Что пишут в блогах
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?
- Software Engineering Happiness Index 2025
- От вебинаров до биллинга: что нужно тестировать в EdTech на самом деле
- Штат, гибрид или аутсорс тестирования: честный разбор экономики QA-команд в 2026

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Программирование на C# для тестировщиковНачало: 3 июля 2026
-
Организация автоматизированного тестированияНачало: 3 июля 2026
-
Логи как инструмент тестировщикаНачало: 6 июля 2026
-
Техники локализации плавающих дефектовНачало: 6 июля 2026
-
Charles Proxy как инструмент тестировщикаНачало: 9 июля 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 9 июля 2026
-
Азбука ИТНачало: 9 июля 2026
-
Регулярные выражения в тестированииНачало: 9 июля 2026
-
Python для начинающихНачало: 9 июля 2026
-
Тестирование GraphQL APIНачало: 9 июля 2026
-
Школа для начинающих тестировщиковНачало: 9 июля 2026
-
Программирование на Python для тестировщиковНачало: 10 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
| Настраиваем собственные инструменты: тестирование подсветки кода в IDE |
| 21.04.2025 00:00 |
|
Тестировщики, скорее всего, знакомы с понятием тест-пирамиды: юнит- и компонентные тесты, различные уровни интеграционных тестов, и все остальное. Инструменты и приложения - с открытым или закрытым исходным кодом, коммерческие или для внутреннего использования, - всегда требуют соблюдения специфических правил для корректного и оптимального использования. Командам полезно внедрять в эти инструменты автоматическую валидацию вроде статического анализа кода. Статический анализ кода позволяет тестировать программу, не запуская код. Не путайте с подсветкой синтаксиса, когда подсвечиваются ключевые слова и элементы языка программирования. Техники вроде статического анализа кода помогают убедиться, что созданный инструмент можно использовать целевым образом, особенно если планируется его широкое применение в отрасли. Такие проверки могут выявить проблемы кода на ранних этапах процесса разработки, и даже помочь инженерам разобраться, как работать с этими инструментами. Возможность статически анализировать код особенно важна для разработчиков редакторов кода и IDE (интегрированных сред разработки), а также для тех, кто создает IDE-плагины. Это связано с тем, что создатели языков программирования, тест-фреймворков и т. п. должны внедрять статический анализ кода для его доступности инженерам-пользователям. Однако просто внедрить такие проверки недостаточно. Очень важно протестировать их, чтобы убедиться в их верной работе – они не должны путать пользователей или вводить их в заблуждение, ложно сообщая о правильном коде, как о неправильном (и наоборот). Немного предысторииПрежде чем я начал разрабатывать плагины для JetBrains IDE, я работал тест-автоматизатором. Я писал юнит-тесты для наших фреймворков тест-автоматизации, интеграционных Selenium-тестов и тестов Web UI. Когда меня познакомили с тестированием IDE-плагинов, мне поначалу показалось очевидным, что для ряда фич нужны юнит-тести и имитация объектов. Это было не слишком сложно, но постепенно я осознал, что это перебор. Если у вас есть только молоток – все вокруг становится похожим на гвоздь. Я выяснил, что для такого тестирования есть более подходящие способы. В разделах ниже – больше информации об оптимальном выполнении каждого теста. Разные IDE-платформы – разные возможности тестированияНиже я покажу, как я тестировал подсветку кода в редакторах трех крупных IDE, для которых разрабатывал плагины. У каждой IDE специфические возможности и подходы к тестированию ее функций, поэтому для простоты я перейду от неоптимального решения – юнит-тестирования – к более подходящему, к разновидности визуального тестирования на уровне интеграции. Мой опыт в разработке расширений для Visual Studio и VS Code ограничен (я в основном работаю над плагинами к JetBrains IDE), и, вероятно, есть решения получше, чем приведенные мной. Однако они все же демонстрируют то, о чем я говорил во введении. Пожалуйста, обратите внимание: секции ниже содержат код на трех разных языках - C#, TypeScript и Java, поэтому потребуются некоторые технические знания. Я старался, чтобы код был как можно проще и чище. Итак, начнем с примера. Пример проблемыДопустим, у нас есть простой метод с единственным параметром vararg, в который должно передаваться четное число пар имя-значение. Пример для C#: void SetHeaders(params string[] nameValuePairs) { ... }
Мы хотим подчеркивать имя метода и выводить сообщение, если в него передано нечетное количество аргументов (к примеру, у имени заголовка нет значения). Вызов этого метода, провоцирующий сообщение, может выглядеть так: anObject.SetHeaders("header", "value", "another header");
Посмотрим на пример решения в расширении Visual Studiol Расширения Visual StudioНачну с упрощенного объяснения, как расширения Visual Studio работают с подчеркиванием различных частей документа. Маркировка различных участков редактора при помощи как видимых пользователю, так и скрытых данных, называется тегированием. Когда соответствующие теги видны пользователю, они отображаются с так называемым «волнистым подчеркиванием», вот так:
Волнистое подчеркивание представлено, как класс ErrorTag и его конкретные специфические реализации. Оно несет видимую пользователю информацию – тип ошибки для форматирования, и подсказку (к примеру, сообщение об ошибке) для отображения. Для отображения ErrorTags они должны быть зарегистрированы в редакторе. Это делается при помощи так называемых копий ITagger, с собственным ITagger для каждого типа тегов через метод GetTags(): public IEnumerable<ITagSpan<SquiggleTag>> GetTags(NormalizedSnapshotSpanCollection spans) { ... }
Тип ITagSpan содержит область, в которой тег регистрируется в редакторе, поэтому вы точно знаете, где он будет отображаться. Когда в редакторе произошли изменения, платформа расширений вызывает этот метод с коллекцией областей (участков документа), для которой требуется обновление тегов. Если там содержится что-то вроде конкретной строки, этот метод должен вернуть тегирование для этой строки. Воспользуемся этим методом в качестве субъекта наших тестов. Тестирование данных тегированияМы знаем, что для получения и последующей валидации актуальной информации о тегах надо вызвать ITagger.GetTags(NormalizedSnapshotSpanCollection). Это будет выглядеть примерно так: IList<ITagSpan<IErrorTag>> squiggles = squiggleTagger.GetTags(spanCollection).ToList(); Коллекция областей – это то, где мы можем контролировать участок документа, чьи теги тестируются. Так как, по моему опыту, создать NormalizedSnapshotSpanCollection со всеми зависимостями не так-то просто, я пропущу этот этап. Вызвав getTags(), можно проверить возвращенные данные о волнистом подчеркивании. Мы знаем, что в сниппете кода выше должен быть только один тег – на имени метода. Начнем с его проверки: Assert.That(squiggles, Has.Count.EqualTo(1)); Затем валидируем все данные в коллекции: стартовую позицию, длину подчеркивания, тип ошибки и сообщение об ошибке: Assert.That(squiggles[0].Span.Start.Position, Is.EqualTo(120)); Дальше в тесте будет создание или имитация SpanCollection, которая передается в GetTags(), и другая логика настройки вроде эмуляция документа, чтобы он был не пустым, и некое визуальное отображение местоположения тестируемых тегов. Хорошее ли это решение?Как можно видеть, по сути это юнит-тестирование, и само по себе это не проблема. Но несмотря на то, что цели тестирования тегов мы достигаем, я вижу тут ряд проблем:
Должен подчеркнуть, что для разработки VS-расширений есть куда более продвинутые решения – скажем, проект dotnet/roslyn. Но он, кажется, опирается на ряд более технических компонентов. Думаю, первый пример хорошо демонстрирует изначальный подход к проблеме, и помогает заложить основу для дальнейших примеров. Расширения VS CodeУ VS Code иная концепция и номенклатура подсветки кода (как и многого другого). Примечание: аналогичные концепции использует Language Server Protocol, но их обсуждение выходит за рамки статьи. Подсветка текста в VS Code называется диагностикой. В нее входит следующее:
Идея тут в том, что в ExtensionContext можно зарегистрировать одну или несколько DiagnosticCollections, а затем добавить к ней объекты Diagnostic, зарегистрировав их для определенных файлов текущей рабочей области. Это позволяет отображать коллекции в редакторах. Так как расширения VS Code написаны на TypeScript, код в этой секции тоже написан на этом языке. Итак, представим, что у нас есть функция, анализирующая документ и затем обновляющая вышеупомянутую диагностику проблемами, найденными в нем. export function analyseDocument( Эту функцию нужно зарегистрировать в обработчике событий VS Code (например, для изменения документа), чтобы она вызывалась, когда документ меняется. Когда все готово, можно начинать тестирование. Наивный подход – вызов функции при помощи созданного вручную TextDocument и DiagnosticCollection, и последующая валидация, содержит ли DiagnosticCollection правильные объекты Diagnostic. Однако есть способ проще. Тестирование в копии VS CodeСуществует пакет npm (Node.js Package Manager) @vscode/test-electron, при помощи которого, помимо всего прочего, можно заранее настроить рабочее пространство с папками и файлами, открыть копию VS Code из теста внутри этого пространства и использовать находящиеся в нем документы для тестирования. Так как тест автоматически откроет VS Code с рабочим пространством внутри (благодаря настройке test-electron), наш первый шаг – открытие документа из этого рабочего пространства. Как вариант, можно создать новые документы и на лету наполнить их содержимым, если для ваших тестов это необходимо. const fileUri = await getFileFromWorkspace("IncompleteVarargs.cs");
Здесь getFileFromWorkspace() – служебный метод, который возвращает URI файла для заданного имени файла (IncompleteVarargs.cs) в рабочем пространстве. IncompleteVarargs.cs содержит вызов метода anObject.setHeaders() с нечетным количеством аргументов, который можно использовать для тестирования. В плане открытия документа разница между openTextDocument() и showTextDocument() в том, что первый не показывает новую вкладку редактора, а второй это делает, но вам нужны оба этих метода. Затем можно получить всю диагностику рабочего пространства через API VS Code, и выбрать диагностику для тестируемого файла. //Массив пар Uri и Diagnostic[] Хорошее ли это решение?Теперь это очень похоже на решение для Visual Studio. Однако оно может быть сложнее или тяжелее в плане запроса диагностики через множественную индексацию массивов. Однако при использовании глубоких проверок равенства объектов можно сильно улучшить простоту и читабельность теста В целом могу сказать почти то же самое, что и про пример Visual Studio. Однако тут удобнее то, что можно правильно настроить реальное рабочее пространство VS Code и проводить тестирование внутри него. К тому же у вас есть доступ к другой функциональности VS Code. В результате можно проверить функциональность расширения с точки зрения конечного пользователя. Есть ли альтернатива?Собирая материал для статьи, я нашел проект stylelint/vscode-stylelint в GitHub – он использует возможности тестирования моментальных снимков библиотеки Jest. Это здорово подходит для плавного перехода к возможностям следующей IDE. Цитирую с сайта Jest: «Типичный тест-сценарий для моментального снимка отрисовывает компонент UI, делает снимок, а затем сравнивает его с эталонным снимком, который хранится в тесте. Тест упадет, если два снимка не совпадают: или изменение не запланировано, или нужно обновить эталон под новую версию компонента». Код теста получает объекты Diagnostic из документа, а затем проводит валидацию снимков. const diagnostics = await waitForDiagnostics(document); Валидация выполняется на основании снимка, в котором хранятся ожидаемые значения свойств объекта Diagnostic, например, так (точный пример для вышеупомянутого снимка): Object {
Мне куда больше нравится это решение, так как тут:
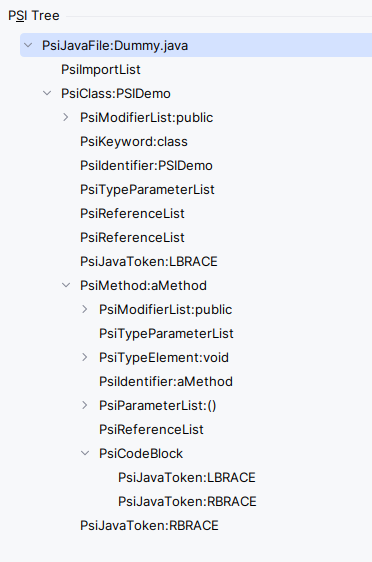
Однако такой подход не позволяет точно пронаблюдать, где именно в файле применится диагностика. Для этого мы перейдем к еще одной IDE и изучим другой способ тестирования снимков. Платформа IntelliJУ IntelliJ свои собственные уникальные концепции подсветки синтаксиса и ошибок. Одна из них называется Inspections и создана для статического анализа кода. Я продемонстрирую ее работу далее. Интерфейс структуры программы (PSI)Inspections и многие другие опции платформы используют так называемый PSI (Program Structure Interface) для работы с элементами кода в редакторе. Цитирую из документации IntelliJ Platform Plugin SDK: "Файл PSI (Program Structure Interface) – это корень структуры, описывающей содержимое файла как иерархию элементов в определенном языке программирования». Это можно представить, как абстрактную AST (Abstract Syntax Tree), которая генерируется для каждого файла на основании грамматических определений соответствующего языка. Это похоже на работу с Reflections API в Java, и вы можете запрашивать классы, методы, конструкторы, и т. д. К примеру, этот код Java: public class PSIDemo {
даст вот такое дерево PSI:
InspectionsДля внедрения инспекции нужно внедрить класс, расширяющий базовый класс LocalInspectionsTool и один из его методов buildVisitor():
class IncompleteVarargsInspection extends LocalInspectionTool {
Для тестирования мы нацелимся на вышеупомянутый метод buildVisitor() и этот класс инспекции в целом. Тестирование в редакторе в памятиНесмотря на то, что платформа IntelliJ поддерживает UI-тестирование фич IDE через своего собственного IntelliJ UI Test Robot, инспекции не тестируются в реальной копии IDE или реальном редакторе. Но для полноценного тестирования инспекций это и не нужно. К тому же в случае с инспекциями и другими опциями платформы, визуально отображающимися в редакторе, результаты тестов встраиваются в тестируемые исходные файлы с разметкой в стиле XML, примерно так: <warning descr="expected warning message">the code to be highlighted</warning> Код тестирования исходного примера будет выглядеть примерно так: @Test Тест выполняет следующие шаги:
testHighlighting(/*checkWarnings*/ true, /*checkInfos*/ false, /*checkWeakWarnings*/ true); Хорошее ли это решение?Я думаю, что среди трех IDE-решений это, находящееся на уровне интеграционного тестирования, лучше всего подходит для тестирования подсветки, и лично мне оно больше всего нравится – вот почему:
Выбор за вамиНадеюсь, вы нашли в этой статье что-то интересное для себя вне зависимости от того, есть ли у вас опыт тестирования IDE-фич. Возможно, для технологий и техник, упомянутых в статье, существуют решения поновее и поудобнее. Вне зависимости от возможностей каждой IDE или соответствующих утилит, эти примеры хорошо демонстрируют, что определенные уровни тестирования (в этом случае интеграционный / end-to-end) подходят для тестирования определенных решений лучше, чем юнит-тесты. Выбирайте с умом. |