Что пишут в блогах
- QAOps: как объединить QA и DevOps, чтобы ускорить релизы без потери качества
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Азбука ИТНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Python для начинающихНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
| Что там по автотестам на Android в 2022? |
| 16.11.2022 00:00 |
|
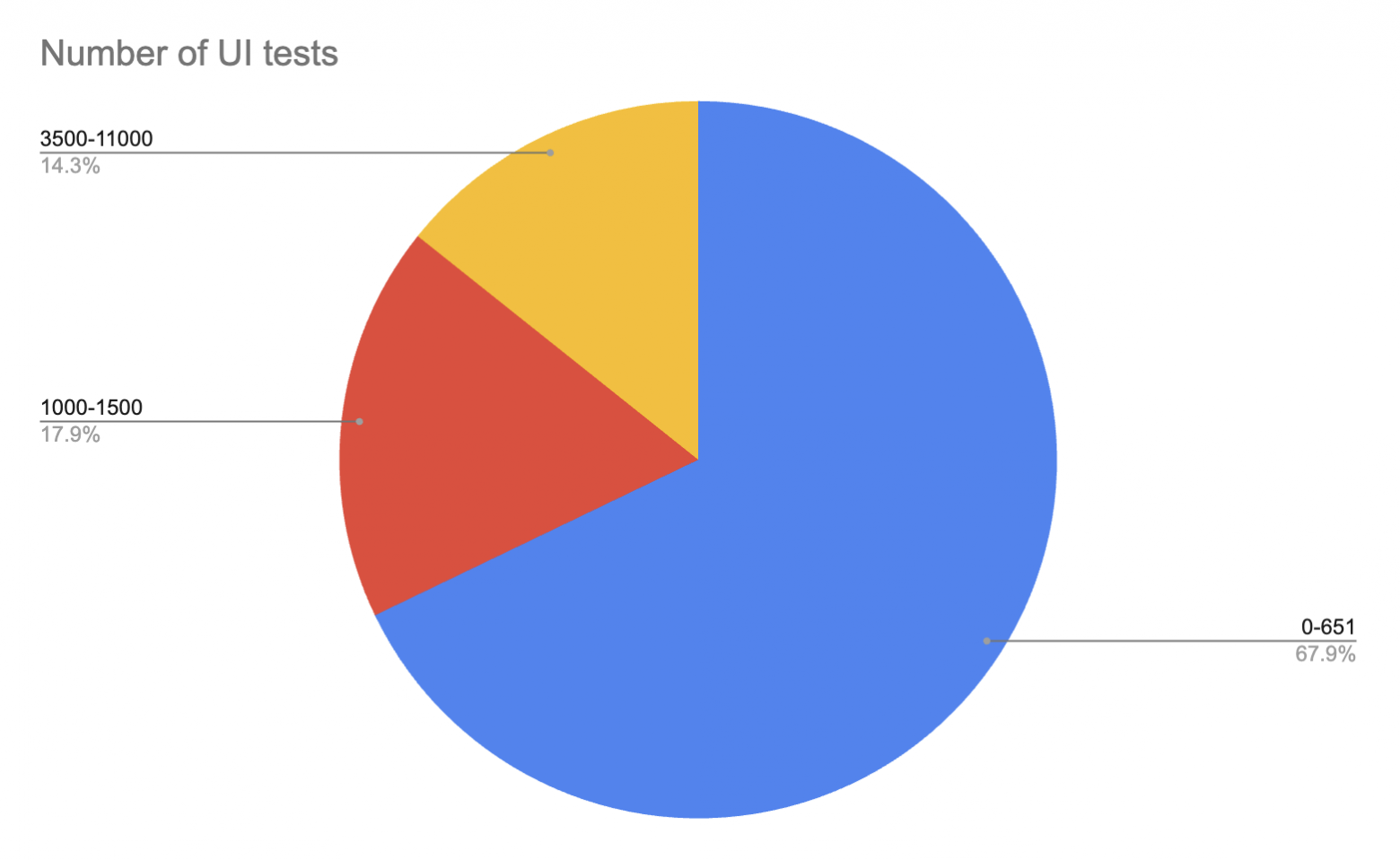
Автор: Евгений Мацюк Всем привет! Меня зовут Женя, и я люблю автотесты. Причем люблю так сильно, что даже стал соавтором Kaspresso, OpenSource библиотеки для написания автотестов под Android, и автором ряда докладов и статей про тесты (Kaspresso: фреймворк для автотестирования, который вы ждали, Автотесты на Android. Картина целиком, Kaspresso tutorials. Часть 1. Запуск первого теста, Дмитрий Мовчан, Евгений Мацюк — Как начать писать автотесты и не сойти с ума). Также со мной полюбил автотесты и мой товарищ, Сергей Ярцев, который является CTO в HintEd, и также вынужден трогать автотесты, причем под разные платформы. В одной из своих статей (Автотесты на Android. Картина целиком) я описывал, что вообще в себя включают Автотесты под Android. Если кратко, то я выделял 4 большие области: Процесс написания автотестов, Runner, Инфраструктура и Остальное, которое включало в себя отчеты, интеграцию с CI/CD и тд. В свое время (2019-2020) когда мы делали Kaspresso, мы закрывали боль с написанием автотестов. Теперь разработчики и тестировщики могут писать красивый и понятный DSL и не думать про проблемы с флаканием, логами, скоростью и тд. По другим же областям были некоторые решения, но команды, выстраивающие весь процесс, должны были сами со всем этим разбираться и все это стыковать. Особенно больно было с Инфраструктурой, где приходится нырять в дивный мир DevOps и частично даже Highload. Недавно мне стало интересно, а как сейчас обстоят дела у разных команд с автотестами. Для этого мы с Сергеем провели ряд интервью с более, чем 30 разными командами. Да, это далеко не вся выборка, и данное исследование точно не претендует на абсолютную истину. Но 30 больше, чем 1 или 2 или 5, и поэтому исследование точно может наводить на кое-какие мысли. Исследование Итак, что за команды мы опрашивали. Большая часть команд находится в России, но мы также охватили команды из Европы, США и Австралии. Мы пообщались с такими компаниями, как Spotify, Revolut, Badoo, Авто.ру, Sber, HH и другие. У всех есть UI тесты в том или ином виде. Причем количество тестов достаточно сильно варьируется:
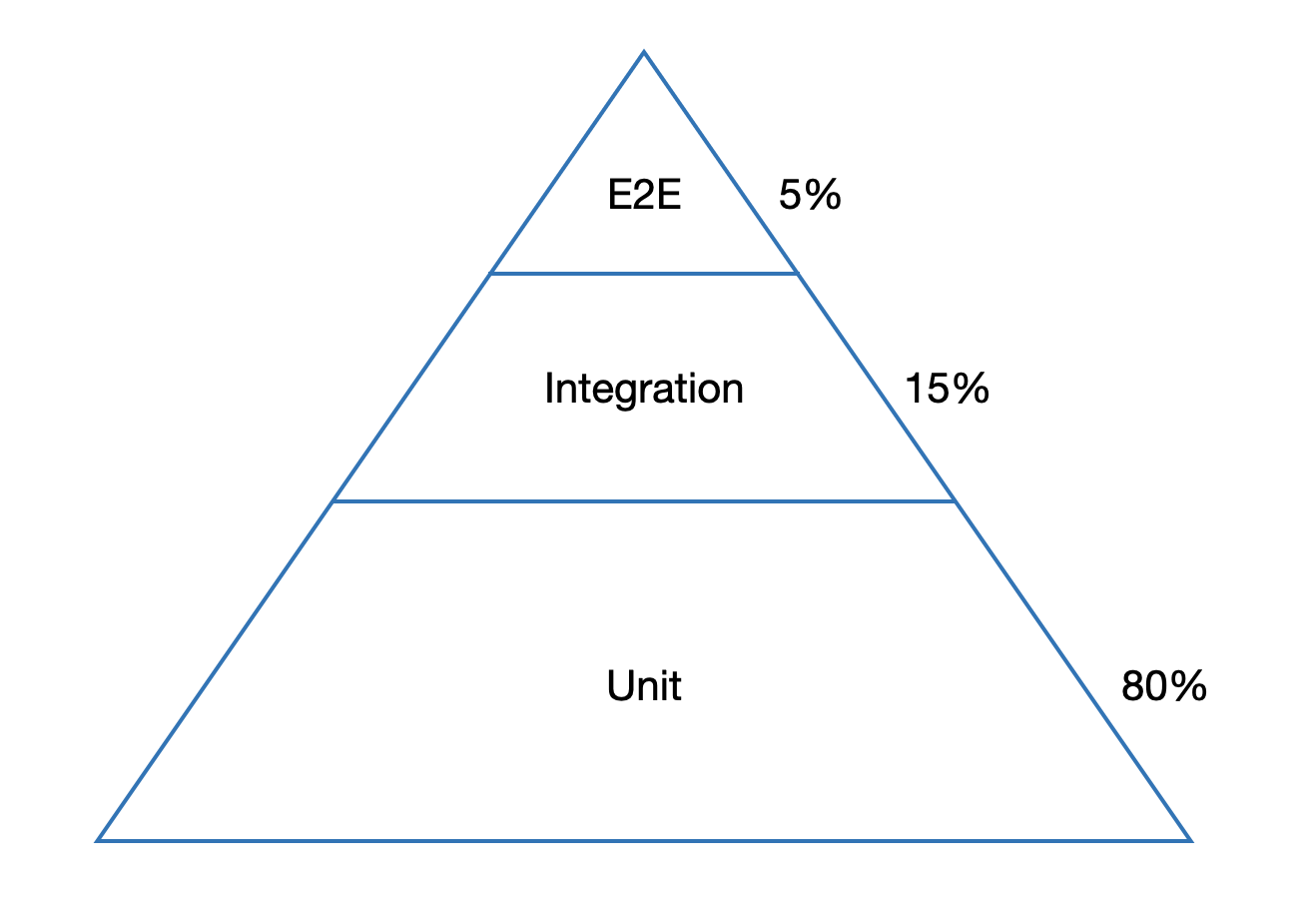
Только у 1/3 UI тестов больше 1000. Рекордсмены - 11000 тестов. Интересно было понять, кто как соблюдает пирамиду тестирования. Напомним, что пирамида здорового человека - это когда Unit-тестов примерно 80% от общего количества, а E2E (они же UI обычно) - около 5%:
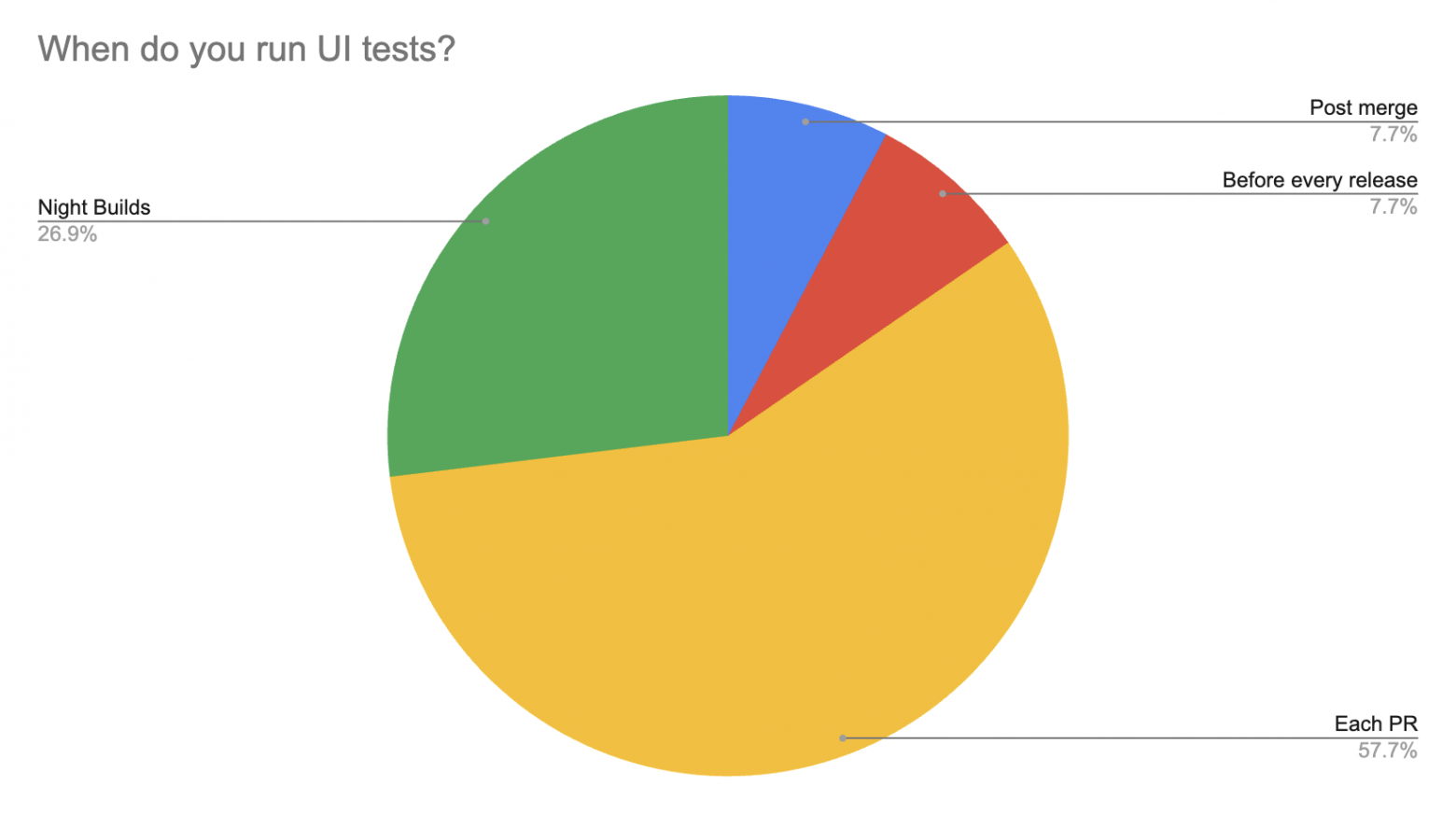
У 75% наших респондентов пирамида правильная или почти правильная. У 25% что-то пошло не совсем так (количество E2E превышает количество Unit тестов), но называть мы их, конечно же, не будем, это будет наш маленький секрет. Следующим вопросом было, на какой наиболее ранней стадии команды запускают UI тесты. Причем тесты могут быть не все (какой-то определенный набор или набор после impact анализа) и могут быть на замокированных данных. Картина следующая:
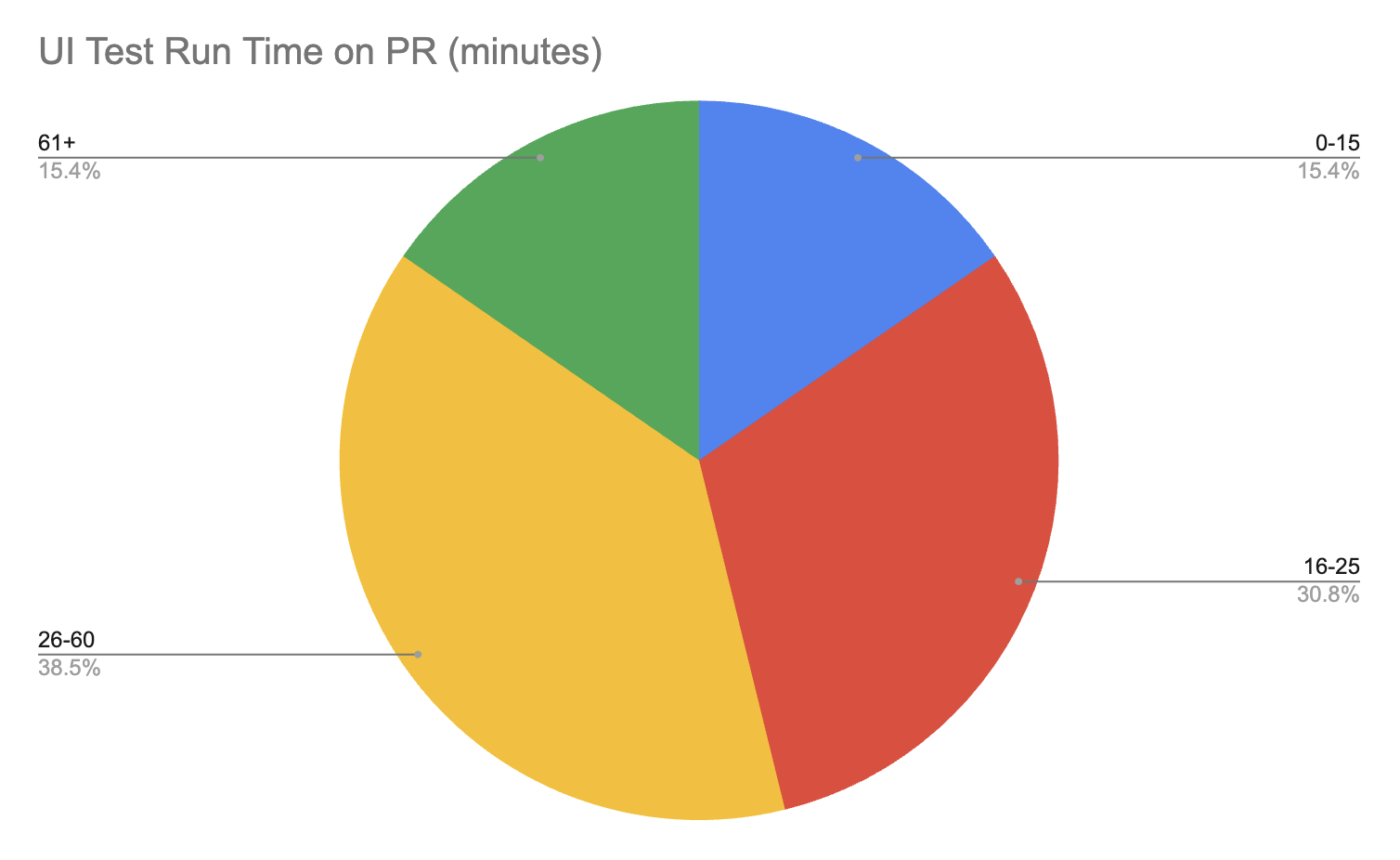
Более половины делает это на PR, еще четверть на регулярных ночных билдах. Как мы видим, практика запуска тестов только перед релизом, по сути, ушла в прошлое. Также хотим отметить, что более половины всех респондентов использует замокированные данные. По опыту, обеспечить стабильность тестов, тем более на PR, без мокирования практически нереально. Как обстоят дела со средним временем прогона UI тестов на PR? Предлагаем взглянуть на график ниже:
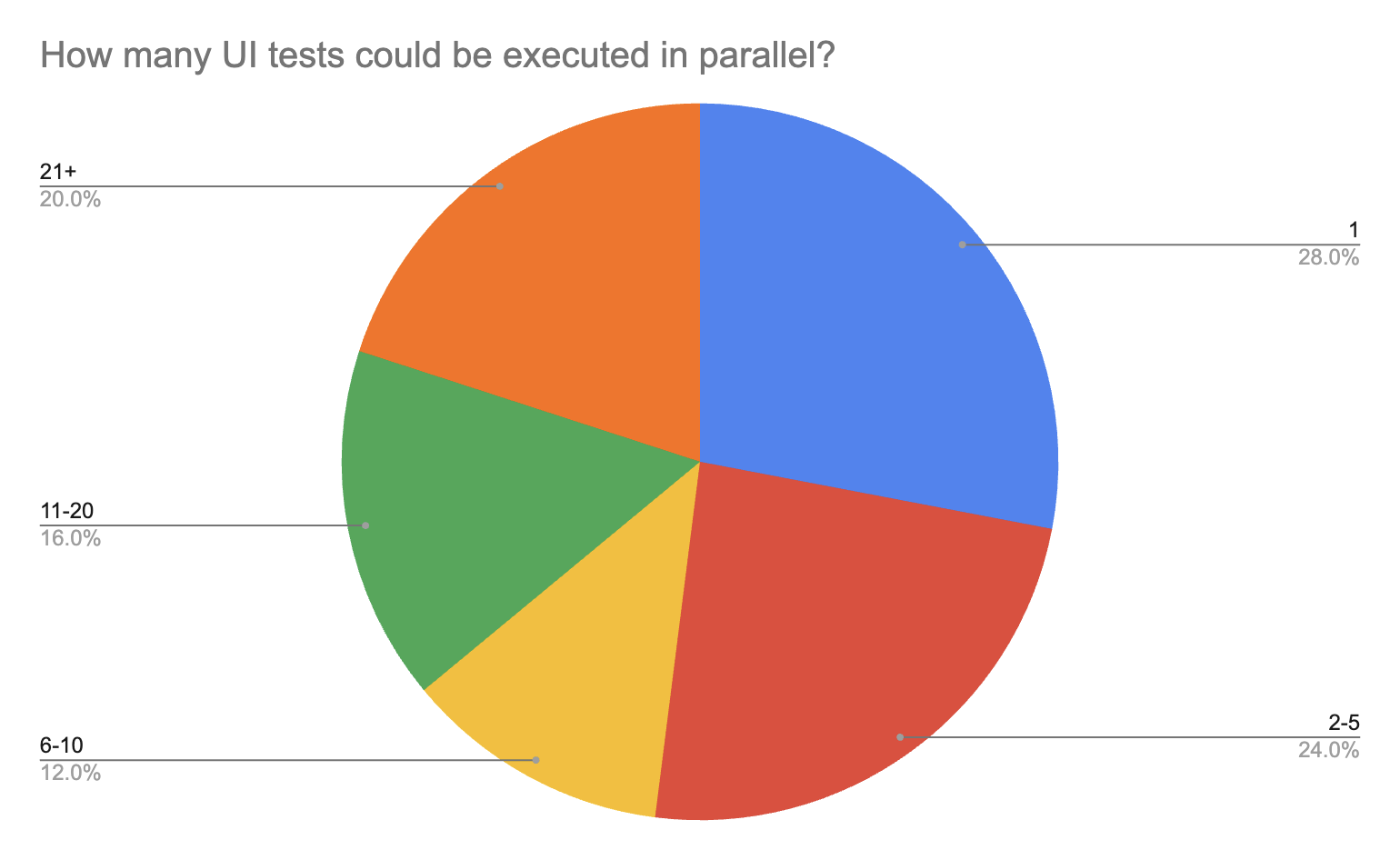
Я не раз встречал утверждение, что разработчики готовы ждать результатов прогона не более 15 минут. В противном случае они переключаются на другие задачи, и текущий PR подвисает. К сожалению, у меня нет каких-то исследований на этот счет. Но если отталкиваться от цифры 15 минут, то многим командам есть еще куда расти. Масштабируемость инфраструктуры - наше все. Стоит также отметить, что время прогона тестов не на PR (ночные прогоны, прогоны после вливания ветки) уже не так критично, и там встречаются цифры 2-3 и более часов. Коль уж мы затронули вопрос масштабируемости, то очень интересно взглянуть на то, сколько тестов в параллели могут запускать команды в среднем:
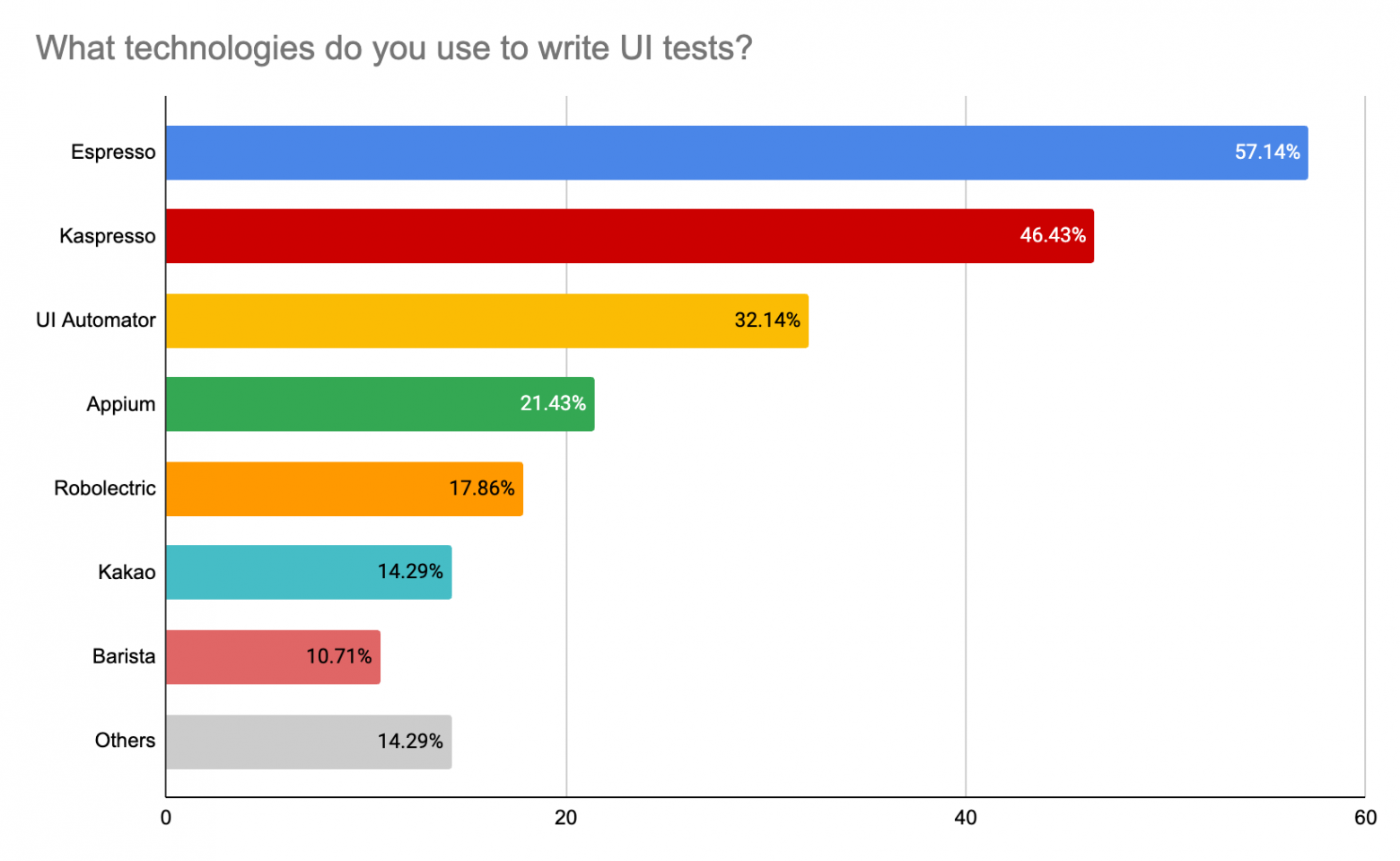
Более половины респондентов ограничиваются только 5 эмуляторами. Добавлю, что практически все, у кого в параллель запускается 1 тест, не гоняют тесты на PR. Ну, оно и понятно, тут все упирается в инфраструктуру. Далее мы поспрашивали команды про используемые технологии (в ответах команды могли выбирать несколько пунктов, поэтому сумма процентов легко может быть 146%):
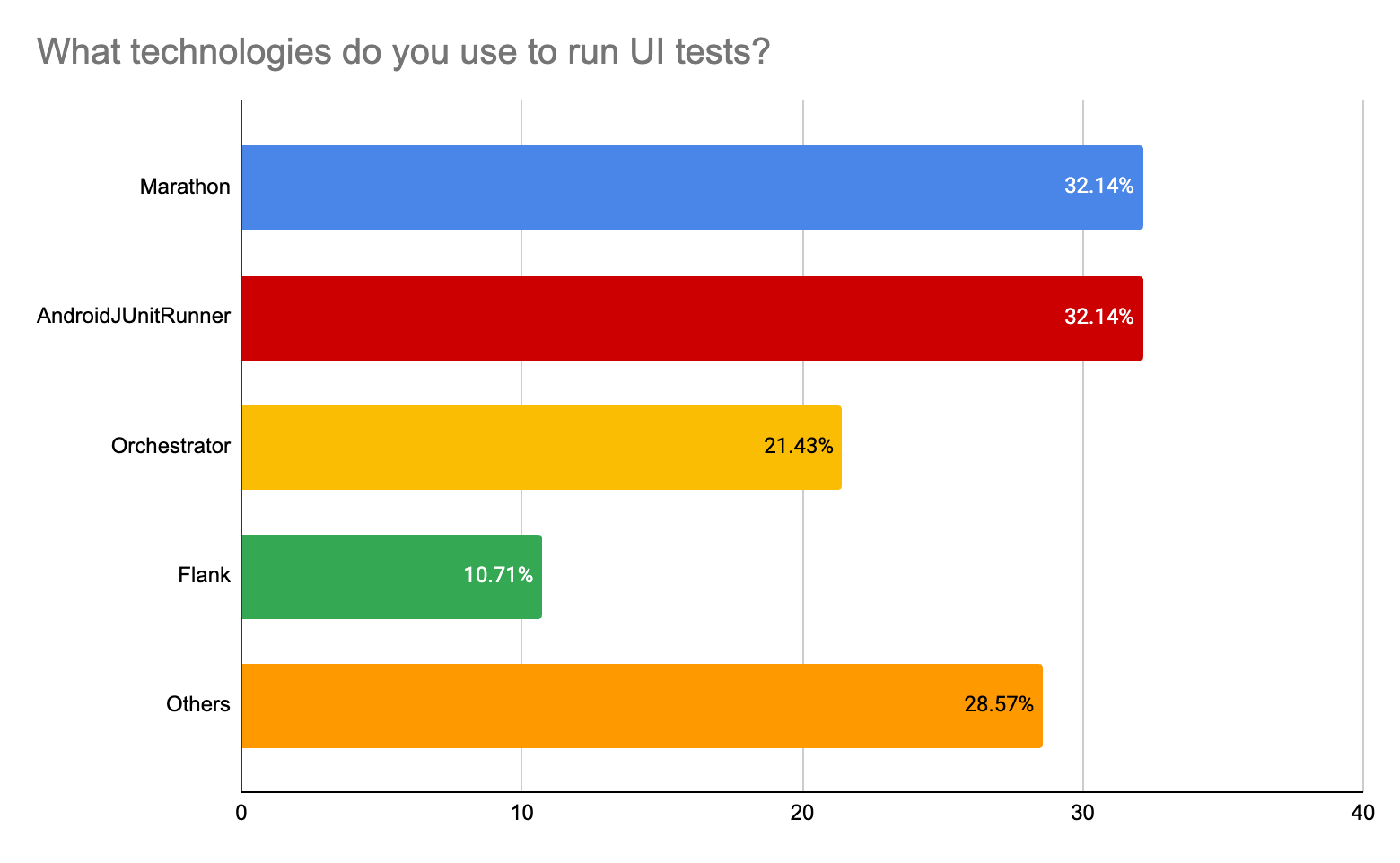
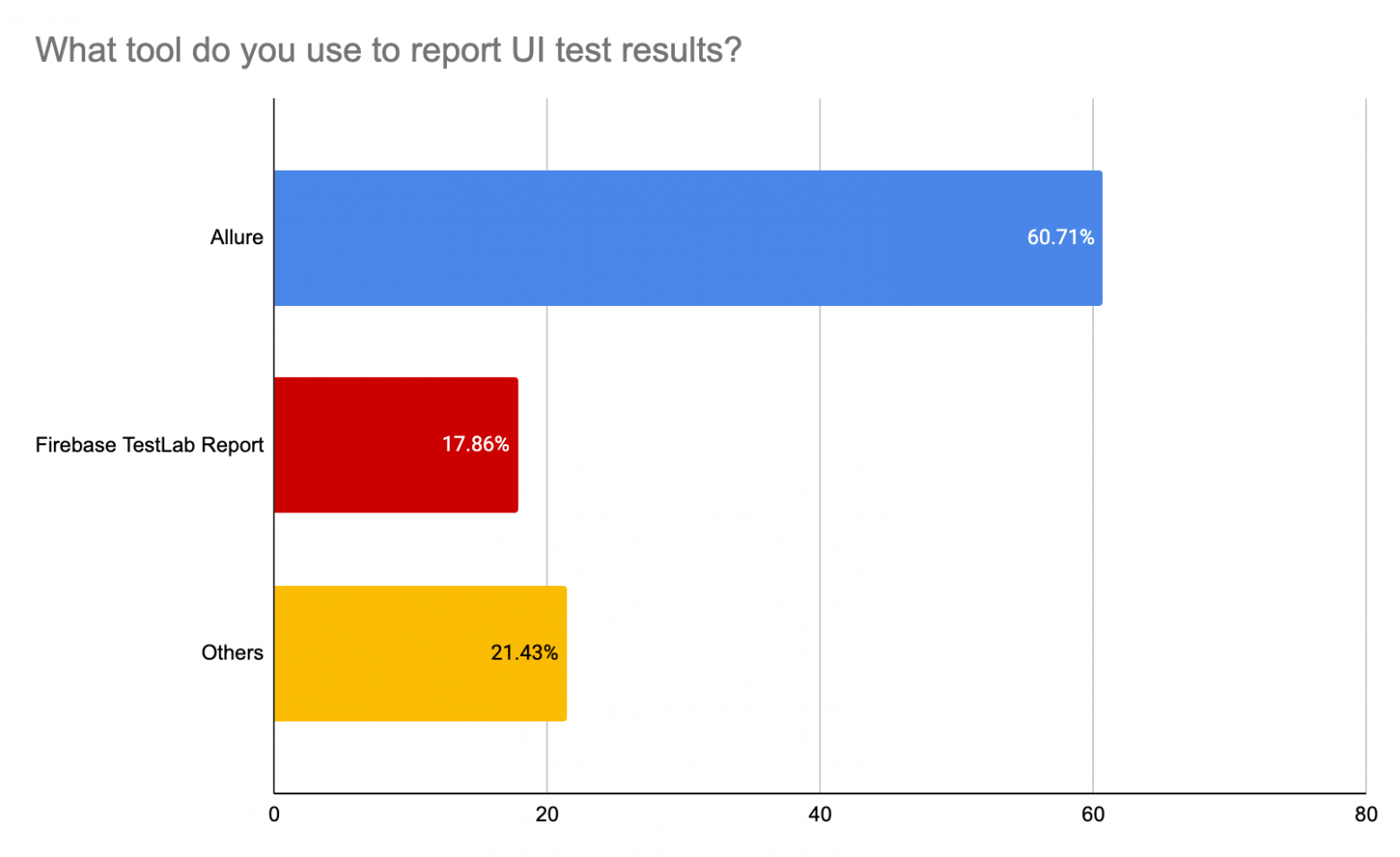
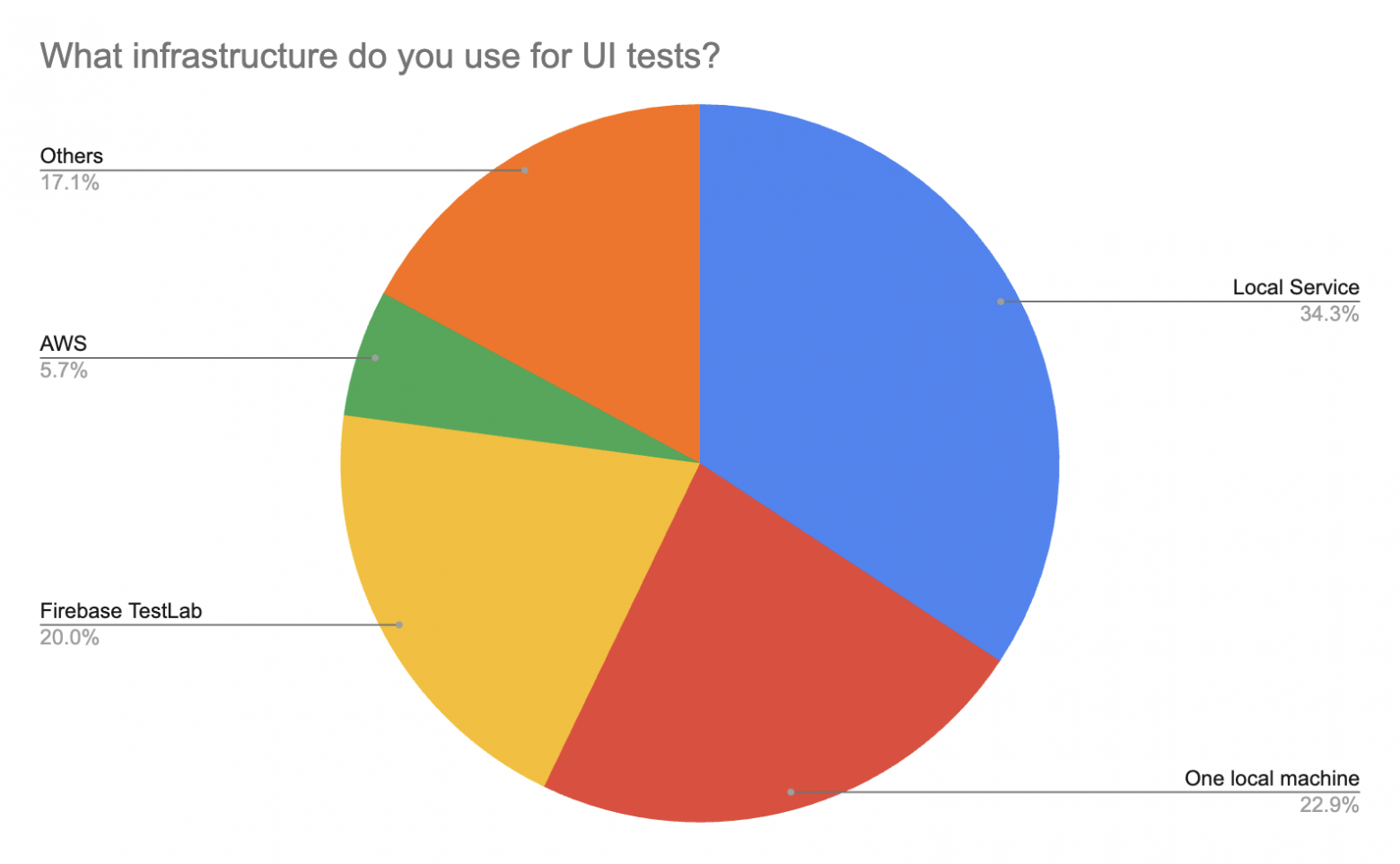
Как мы видим из опросов, православный набор инструментов православного разработчика - это Kaspresso (почти на первом месте) + Marathon + Allure. Высокий процент использования Espresso и UI Automator скорее объясняется периодической необходимостью что-то “докрутить” под себя плюс некоторым процентов кастомных решений, базирующихся на нативных инструментах (Espresso и UI Automator). Кто как организовывает инфраструктуру? Тут результаты довольно интересны:
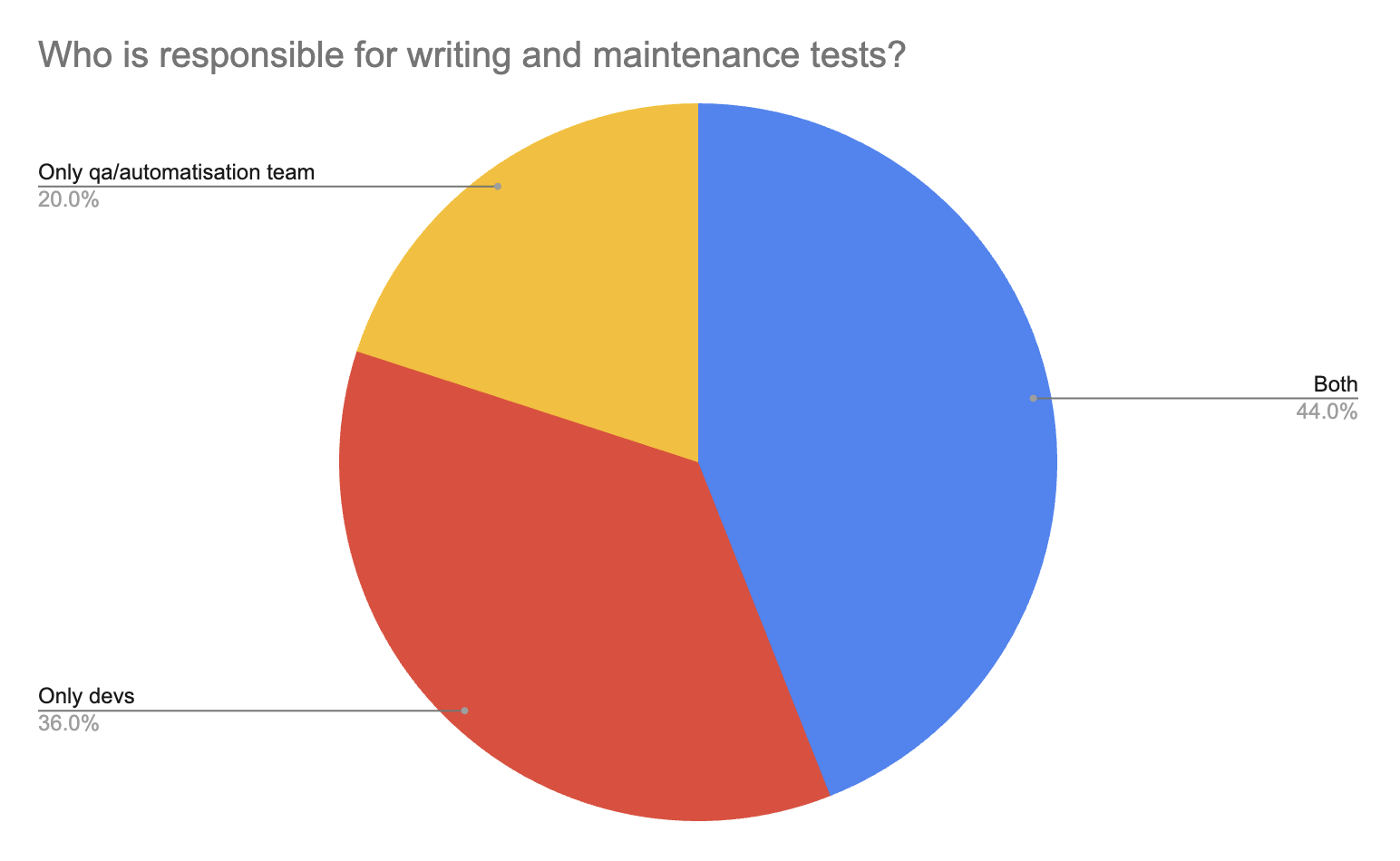
Почти четверть респондентов используют одну локальную машину. Также в лидерах Local Service (несколько серверов, которые оркестрируются Kubernetes или чем-то подобным) и Firebase TestLab. Также люди используют AWS, Google Cloud, OpenStf, билд-агенты и тд. Далее, хотелось немного посмотреть на процессы, а именно, кто отвечает за “написание и поддержку тестов” и “инфраструктуру тестов”:
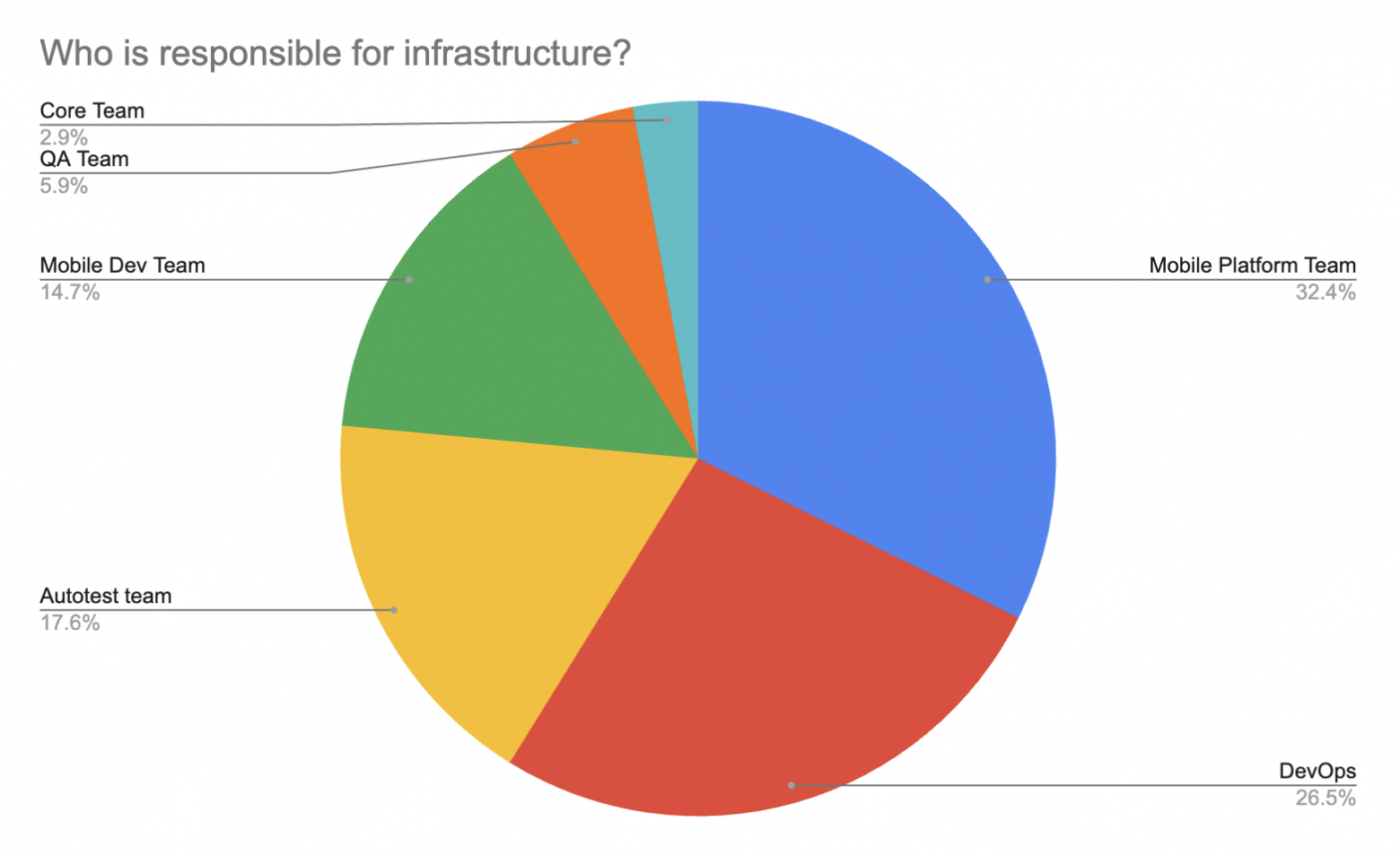
По написанию и поддержке тестов необходимо отметить, что это уже не прерогатива только команды QA или отдельной команды автоматизации, про которую рассказывают легенды. Разработка активно вовлекается в эти процессы, ведь тесты - это и про качество кода, а значит это ответственность и разработчиков. Кроме того совместная работа разработки и тестирования помогает достигать лучших результатов, избегая постоянное перекидывание ответственности. По инфраструктуре тоже можно заметить, что эти вопросы не скидываются только на команду автоматизации, как раньше, а поднимаются на уровень выше и делегируются в основном Mobile Platform Team и DevOps Team. И одним из последних вопросов было, что команды используют или хотели бы использовать для улучшения автотестов (перфоманс, возможности, удобство и тд.). Далее привожу список, отсортированный по популярности:
ВыводыДалее мы с Сергеем приведем свое мнение на счет того, как изменилась ситуацию с автотестами под Android в сравнении с 2020 годом. Повторюсь, это частное мнение, основанное на определенной выборке. Это не полномасштабное исследование, однако, ряд интересных моментов почерпнуть точно можно. Процесс написания автотестов90% опрошенных нами команд используют нативные тесты. Однако, мы не можем утверждать, есть ли тенденция к бОльшему использованию нативных тестов в сравнении с кроссплатформенными решениями. Те, кто только начинает выстраивать автотесты у себя, очень довольны Kaspresso, так как Kaspresso позволяет избегать много боли. Это абсолютно честное мнение без какой-либо доли предвзятости с моей стороны =). Команды же, которые вложили много ресурсов в свои решения, базирующиеся на Espresso и UI Automator, в конечном счете, или доводили свои решения до какого-то приемлемого вида, или постепенно переезжали на другие решения типа Kaspresso, но с оставлением части тестов, написанных на Espresso и UI Automator. Runner + ОтчетыНативные решения типа AndroidJUnitRunner и Orchestrator по-прежнему популярны. Но если вы хотите что-то лучше, то весь выбор сводится по сути только к одному инструменту - Marathon, который активно развивается и по сей день. Единственный “минус” или особенность Marathon - это то, что он никак не покрывает инфраструктурную часть в отличии от, например, Flank, который умеет работать с Firebase TestLab (правда, только с ним и умеет). По отчетам русскоязычная аудитория почти повсеместно использует Allure. Что-то лучше Allure на рынке, честно говоря, не видно. ИнфраструктураКоманды, которые давно в деле, выстроили кастомную систему на основе своих серверов, самостоятельно их оркестрируя и поддерживая. Но в остальном, ситуация с инфраструктурой остается довольно грустной. На рынке так и не наблюдается простого, кастомизируемого и масштабируемого решения. Этим объясняется, что 23% опрошенных гоняют тесты на одной локальной машине. Да, есть Firebase TestLab, но он хорошо подходит для малого количества относительно простых тестов. Когда же тестов становится много, то хочется иметь репорты качественнее, параллелизацию из коробки, просмотр истории с аналитикой, возможность кастомизировать докер-образы (настроить прокси, например) и многое другое. Все это придется как-то настраивать самому. Слышал еще про вот такое решение - emulator.wtf, но ничего не знаю про успешное применение. Из интересного хочу отметить появление TestWise, который мы с Сергеем консультируем. В следующей статье мы хотим провести сравнение всех этих сервисов. ПроцессыРаньше преобладало мнение, что автотесты - это ответственность исключительно команды автотестирования. Такая парадигма могла работать, но скорее приводила к проблемам типа рассинхронизации приложения и тестов, перекидывания ответственности и тд. Сейчас я бы отметил коренной сдвиг в сторону того, что автотесты - это такой же код и такая же необходимая составляющая качества приложения. Разработчики гораздо активнее вовлекаются в процесс, а тесты стараются запускать как можно раньше, то есть на PR. Кроме того, для улучшения стабильности тестов необходимо мокировать работы с бэкендом, а эта работа точно требует активного привлечения разработки. Также, запуск тестов на PR максимально упрощает поиск причины падения тестов, так как скоуп изменений весьма ограничен. ЗаключениеНа этом мы бы хотели попрощаться. Пишите в комментарии ваши вопросы и мысли, с удовольствием подискутируем! |