




UI-автотесты под Android — отличный инструмент, который позволяет кратно сократить время на проверку разрабатываемых фич и свести к минимуму участие в ручном регрессионном тестировании инженеров по обеспечению качества. Но работать с UI-тестами надо правильно — иначе все может прийти к ситуации, при которой автотесты становятся нестабильными, а их результаты не вызывают доверие.
Меня зовут Эмилия Куцарева. Я — руководитель команды автоматизации тестирования в Одноклассниках (VK). В этой статье я расскажу о нашем подходе к работе с Android UI-автотестами: как устроен запрет мерджа, как смогли стабилизировать тесты, как настроили параметризацию запуска.
UI-автотесты в ОК
В ОК большое количество UI-автотестов на Android — около 1400. Чтобы оптимизировать обработку такого значительного объема, мы запускаем в облаке по 250 автотестов в 3 потока — это позволяет выполнять одновременно 750 тестов. Под каждый автотест создается свой эмулятор, который удаляется после завершения теста. Из технологий мы используем Java и Espresso.
Сборка APK и запуск unit-тестов под каждую ветку проходит на Teamcity в течение 15 минут. После этого на прогон UI-тестов требуется 15-20 минут. Таким образом, от запуска сборки до получения результатов тестирования у нас уходит 30-35 минут.
Автотесты запускаются из Pull request’a (пулл реквеста). Соответственно, вся информация о результатах приходит туда же. Мы гоняем UI-автотесты на каждый commit (коммит) в каждом пулл реквесте. Таким образом, при создании разработчиком пулл реквеста сразу запускаются UI-автотесты.
Как устроен запрет мерджа в пулл реквесте? Автоматический запрет или разрешение мерджа зависит от:
сборки приложений и тестов (если APK приложения и тестов не собрались, незачем запускать Unit- и UI-тесты);
прогона unit-тестов;
прогона UI-тестов;
аппрувов от мейнтейнеров.
Соответствие или несоответствие этих условий предварительно установленным критериям дает либо разрешение, либо запрет мерджа.
Какие результаты запуска UI-тестов мы получаем
Остановимся на том, как мы добились запрета мерджа по UI-тестам. Пулл реквест — это наша основная точка входа. Такая реализация была выбрана для удобства разработчиков, которые выполняют основной массив работы именно в пулл реквесте — это позволило консолидировать всю нужную информацию в рамках «одного окна».
О результатах теста мы информируем с помощью сообщений в пулл реквесте, в которые вынесли всю ключевую информацию. Так, в нашем случае сообщение включает:
статистику по запущенным тестам;
ссылки на отчеты по тестам;
ссылки для перезапуска тестов;
ссылки на APK и сборку в Teamcity;
ссылку на статистику по тестам (количество стабильных, нестабильных, вечно падающих).
Так, при разрешении мерджа в сообщении будет позитивная статистика ветки по количеству упавших тестов и зеленая галочка, как показатель того, что мердж разрешен.

Если же количество упавших на ветке тестов превышает допустимый лимит, сообщение вместе со статистикой будет содержать еще и ссылку на прогоны упавших тестов. Соответственно, вместо зеленой галочки будет красный крестик, указывающий на то, что мердж запрещен.

Принцип разделения автотестов на категории
Мы разделили автотесты на три категории:
стабильные — тесты, которые проходят больше 80% (принятый нами лимит);
нестабильные — тесты, которые проходят больше 0%, но меньше 80%;
вечно падающие — тесты с нулевым рейтингом, которые падают на всем цикле рассматриваемых раундов.
При расчете стабильности тестов мы придерживаемся небольшого свода правил.
Учитываем только n последних запусков. Мы не смотрим на всю историю прогона автотестов, потому что приложения и сами тесты быстро меняются. Например, сейчас при расчете мы учитываем только 50 последних запусков.
Берем только доверенные джобы Teamcity. Чтобы не влиять на статистику запусков из-за возможных изменений входных параметров джоб и получать объективные результаты, мы не учитываем ручные запуски с разными параметрами. При расчете стабильности учитываем только автоматические запуски с одинаковыми параметрами, они и являются доверенными — так мы повысили надежность и стабильность.
Запускаем автотесты только на основных ветках. Наш релизный цикл следующий: Pull Request → develop → stable → release. Соответственно, при расчете стабильности тестов мы смотрим только на develop-, stable- и release-ветки. То есть, даже если фича готова и автотесты по ней запускаются на доверенных джобах, она не будет учтена, пока не попадет в основную ветку. Так мы исключаем влияние на результаты автотестов.
Не учитываем инфраструктурные падения. Поскольку мы не можем гарантировать отсутствие ошибок на уровне инфраструктуры, при расчете стабильности тестов, мы не учитываем подобные падения, так как они никак не зависят от работы самого теста.
Считаем не только запуски, но и перезапуски автотестов. Это позволяет получать максимально объективную оценку стабильности автотестов.
Такая комбинация подходов дает нам возможность получать точную статистику по автотестам.
Помимо этого, мы также исключаем из падающих на ветке тесты с известными падениями. То есть, если мы находим падающий тест, который ранее уже маркировали, то мы исключаем его из расчета статистики, так как это уже известный, а не новый баг. Так мы уходим от ситуации, при которой падающий тест с известной проблемой влияет на статистику во всех прогонах.
В отчеты по падающим автотестам в пулл реквесте мы выводим как ссылки на стабильные тесты, которые упали, так и топ нестабильных. Это нужно, чтобы мы могли видеть и тесты, для которых запрет на мердж будет не такой строгий.
При этом разрешение мерджа зависит от полученных результатов отработки автотестов. Например, у нас следующий подход:
если среди стабильных автотестов, которые больше 80%, падает хоть один — будет запрет мерджа;
если в нестабильных тестах больше 25 падений (принятый нами лимит) — будет запрет мерджа;
статистика вечно падающих тестов не влияет на запрет.
В итоге сообщение при запрете мерджа будет иметь следующий вид:
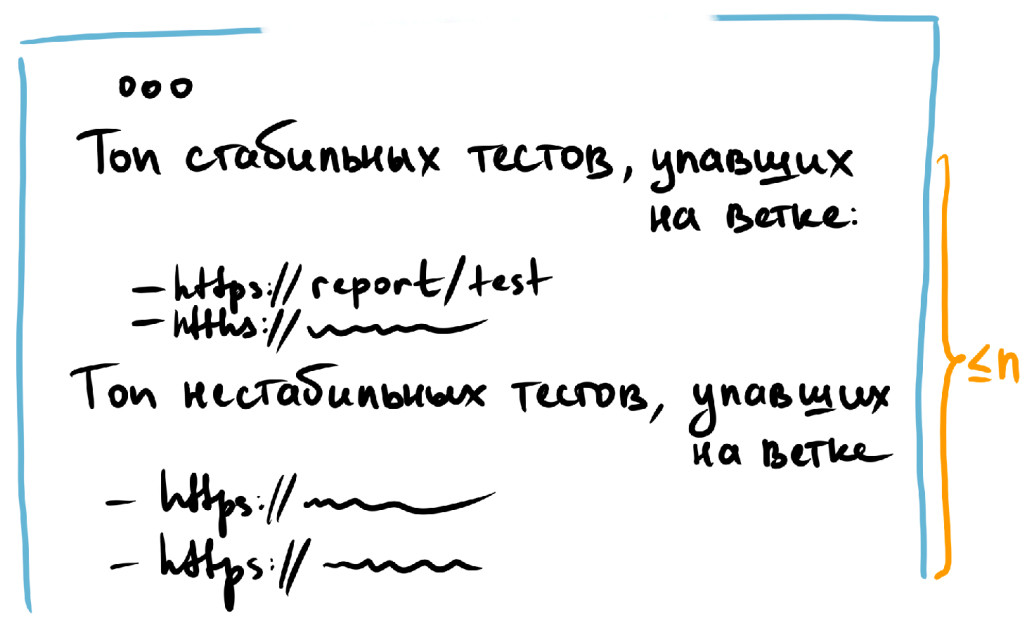
Так, сообщение содержит:
топ стабильных тестов, упавших на ветке и ссылки на них — можно сразу в пулл реквесте перейти по ссылке, увидеть скриншоты, логи, посмотреть, когда этот тест падал, какая у него история;
топ нестабильных тестов, упавших на ветке и ссылки на них.
При этом, чтобы не захламлять лог пулл реквеста, за раз мы выводим не более 20 сообщений.
Работа со статистикой по тестам
Нам важно маркировать и отслеживать все, что происходит с тестами. Поэтому мы ведем статистику, которую можно открыть в любой момент. Например, через нее мы можем увидеть:
какие тесты находятся в стабильной категории;
какие — в числе нестабильных и требуют исправления.
Кроме прочего, на основе этих данных мы можем проводить аудит автотестов. Здесь есть несколько нюансов.
Новый тест — не обязательно стабильный. Вполне возможно, что даже после успешного первого запуска тест упадет условно на третьем. То есть, минимальный подсчет статистики лучше начинать после нескольких запусков — именно так мы и делаем. Тесты, которые не прошли пять прогонов (принятый нами лимит), мы относим к категории вечно падающих.
Важно отметить, что для разрешения мерджа для новых тестов, они обязаны быть зелеными. Это правило позволяет нам избежать попадания красных тестов в мастер-ветку.
Тест может неожиданно начать падать. Причин может быть много — например, попадание бага в develop или обновление API. Чтобы не получать блокировку мерджа из-за падений ранее стабильного теста, нужны механизмы смены категории автотеста, а также функция ручного разрешения мерджа.
Баг может попасть в основную ветку. В различных граничных случаях в основную ветку может попасть и баг, и сломанный автотест. Поэтому мы отслеживаем падения — если тест на develop-ветке начал падать n раз подряд, дежурный Android-тестировщик получает уведомление. В нашем случае нотификация отправляется после 5 падений на develop.
Таким образом, запрет мерджа в пулл реквесте мы реализуем следующим образом:
разделяем тесты по категориям: стабильные, нестабильные, вечно падающие;
постоянно отслеживаем стабильность автотестов;
игнорируем известные и инфраструктурные падения.
Благодаря такому подходу, мы можем автоматически запрещать мердж.
2. Как мы делаем тесты стабильнее
Стабильность Android UI-автотестов для нас — ключевой параметр, к улучшению которого мы стремимся. Чтобы обеспечить это, мы занимаемся оптимизацией комплексно и на всех уровнях:
внутри кода тестов;
внутри Runner’а (раннера);
внутри пулл реквеста.
2.1. Повышение стабильности внутри кода тестов
Естественно, для повышения стабильности можно и нужно работать над бизнес-логикой, кодом автотестов и имеющимися ошибками. Но нам было важно стабилизировать процессы общие для всех тестов.
Использование ретраев
Начнем с ретрая действий, для него мы реализовали следующую схему:
Если действие совершается без проблем — ничего не происходит.
Если при совершении действия возникает NoMatchingViewException или PerformException, подключается класс Espresso FailureHander, который ловит подобные исключения.
При обнаружении исключений запускается ретрай действия. Этот цикл выполняется в течение заданного периода времени, если не получен положительный результат.
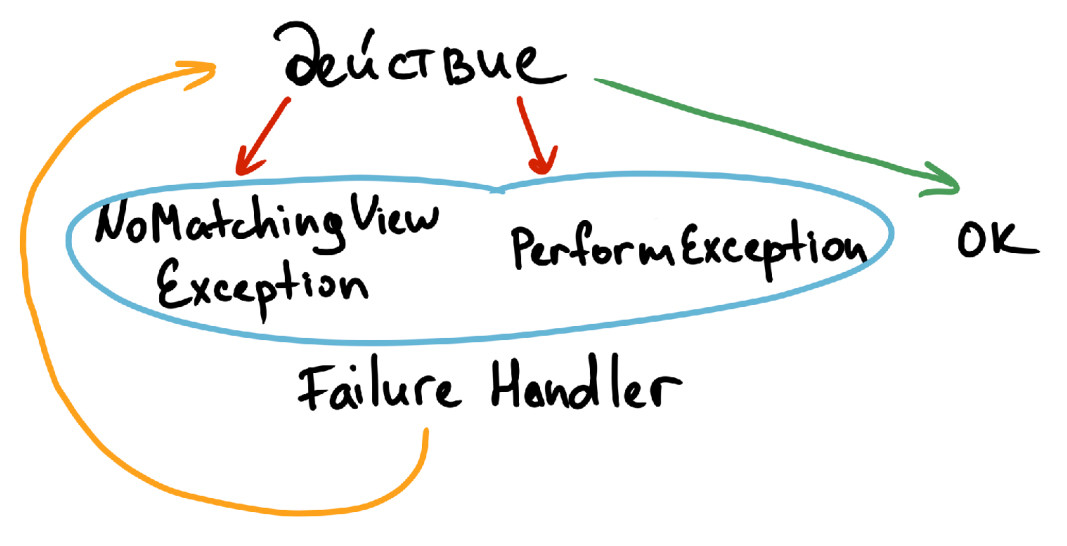
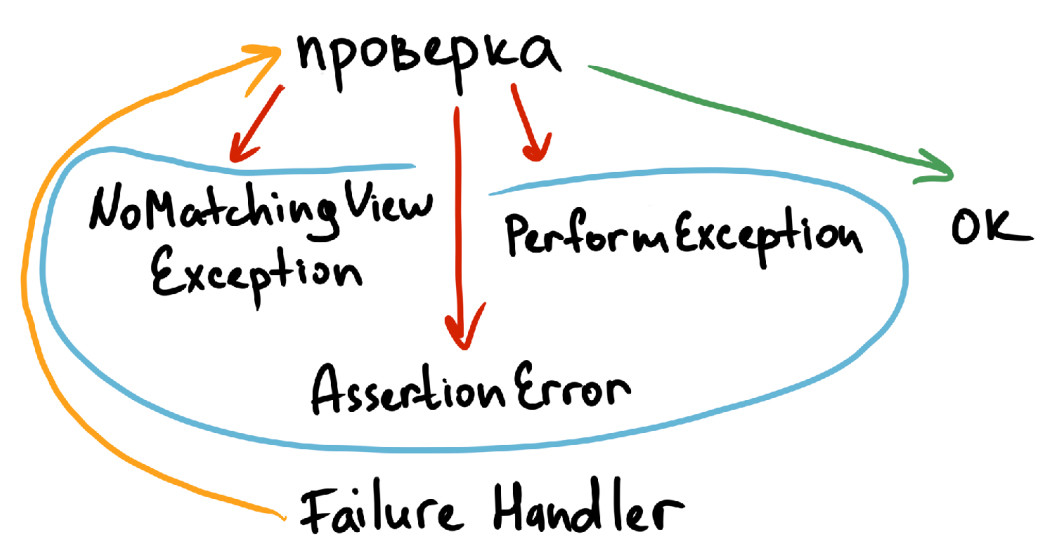
Таким образом, мы закладываем возможность сделать несколько попыток, чтобы повысить стабильность тестов. Алгоритм ретрая проверок схож. Так:
Если проверка выполняется без проблем — дальше ничего не происходит.
Если во время проверки возникает NoMatchingViewException, PerformException или AssertionError, подключается класс Espresso FailureHander, который ловит исключения и отправляет их на ретрай.
Попытки повторяются либо до получения положительного результата, либо до завершения установленного таймаута.
Работа с повторяющимися элементами
Espresso не позволяет работать с повторяющимися элементами: например, если что-то надо найти по Matcher — это должен быть один элемент. Поскольку в ОК много повторяющихся элементов (например, списки друзей, сообщений или музыкальных треков), мы реализовали следующий алгоритм:
Если нашелся всего один элемент — все хорошо, ничего не происходит.
В случае обнаружения множества одинаковых элементов, возникает ошибка AmbigiousViewMatcherException.
Для отлавливания исключения мы используем FailureHandler и забираем только первый элемент.
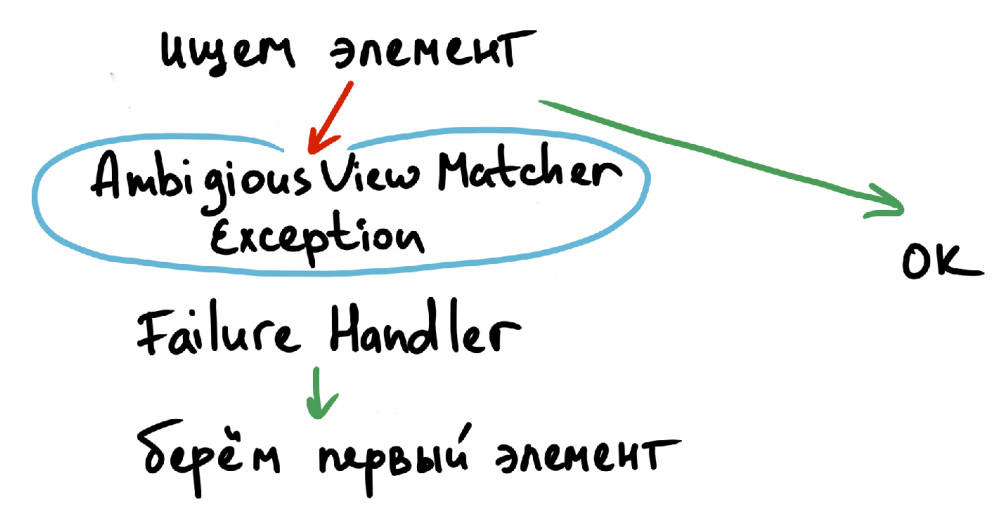
Вместе с тем у такого подхода есть ограничение — придется всегда работать только с первым элементом. Если нужно работать с произвольными элементами — надо точнее прописать сам матчер.
Использование ожиданий
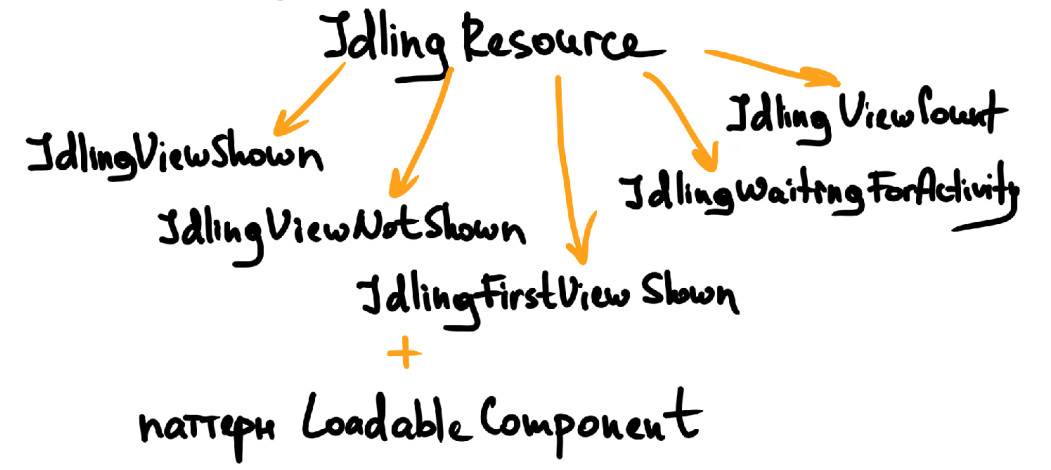
Мы также используем ожидания. Так, в Espresso есть IdlingResource. Для себя мы реализовали множество кастомных ожиданий, в том числе: IdlingViewShown, IdlingViewNotShown, IdlingFirstViewShown, IdlingViewCount и другие.
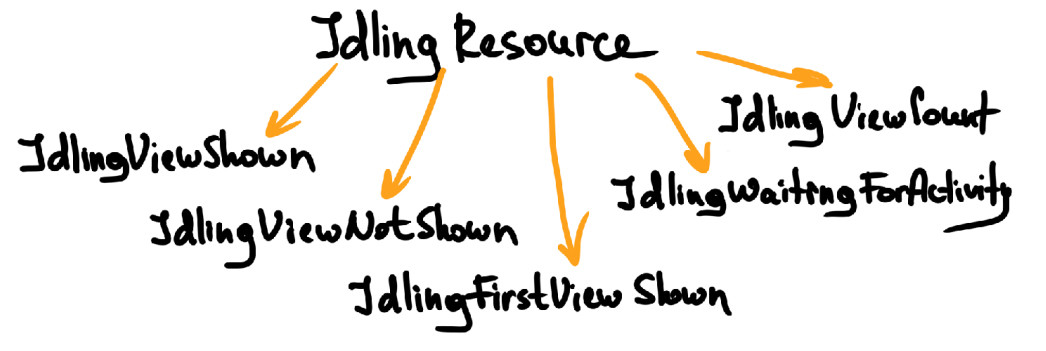
Таким образом мы можем ожидать и отслеживать появление тех или иных элементов. В комбинации с паттерном Loadable Component мы получаем идеальную схему. Почему? При загрузке новой страницы мы не всегда можем рассчитывать на ожидания, которые есть в Espresso, поэтому первым методом при загрузке новой страницы вызывается метод ожидания — например, ожидание определенного элемента экрана, что позволяет убедиться, что экран загружен полностью и с ним можно работать.
Ожидания у нас ограничены по времени — если лимит времени превышен, тест падает с понятной, интерпретируемой ошибкой.
Аналогичная логика ожидания применяется у нас в автотестах для всех платформ.
Уход от UI
При оптимизации стабильности на уровне кода мы также решили максимально уйти от UI за исключением шагов, которые должны быть выполнены через интерфейс. Так, для большинства сценариев мы начали использовать наш API-клиент — с его помощью мы можем пропустить все необязательные шаги автотеста, что значительно экономит время и повышает стабильность тестов.
Также мы добавили работу с deep links. Так мы получили возможность быстрой навигации для пропуска отдельных шагов и действий. Это помогло нам сократить время и повысить стабильность тестов.
Дополнительно мы добавили быстрый логин. У нас в ОК для проверки функций и бизнес-логики в большинстве случаев нужна эмуляция пользователей, поэтому практически в каждом автотесте выполняется логин. Функция быстрого логина через специальный метод позволила нам пропускать шаг логина. В итоге мы сокращаем время выполнения теста и не попадаем на эксперименты страницы логина.
Суммарно для ухода от UI мы использовали:
API-клиент;
переходы по deep links;
быстрый логин.
Таким образом, чтобы повысить стабильность UI-автотестов, мы на уровне кода:
ретраим действия и проверки (с сохранением всей истории в системе отчетности);
работаем с повторяющимися элементами;
используем ожидания;
заменяем UI шаги.
2.2. Повышение стабильности на уровне Runner’а
У нас есть собственный кастомный раннер и мы оптимизировали процессы внутри него, чтобы сделать тесты стабильнее.
Использование ретраев
Первое, что мы реализовали в рамках оптимизации — сделали ретрай действий раннера:
получение эмулятора;
установку приложения и тестов;
скачивание данных с эмулятора.
Каждое из этих действий не защищено от падений, поэтому нам было важно самостоятельно исключить влияние потенциальных ошибок на автотесты — ферма всегда должна работать стабильно.
Сейчас на все действия раннера мы даем три попытки. В результате инфраструктурных падений стало намного меньше.
Одновременно с этим мы также ретраим тесты и на уровне раннера.
Так, в случае падения теста мы смотрим на его успешность. В нашем случае лимит успешности равен 30% — если тест работает относительно стабильно, мы считаем, что все хорошо. Если успешность ниже 30%, мы считаем, что тест нестабильный или вечно падающий, поэтому не ретраим его, чтобы не тратить время и ресурсы.
Ретраи автотеста мы выполняем параллельно для ускорения времени запуска. Сейчас у нас для падающих автотестов запускается 2 ретрая, как только автотест упал на основном запуске.
При этом мы ограничиваем максимальное количество ретраев на запуск. Сейчас пороговое значение — 100 тестов. Так мы снижаем нагрузку на ферму и исключаем сценарий, при котором одновременно могут перезагрузиться сразу 1400 наших тестов. Более того, ретрай 100 тестов на запуск — достаточный для нас показатель того, что ошибок в тестах сильно много и сначала надо их устранить.
Использование таймаутов
На уровне раннера мы также используем таймауты, чтобы тесты не выполнялись бесконечно. Для этого мы:
ограничиваем время прогона — раннер принудительно останавливает тест, если он не успевает за выделенное время;
останавливаем зависшие тесты по заданному таймауту — это позволяет не тратить ресурсы фермы впустую.
Таким образом, повышение стабильности на уровне раннера мы обеспечиваем:
ретраем действий раннера (с сохранением всей истории в системе отчетности);
ретраем тестов (с сохранением всей истории в системе отчетности);
ограничением времени на тесты.
2.3. Повышение стабильности внутри пулл реквеста
Помимо получения сообщений с результатами прогона и просмотра статистики, из сообщения в пулл реквесте у нас можно:
перезапустить только что упавшие тесты;
перезапустить все тесты.
При этом запрет мерджа будет считаться по новому прогону — устаревшая статистика не учитывается.
Вместе с тем, здесь есть нюанс. Так, у нас в прогон уже включены два ретрая, поэтому может быть ситуация, когда мердж разрешается после того, как тест успешно завершился только с шестой попытки. Поэтому важно отслеживать, чтобы в пулл реквесте не было неоправданно много прогонов. Но ради автоматического запрета мерджа мы идем на такие издержки.
Для повышения стабильности внутри пулл реквеста мы также решили замораживать (мокировать) фича тогглы (feature toggles). Для этого мы предусмотрели два варианта:
Заморозка фича тогглов для всех тестов. В нашем Android-проекте лежит файл с фризом всех пропертей, из которого мы постоянно читаем, какие проперти и с каким значением прописаны, и применяем их для всех тестов.
Заморозка фича тогглов для отдельных тестов через аннотации. У нас есть отдельные аннотации для тестовых классов. Мы можем поставить конкретному тесту аннотацию с указанием значения фича тоггла. Таким образом мы можем без конфликта запускать тесты и на старые, и на новые фичи.
Ключевой момент в такой реализации — поддержание мокирования фича тогглов в актуальном состоянии (их нужно отслеживать и своевременно актуализировать).
Итого, для повышения стабильности UI-автотестов мы реализуем улучшения на уровне кода, раннера, пулл реквеста и фича тогглов.
3. Как мы запускаем тесты?
Теперь подробнее о том, как мы запускаем тесты.
Параллелизируем тесты
До момента, когда у нас было 700 тестов, мы запускали их на одном инстансе облака. Но с увеличением количества тестов и появлением необходимости запускать их на каждый коммит в каждый пулл реквест так, чтобы они не стояли в огромной очереди, нам потребовалось изменить подход.
Так как мы решили запускать автотесты из разных пулл реквестов на нескольких облачных инстансах одновременно, нам нужно было сделать тест изолированным относительного самого себя, чтобы мы могли запускать несколько его экземпляров в параллель и эти запуски не влияли друг на друга. Для этого мы работали над данными внутри автотестов: они должны быть либо динамическими, либо статическими на чтение. В этом нам значительно помог перевод всех тестов на использование временных ботов (ненастоящие пользователи, созданные под конкретный запуск автотеста), взамен статических (ненастоящие пользователи, созданные единожды под конкретный автотест и неменяющиеся со временем).
Тесты, которые мы по разным причинам не можем запустить на временных ботах, мы оставляем на статических. Но делим на две категории: на чтение, на редактирование.
Боты на чтение ничего не меняют, поэтому мы можем запускать автотест с ними в несколько потоков.
Но с ботами на редактирование мы не можем запустить один автотест в несколько потоков одновременно. Поэтому для таких ситуаций мы решили, что у нас будут отдельные прогоны, в которых тесты не выполняются параллельно самим себе. Такие автотесты у нас запускаются только на develop-, stable- и release-ветки, а не на каждый коммит в каждый пулл реквест.
Добавляем аннотации для запуска
Нам важно, чтобы тесты можно было запускать по-разному, с учетом потребностей и предпочтений инженеров по обеспечению качества и разработчиков. Поэтому мы добавили аннотации для запуска.
Мы используем несколько типов аннотаций:
Тип устройства. Например, смартфон или планшет — у нас есть тесты, написанные под конкретный тип.
Тип теста. Например, отдельные тесты для проверки апгрейдов версий.
Имя пакета, тестового класса, тестового метода.
Теги. С помощью тегов можно промаркировать, к какой категории относится тест и что именно он затрагивает. Например, через сообщения можно отправлять фото, поэтому при запуске теста сообщений тест мы помечаем тегами message и photo. Благодаря таким тегам также можно быстро запустить все тесты с определенным тегом — например, если нужно проверить все, что связано с фото, достаточно запустить тесты по тегу photo.
Имя автора/владельца автотеста.
Каждый из типов аннотаций мы можем свободно сочетать, что позволяет получать сотни комбинаций под разные задачи и сценарии.
Настраиваем запуск через TeamCity
Также мы настроили запуск через Teamcity. Так, сейчас умеем запускать автотесты:
на разных тестовых средах;
на разных уровнях Android API;
с указанными значениями feature toggle;
c разными версиями API-клиента;
с разными режимами StrictMode — так мы упрощаем контроль для разработчиков;
с разными дополнительными логами — это позволяет отслеживать метрики, которые нужны в конкретном сценарии.
Итого запуск тестов мы реализовали следующим образом:
Запараллелили всё, что можно. Сейчас из 1400 тестов менее 20 работает со статическими ботами, остальные — на временных.
Навесили аннотации под разную логику и добавляем новые аннотации по запросу.
Настроили запуск с любыми кастомными параметрами, которые могут понадобиться.
Динамика развития и улучшения Android UI-автотестов в ОК
Мы работаем с автотестами давно и непрерывно их развиваем.
Так, в 2018 году у нас было всего около 300 автотестов, а к 2024 — больше 1400. Благодаря непрерывной оптимизации, даже с повышением количества тестов, мы сумели уменьшить процент их падений (например, с 6% в 2020 году до 0,5% в 2024 году) и не завышать время на запуск — как и при 300 тестах, так и на запуск 1400 тестов нужно около 20 минут.
К настоящему моменту у нас реализованы различные механизмы ретрая, которые сделали наши автотесты существенно стабильнее и предсказуемее. Также сейчас у нас есть полная, работающая логика запрета мержа в пулл реквесте по UI-автотестам, благодаря которой мы можем находить баги в момент разработки и конкретизировать, что именно и где не работает.
Мы продолжаем работать над развитием наших Android UI-автотестов. Сейчас занимаемся улучшением системы мокирования фича тогглов, оптимизацией фреймворка и другими актуальными задачами, о чем, надеюсь, вместе с коллегами расскажем в будущем.