Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Азбука ИТНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Python для начинающихНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Инженер по тестированию программного обеспеченияНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
-
Bash: инструменты тестировщикаНачало: 1 октября 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 1 октября 2026
-
Docker: инструменты тестировщикаНачало: 1 октября 2026
-
SQL: Инструменты тестировщикаНачало: 1 октября 2026
-
Git: инструменты тестировщикаНачало: 1 октября 2026
| Стратегии тестирования микросервисов |
| 31.10.2022 00:00 |
|
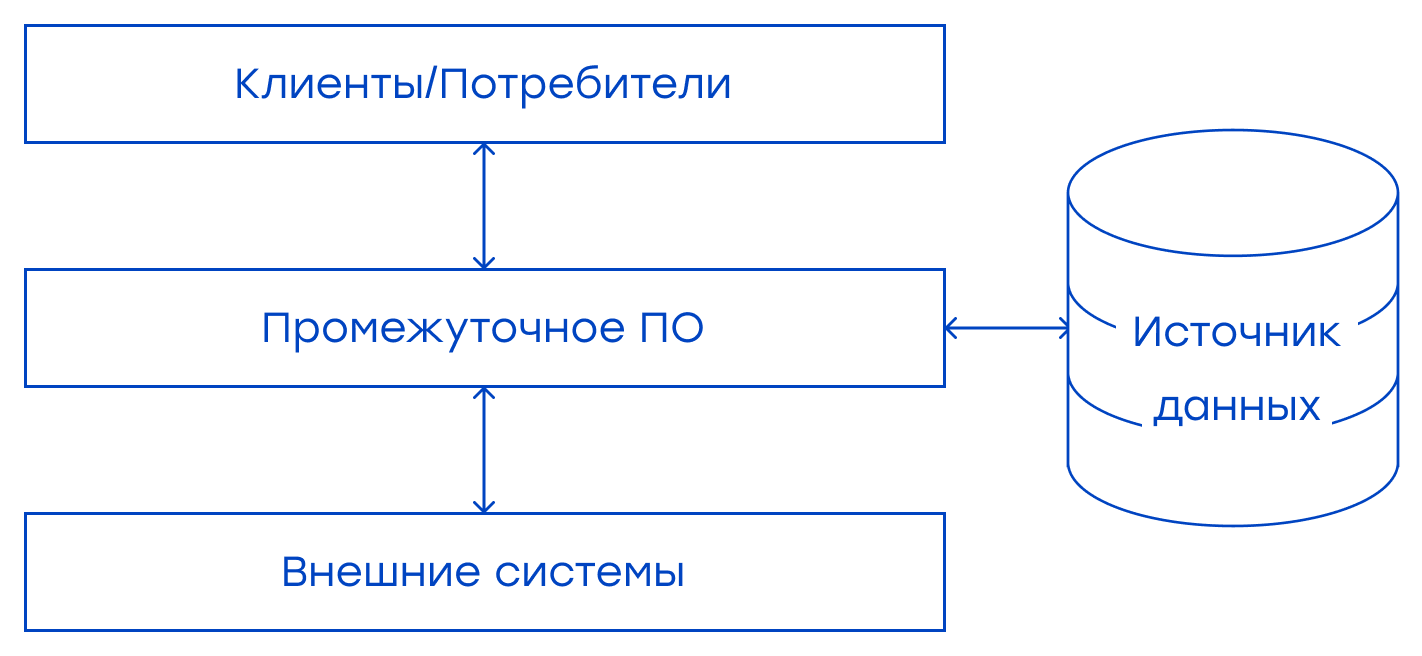
Автор оригинала: Onur Baskirt В оригинальной статье используется большое количество терминов, для которых в русском языке нет устоявшихся аналогов. Поэтому в спорных моментах будут указываться как переведенные термины, так и оригинальные английские понятия. От автора: в этой статье я поделюсь своим опытом тестирования микросервисов. В последние годы команды разработчиков программного обеспечения внедряют архитектуру микросервисов, чтобы иметь возможность разрабатывать, тестировать и деплоить сервисы независимо и быстро. Для эффективного тестирования таких систем необходимо хорошо знать их архитектуру. Давайте начнем с простого архитектурного представления микросервисов. Как правило, у нас есть клиенты/каналы/потребители (UI), такие как Web, мобильный Web, мобильные и десктопные приложения. У нас также могут быть некоторые нижестоящие (downstream) или внешние (external) сервисы, которые выполняют операции по обеспечению лояльности и обработке данных клиентов и даже критически важных бизнес-данных. Эти операции и данные зависят от сферы компании. Между клиентами и внешними системами есть промежуточный слой, который осуществляет связь, перевод и некоторые бизнес-операции.
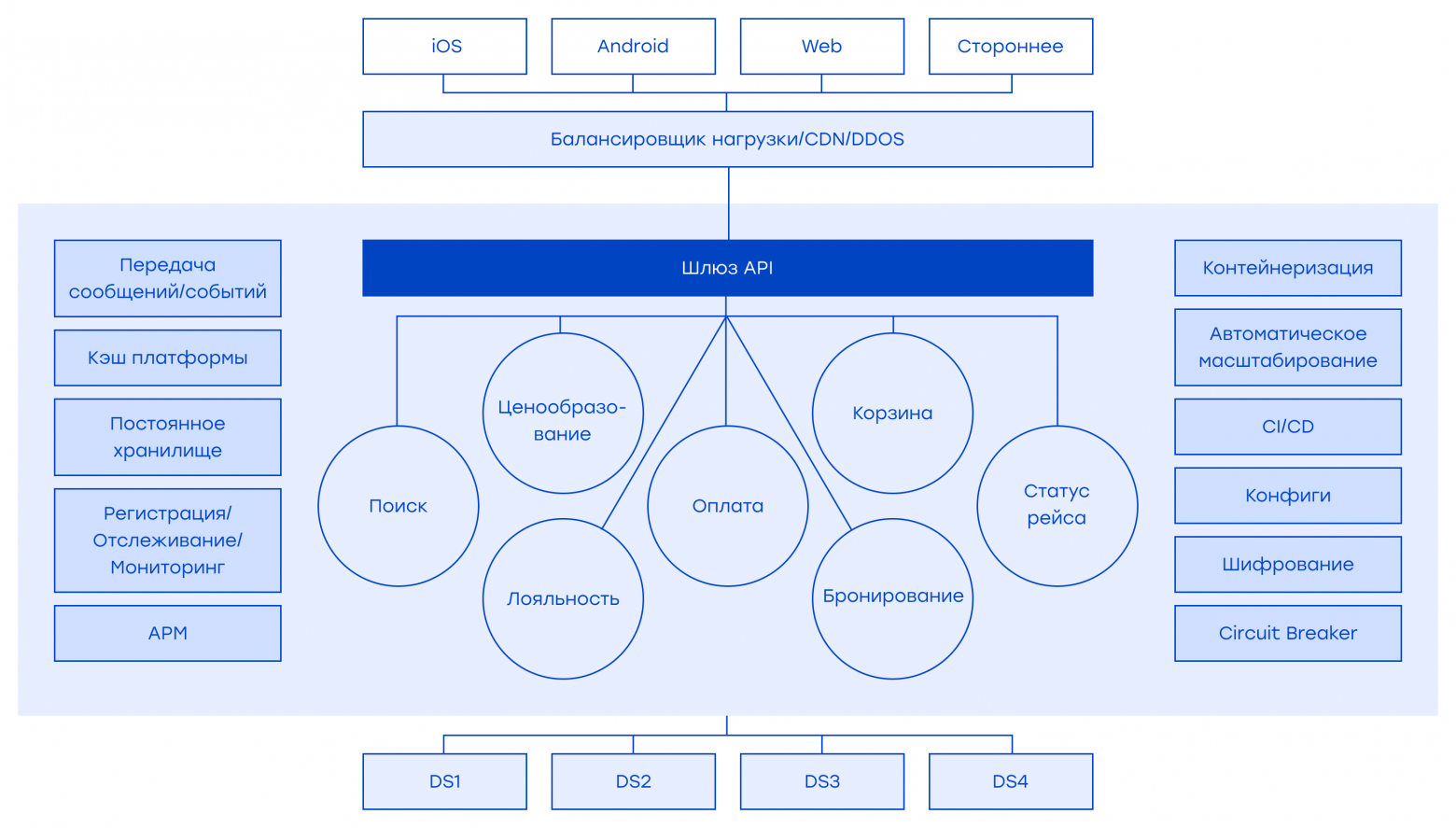
* Здесь, в идеале, у нас есть несколько источников данных для каждого сервиса. В приведенной выше архитектуре у нас может быть несколько сервисов на уровне промежуточного программного обеспечения. Они взаимодействуют друг с другом, клиентами и внешними системами. Чтобы протестировать этот уровень, мы должны знать внутреннюю архитектуру промежуточного ПО. Как правило, она состоит из API-шлюза, микросервисов, хранилищ данных и других элементов, таких как очереди сообщений. Запросы от каналов обычно пересылаются и направляются к сервисам через шлюз. Он должен тщательно тестироваться, поскольку все коммуникации проходят через него. После уровня шлюза у нас есть микросервисы. Некоторые из них взаимодействуют друг с другом и общаются с хранилищами данных, внешними системами и API-шлюзом. В общих чертах мы рассмотрели архитектуру микросервисов. Теперь я хочу сосредоточиться на стратегиях их тестирования. В типичной архитектуре микросервисов нам приходится иметь дело с областями, приведенными на диаграмме ниже. Эти проблемы порождают сложные задачи тестирования, которые необходимо решать.
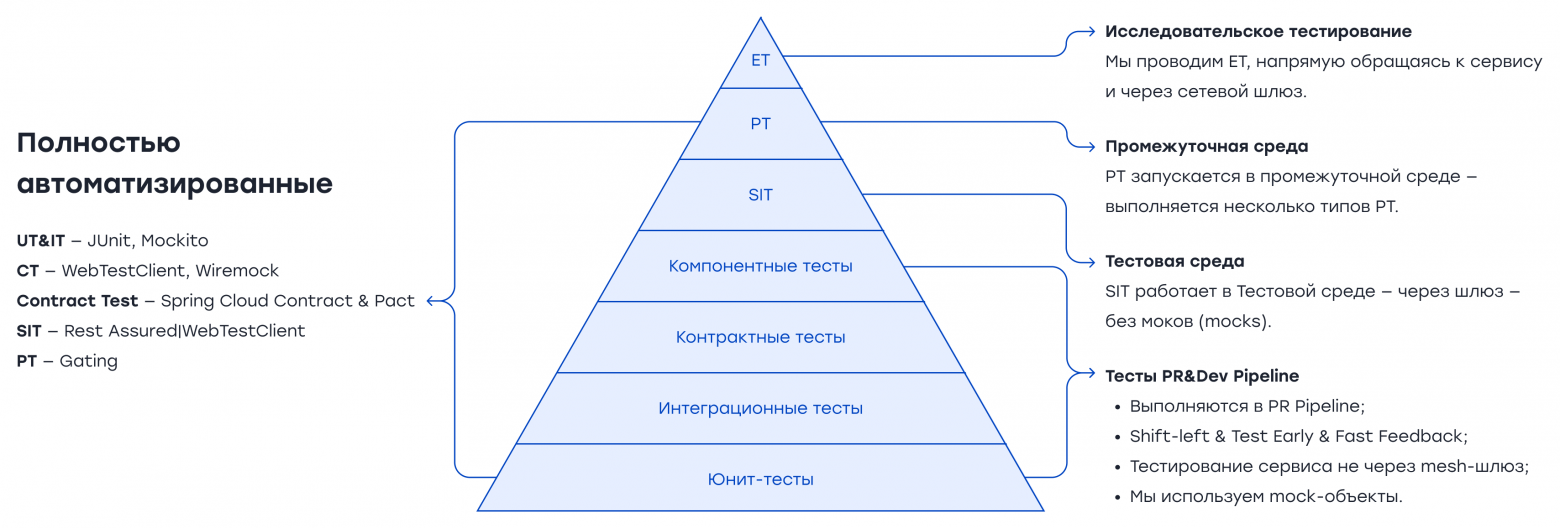
Как видите, в этой архитектуре у нас несколько уровней и компонентов; таким образом, необходимо модифицировать «знаменитую пирамиду тестов», и у нас будет несколько типов тестов. Наряду с обычными видами функционального тестирования, также нужно проводить некоторые другие виды тестирования, такие как нагрузочное тестирование, тестирование на выносливость (endurance testing), стресс-тестирование, spike-тестирование, тестирование балансировки нагрузки, хаотическое тестирование (chaos testing), тестирование репликации данных, тестирование доступности, тестирование безопасности, мутационное тестирование (mutation testing) и т.д. Таким образом, мы повышаем качество микросервисов и всей системы. Если элементы пользовательского интерфейса присутствуют в нашей области применения, нам необходимо провести тестирование, связанное с UI, такое как автоматическое тестирование пользовательского интерфейса (UI automation), визуальное тестирование, тестирование доступности и т.д. Но тесты, связанные с UI, в основном относятся к тестированию на стороне канала/потребителя. Для тестирования микросервисов мы следуем пирамиде тестирования, представленной на диаграмме ниже. У нас больше модульных тестов, чем тестов компонентов, и больше тестов компонентов, чем тестов интеграции системы. Количество интеграционных тестов в некоторых условиях может быть незначительным. Это зависит от сервиса и его интеграций. Кроме того, мы проводим контрактные тесты (contract tests) как можно раньше. Они дают раннюю обратную связь о несоответствиях в контрактах и выполняются быстрее, чем функциональные тесты.
Давайте рассмотрим эти типы тестирования по очереди. С их помощью мы будем эффективно тестировать микросервисы. Тем не менее, прежде чем продолжить, я хотел бы разделить эти типы тестов на Pre-Deployment и Post-Deployment. Pre-Deployment ТестыЭти тесты пишутся внутри проекта сервиса (т.е. под тестовым пакетом сервиса), и для каждого CI/CD-пайплайна (pipeline) мы запускаем их перед деплоем. Примерный вид этих пакетов ниже.
Если у вас есть микросервисы на базе JAVA и вы используете maven в качестве решения для управления зависимостями, вы можете инициировать все эти тесты в CI/CD-пайплайне в указанном ниже порядке с помощью команд maven. Если вы используете инструменты CI/CD, такие как Jenkins, вы можете поместить эти команды mvn в свой groovy-скрипт Jenkins и управлять этапами. Например, вы можете запускать компонентные тесты с помощью приведенной ниже команды mvn: Кроме того, вы можете изменить эти команды в зависимости от ваших потребностей и требований к микросервису. В пайплайне они могут выполняться в следующем порядке. (Вы можете поменять порядок выполнения компонентного и контрактного тестирования, и, по моему мнению, контрактные тесты должны выполняться перед компонентными. Это хорошая практика для Contract First Testing).
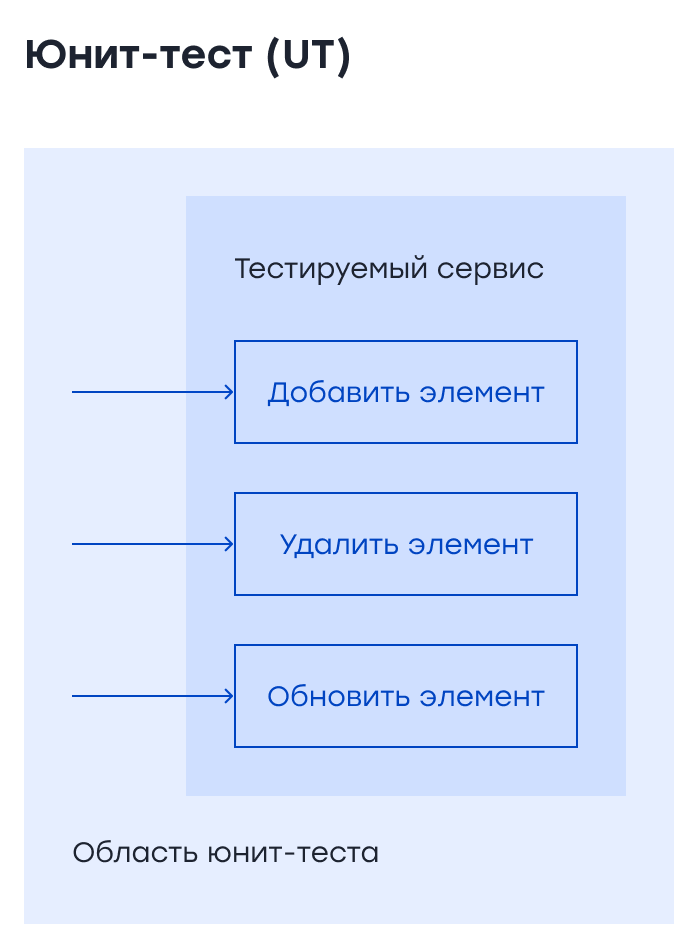
Теперь давайте подробнее разберем эти виды тестирования. Юнит-тестыЮнит-тест фокусируется на одной «единице кода», чтобы изолировать каждую часть программы и проверить правильность отдельных частей. Как правило, разработчики пишут модульные тесты, используя библиотеки модульного тестирования, такие как JUnit, Mockito и т.д. Они напрямую вызывают методы реализации в модульных тестах. И им не нужно запускать сервис локально и обращаться к нему через endpoint.
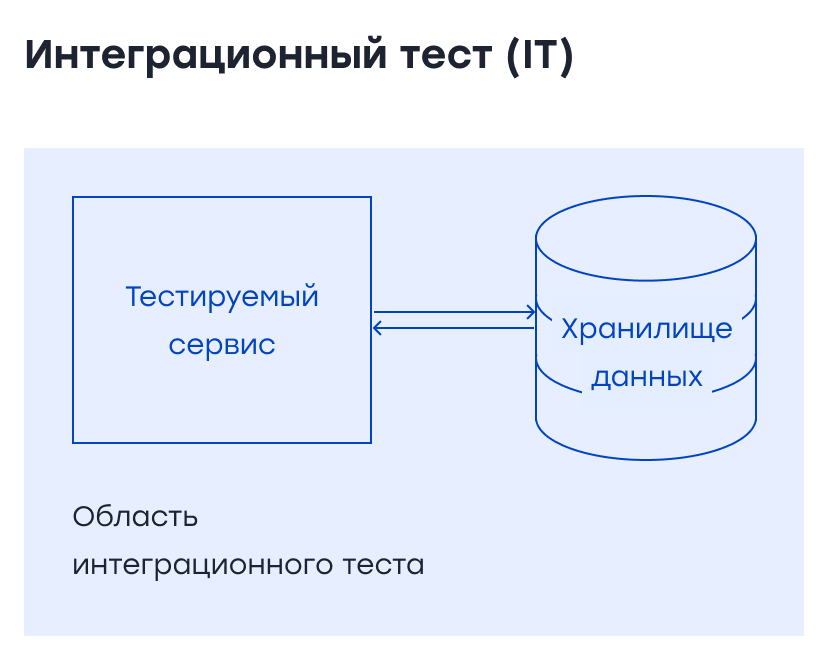
Интеграционные Тесты Они проверяют пути связи и взаимодействие между компонентами для обнаружения дефектов интерфейса. Например, соединения с хранилищем данных. Для интеграционных тестов нам также не нужно запускать службу локально. Мы можем вызвать любой реализованный метод для требуемого теста, но необходимо проверить интеграцию с внешними системами, например, соединение с БД или соединение с другим сервисом.
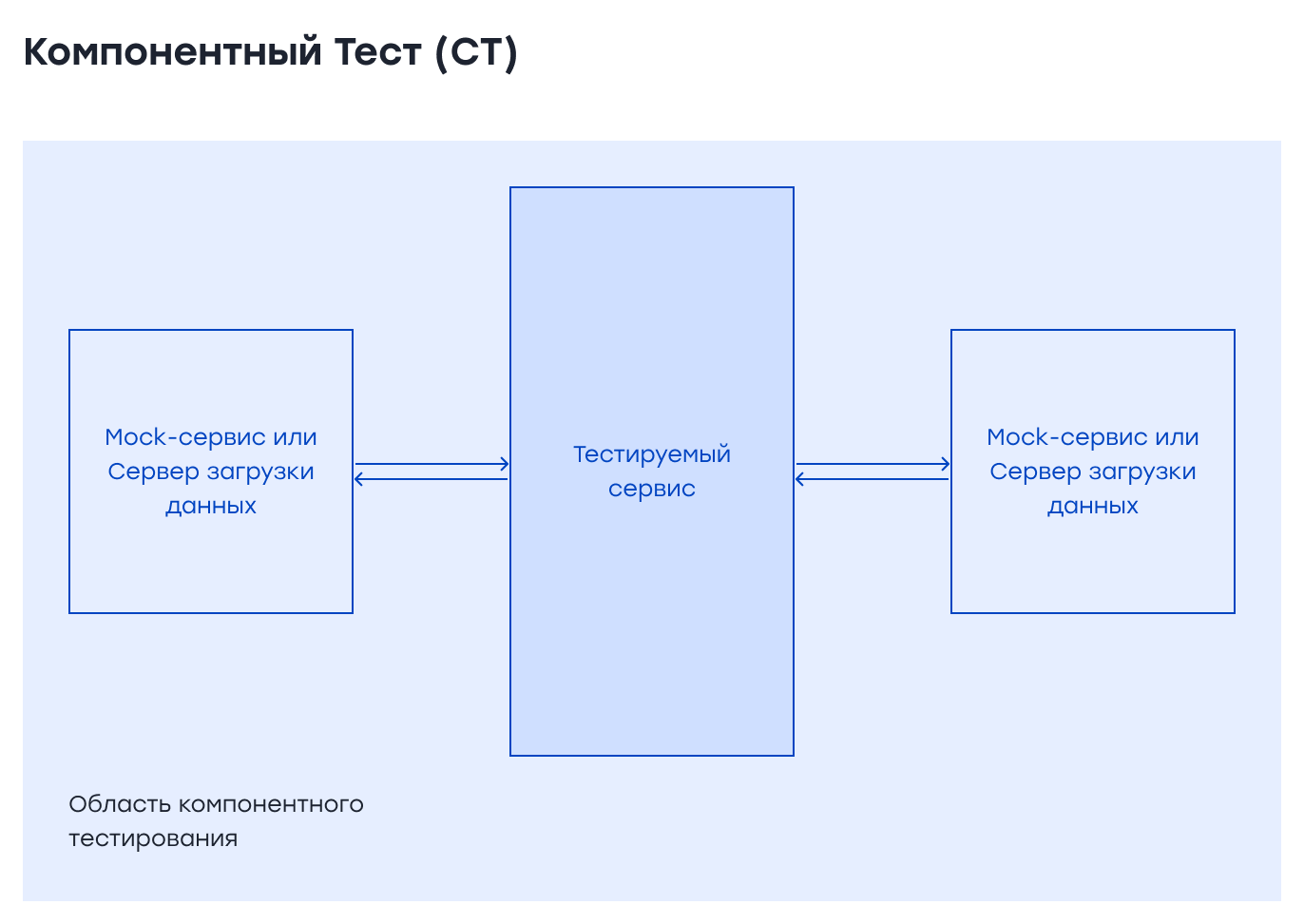
Компонентные тесты В микросервисной архитектуре компонентами являются сами сервисы. Здесь нужно изолировать каждый компонент (сервис) от его аналогов или коллабораторов (collaborators) и писать тесты с определенной степенью детализации. Мы можем использовать такие инструменты, как WireMock, для имитации внешней системы или других сервисов. Также мы можем использовать in-memory базы данных для имитации БД, но это создаст немного больше сложностей. В идеале нужно сымитировать все внешние зависимости и тестировать сервис в изоляции. В компонентных тестах нужно запустить сервис локально и автоматически (если у вас есть проект Reactive SpringBoot WebFlux, вы можете использовать WebTestClient и аннотацию @AutoConfigureWebTestClient, чтобы сделать это), и когда сервис запущен, обратиться к его конечной точке, чтобы проверить наши функциональные требования. На этом уровне необходимо покрыть большинство сценариев функционального тестирования, поскольку компонентные тесты выполняются до деплоя, и если в нашем сервисе существует функциональная проблема, мы можем обнаружить ее до него. Это соответствует подходу shift-left и раннему тестированию.
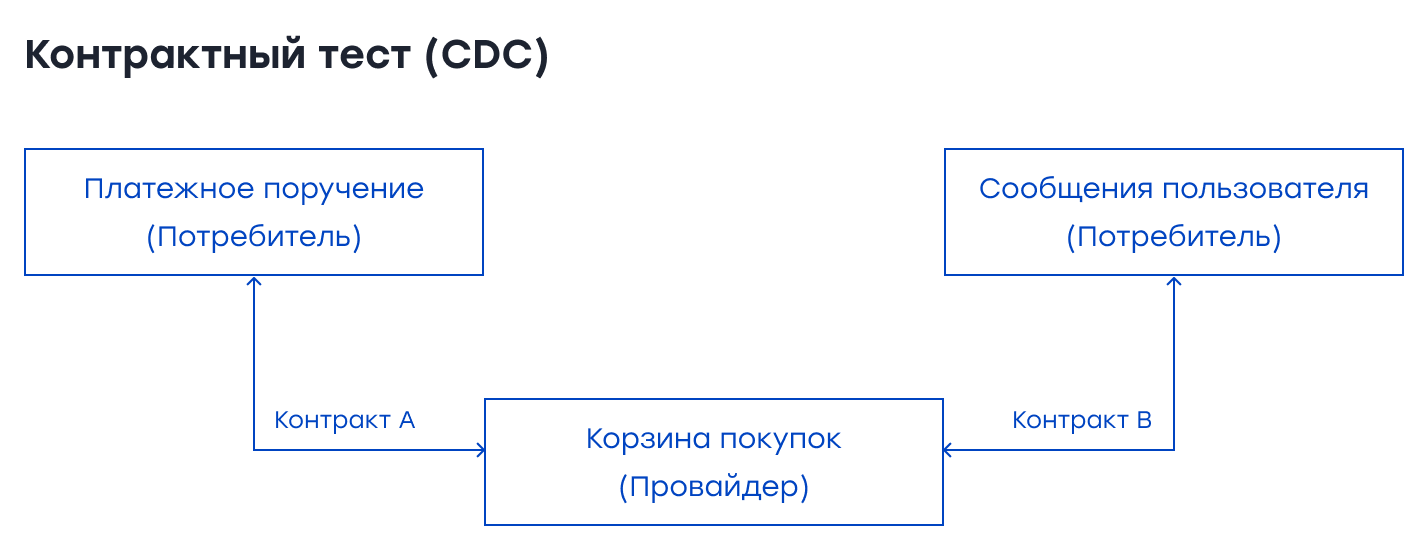
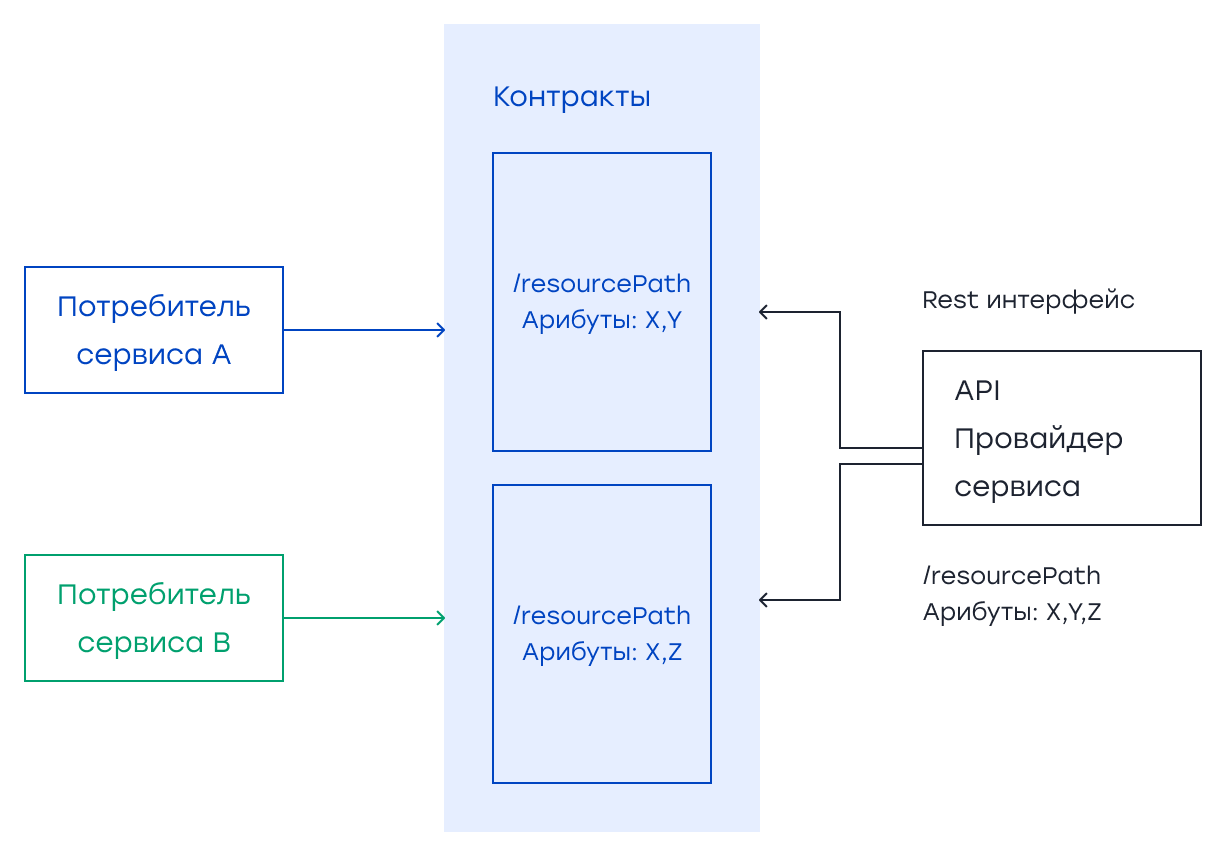
Контрактные тесты (ориентированные на потребителя) Контракты – это серия соглашений между провайдером сервиса и потребителем. Провайдеры могут тестировать свои услуги по этим контрактам, чтобы убедиться, что они не нарушают никаких соглашений с потребителей, тем самым помогая сохранить обратную совместимость услуг.
Если вы используете Spring Boot, то можно использовать Spring Cloud Contract, или вы можете использовать PACT для тестирования контрактов. Pact был написан для Ruby, но сейчас он доступен для многих языков, например, JavaScript, Python и Java. Перед началом контрактных тестов должно быть достигнуто соглашение между потребителями/каналами и провайдерами/посредниками/внешними системами. Затем нужно использовать определенные контракты для написания контрактных тестов. Идея тестирования контрактов на основе потребительского подхода (Consumer-Driven Contract Testing или CDC) заключается в том, что потребительская служба запускает набор интеграционных тестов на API службы провайдера. Эти тесты генерируют файл под названием контракт, и служба провайдера может использовать его для проверки ожиданий по контракту между потребителем и провайдером.
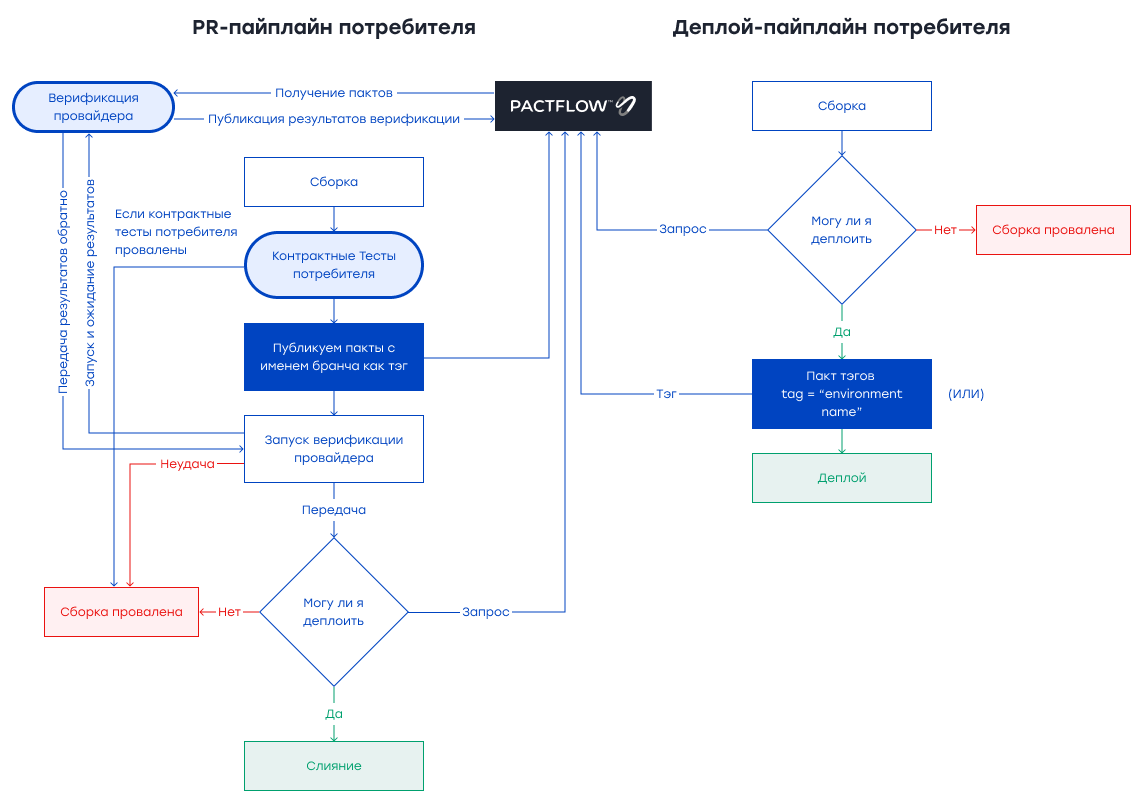
Прежде чем приступить к контрактным тестам, необходимо заключить соглашение между потребителями и поставщиками. Затем нужно начать использовать определенные контракты для написания тестов. Ниже приведен обзор интеграции тестов потребительских контрактов в PR-пайплайн и того, как деплой-пайплайн (deploy paipline) работает с интеграцией пакта (pact).
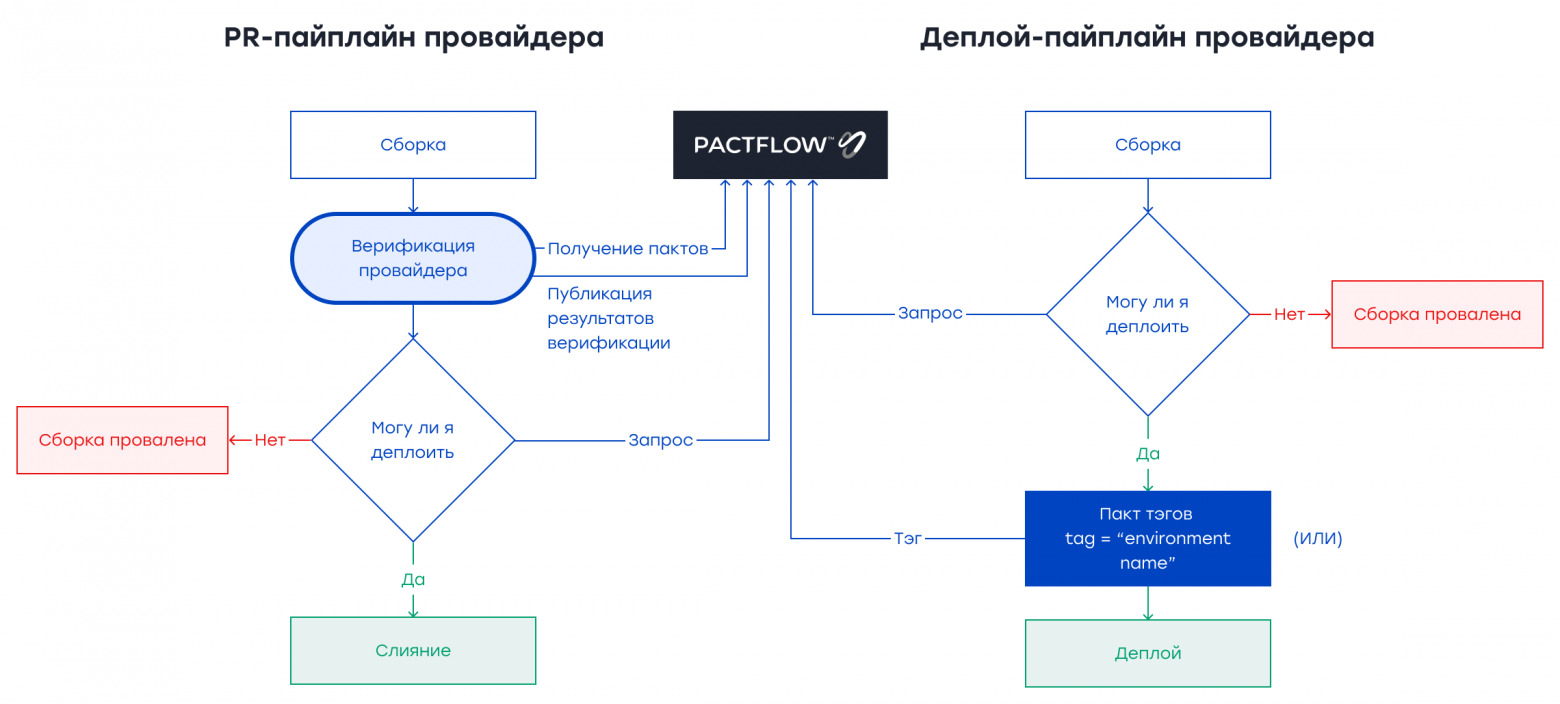
Ниже представлена интеграция проверки поставщиков в PR-пайплайн.
Как показано ниже, в PR-пайплайне выполняются контрактные тесты потребителя и провайдера.
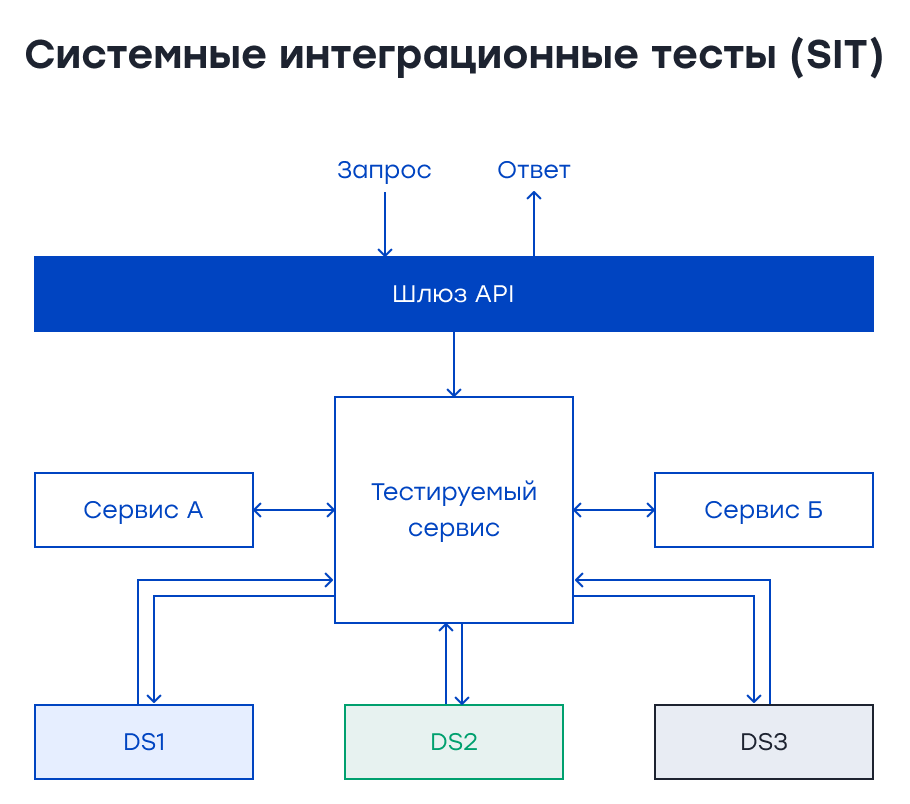
Post-Deployment тесты Системные интеграционные тесты (E2E Tests)Системные интеграционные тесты (System Integration Tests или SIT) гарантируют, что мы создаем правильную систему и поведение приложения в интегрированной среде. Мы тестируем важные пользовательские потоки от начала до конца, чтобы убедиться, что их поведение соответствует ожиданиям. Для системных интеграционных тестов не следует использовать моки (mocks) или стабы (stubs). Все компоненты системы должны быть интегрированы. Таким образом, мы можем убедиться, что интеграция на уровне системы работает так, как ожидается. Эти тесты занимают больше времени, чем другие. Поэтому необходимо протестировать критические бизнес-потоки на уровне SIT.
Если у вас есть технический стек на базе JAVA, вы можете использовать Rest-assured для написания SIT-тестов. Для этих тестов мы следуем приведенной ниже процедуре.
После изучения и обнаружения мы создаем наши тестовые сценарии, а затем приступаем к реализации SIT-тестов. Также можно использовать cucumber или любую другую библиотеку BDD, чтобы добавить привкус Gherkin вашим тестам или создать свои классы шагов, чтобы скрыть детали внутри методов классов шагов.
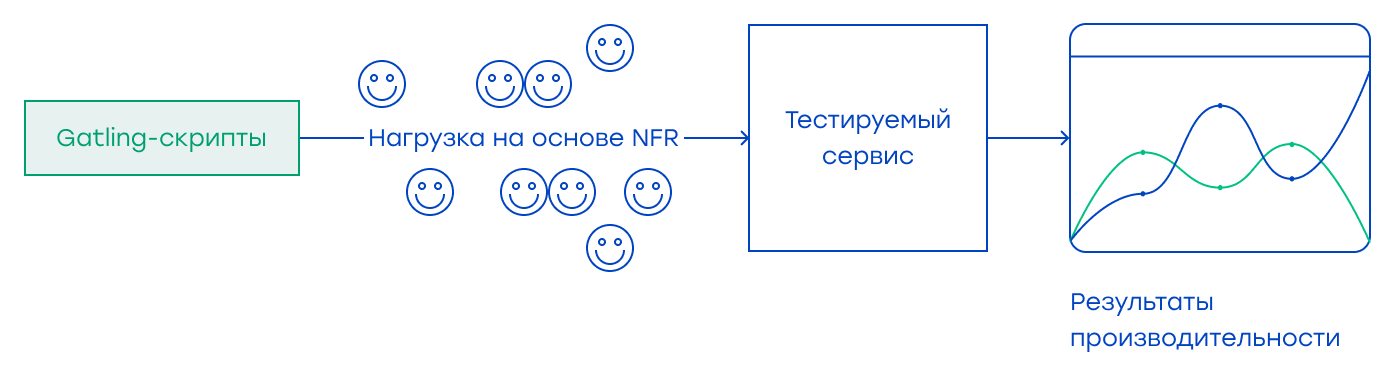
Тесты производительностиПосле деплоя в тестовой или stage-среде мы начинаем проводить тестирование производительности на уровне сервиса. В микросервисах мы можем проводить тестирование производительности несколькими способами. Во-первых, имитируя все внешние зависимости и обращаясь непосредственно к эндпоинту, чтобы измерить автономную производительность. Для этих тестов мы можем использовать несколько технологий или инструментов, таких как Gatling, JMeter, Locust, Taurus и др. Если у вас стек на базе JAVA и вы выбрали Gatling в качестве инструмента производительности, я предлагаю создать проект на базе maven и интегрировать тесты в ваш пайплайн. Также мы можем проверить поведение сервера с помощью некоторых APM-инструментов, таких как NewRelic, DynaTrace, AppDynamics и др. Эти инструменты дают дополнительную информацию о производительности сервиса и системы, и их приятно использовать вместе с результатами тестов производительности.
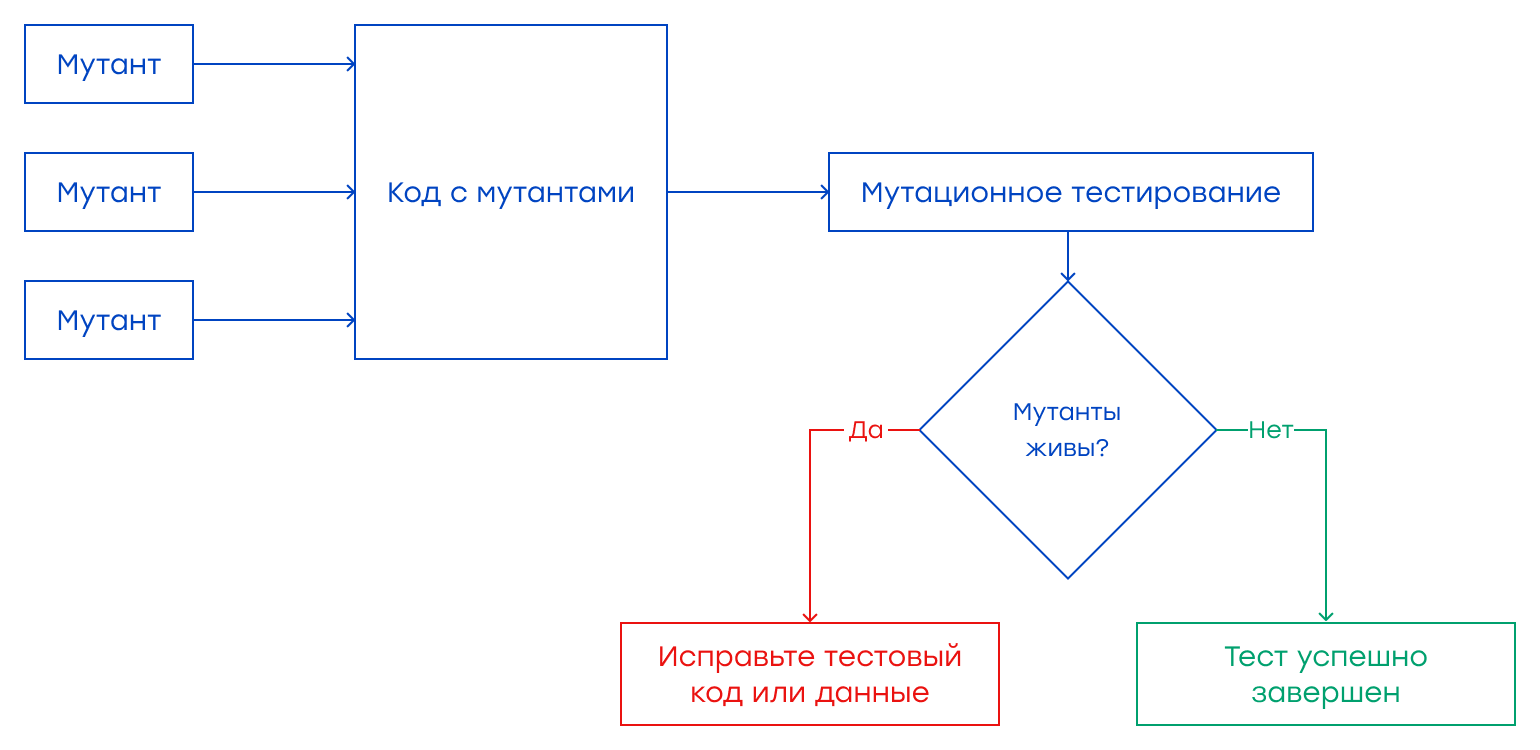
Также мы тестируем производительность при помощи API-шлюза. В этот раз добавляем факторы шлюза в наши тесты производительности. В реальной жизни все запросы канала проходят через шлюз, прежде чем попасть к сервисам. Вот почему также важно проводить тестирование производительности через шлюз. Здесь мы можем не использовать моки или стабы. Тем не менее, если мы коммуницируем с внешними системами, мы должны очень тщательно подбирать данные для тестирования производительности, прежде чем его начинать. Если внешние системы работают медленно, это повлияет на результаты тестирования производительности. Используя APM-инструменты, мы должны определить проблемные области. Если у нас гибридная серверная архитектура, то есть некоторые серверы локальные (on-premise), а некоторые – в облаке (AWS, Azure и т.д.), нужно тестировать производительность для каждого сервера. Таким образом, мы будем знать о производительности локальных и облачных серверов. Кроме того, в гибридной архитектуре репликация данных происходит между локальными и облачными серверами. Поэтому нам необходимо провести тесты XDCR (Cross Data Center Replication) для определения максимальной производительности репликации данных. Например, мы создаем корзину покупок на локальном сервере, просматриваем ее на облачном сервере, обновляем ее на локальном сервере, удаляем продукт в облаке и снова просматриваем его на локальном сервере. Мы можем сгенерировать множество сценариев, и все эти сценарии должны выполняться безупречно с заданными интервалами паузы между каждой операцией. Также необходимо провести дополнительные тесты производительности. Их может не быть в пайплайне, но их нужно учитывать для оценки производительности и стабильности системы. Мы проводим spike-тестирование, применяя внезапные пиковые нагрузки, и проверяем функциональность автомасштабирования в этих тестах. Мы добавляем задания для тестирования на выносливость (endurance test) в нашу CI/CD-платформу для параметризации времени выполнения теста и запускаем тесты на выносливость в течение длительного периода для проверки поведения и стабильности сервиса в течение длительного периода. Также при тестировании производительности можно проверить факторы балансировки нагрузки. В этих тестах мы проходим через балансировщик нагрузки, API-шлюз, а затем сервисы. Тесты и сканирование безопасности и уязвимостиВ пайплайн сервиса после деплоя следует добавить автоматическое сканирование уязвимостей и безопасности с помощью таких инструментов, как Zed Attack Proxy, Netsparker и т.д. В каждом новом PR мы можем сканировать наш сервис с помощью правил безопасности и уязвимостей OWASP. Если вы используете ZAP, можно обратиться сюда и сюда для сканирования ваших API. Хаотическое тестированиеХаотическое тестирование проверяет отказоустойчивость и целостность системы путем проактивного моделирования сбоев. Это имитация кризиса для системы и ее реакция на него. Таким образом, мы знаем поведение системы при незапланированных и случайных сбоях. Эти сбои могут быть техническими, природными или стихийными бедствиями, например, землетрясение, влияющее на серверы. Мы можем использовать инструменты хаотического тестирования, такие как «обезьянье тестирование» (chaos monkey), который случайным образом завершает работу экземпляров виртуальных машин и контейнеров, запущенных в вашей производственной среде. Таким образом, мы можем проверить отказоустойчивость системы. Мутационное тестированиеМутационное тестирование – это еще одна техника, при которой мы вводим мутантов в код и проверяем, жив он или нет после выполнения теста. Если эти мутанты погибают, это хороший знак, что наши тесты обнаруживают сбои; если нет, следует улучшить тестовый код или тестовые данные. Мутационное тестирование обеспечивает качество наших тестов, а не самого кода сервиса, и его можно проводить как можно раньше в PR-пайплайнах.
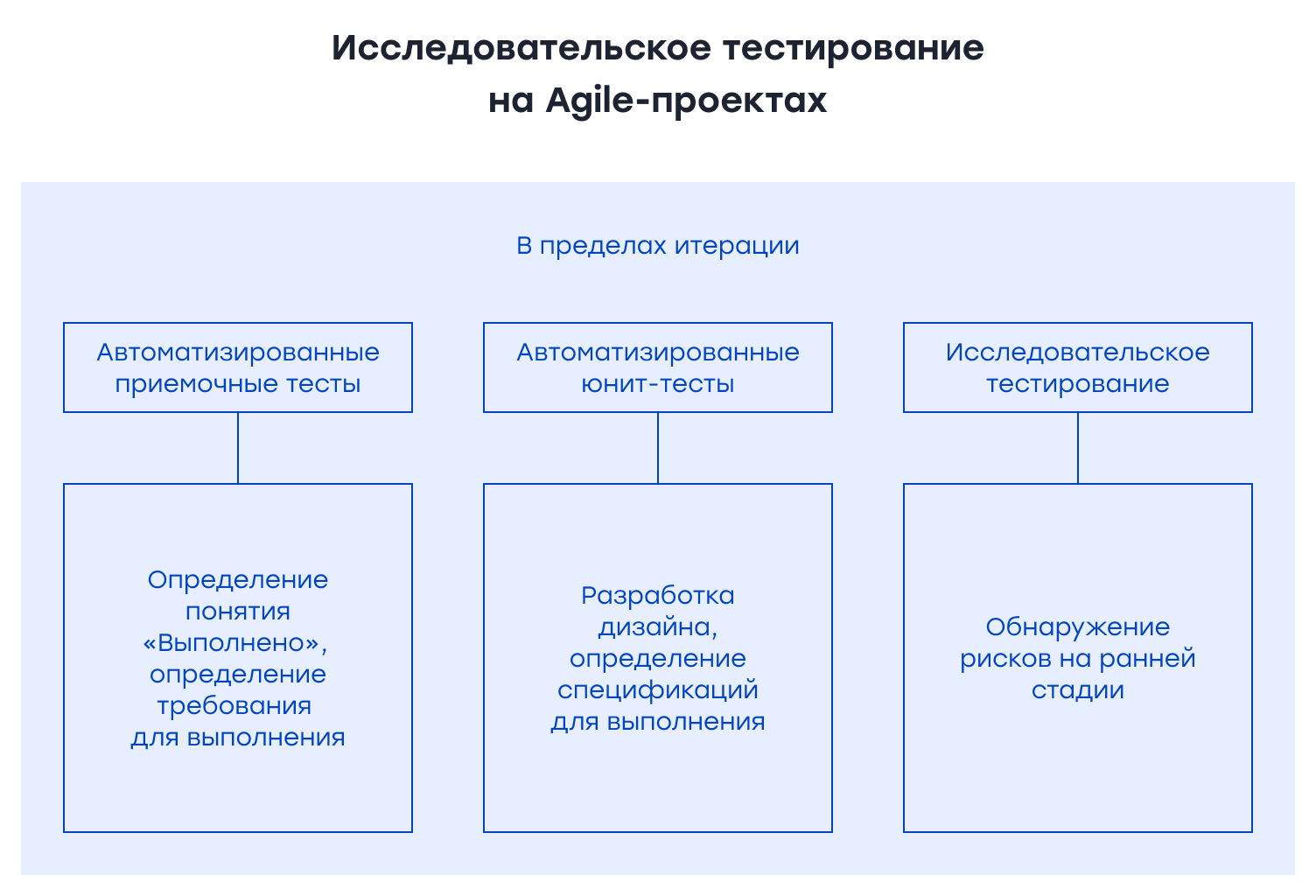
Исследовательское тестированиеИсследовательское тестирование (Exploratory Testing) – это тестирование методом свободного поиска, используемое для обнаружения неизвестных проблем во время и после процесса разработки программного обеспечения. Проводить исследовательское тестирование нужно на протяжении всего жизненного цикла тестирования. Обычно мы начинаем его сразу после фазы анализа требований. Таким образом, мы можем обнаружить риски и проблемы раньше, что также помогает автоматизированному тестированию. Для исследовательского тестирования API мы используем инструменты postman или insomnia. Для получения подробной информации об исследовательском тестировании вы можете ознакомиться с этой статьей.
Подход на основе тестовых данных Одной из самых больших проблем в тестировании и автоматизированных тестах являются тестовые данные. Предлагаю следующие рекомендации:
Подход к тестированию до выпуска релизаПеред выпуском наших сервисов для клиентов мы проводим предварительную проверку. Команда должна провести эту проверку, чтобы охватить новые изменения и критические сценарии перед запуском в эксплуатацию. Если пайплайн сервиса зеленый, тесты SIT пройдены, тесты PT пройдены, UAT одобрен, а финальные проверки предэксплуатационной (pre-production) среды пройдены, мы готовы перейти к деплою на проде. Когда деплой в эксплуатационной среде выполнен, и новая версия сервиса работает в продакшене, мы должны отслеживать это с помощью инструментов APM и протоколирования. |