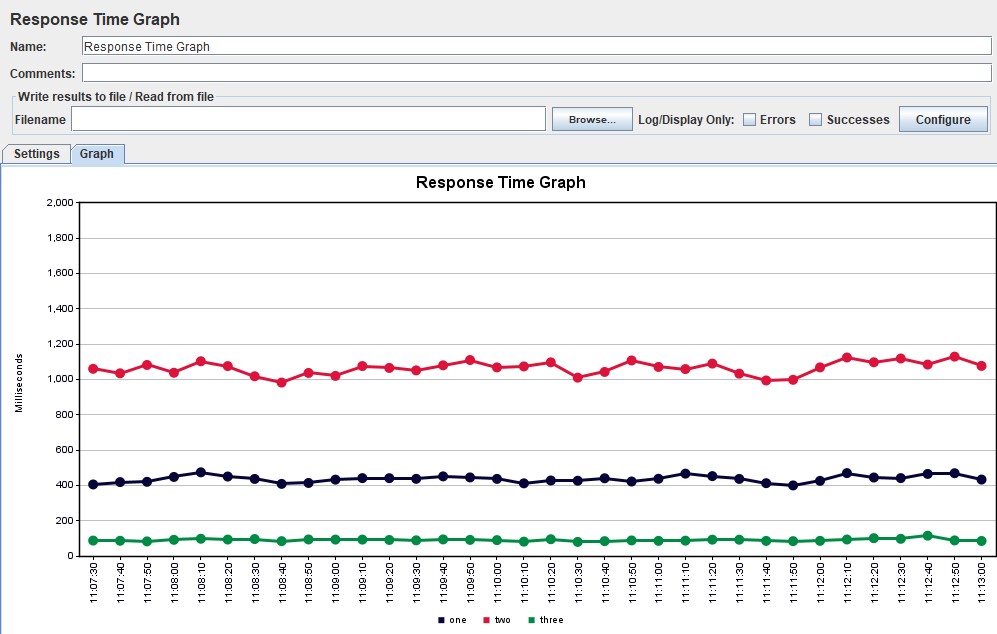
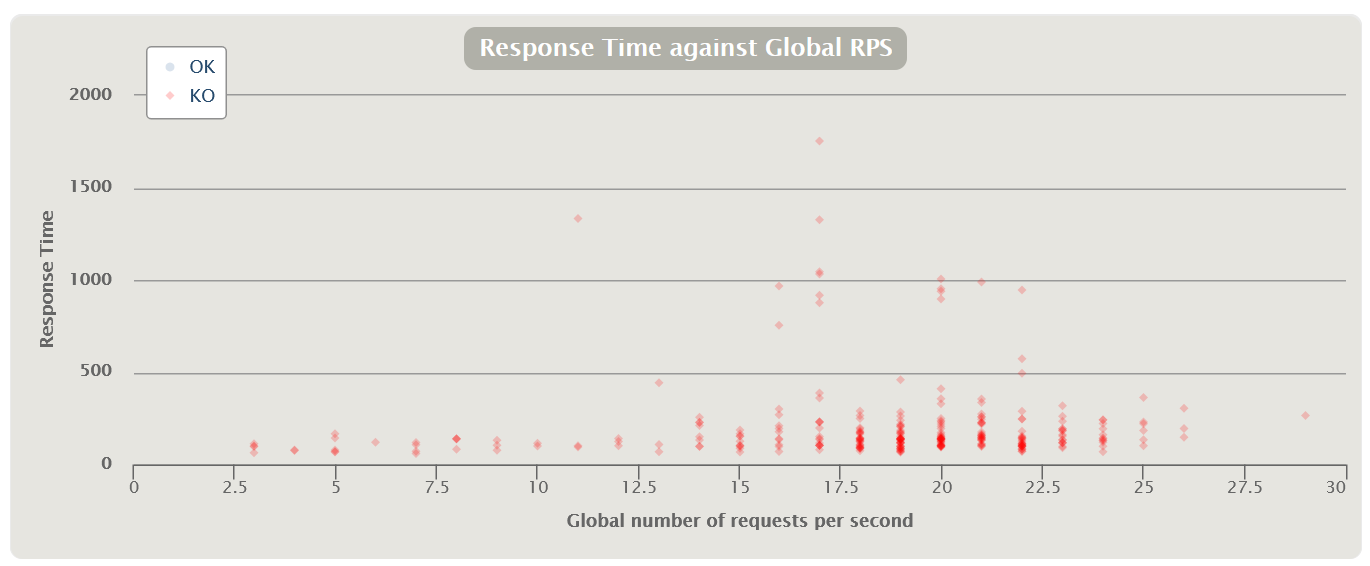
График Response Time Чаще всего измеряется в миллисекундах — показывает время ответа на запросы к приложению. Время отклика не должно превышать SLA. Этот график является основным инструментом для поиска точек деградации при проведении нагрузочного тестирования.
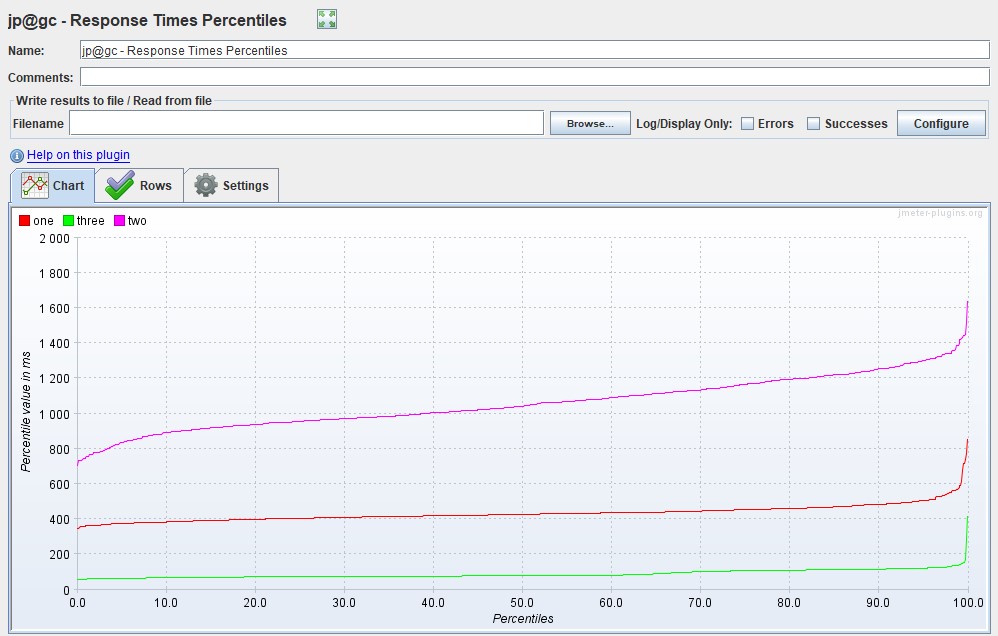
Вариации графикаВозможна модификация, в которой применяются перцентили времени отклика и добавляется линия среднего времени отклика по всем запросам. Использование перцентилей здесь будет более правильным решением, так как среднее время отклика очень чувствительно к резким выбросам.
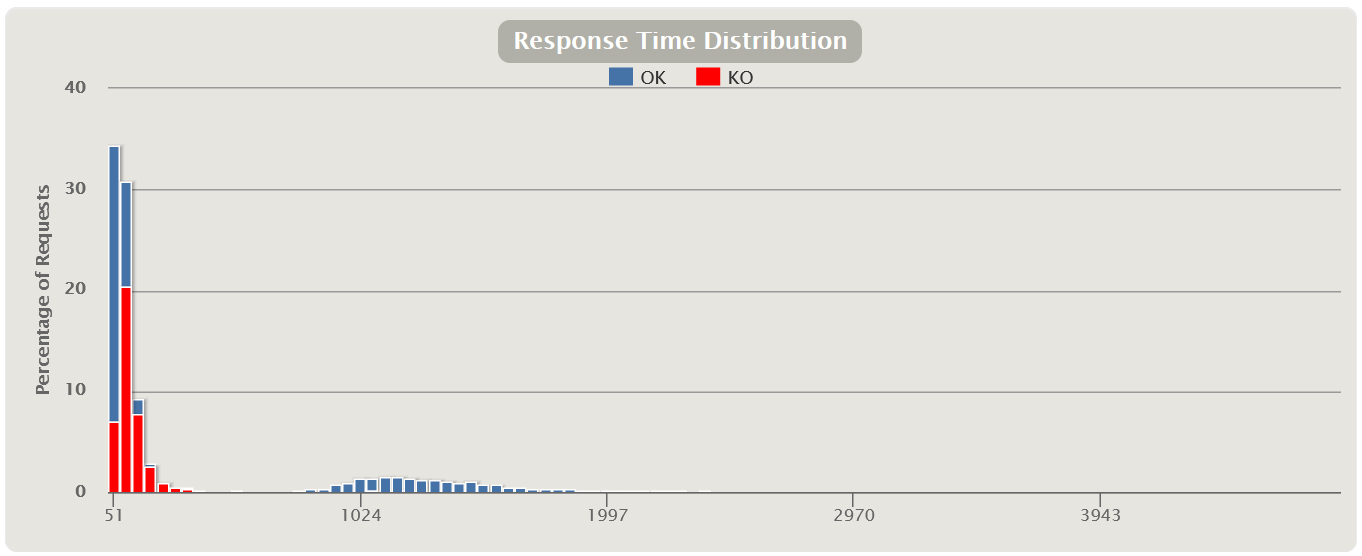
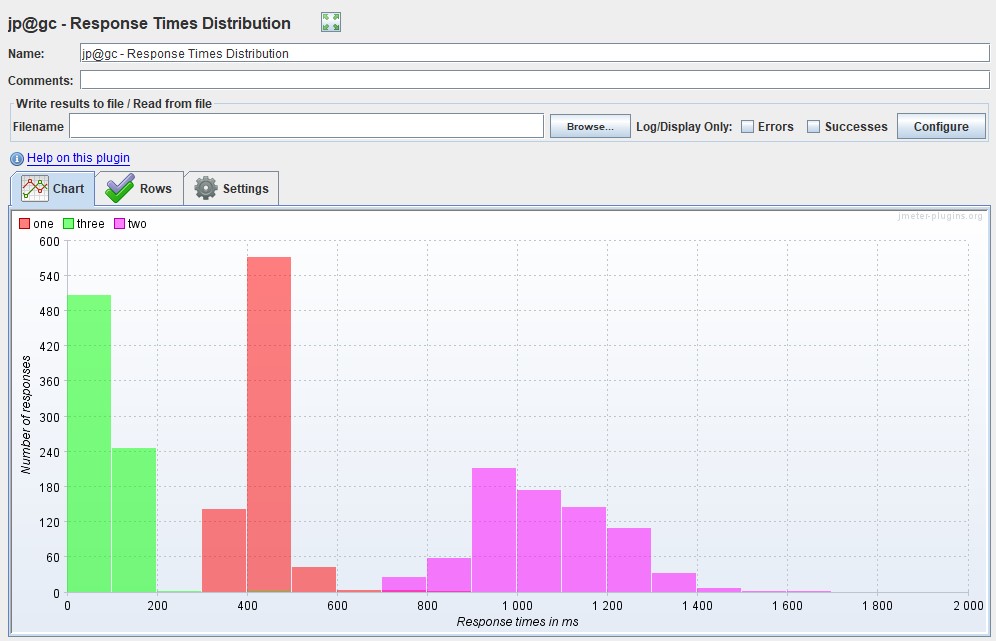
Распределение Response Time Также есть прекрасные графики, показывающие зависимость распределения времени от количества запросов.
Latency Из этой метрики также можно выделить дополнительный параметр Latency (миллисекунды) — время задержки (чаще всего под этим понимают Network Latency). Этот параметр показывает время между окончанием отправки запроса до получения первого ответного пакета от системы.
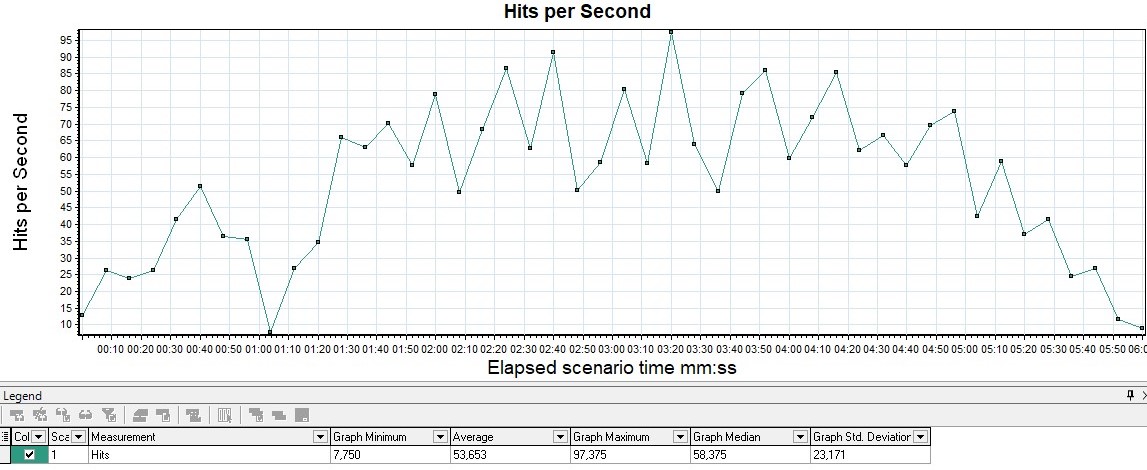
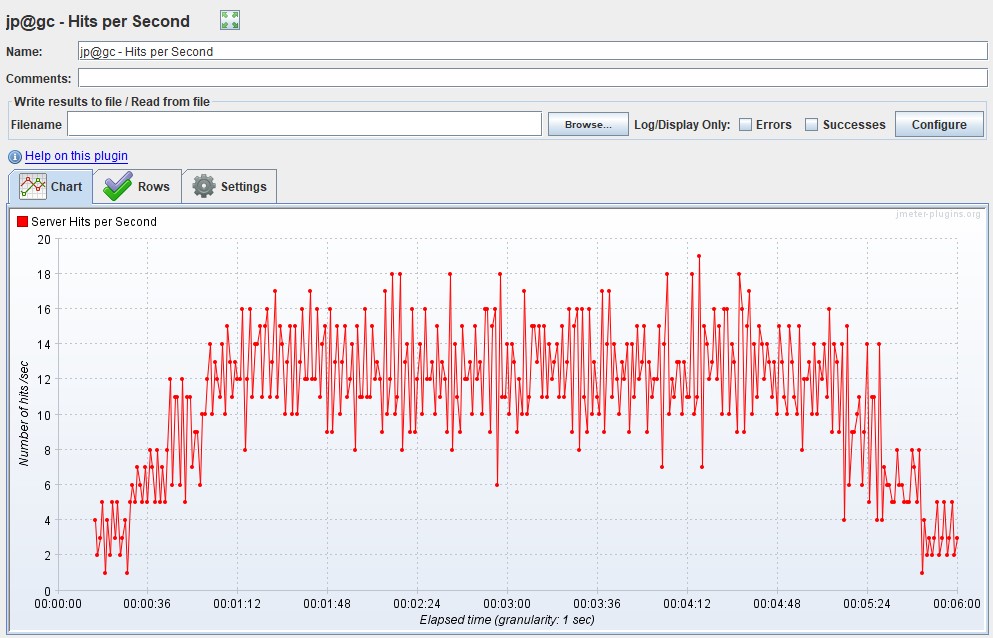
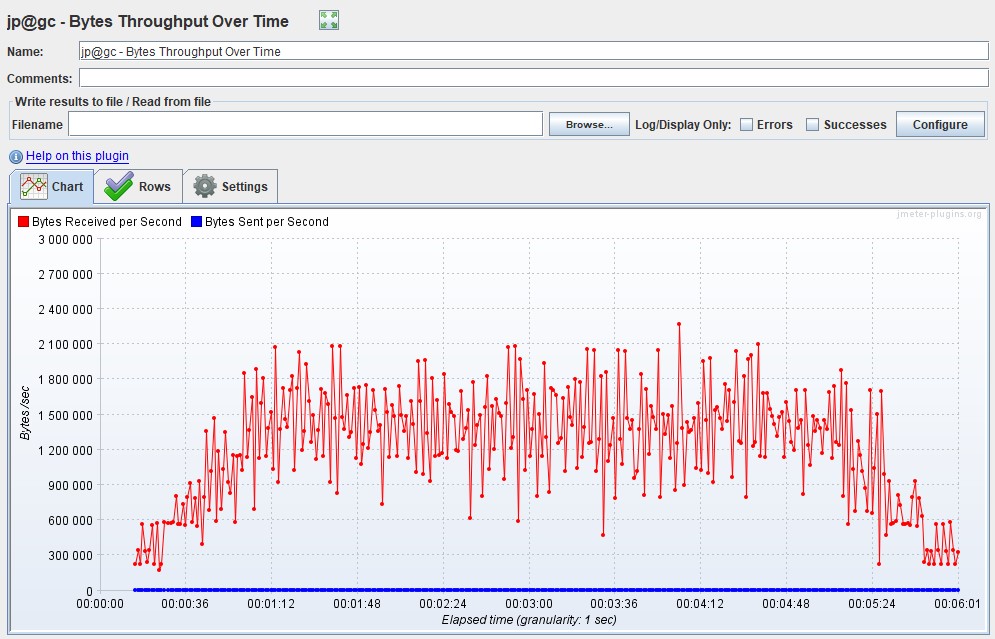
Bandwidth Аналогично метрике выше можно выделить параметр Bandwidth (килобит в секунду) — ширину пропускания канала. Он показывает, какой максимальный объем данных может быть передан за единицу времени. График Request Per SecondИзмеряется в штуках в секунду — показывает количество запросов, поступающее в систему за 1 секунду.
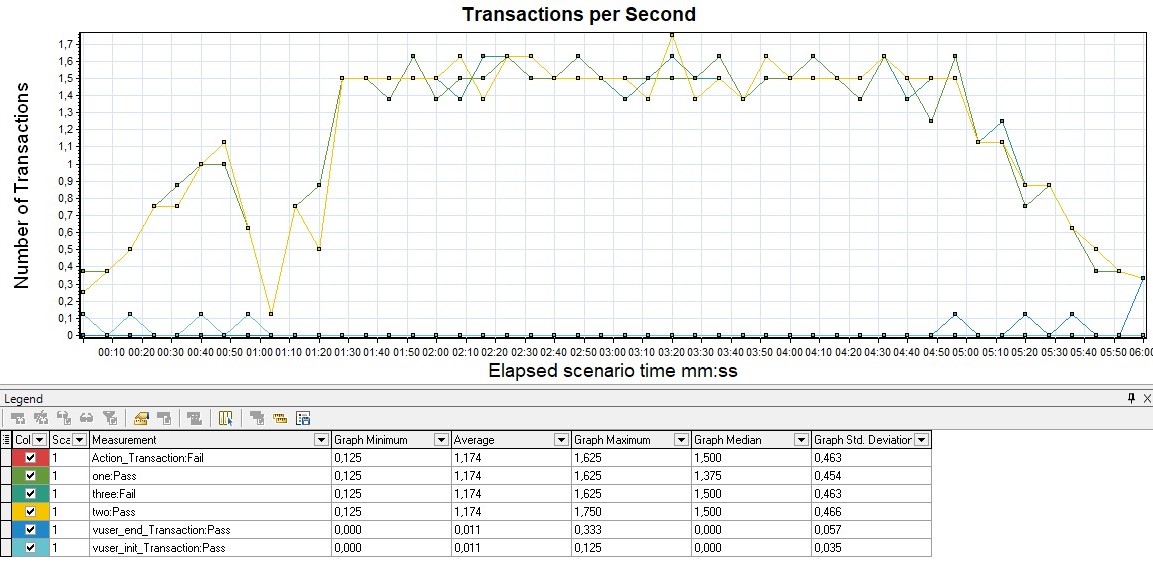
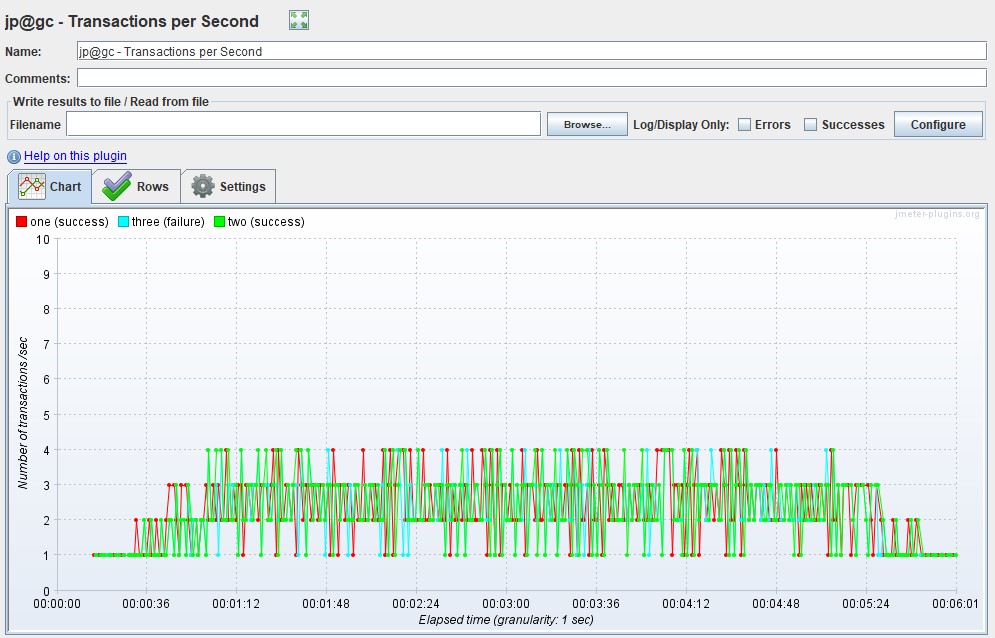
TPS
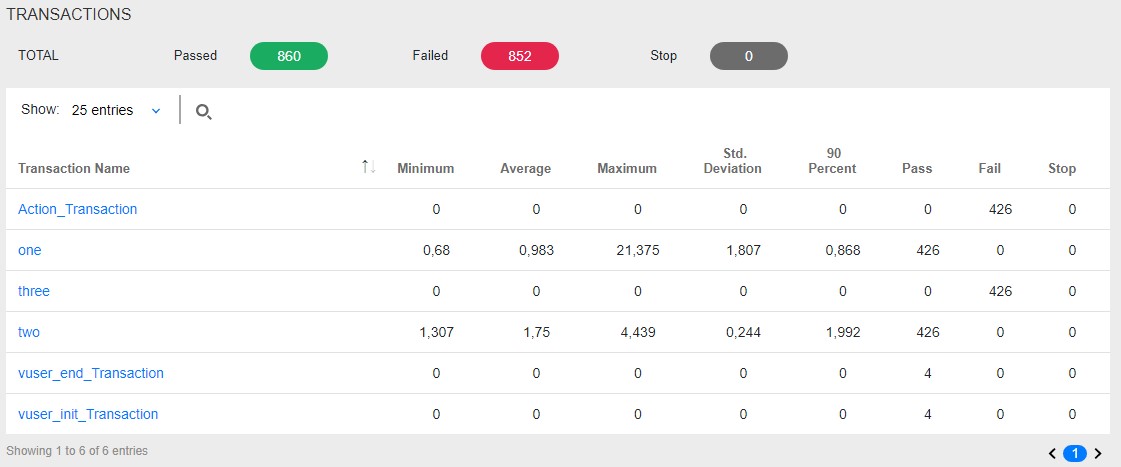
Измеряется в штуках в секунду и показывает количество транзакций (в рамках транзакции может быть множество запросов) за 1 секунду.
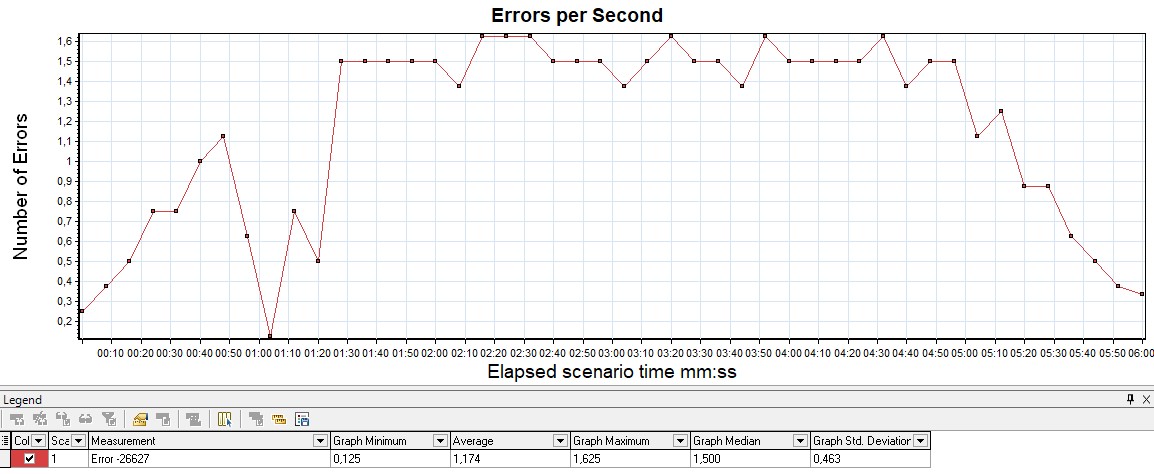
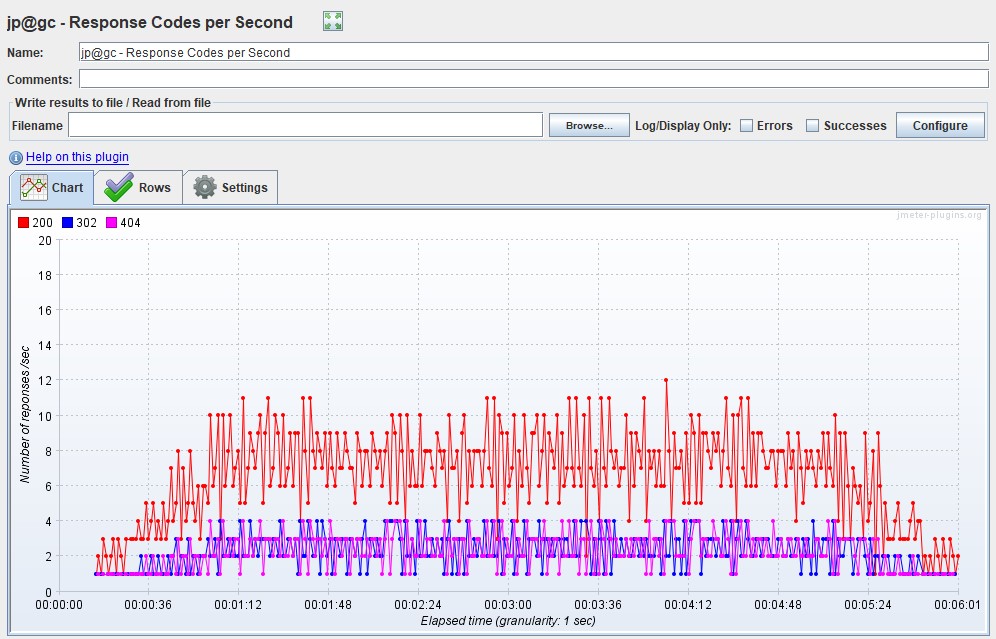
График Errors Обычно измеряется в rate (штук в секунду) — график показывает рост количества ошибочных запросов. Также удобно измерять значение в процентах от общего числа запросов. По этому графику отслеживается выход за пределы SLA по количеству или проценту ошибок.
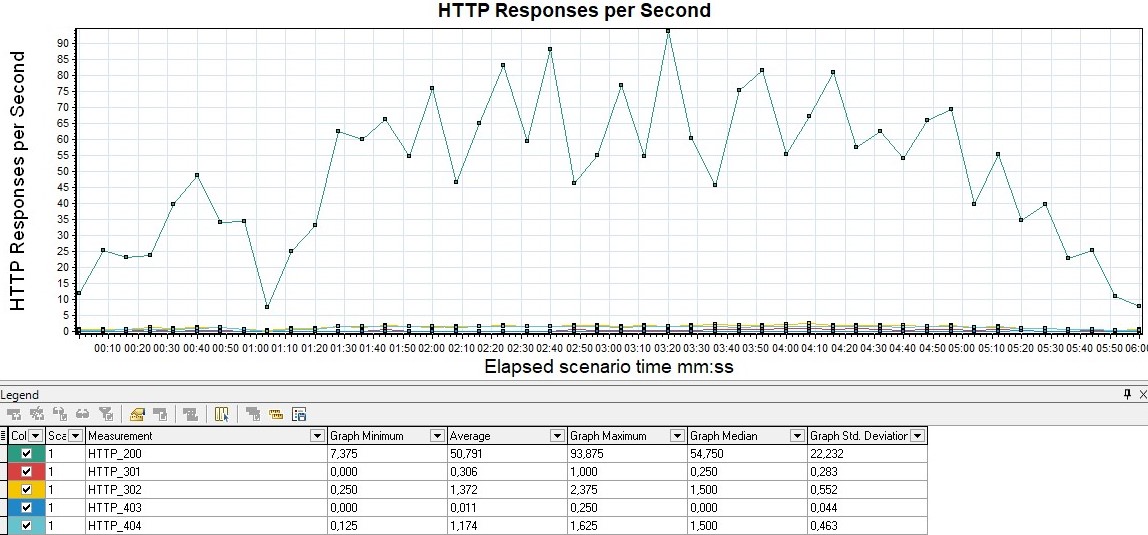
HTTP responses status
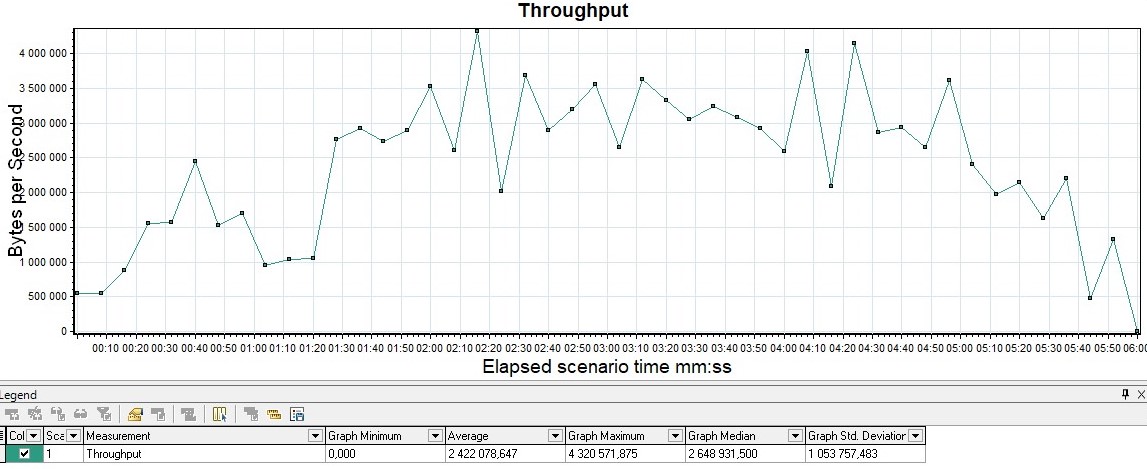
График Throughput Измеряется обычно в битах в секунду. График показывает пропускную способность приложения, а именно какой объем данных был отправлен и обработан приложением в единицу времени.
Возможные модификации
Получение графиков Большинство графиков можно получить, используя отчет HTML Based Gatling Reports после теста или же настроив связку мониторинга Graphite-InfluxDB-Grafana. Для отображения можно использовать готовый дашборд из библиотеки дашбордов https://grafana.com/grafana/dashboards/9935. Матричное описание метрикВсё, что мы описали выше, представлено в виде маленькой таблички, суммирующей все эти знания.
|