Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Азбука ИТНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Python для начинающихНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
| Тестирование мобильных и веб-приложений: как избежать фейлов при планировании |
| 18.07.2024 00:00 |
|
Автор: Константин Морев
Привет, я Костя — QA Lead в tekmates. Мы создаём диджитал-продукты для крупного, малого и среднего бизнеса. Я 4 года проработал в тестировании — как в заказной разработке, так и в собственном продукте. За это время приложил руку к WEB, Mobile, API, OLAP, IoT-проектам. В статье расскажу про частые ошибки при планировании тестирования веб- и мобильных приложений, и, конечно, как их избежать. Все советы из моей практики, поэтому не стесняйтесь в комментах рассказывать, как устроено тестирование у вас — будет интересно забрать рабочие лайфхаки. Кроме советов также покажу интересные кейсы: например, с помощью каких инструментов автоматизации мы сократили работу в рамках регресса с 2 часов до 20-25 минут. Итак начнём. Вот какие проблемы я вижу.
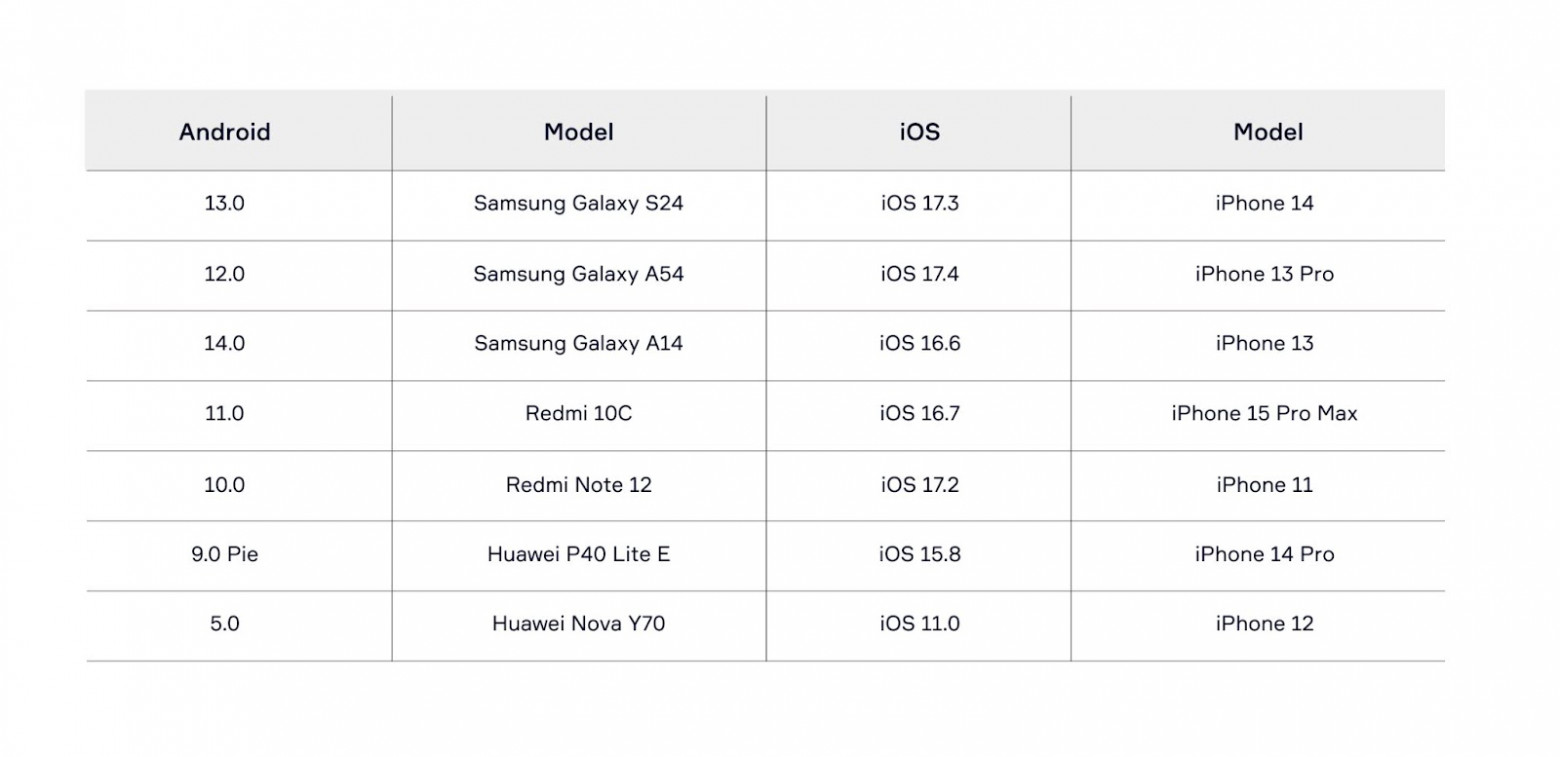
Проблемы в планировании мобильного тестированияОшибка 1. Неправильный баланс устройств и платформ для тестированияБрать любой телефон и тестировать на нём непродуктивно. Забив за собой какой-то рабочий девайс и тестируя на нём каждый день, вы игнорируете один из принципов тестирования — парадокс пестицида. Его суть в том, что если долго выполнять одни и те же проверки, они однажды перестанут выявлять ошибки. Важно понимать свою целевую аудиторию, тенденции рынка. На основе этого формировать, корректировать пул девайсов и периодически «встряхивать» тестирование, меняя устройства между QA-инженерами. Чтобы правильно выбрать девайсы, полезно обращаться к статистике. Так, по данным Statcounter и Backlinko, за последний год Android занял около 70% всей доли рынка ОС на мобильных устройствах, а iOS — 30%. На старте проекта, или в процессе, советую собрать статистику с того же Statcounter по устройствам, операционным системам, и сделать таблицу. Например, такую:
Учтите минимальную версию ОС, которую поддерживает ваше приложение, и не забудьте вписать её. Даже исходя из такой простой таблицы, можно примерно понимать основной охват и руководствоваться им. Так как моделей телефонов очень много, невозможно протестировать приложение на всех. Поэтому нужно верно рассчитывать выборку моделей для тестирования на реальных устройствах, а остальную потребность закрывать симуляторами. Мы с командой на наших проектах стараемся использовать как минимум 2-3 устройства из таблички, чтобы проверять основную функциональность, так как незаменима проверка аппаратной части: камера, аккумулятор, динамики, вибромотор, звонки и прочее. Отдельные кейсы тестируем, используя симуляторы — Android Studio, XCode, Genymotion. Например, так проверяем кейсы с учётом расширения экрана и случаи, специфичные определённым комбинациям ОС и модели. Понятно, что не всегда хватит денег, чтобы купить реальные устройства по всем нуждам. Но не стоит создавать себе симулятор с рандомной моделью и осью. Миксуйте оба варианта тестирования, потому что, следуя простой комбинаторной логике, так вы скорее охватите все нужные условия. Ошибка 2. Недостаточная подготовка тестовых сценариев и тестовых данныхБольшая проблема, когда QA-инженеры не могут начать готовиться к тестированию ещё до того, как функциональность будет собрана в сборку или ветку. В итоге наступает день Х, можно начинать тестирование, и тут выясняется, что:
Если аналитика страдает на начальном этапе проекта, это сильно влияет на дальнейшее тестирование. В результате мы не можем своевременно приступить к тестам, потому что приходится уточнять информацию прямо по ходу работы, параллельно подготавливая тестовую документацию. Поэтому важно начать изучать требования к продукту как можно раньше, преследуя принцип Shift Left. На основе принципа:
где:
Не забываем про уровни покрытия функционала по видам тестирования: учитываем smoke и regress-тесты. Ошибка 3. Недостаточно времени на тестированиеЯркий пример из опыта: работали по Agile, спринты из двух недель. Приложение успешно выпущено в маркеты, есть хорошие отзывы. Но регресс за регрессом тестировщики жаловались, что им не хватает времени на выполнение задач. Более того, зайдя на проект как Lead QA, я увидел: тестовая документация очень худа, тест-кейсы актуализировались месяцы назад, не хватает ряда основных документов и инструкций. Всё время в рамках спринта отдавалось операционке, не хватало времени на то, чтобы действительно обеспечивать необходимое качество приложения. Копая глубже, я выяснил — планирование у команд проходило без оценки. На моих глазах менеджер проекта просто брал и накидывал из бэклога задачи в спринт, сопровождая речь простым «Успеем?». Из-за того что оценки не было, бэклог разрастался, релиз сдвигался — это влияло на настроение команды.
Тут комплексная проблема, но со стороны QA всегда должна исходить оценка времени выполнения задач. Это помогает спланировать спринт грамотно, выделить на работу необходимое время, а не надеяться на чудо. Всегда нужно держаться конкретных цифр, иначе успех или провал сложно измерить. Мы провели беседу с отделами и определили, что каждый участник спринта, ответственный за задачу, обязан оценить её по времени. Для этого есть множество техник — например, здесь и тут — которые помогают рассчитать время на выполнение задачи. Чаще всего мы используем такие техники: Оценка «Трёх точек» — Three-point estimate Считаем так:
или
где:
Оценка «Снизу-вверх» — Bottom-up estimate Считаем так:
где:
С помощью метода «Снизу-вверх» хорошо оценивать User Story. Например, чтобы вывести общее время на тестирование User Story, нужно оценить отдельно:
Когда мы оцениваем проекты Agile, сначала используем грубую оценку. Мы начинаем с общей оценки различных частей проекта, а затем постоянно уточняем её по мере того, как появляется новая информация. Как и планирование в Agile, оценка происходит непрерывно и становится более детализированной по мере развития проекта. Поэтому не стоит забывать корректировать себя и здесь, пересматривать свои результаты, если нужно. Как только мы ввели оценку, резко изменилось понимание спринта, начали выделять время на работу с инцидентами, появились задачи на создание тестовой документации. Прогоны regress и smoke тестов тоже были включены в спринт под конкретными цифрами. Команды начали меньше уставать, снизился уровень стресса, клиент стал счастливее. Мы сразу начали понимать, где и какой у нас результат, потому что стали контролировать своё время.
Отсутствие адекватного контроля качестваОшибка 1. Игнорирование использования стандартных инструментов контроля качестваПервый простой инструмент, который нам нужен — инструмент для отслеживания версий. Можно задать себе вопрос: «Но этим же занимаются разработчики?». Хотя это, может быть, неочевидно, но многие разработчики игнорируют этот процесс до последнего. Хорошая разработка приложений выполняется поэтапно. По мере того, как мы улучшаем и добавляем новые функции в приложение, важно вести систему нумерации версий. Она поможет понять, что содержит каждая сборка, и куда эти сборки пойдут дальше. Например, просто назвать сборку 1.0, а затем перейти на 1.1 не так уж и сложно. Однако всё меняется, когда мы задаём вопросы:
Если мы будем знать ответы на эти вопросы, сможем верно планировать наше тестирование вперёд и даже назад. Отслеживать внесённые улучшения, функции и изменения можно с помощью Git, SVN или простого текстового файла или электронной таблицы, которую мы ведём в Confluence проекта в разделе для QA. Что ещё более важно, этот процесс нужно также документировать: фиксировать, какие были проблемы в этой версии. Когда что-то не работает в текущей версии, это может значить, что нужно откатиться к последней известной рабочей версии. И если это не отслеживать корректно, можно крупно пролететь… Ещё довольно банальный момент, но нужно поддерживать актуальность в этой системе. Сделать это привычкой: после выпуска новой сборки, нужно пойти и обновить информацию на стороне тестирования. Опять же, если команда разработчиков уже взяла на себя ответственность за это, просто нужно убедиться, что мы в курсе и у нас есть доступ к этой информации. Если разработчики этого не сделали, нужно пойти и помочь им, чтобы убедиться, что они будут делиться данными для документации изменений. В конце концов, они будут зависеть от этой информации так же, как и QA. Второй инструмент, который мы используем — инструмент для отслеживания багов. Планировать сложно, если мы не сможем чётко определить, что было сломано, что сломано сейчас и что может быть сломано в будущем. Что исправили, что исправлено и что ещё нужно исправить, также важно понимать. Ещё один пример из жизни: тестировщик не завёл баг-репорт, попросил разработчика исправить его на словах. Исправления сделаны, но никто не задокументировал:
В итоге мы работаем в сером пространстве, где всё размыто. Это оставляет всё, что касается процесса тестирования, открытым для интерпретации со стороны. На примере выше, может показаться, что тестировщики ничего не делают, каждая фича идеально программируется.
Отслеживание багов, как и отслеживание версий, требует больших усилий и времени. Когда мы создаём продукт для релиза, контроль над этими вещами может показаться пустой тратой времени, но это не так! QA-инженерам нужно быть в курсе проблем с приложением, прежде чем переходить к этапам тестирования. И вне зависимости от роли на проекте — от разработчиков до менеджеров — эта информация будет использована при планировании. Ошибка 2. Отсутствие информации об основных элементах при планированииМожно выделить четыре ключевых элемента, о которых стоит помнить: КлиентС точки зрения бизнеса, мы начинаем тестирование не с ПО или даже с документаций. Мы начинаем с клиента. Хорошо, если есть целевая демографическая группа, которая, как мы ожидаем, будет пользоваться нашим приложением, и мы сможем определить свои ресурсы на основе этих пользователей. Информация о потенциальных пользователях поможет ответить на такие вопросы:
Если понимать пользователей, будет проще определить путь для тестирования, а также потребности в оборудовании, девайсах и ПО. Например, наша целевая аудитория состоит как из технически подкованных пользователей, так и из новичков. Это значит, что нужно создать интуитивно понятный пользовательский интерфейс и предоставить подробную документацию или обучающие материалы для поддержки менее опытных пользователей. Проще говоря, заложить фундамент для разработки раздела FAQ внутри приложения. Если мы отвечаем на вопрос о том, будут ли наши пользователи платить за приложения, значит, вероятно, надо запланировать необходимость тестирования механизмов внутренних покупок и подписок, а также проверку безопасности и надёжности процесса оплаты. Это всё могут исследовать аналитики или продакт-менеджеры. Но тестировщикам тоже полезно понимать эту информацию и иметь возможность получить её от упомянутых специалистов. ВремяСколько времени понадобится на тестирование, зависит от сложности приложения, его стабильности и от того, насколько точно мы можем оценить наше время на работу — это можно сделать по формулам из предыдущего блока. Если мы тестируем обновлённое приложение или что-то очень простое, тут может понадобиться значительно меньше времени, чем если мы начинаем тестирование приложения «с нуля». Конечно, это может занять не так много времени, как мы запланируем, но никто не будет жаловаться, если мы всё сделаем раньше. ЗависимостиРазработчики, менеджеры, аналитики, дизайнеры, инструменты и сервисы — всё это зависимости. Эти вещи могут повлиять на расписание и успех больше, чем любой другой элемент. Очень важно не упускать их из виду во время планирования тестирования. Само приложениеЧтобы понять, как тестировать приложение, нужно внимательно изучить и понять, что оно делает, как это делает и зачем мы его разрабатываем. В одном из проектов на моей работе значительная часть функциональности приложения имеет в себе множество интеграций с государственными сервисами. Понимание каждого этого сервиса очень сильно помогает тестированию.
Нужно понимать, что некоторые вещи, которые мы определим сегодня, могут измениться завтра. И к сожалению, все мы знаем, что такое происходит часто в рамках проектов. Разработка приложений — это потоковый процесс, и нужно быть гибким, чтобы преуспеть. Игнорирование автоматизации тестированияОшибка. Игнорирование выбора инструментов для автоматизацииПонятное дело, что автоматизация — это круто. Конкретно на наших проектах она:
Пункты 1, 2 и 4 в целом понятны, поэтому подробнее опишу пункт 3, который и сподвиг нашу команду задуматься об автоматизации на проекте. Как уже говорил раньше, у наших приложений есть несколько интеграций с различными сервисами. И вот ситуация: запланирован регресс, QA берут релиз-кандидат сборку мобильного приложения и выясняется, что один из (а то и более) интеграционных сервисов «500-тит», сервис недоступен.
Мы провели Root Cause Analysis (RCA) и увидели, что одна из рабочих схем интеграций сменилась. Нужно откатывать некоторые изменения или выкатывать фикс, нарушая Code Freeze для регресса. Время, потраченное на изучение проблемы, и последующее решение касаемо интеграции — всего этого можно было избежать, будь у нас простой способ это предсказать. Мы проанализировали ситуацию, запустили API авто-тесты. Они по графику каждое утро показывали нам общую картину — не упало ли где-то что-то. И таким образом помогали вовремя реагировать на ситуацию. Примеры тестов, которые можно и нужно автоматизироватьЗачастую заказная разработка не предусматривает полный охват автотестами функциональности. Но это не мешает использовать простые инструменты автоматизации, чтобы облегчить свою работу — например, интеграционные автотесты на Postman. Postman очень юзер-френдли, в нём есть встроенный AI-помощник, а написание скриптов для API-тестов происходит довольно быстро, благодаря встроенным шаблонам. Но можно, конечно, выбрать и другой инструмент или фреймворк под свои нужды. Так, на одном из веб-проектов, мы в формате «пилота» решили изучить новый фреймворк для автоматизации e2e тестов — Playwright. Документация понятная и простая, есть встроенный режим написания скриптов по ходу ведения ваших активностей на экране, поддержка языков JavaScript, TypeScript, Python. Работая с Playwright, мы потратили примерно шесть часов на изучение написания простых скриптов на фреймворке, а само покрытие автотестами заняло около двух полных рабочих дней.
Резюмирую. Вот что, по моему опыту, стоит начать автоматизировать уже сейчас:
Что в итоге
А теперь давайте обсудим: как вы планируете ваше тестирование и учитываете ли что-то ещё, о чём я не рассказал? |