




Программистам требуется судить о том, насколько дорого обходится тестирование конкретной системы, будь то модульное, интеграционное или функциональное тестирование. Каждый последующий из этих этапов в некотором смысле «дороже», чем предыдущий.
В качестве приближения такая модель вполне надёжна, но она начинает сбоить по мере того, как проявляется всё больше нюансов, а именно: что мы тестируем, и как результаты теста выводятся пользователю:
Бывают медленные модульные тесты.
Бывают быстрые функциональные тесты
Сколько я работаю в Google, столько там применяется концепция размер теста (развёрнутое объяснение). Размер теста интересен потому, что по типу теста можно лишь отчасти определить, во что этот тест нам обойдётся. Нам же интереснее, чтобы по размеру тестов можно было приобретать качественное представление о различных свойствах, и уже на основе этой информации корректировать размер теста. Иными словами, это как раз тот случай, когда размер имеет значение. Ниже перечислю те компоненты системы, качественные аспекты которых будут интересовать нас в этой статье:
Доступ к сети;
База данных;
Доступ к файловой системе;
Многопоточность.
Обдумывая всю эту идею о размерах тестов, я, в частности, начал понимать, что для хорошо спроектированного и протестированного софта характерна следующая пирамидальная структура тестов. Пирамида демонстрирует, сколько именно тестов какой категории было использовано. Такая система тестового покрытия состоит из множества мелких тестов, дополняемых не столь многочисленными средними тестами и увенчивается считанными крупными (или даже колоссальными) тестами, проверяющими работоспособность всей программы:
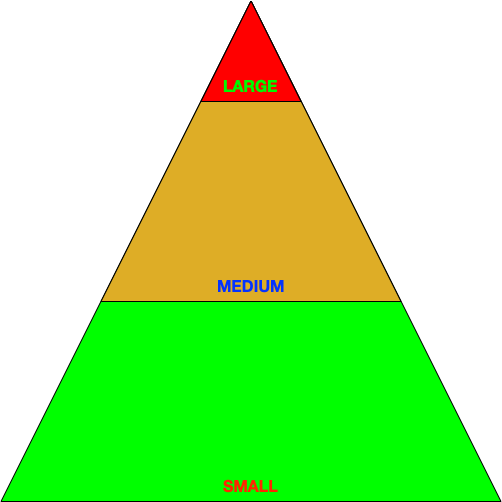
Думаю, такая стратификация очень хорошо работает на практике — по крайней мере, к ней основательно приучают разработчиков в масштабе всей компании Google. Тем не менее, давно пора пересмотреть эти критерии, внести в них поправки и, возможно, даже расширить. Почему? Потому, что бывают:
Тесты, выполняемые по сети и при этом более быстрые, чем другие тесты, также выполняемые в этой сети.
Тесты, выполняемые в базе данных, и при этом более быстрые, чем другие тесты, также выполняемые в этой базе данных.
Более того, берусь утверждать, что некоторые работающие по сети тесты выполняются настолько быстро, что их легко спутать с небольшими модульными тестами, при которых сеть не используется. Аналогичная ситуация складывается в случае с базой данных.
Думаю, вы понимаете, к чему я клоню: модель — это всегда лишь модель, и применимость её ограничена. Нет, не сочтите это за колкость в адрес размеров тестов. Исходно, когда эта идея у меня только появилась, приведённые тесты служили лакмусовой бумажкой, и в них заложена достаточно качественная эвристика. Но мне постоянно казалось, что некоторые рекомендации не подтверждаются на практике, и их желательно модернизировать.
❯ Существующие критерии
Итак, в каких же случаях имеющихся критериев недостаточно, и как нам их поправить? Давайте разберём их по очереди.
Доступ к сети
Не так интересно, передаём ли мы в ходе теста информацию по сети, как…
К чему именно мы обращаемся;
Где находится сущность, к которой обращается тест;
Насколько доступна сущность, к которой мы хотим обратиться, и насколько надёжна связь при таком обращении.
Чтобы пояснить эту мысль, отмечу: вышеприведённые свойства значительно отличаются у автоматизированного теста, если мы по HTTP обращаемся к…
Сайту https://www.google.com;
Веб-серверу в локальном интернете;
Веб-серверу, который в результате этого теста должен запустить сопутствующий подпроцесс;
Веб-серверу, запускаемому через слушатель в том же процессе, который является локальным относительно теста.
Примечание: выше я упоминаю HTTP только в качестве фигуры речи; всё вышеописанное в той же степени применимо и к другим протоколам.
Рассмотрим в этом ракурсе package httptest с его API httptest.NewServer. Этот API поднимает локальный HTTP-сервер через локальное петлевое соединение, чтобы выполнять экземпляры http.Handler с реальным http.Client. Это определённо соответствует тому, как должен выполняться критерий обращения к сети — в зависимости от контекста использования. То есть, при модульном тестировании http.Handler должен выполняться сам по себе, а при интеграционном должна правильно работать вся тестируемая система, серверная часть которой основана на протоколе HTTP. Но разве вы автоматически сочли бы средними или крупными те тесты, в которых используется package httptest? Я — нет.
(Используем) базу данных
Обращения к базе данных во многом подобны обращениям к ресурсам по сети. Но не так интересно, зависит ли тест от обращений к базе данных, и оформлено ли это в качестве булева условия; интересно вот что:
Где именно находится та база данных, к которой он обращается (напр., внутри процесса, как в случае с SQLite, локально, как в случае с Postgres, удалённо, как в случае с MySQL, т. д.);
Каким образом настраивается и управляется база данных (напр., через тест, вспомогательную функцию, которую придётся отдельно писать программисту или инженеру по базам данных, через автоматизацию и оркестрацию в продакшене, т. д.);
В каком именно окружении будет работать база данных, как это будет выглядеть с точки зрения предметной области (эфемерный тест, песочница, уровень QA, продакшен, т. д.);
Как вообще будет организована настройка базы данных (напр., программно или вручную).
Рассмотрев все эти различные критерии, легко заметить, что в каждом из них есть градация. Например, можно сказать, что внутрипроцессная база данных, которую требуется настраивать вручную, обойдётся вам примерно в ту же цену, что и облачная база данных, которая может настраиваться автоматически.
Если вам повезёт обзавестись такой базой данных, которая будет расположена локально и при этом герметична с точки зрения теста (то есть, работать с ней будем при помощи вспомогательной тестовой функции, то зависимость от базы данных обойдётся вам настолько дёшево, что вы смело сможете её игнорировать. Это особенно актуально, например, в том случае, если можно воспользоваться SQLite в качестве базы-дублёра.
Примечание: в зависимости от того, какова природа конкретного теста, не все движки баз данных взаимозаменяемы. Это большая отдельная тема.
Размышляя в таком духе, я пришёл к выводу, что многие программы отличаются достаточной гибкостью, чтобы пользователь мог указывать альтернативные базы данных (в терминологии ODBC — «коннекторы» или «драйверы»), в период конфигурации или во время выполнения.
Проводя тесты на реальной базе данных, а, например, не на тестовом двойнике или на уровне абстрагирования базы данных (DAL) вы выигрываете, так как в таком случае тесты получатся более достоверными, чем без применения базы данных.
Обращения к файловой системе
Как в таком случае рассматривать обращения к файловой системе? Что, догадываетесь, что я напишу дальше? Правильно — зависит от ситуации! Сами обращения к файловой системе не так интересны, как к чему именно мы обращаемся, а именно …
Каков этот тест относительно всей системы — локальный или глобальный;
Для чтения или для записи;
Быстрый или медленный этот тест по своей природе.
Работая с API вспомогательных тестовых функций, вообще не составляет труда создавать иерархии файловых систем, локальные на уровне теста, очищаемые сразу после того, как тест будет выполнен. Честно говоря, для этого требуется, чтобы тестируемый код хорошо поддавался заданию пути, но, вероятно, тест изначально должен быть приспособлен к работе с разными путями, а не только с элементами, жёстко запрограммированными в коде приложения.
Использование многопоточности
Поверьте, конкурентность и параллелизм – темы всегда непростые, и особенно при тестировании. Но к этой дискуссии хочется добавить, что всякая обеспокоенность по поводу многопоточности меркнет перед вопросом о том, синхронно ли работает тестируемая система на уровне её публичного API. Особенно этот вопрос актуален, когда приходится беспокоиться о временах жизни сущностей, выполняющихся независимо друг от друга. При работе с синхронными API можно многое упростить.
Если вы работаете с системой, для которой не свойственна такая синхронность, то иногда всё можно организовать эргономичнее, например, предусмотрев вспомогательную тестовую функцию в качестве абстракции для выполнения типичных операций данного теста:
// Команда flush сообщает тестируемой системе, что нужно завершить все операции с хранилищем данных, которые пока ожидают завершения. Функция
// блокируется, пока тестируемая система не завершит эту операцию.
func flush(ctx context.Context, t *testing.T, sutAddr string) {
t.Helper()
req := http.NewRequestWithContext(ctx, "GET", sutAddr + "/-/flush", http.NoBody)
client := &http.Client{Transport: new(http.Transport)}
if _, err := client.Do(req); err != nil {
t.Fatalf("flushing SUT: %v", err)
}
}
// addPurchaseRecord отправляет в хранилище данных запись о той покупке, которую
// совершил пользователь.
func addPurchaseRecord(ctx context.Context, t *testing.T, sutAddr string, p store.Purchase) {
t.Helper()
// пропуск: отправить покупку в тестируемую систему
flush(ctx, t, sutAddr)
}Обратите внимание: flush и addPurchaseRecord работают синхронно (как предполагается) через процедуру flush. Пользуясь такой техникой, мы сильно упрощаем процесс рассуждения о наших тестах.
❯ Предлагаемые новые критерии
Итак, можете ли вы предложить какие-либо дополнительные критерии сверх оригинальных? Я хотел бы добавить некоторые (достаточно абстрактные) рекомендации по поводу новых тем.
Длительность первичной настройки
В исходной документации по размеру тестов значительное внимание уделено тому, сколько времени можно позволить уделить на выполнение тестового набора — чтобы укладываться в дедлайны. Речь о выполнении всего набора тестов, а не об отдельных тестовых сценариях внутри него. Для первого шага отлично, но в ретроспективе я бы отметил, что такая общая длительность выполнения всего тестового набора — это ещё не всё.
Напротив, я бы вернулся к вопросу о длительности отдельных тестовых сценариев и о том, какую роль они играют в обустройстве тестов. Опять же, давайте сравним две реализации тестовых вспомогательных функций для баз данных:
Первая: создаёт локальную базу данных SQLite в известном состоянии.
Вторая: локально запускает MySQL, и состояние базы данных при этом известно.
В остальном процессы подготовки одинаковы: создаётся база данных в известном состоянии, а если требуется — выполняется и дополнительная подготовка. Интуиция подсказывает, что вариант с SQLite будет дешевле, чем с MySQL: никакой эквилибристики с подпроцессами, никакого сервера, т. д. Этот случай приведён только в качестве иллюстрации, а не потому, что я хочу демонизировать MySQL.
Итак, предположу, что следует учитывать, сколько времени требуется на настройку зависимостей при подготовке теста. Это особенно важно в наше время, когда существуют программы для индивидуального прогона тестов (напр., go test -run=<name>) при помощи выражений-фильтров. Весь тестовый набор в таком случае выполнять не требуется. Подробнее об этом здесь.
Вот какой вывод из этого следует: если тестовая конфигурация максимально близка к независимому выполнению всех необходимых тестов, то никому не захочется нести дополнительные издержки на подготовку тех тестов, что не нужны для решения задачи. Причём, такая минимизация издержек на подготовку особенно ощутима, если подробно разбираться в каждом тестовом случае, выясняя, почему что-либо пошло неправильно (исправлять регрессию). Это важнейший аспект, связанный с удобством поддержки.
Кстати, а вам интересно, что я думаю о таких API как @BeforeClass и @BeforeAll? Если коротко — они вынесли мозг целому поколению разработчиков.
Чем меньше времени требуется на подготовку теста, тем меньше сам тест.
Цена ресурсов
Цена ресурсов — ещё одно интересное измерение этой проблемы, она дополняет проблему длительности подготовки. Основная идея такова: сами тестовые случаи, а также их зависимости могут требовать разного количества физических (вычислительных) ресурсов. Сами представьте, сколько оперативной памяти потребуется на эксплуатацию локального экземпляра MySQL по сравнению с SQLite в одном и том же тестовом случае). Машинный ресурс на эксплуатацию этой MySQL нужно где-то взять, поэтому кто-то должен за него заплатить!
Этот момент особенно важен в случае функциональных тестов.
Ещё один важный аспект, который важно учитывать в данном случае — это облачные вычислительные ресурсы (например, тест создаёт эфемерный продакшен-кластер из нескольких бэкендов). В сущности, здесь мы переформулируем предыдущий тезис.
Итак, чем меньше ресурсов требуется на выполнение теста, тем меньше сам тест.
Фундаментальная герметичность
Думаю, из вышесказанного понятно следующее: я считаю, что при современном автоматизированном тестировании относительно легко обеспечить герметичность тестов. Вторая ключевая возможность — это код, в который можно вручную внедрять зависимости. Например, можно указывать, какая иерархия каталогов должна использоваться в системе, указать адрес конечной точки для HTTP-сервера, который будет задан в качестве зависимости для тестируемой системы, т. д.).
Чем более герметичны сам тест, его вспомогательная функция или его зависимости, тем более компактный тест мы можем себе позволить.
❯ Заключение
Прочитав всё вышесказанное, вы могли подумать, что меня интересует только скорость. Нет, не только скорость меня волнует, но с точки зрения читателя скорость настолько ощутима, что к ней легко апеллировать. На самом деле (и это касается возможностей, предоставляемых многими современными API), слишком сложно писать тесты, в которых использовалась бы и сеть, и база данных, и что-нибудь ещё, и при этом тесты оставались быстрыми, надёжными и детерминированными.
Также вы могли найти интересным мой стиль (когда я привязываю аргументацию к рекомендациям по стилистике тестов) и попробовать высказываться таким образом и о языках программирования. Я не случайно так поступил: с какой бы системой мне ни приходилось иметь дело, с ней все обращаются по-своему, и ожидания от этой системы тоже у всех разные. Вся философия практиков этим пронизана. Думаю, в таком ключе было бы интересно поговорить о Go, поскольку многие признают, насколько этот язык — совершенно неслучайно — отличается от экосистемы к экосистеме. Представьте на минутку, если бы API вспомогательной тестовой функции был нативной функцией. И здесь мы ещё не учитываем, насколько проще при этом было бы создавать тестовые двойники.
Надеюсь, я помог вам увидеть в новом свете тесты, которые вы пишете для ваших программ. Глоссарий тестирования очень богат, но, увы, настолько же непоследователен, если применять его на практике. В любом случае, рекомендую вам оценивать тесты как качественно, так и количественно, а не следовать жёстким догмам.
Удачи с тестированием!