Что пишут в блогах
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Python для начинающихНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Азбука ИТНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
| Вы уже используете “Доменный анализ” / “Domain analysis” |
| 10.05.2023 00:00 |
|
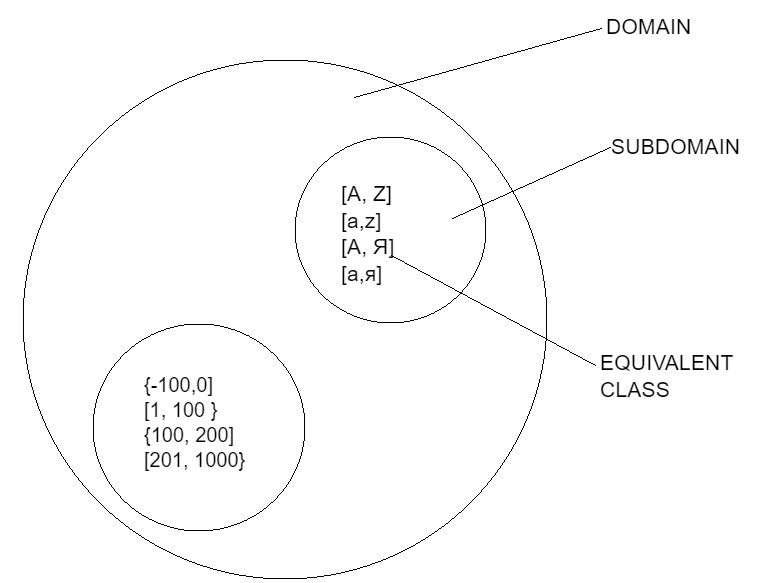
Автор: Никонов Владислав Статья написана в рамках моего личного блога о тестировании и QA: https://t.me/qanva_blog При изучении техники тест‑дизайна «доменный анализ», я столкнулся с тем, что многие авторы описывают ее по‑своему, что вполне логично. Перелопатить много разных статей об одном и том же, чтобы найти подходящее изложение материала и в конце концов понять желаемое — естественный процесс обучения. Но в случае доменного анализа, я заметил расхождение: кто‑то описывает данную технику сложно, а кто‑то ограничивается простой позицией — «это просто работа с классами эквивалентности и граничными значениями». Определение доменного анализа У данной техники тест‑дизайна много названий: «доменный анализ», «анализ классов эквивалентности», «доменное тестирование», «анализ эквивалентного разбиения», «тестирование областей определения», «domain analysis». Это, чтобы вы не растерялись на собесе =) Прежде, чем штудировать источники информации, давайте посмотрим, что можно вытащить из различных определений понятия «Доменный анализ»:
Для себя я вынес следующее:
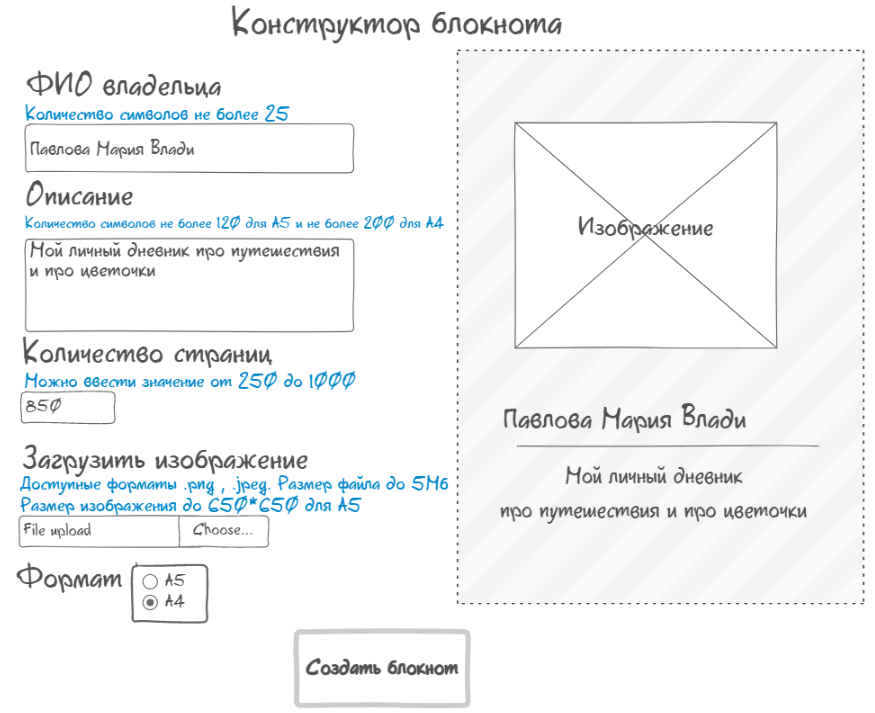
Сформулировать свое полное определение попытаемся в конце =) Что такое “домен”?В большинстве источников игнорируют это понятие и сразу идут в бой с примерами использования техники. Для меня это было проблемно, так как ни сразу понятно, что конкретно нужно объединять в область значений и где здесь сам «домен». Для примера возьмем сайт создания блокнота по описанию пользователя. На нем есть такая форма:
Домен, в данном случае, это сама форма с ее полями, так как поля формы относятся к одной части функционала и объеденины общей логикой. Мы не будем тестировать каждое поле по отдельности, а заполнив каждое отдельное поле подобранным, определенным образом, значением, нажмем кнопку «Создать блокнот«. То есть «домен» — это логически связанные между собой шаги/переменные/объекты, в рамках одного функционала: форма авторизации, форма регистрации, оформление заказа в интернет магазине, заполнение данных о пользователе, конвертирование различных форматов файла на разных ОС, окно редактирования изображения, отдельная зона игровой локации, инвентарь персонажа, окно крафта конкретной вещи из инвентаря персонажа и т. д. Хочу заметить, так понятие «домен» понимаю лично я. И в данной статье буду опираться на него. Но, что интересно: как правило, в других источниках «доменом» называют конкретный параметр. Например, в форме авторизации, поле ввода логина мы можем ввести определенный текст. В данном случае текст(строка) — домен. Далее, строку логически делят на поддомены: латиница, кириллица, символьная строка, длинная строка, короткая строка..все это классы эквивалентности. И далее выбирают определенных представителей из диапазона эквивалентности, а также граничные значения. Мне кажется что «домен» это про объединение параметров общей логикой и про множественность параметров, а не про отдельные параметры. Моя логика следующая: логически объединяем набор параметров ( домен ) > каждый параметр( поддомен) разбиваем на классы эквивалентности > выбираем представителей из каждого класса эквивалентности:
Алгоритм использования техникиДля успешного использования техники, в разных источниках, в совокупности прослеживаются следующие шаги:
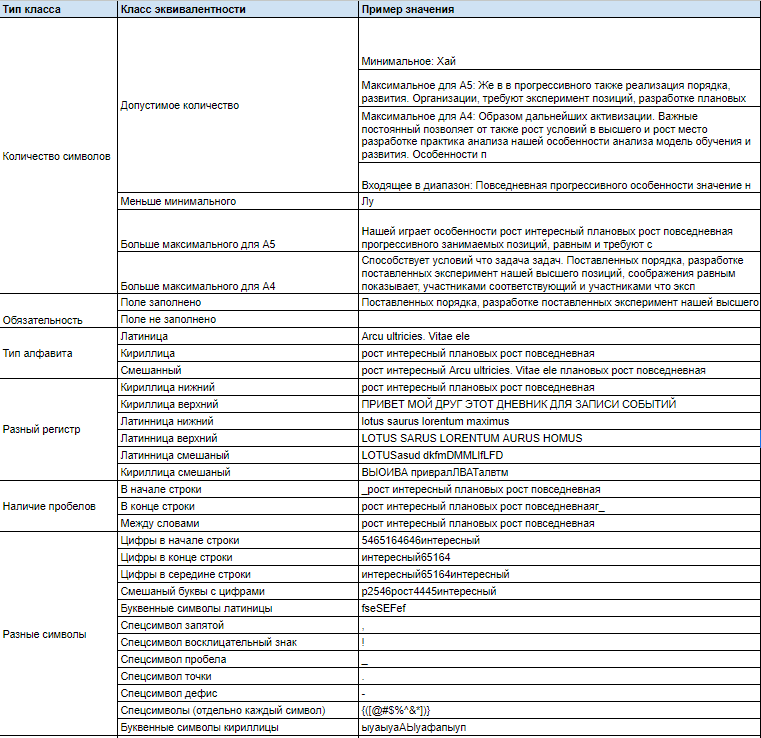
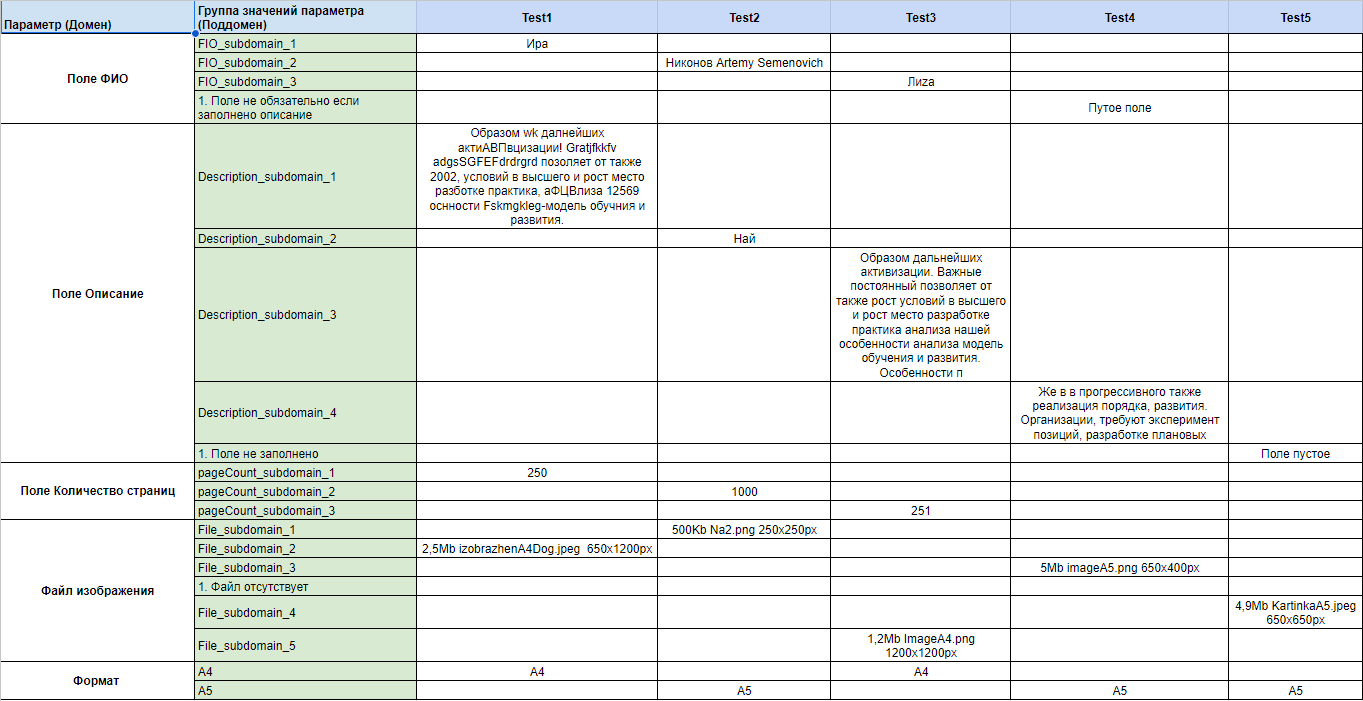
Анализ входных параметровКак мы можем заметить, мы постоянно анализируем наши параметры и пытаемся найти связи их друг другом, какие-то ограничения и риски. Выделяем входные параметры: Поле ФИО:
Поле Описание:
Поле Количество страниц:
Загрузить изображение:
Применение уже знакомых техник тест дизайнаИтак, поддомен для нас это совокупность всех возможных значений переменной. Перед нами стоит задача выделить подобласти для каждого параметра, все элементы которых предположительно приводят к одинаковому результату выполнения программы для сокращения количества тестов. Как минимум мы можем разбить на две подобласти — валидные и невалидные значения. Эту задачу как раз прекрасно решает техника разбиения на классы эквивалентности.
Также необходимо убедиться, что границы области заданы верно, в чем нам поможет анализ граничных значений. Но данную технику не всегда можно применить, так как существуют упорядоченные и неупорядоченные классы эквивалентности, и в неупорядоченных нет способа выделить граничные значения, которые с большей вероятности могут привести к возникновению сбоя. В таком случае можно попробовать разбить неупорядоченный класс эквивалентности на подклассы и взять по значению из каждого. Например, множество символов с клавиатуры: класс эквивалентности — символы с клавиатуры, подклассы: числовые символы, специальные символы на разных раскладках, буквенные символы на разных раскладках, сочетания двух клавиш, сочетания трех клавиш. При использовании граничных значений, важно помнить, что данная техника не ограничивается числовыми границами диапазонов. Также существуют:
Также важно выделение особых точек:
В этом поможет спецификация и коллеги, которые лучше разбираются в продукте — аналитики, разработчики, да и просто другие тестировщики, дольше вас работающие на проекте. Проанализировав входные параметры, мы получили следующие данные:
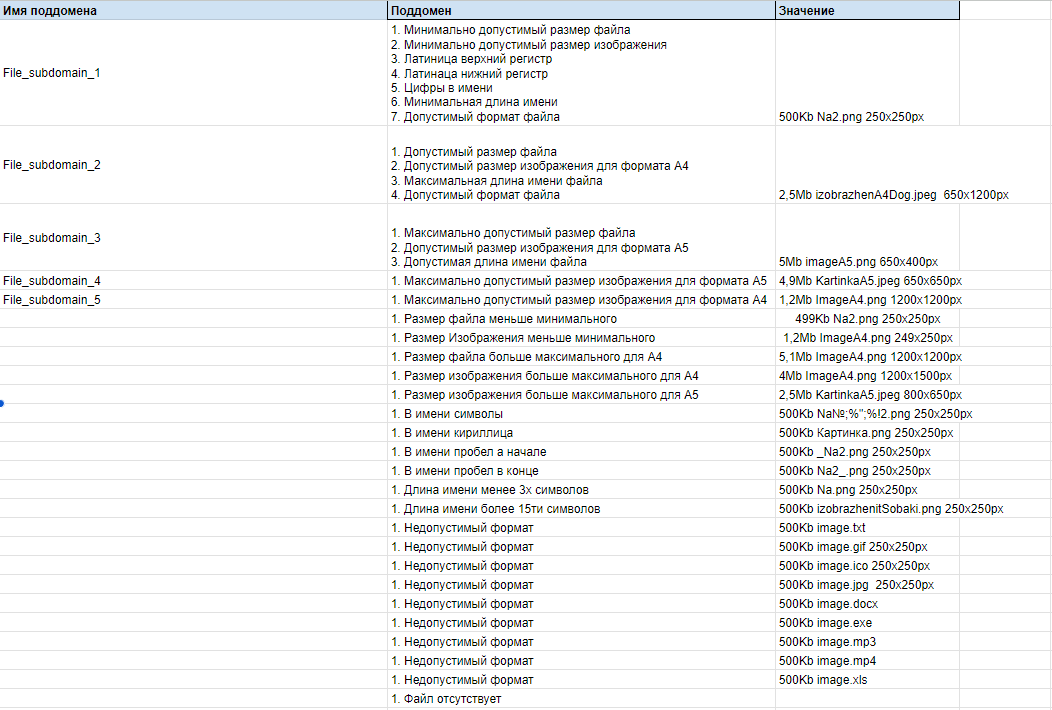
Объединение тестовНе будем забывать, что суть доменного анализа не только в выборе показательных значений параметров, но и в одновременной проверке множества позитивных условий одновременно. Таким образом из набора позитивных значений различных классов эквивалентностей формируем поддомены:
Имена поддоменов заданы для удобства их использования в будущем. Суть доменного тестирования в объединении множества позитивных независимых значений для более эффективного выбора тестовых значений и построения меньшего количества тестов, не теряя при этом в тестовом покрытии. Именно поэтому мы объединяли позитивные значения параметров одного поддомена в одно тестовое значение.
Но следует понимать, что такое объединение увеличивает время локализации ошибки, при обнаружении бага. В таком случае, поможет алгоритм похожий на бинарный поиск:
Тем не менее даже с этим алгоритмом, не стоит комбинировать более восьми значений или параметров. Теперь, по тому же принципу, мы можем объединить позитивные независимые значения разных поддоменов в один позитивный тест, и так для всех представителей всех поддоменов/
В получившейся таблице намерено скрыты негативные тесты, которые объединять мы не имеем право, так как это приводит к непониманию какое именно негативное значение привело к ошибке. Негативные проверки удобнее будет выписать отдельно. Для меня удобнее выписать получившиеся тесты в отдельную таблицу
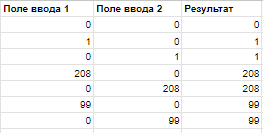
В итоге, мы пришли к 5 позитивным тестам и 51 негативному. На данном примере мы наблюдаем сокращение количества проверяемых значений без потери эффективности тестирования. Анализ выходных параметровВ используемом мной примере, я намерено опускаю анализ выходных параметров. После заполнения необходимых полей, просто жмем на кнопку «Создать блокнот» и представим, что нас перебрасывает на страничку с надписью «Прекрасный блокнот получился! Наш менеджер с вами свяжется!». Анализировать тут особо нечего. Тем не менее это важный этап, на котором вы сможете найти тестовые входящие значения для различных выходных данных. Сами выходные данные мы никак не вводим и не можем повлиять на них напрямую, но зато мы можем повлиять на них путем различных комбинаций значений входных данных. Часто приводят следующий пример — есть программа сложения двух целых чисел:
Если начать анализировать какие значения может принимать выходной параметр, то на ум приходит следующее:
Можно дальше развивать мысль, но давайте просто выделим:
Выделим представителей: 0 , 1, 99, 208 Эти представители будут ожидаемым результатом в тесте и чтобы его добиться, на вход мы выбираем следующие тестовые значения входных данных:
А далее мы уже смотрим, входят ли эти значения в выбранные при анализе входных данных или необходимо обновить. В данном примере мы ограничились рассуждениями о данных, но это не должно ограничивать вас в мышлении. В нашем случае с формой создания блокнота, после клика на кнопку «Создать блокнот«, вполне могло всплывать модальное окно с расчитаной стоимостью собранного блокнота, где мы бы анализировали сумму в зависимости от выбранных значений. Или, к примеру, открывалась бы другая форма с динамическими полями, где в зависимости от выбранных нами значений, предлагались другие возможности кастомизации блокнота и мы бы анализировали зависимости и условия. Важно было передать суть, а дальше вы уже сами. ЗаключениеДоменное тестирование это не совсем отдельная техника тест‑дизайна, а комбинация различных техник: классы эквивалентности, граничные значения, комбинаторика и попарное тестирование (зависимости), тестирование на основе рисков, предугадывание ошибок, таблицы похожие на «таблицы принятия решений» и даже белый ящик (когда вы анализируете значения переменных). Доменный анализ только формализует все перечисленные техники и результат применения будет тем эффективнее, чем лучше вы разбираетесь в тест‑дизайне и чем опытнее вы специалист. Именно поэтому, в комментариях к различным статьям и видосам можно увидеть радостные и удивленные откровения людей по типу: «О, а я так и делаю! Не знал, что это называется доменный анализ!». Ну и на последок, попробуем сформулировать определение своими словами:
На всякий случай, вот вам ссылка не на скрины таблиц а на гугл таблицу. |