Что пишут в блогах
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Python для начинающихНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Азбука ИТНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
| Цена регресса. Как мы организовали инфраструктуру для Е2Е-тестов |
| 30.09.2021 00:00 |
|
Автор: Боков Максим Мы, команда автоматизации Страхового Дома ВСК, подготовили небольшой рассказ о нашей инфраструктуре. Эта статья может быть входной точкой для специалистов, желающих внедрить автотестирование у себя в компании. Расскажем, какие системы, паттерны и фреймворки можно использовать, а также как интегрировать это в релизный цикл. Материал подойдёт как юным автоматизаторам, так и тем, кто желает поближе познакомиться с темой. Большое внимание уделим не только абстрактным вопросам, но и организации кода проекта. Добро пожаловать под кат.
Изложение поделено на две логические части. В первой опишем инфраструктуру и процесс, а во второй рассмотрим некоторые детали написания кода. Но для начала немного обрисуем рабочую среду:
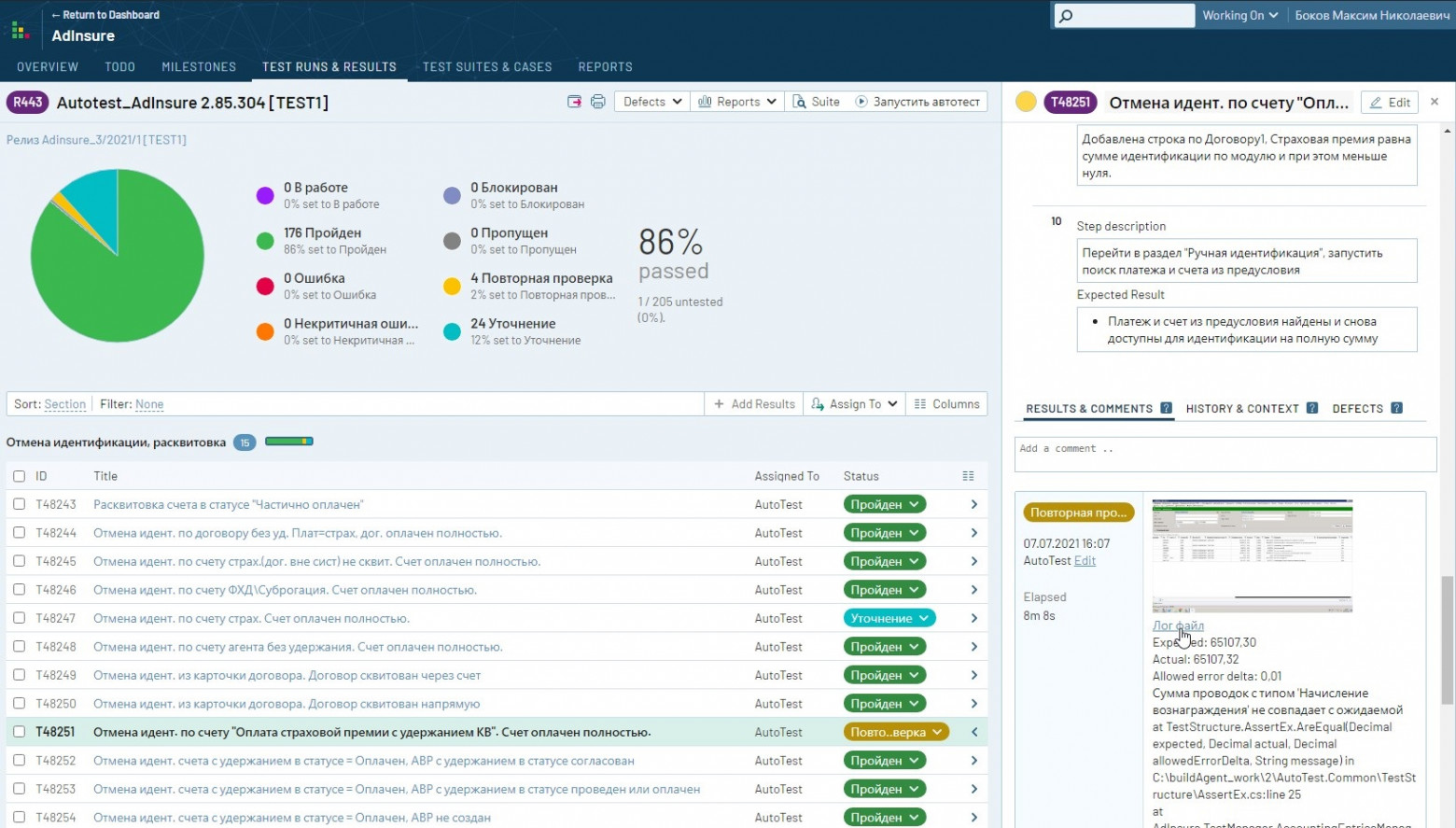
Кому и зачем нужна команда автоматизаторовОчевидно, что компании стремятся к уменьшению релизного цикла разрабатываемого ПО. Для достижения этой цели команды разработчиков прибегают к различным гибким методологиям. Однако всё равно отделу контроля качества приходится раз за разом выполнять регрессионное тестирование, занимающее от нескольких дней до нескольких недель. Именно поэтому существуют такие команды, как наша, стремящиеся сократить время регресса за счёт автоматизации. Т. к. команда ручного тестирования является нашим заказчиком, мы постарались максимально прозрачно интегрироваться в их процесс. Страховой Дом ВСК использует TestRail как систему управления тестированием. Выполнение регрессионного тестирования сводится к следующим простым этапам:
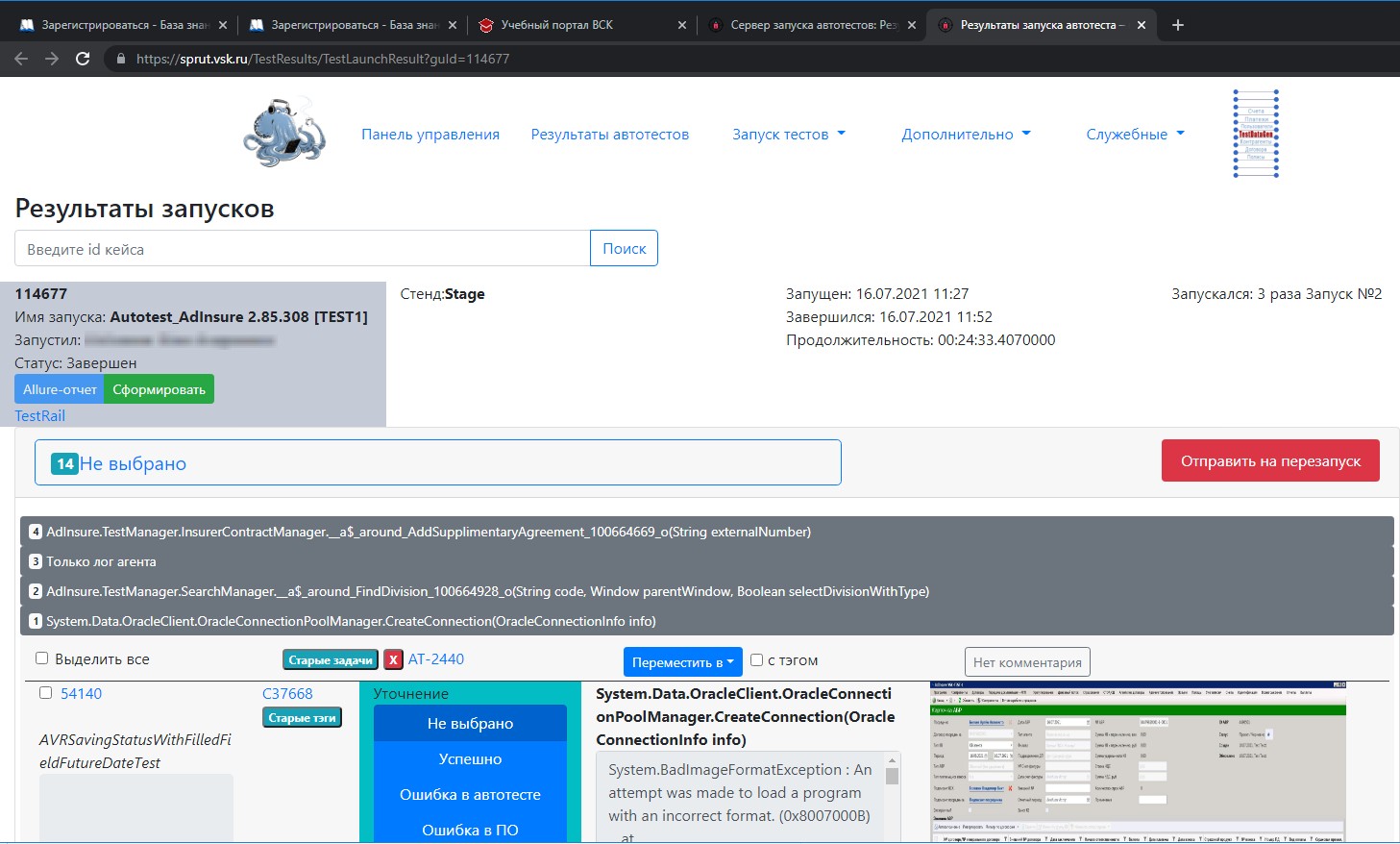
Инфраструктура и автотестовый дашборд Как уже упоминалось, процессом запуска автотестов руководит отдельная система. Многие компании предпочитают разрабатывать подобную инфраструктуру самостоятельно, чтобы лучше контролировать процесс. Мы не исключение, поэтому знакомьтесь со Sprut. В первую очередь на Sprut возложена работа с очередью запускаемых тестов, мониторингом и управлением процессами. (За деплой отвечает Azure DevOps, а за виртуалки в докере — Selenoid. В будущем планируем внедрить автодеплой при запуске.) Также Sprut выполняет постобработку результатов прогонов: классификацию и кластеризацию. Из-за того, что тестам свойственно падать пачками, Sprut предоставляет прогон тестплана в сгруппированном по ошибкам виде. Автотестеру проще работать с такой системой, чем с TestRail.
Для каждого упавшего теста можно посмотреть логи, скриншоты и другие артефакты. Если тест упал из-за Assert, система относит инцидент к категории «Ошибка ПО» (т. е. не прошла целевая проверка). В силу природы самих Е2Е-тестов падения, которые случились не в секции Assert, попадают в отдельную категорию, где дежурный разработчик тестов уже проводит анализ, т. к. нельзя однозначно определить, это «Ошибка в автотесте» или «Ошибка ПО». В ходе анализа Sprut позволяет сразу создать тикет в Jira и назначить ответственного. После исправления автотестов система позволяет выполнить перезапуск не прошедших ранее кейсов, а результат аккумулируется с предыдущим раном в тестовом плане. Так за несколько итераций мы можем разобрать все проблемы. О сложности Е2Е-тестовПроект автотестов — это такой же программный продукт, код которого нужно писать и поддерживать. И этот код следовало бы тоже тестировать, но тогда мы войдём в бесконечную рекурсию (тесты, которые тестируют тесты, которые тестируют...). Е2Е-тесты по своей сути обеспечивают самый высокий уровень защиты от багов, но являются очень хрупкими и нестабильными. Поэтому мы подошли к архитектуре со всей ответственностью и разработали структуру, о которой дальше пойдёт речь.
Наш способ организации проекта позволяет бороться с усложнением системы, возникающим из-за увеличения числа автоматизированных тестов. Для наглядности предлагаю разработать автотест для следующего упрощённого кейса:
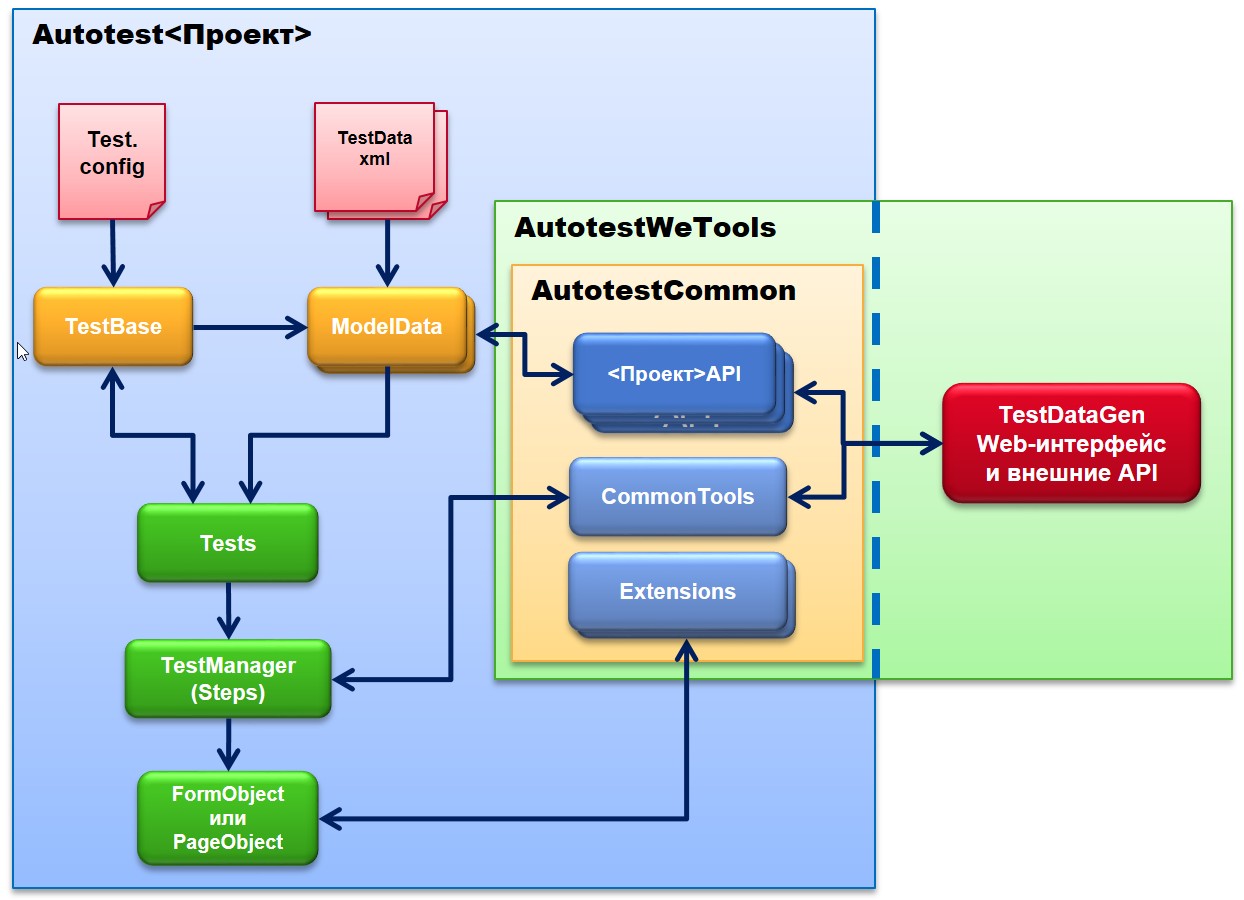
Ожидаемый результат: появляется сообщение с предупреждением «Автомобиль не существует в базе». Модель данныхВ нашей системе модель содержит всю необходимую для выполнения теста информацию. Мы выделяем два основных типа моделей: ● Общие модели Это классы, описывающие бизнес-объекты тестируемого приложения и принципы генерации их полей. Например: ФЛ (физическое лицо), Паспорт, Договор. ● Модели менеджера Являются композицией общих моделей и включают некоторую служебную информацию теста и специфичные данные для конкретного тестового метода (например, TestID). Создадим для нашего примера общую модель: Обратите внимание, что значение свойства по умолчанию генерируется случайным образом. Такой подход позволяет нам избегать коллизий и тестировать систему с широким диапазоном входных данных. А регистрационный номер не является обязательным и, раз не задан, не станет подставляться в поле поиска по умолчанию. Модель менеджера будет включать в себя только одно свойство: ModelBase содержит определение служебных полей: TestID, Login, Password. Но прежде чем мы перейдём к написанию теста — ещё пара слов о модели. Для каждого тестового метода мы подготавливаем отдельный XML-файл, который будет десериализоваться в конкретный объект, переопределяя интересующие свойства. Так, для нашего теста создадим файл, где будет переопределённый ID теста: В большинстве случаев нас будут устраивать значения свойств по умолчанию. Но если тесты похожи, мы можем переиспользовать тестовый метод путём вставки в XML дополнительных блоков. В XML мы указываем только специфичные для данного теста свойства. Этот трюк во многом облегчает поддержку: для изменения входных данных не требуется знаний языка программирования и можно безболезненно расширять модели CarFindData и CarData. Например, в следующем примере, указав дополнительные наборы данных в той же XML, мы получили новые тесты, ничего не меняя в коде, и можем запускать их отдельно при необходимости. Тестирование UIМы выделяем три основных типа объектов:
Теперь напишем код теста для нашего примера: Мы разбиваем тестовый метод на два этапа. Этап подготовки данных читает XML-файл, который мы создали ранее, и возвращает список десериализованных моделей. Метод NotFoundWarningWhenNotFoundCarTest будет запущен для каждой модели из списка, что позволяет автоматизировать сразу несколько похожих тест-кейсов, используя один и тот же код. Для описания последовательности шагов мы пользуемся Fluent-синтаксисом, что в совокупности с IntelliSense делает написание кода таким же лёгким, как и его чтение. Main.Manager является точкой входа для работы с любыми другими менеджерами. Код в нём может содержать действия корректной инициализации и будет специфичен для каждого отдельного приложения. Его мы рассматривать не будем и перейдём сразу к созданию менеджера страницы поиска автомобиля: Менеджеры должны отделять действия от проверок, предоставляя для этого различные методы. Метод принимает модель данных и сам определяет, какие свойства ему нужны. Допускается, что менеджер может изменять модель для того, чтобы передать какую-либо информацию другой части теста. Реализация CarFindPage зависит от конкретного типа приложения. В наших проектах мы используем два богатых фреймворка: Selenium (для работы с браузером) и FlaUI (для тестирования WinForm). Более подробно о них вы можете узнать в других статьях на Хабре. Итак, мы рассмотрели в общем виде структуру наших проектов. Хороший автотест должен содержать простой, понятный и стабильный код. А каждый метод — писаться с мыслью о повторном использовании в будущем. Такая архитектура позволяет успешно масштабировать количество тестов за счёт переиспользования кода. Чтобы с ростом проекта код оставался таким же чистым, нужно не забывать о таких практиках, как:
Пишем логи правильноЕщё одна важнейшая характеристика автотеста — его максимальная прозрачность и понятность. Т. к. с результатами прогона теста работают не только его создатели, требуется, чтобы ошибка была понятна и тестировщику, и разработчику без дополнительных пояснений. Это экономит гигантское количество времени для всей компании. Добиваемся данной цели следующими способами:
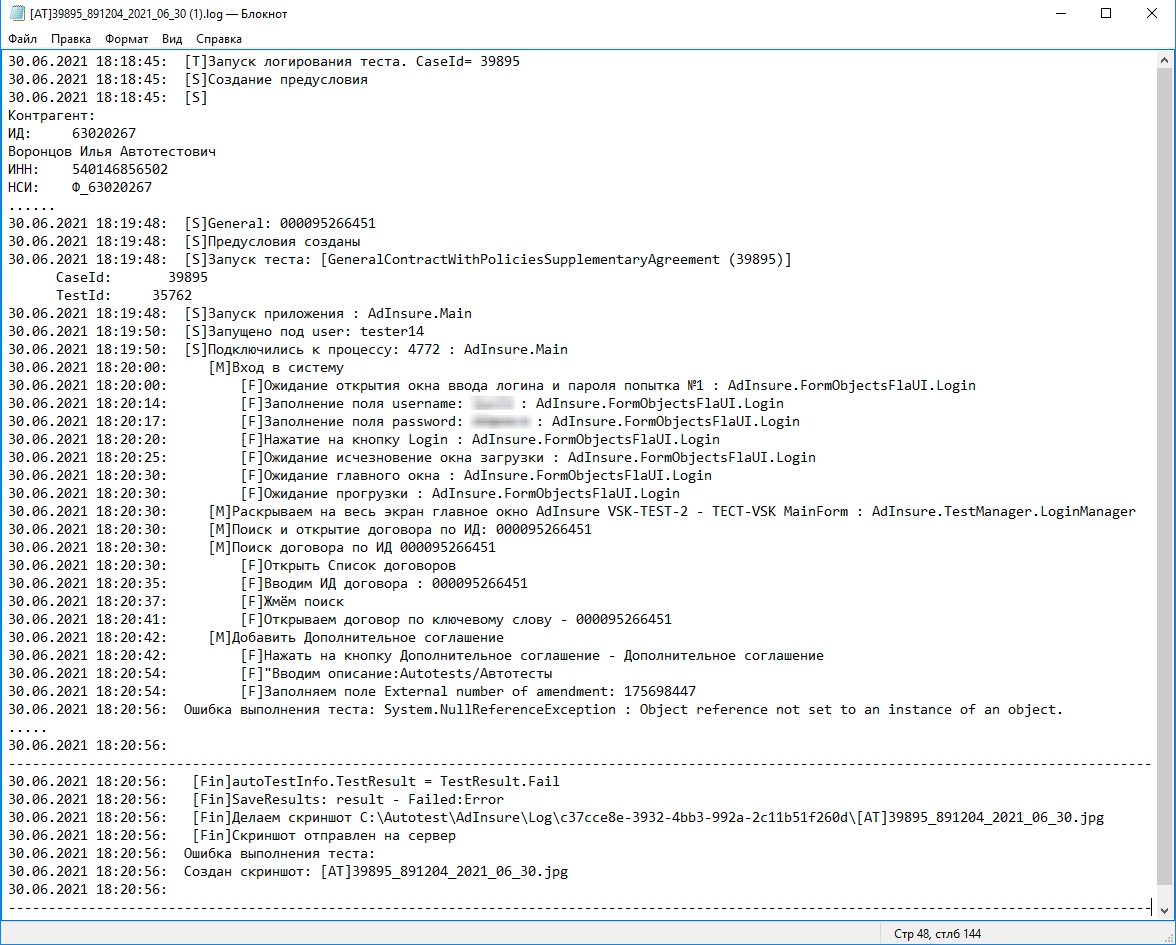
Первые два пункта более-менее очевидны, а про третий мы бы хотели рассказать поподробнее. Вот так выглядит наш файл с логом:
Такой лог очень легко прочесть. Как можно заметить, в него попадают шаги вышеупомянутых менеджеров и действия с FormObject. Чтобы наглядно продемонстрировать, как в коде выглядит объявление этих шагов, модифицируем наш предыдущий пример: Нам всего лишь пришлось добавить один атрибут и обычные комментарии к методам. Атрибут TraceAspect сообщает, что для данного класса нужно сгенерировать код, отвечающий за логирование шагов. Такой трюк возможен с помощью NuGet-пакета Aspect Injector. А сам текст шага будет взят из XML-документации, которую можно сгенерировать на этапе билда. Аналогичным способом реализуются и другие часто повторяющиеся операции. Например, есть аспект для проверки передаваемых аргументов на null в методы страницы. Для добавления этого функционала к любому PageObject необходимо прописать аннотацию [NotNullArgumentAspect] к этому классу. Алгоритм работы следующий:
Подводим итогиСуть автоматизации, как и разработки любого продукта, — сделать систему, позволяющую упростить и ускорить работу пользователей. Мы считаем, что успешно справились с данной задачей, т. к. построили инструмент, которому тестировщики доверяют и который активно используют. На этом наша работа ещё не закончена: в ближайших планах есть много интересных задач по улучшению. Например, чтобы в момент запуска теста в Docker-контейнере автоматически стартовало динамическое развёртывание и тестовый проект сразу подстраивался под среду, указанную в параметрах запуска. Мы постарались показать вертикальный срез нашей инфраструктуры тестирования. Невозможно в рамках одной статьи рассказать обо всех нюансах. Мы готовы ответить на ваши вопросы в комментариях и будем рады, если вы расскажете о своих техниках: как справляетесь с теми или иными проблемами. |