Что пишут в блогах
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Азбука ИТНачало: 16 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Python для начинающихНачало: 16 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
| Нагрузочное тестирование с locust. Часть 2 |
| 01.03.2019 00:00 |
|
Для тех, кому понравилась предыдущая статья Алексея Остапова, продолжаем публикацию его статей об инструменте для нагрузочного тестирования Locust.
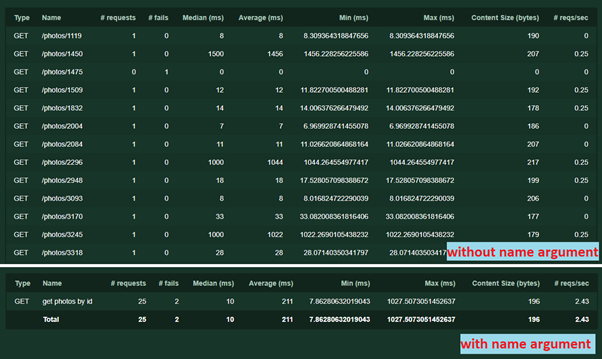
Обработка ответов сервераИногда в нагрузочном тестировании недостаточно просто получить от сервера HTTP 200 OK. Случается, надо еще проверить содержимое ответа, чтобы убедится, что под нагрузкой сервер выдает правильные данные или проводит точные вычисления. Как раз для таких случаев в Locust добавили возможность переопределять параметры успешности ответа сервера. Рассмотрим следующий пример:
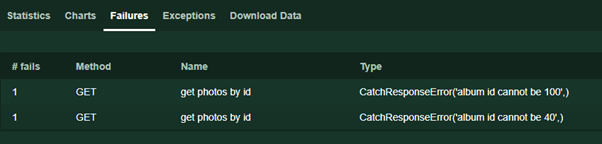
С сервера мы запрашиваем объекты photos со случайными id в диапазоне от 1 до 5000 и проверяем в этом объекте id альбома, предполагая, что он не может быть кратным 10 Тут сразу же можно дать несколько пояснений:
Работа со сложными сценариямиПочти каждый раз, когда ставится задача провести нагрузочное тестирование веб приложения, быстро становится ясно, что нельзя обеспечить достойное покрытие одними только GET сервисами — которые просто возвращают данные.
Из примера можно предположить, что вызывать сервисы в случайном порядке не получится, только последовательно. Более того, у товаров, корзины и формы оплаты могут быть уникальные для каждого пользователя идентификаторы.
В этом примере я добавил новый класс FlowException. После каждого шага, если он прошел не так, как ожидалось, я выбрасываю этот класс исключения, чтобы прервать сценарий — если пост создать не получилось, то нечего будет комментировать и т.д. При желании, конструкцию можно заменить обычным return, но в таком случае, во время исполнения и при анализе результатов будет не так хорошо видно, на каком шаге падает выполняемый сценарий на вкладке Exceptions. По этой же причине, я не использую конструкцию try… except. Делаем нагрузку реалистичнойСейчас меня можно упрекнуть — в случае с магазином все действительно линейно, но пример с постами и комментами слишком притянут за уши — читают посты раз в 10 чаще, чем создают. Резонно, давайте сделаем пример более жизненным. И тут есть минимум 2 подхода:
В классе UserBehavior я создал список created_posts. Обратите особое внимание — это объект и он создан не в конструкторе класса __init__(), поэтому, в отличии от клиентской сессии, этот список — общий для всех пользователей. Первая задача создает пост и записывает его id в список. Вторая — в 10 раз чаще, читает один, случайно выбранный, пост из списка. Дополнительным условием второй задачи является проверка, есть ли созданные посты. Еще немного возможностейДля последовательного запуска задач официальная документация предлагает нам также использовать аннотацию задач @seq_task(1), в аргументе указывая порядковый номер задачи
|