Что пишут в блогах
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?
- Software Engineering Happiness Index 2025
- От вебинаров до биллинга: что нужно тестировать в EdTech на самом деле
- Штат, гибрид или аутсорс тестирования: честный разбор экономики QA-команд в 2026
- Как нагрузочное тестирование защищает бизнес от убытков?
- Исследовательское тестирование и UX‑аудит для интернет-магазина
- Юзабилити‑тестирование без розовых очков: почему идеальный функционал не спасёт от провала?
- А ваши тестировщики защищают ваш продукт и компанию от миллионных штрафов?
- TechWriter Days 3. Как это было
- Ричард Румельт. Взлом стратегии.

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 16 июня 2026
-
Автоматизация тестирования REST API на JavaНачало: 17 июня 2026
-
Автоматизация тестирования REST API на PythonНачало: 17 июня 2026
-
Тестирование безопасностиНачало: 17 июня 2026
-
Тестирование мобильных приложений 2.0Начало: 17 июня 2026
-
Python для начинающихНачало: 18 июня 2026
-
Азбука ИТНачало: 18 июня 2026
-
Инженер по тестированию программного обеспеченияНачало: 18 июня 2026
-
Автоматизация функционального тестированияНачало: 19 июня 2026
-
Школа тест-менеджеров v. 2.0Начало: 24 июня 2026
-
Школа для начинающих тестировщиковНачало: 25 июня 2026
-
Тестирование веб-приложений 2.0Начало: 26 июня 2026
-
Тестирование REST APIНачало: 29 июня 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 29 июня 2026
-
Школа Тест-АналитикаНачало: 1 июля 2026
-
Применение ChatGPT в тестированииНачало: 2 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 2 июля 2026
-
Git: инструменты тестировщикаНачало: 2 июля 2026
-
SQL: Инструменты тестировщикаНачало: 2 июля 2026
-
Docker: инструменты тестировщикаНачало: 2 июля 2026
-
Bash: инструменты тестировщикаНачало: 2 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 2 июля 2026
-
Организация автоматизированного тестированияНачало: 3 июля 2026
-
Программирование на C# для тестировщиковНачало: 3 июля 2026
-
Логи как инструмент тестировщикаНачало: 6 июля 2026
-
Техники локализации плавающих дефектовНачало: 6 июля 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 9 июля 2026
-
Регулярные выражения в тестированииНачало: 9 июля 2026
-
Charles Proxy как инструмент тестировщикаНачало: 9 июля 2026
-
Тестирование GraphQL APIНачало: 9 июля 2026
-
Программирование на Python для тестировщиковНачало: 10 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
| Особенности визуального тестирования интерфейсов |
| 27.02.2019 00:00 |
|
Идея тестировать вёрстку сравнением изображений не нова: сохраняем эталон, вносим изменения в вёрстку, сравниваем новое изображение с сохранённым ранее. Казалось бы, всё просто. Но на практике возникает достаточно большое количество подводных камней.
Антон Усманский, ведущий разработчик инструментов визуального тестирования Gemini и Hermione, на конференции Heisenbug 2018 Moscow выступил с докладом об особенностях этого подхода. А теперь мы публикуем текстовую версию его доклада (для тех, кому удобнее видео, также прикладываем видеозапись).
Я руковожу группой разработки инфраструктуры поисковых интерфейсов в Яндексе. В сфере деятельности моей команды — разработка инструментов тестирования (в частности, визуального), их внедрение и поддержка. Я ведущий разработчик Gemini (собственно, инструмент визуального тестирования) и Hermione (скажем так, инструмент следующего поколения, более общего назначения, умеющий выполнять assert скриншотами).
В докладе я поделюсь опытом, полученным при разработке и внедрении этих инструментов.
Для начала скажу, чего не будет в статье: ни пошаговой инструкции по настройке инфраструктуры в своём проекте, ни сравнения инструментов между собой.
Что же будет? Краткое описание того, как в целом работают инструменты визуального тестирования (в минимальном объёме, необходимом для лучшего понимания основной части), а также описание граблей, по которым мы походили в процессе внедрения инструментов, и, естественно, описание путей обхода этих граблей. Заглянем под капот некоторых инструментов и рассмотрим алгоритмы сравнения изображений.
На протяжении всей статьи будут примеры из конфигурации Hermione — исключительно в качестве визуализации того, о чём буду говорить. Надеюсь, эти отсылки послужат «якорями», которые позволят вам в будущем вернуться к более подробному изучению той или иной темы или обратят ваше внимание на то, на что нужно смотреть при выборе инструментов тестирования.
Начну с этого цвета. Это цвет диффа: большинство инструментов сравнения изображений подсвечивают им отличающиеся пиксели.
У меня он ассоциируется с проблемами, с ощущением, что мне предстоит увлекательное исследование из области применения инструментов, которые я разрабатываю.
Казалось бы, найденный дифф — это хорошо: инструмент справляется со своей задачей. Однако я сам не пишу тесты на вёрстку, а разрабатываю инструменты для них. И я редко анализирую результаты прогонов тестов, когда всё идёт по плану: разработчик запустил тесты, увидел дифф, вспомнил: «Я ж там забыл что-то поправить!», поправил, запустил опять, у него тесты прошли. Мне на анализ попадают случаи, когда что-то пошло не так, и разработчик видит какой-нибудь очень странный дифф. Например, выше не просто пурпурный прямоугольник, а дифф. Позвольте пока сохранить интригу, к этому мы ещё вернёмся. А сейчас немного о том, как в целом устроены инструменты визуального тестирования.
Автоматизация визуального тестированияНачнём мы немного издалека и поговорим об автоматизации в целом.
Что представляет собой ручной тест в контексте тестирования интерфейсов? У нас есть сайт, мы открываем его страницу, выполняем набор действий, приводящих её в определённое состояние (которое и планируем протестировать), и сверяем результат с нашим представлением о том, каким он должен быть.
И кажется, что это довольно просто автоматизируется, но важно помнить, что автоматизация никогда не будет полной.
Самый «ручной» вариант из возможных: взять бумажный блокнот со сценариями, открыть два окна (в одном тестируемая бета, в другом продакшн), записывать результаты в тот же блокнот.
Можно сокращать эту ручную работу, допустим, сервисом, где два iFrame (prod, beta), список тестируемых сценариев с чекерами, поле ввода, возможность снять скриншоты и сразу оформить отчёт.
Можно пойти дальше и автоматизировать шаги, приводящие страницу в тестируемое состояние (тот же Selenium).
А можно даже снимать скриншоты, сравнивать и отдавать человеку на анализ уже только отличающийся.
Но полной заменой ручной работы на автоматическую не будет. Одна ручная работа будет заменяться другой, пусть и в меньшем объёме.
В автоматизации визуального тестирования у нас два типа ручной работы: при написании поддержки тестов и при анализе каждого прогона тестов. Опять-таки, их баланс можно смещать. То, о чём я сегодня говорю, преследует цель смещения в сторону ручной работы при написании и поддержке тестов. Так как мы гоняем тесты чаще, чем пишем, то хотим быстрее анализировать.
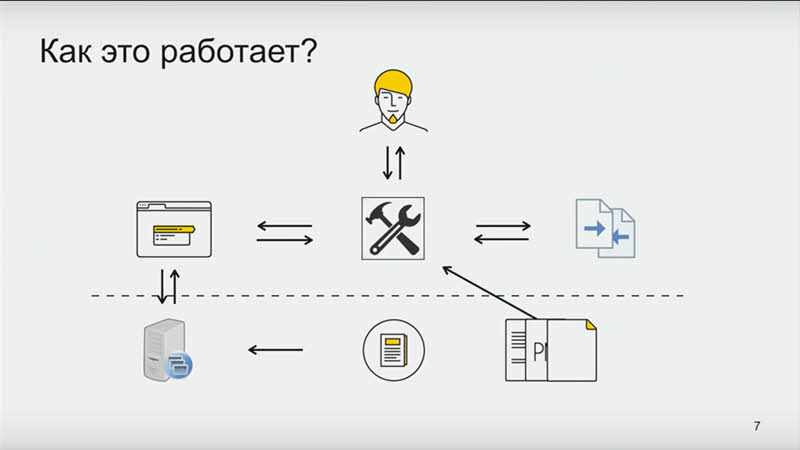
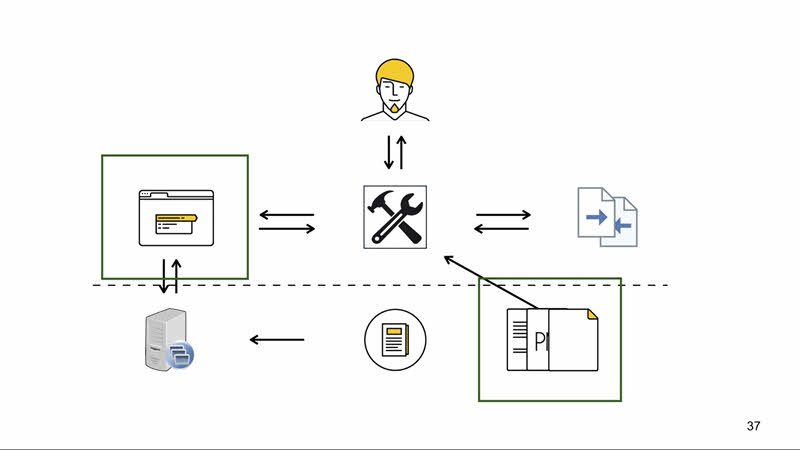
Как это работает? Есть исходники проекта. Мы хотим протестировать его с инструментом визуального тестирования, выполняющим тестовые сценарии. Чаще всего они лежат там же, где исходники, и версионируются вместе с ними. Инструмент парсит тестовые сценарии, а потом для их запуска открывает браузер (хоть браузер у вас на машине, хоть headless-браузер, хоть браузер облаке Selenium).
Чтобы открыть страницу для тестирования, нужен сервер, который эту страницу отдаст. В самом простом случае он отдаёт заранее скомпилированный статический HTML. Или это может быть бета в облаке.
В итоге инструмент открывает страницу и выполняет ранее считанные инструкции, переводя их в команды для браузера (используя, например, протокол WebDriver). Когда страница приведена в тестируемое состояние, снимает скриншот. Со скриншотом возможны дополнительные манипуляции: можно вырезать тестируемый блок, склеить блок из нескольких скриншотов, что-нибудь закрасить, нарисовать неприличное слово — неважно.
У нас есть текущее изображение, и нам нужен эталон. Чаще всего он размещается и версионируется вместе с исходниками и тестовыми сценариями, а сохраняется туда тем же инструментом, запущенным ранее в режиме сохранения эталонов. Теперь нам нужно сравнить текущее изображение с эталоном: мы отдаём их в библиотеку, умеющую построить понятный для человека дифф.
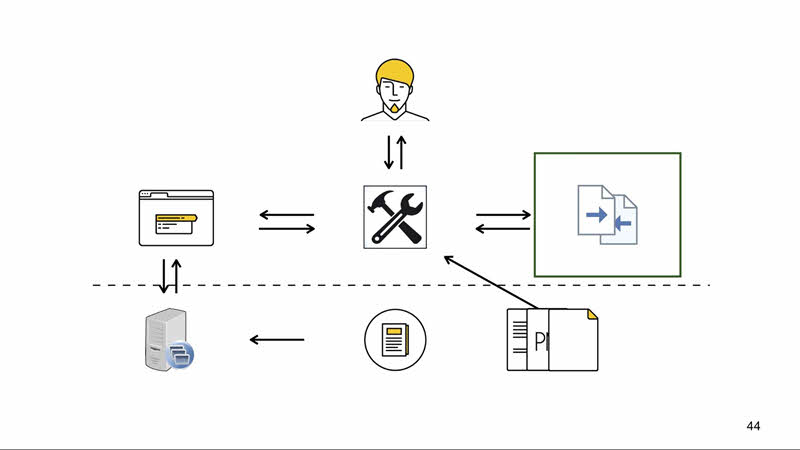
Зачастую у вас будет ещё конфигурационный файл для инструмента. Там могут быть настройки браузера для запуска, настройки точности сравнения изображений и тому подобное. На иллюстрации ниже пунктирной черты — входные данные, которые нужно предоставить инструменту для работы, а выше то, что предоставляет инструмент.
И в зависимости от используемого инструмента вы получаете тот или иной набор. Можно получить сразу всё, можно собрать по частям, как конструктор.
Например, уже не поддерживаемый PhantomCSS предоставляет весь набор: браузер — Phantom.js, библиотека сравнения изображений — Resemble.js. Backstop.js предлагает тот же набор, но умеет работать с Headless Chrome.
Есть инструменты, предоставляющие эту функциональность как сервис: вы регистрируетесь, выполняете набор тестов, имеете возможность посмотреть на отчёты, что-то подредактировать, сохранить эталон. Но зачастую, начиная с какого-то объёма выполняемых тестов, эти сервисы становятся платными. Так, например, работает Applitools.
А есть инструменты, не включающие в себя браузер и ожидающие адрес Selenium как входной параметр. Так, например, работают наши Gemini и Hermione, которые по сути являются test runner’ами и умеют выполнять assert скриншотами. В общем, это такая достаточно грубая схема работы практически любого инструмента визуального тестирования. И чтобы эта инфраструктура работала корректно, приходится вносить изменения и поддерживать все запчасти этой системы.
Браузеры
Позвольте представить хит-парад проблемности браузеров (с точки зрения автоматизации тестирования в них):
Самый удобный и беспроблемный — Headless Chrome. Он просто создан для тестирования: есть даже режимы, отсутствующие в классической версии, упрощающие работу инструментов автоматического тестирования. И если у вас нет весомых причин тестировать в других браузерах, я бы рекомендовал ниже не спускаться.
На следующей ступеньке — самые распространённые браузеры, которые можно поднять в Linux и в дальнейшем завернуть в контейнеры. Это Firefox, Chrome, Яндекс.Браузер, Opera, ну и какие-нибудь другие.
Чуть больше телодвижений понадобится, чтобы поднять мобильные версии этих браузеров в Android и, возможно, тоже в контейнере. Здесь уже приходится использовать дополнительное ПО — Appium, который умеет взаимодействовать с браузером, поднятым, например, в эмуляторе Android.
На предпоследнем месте — браузеры, которые приходится поднимать в других ОС: это IE, Edge, Safari. Здесь начинаются нюансы с лицензированием в этих ОС, и далеко не всё в этих браузерах работает так, как ожидается. Например, вот дифф, с которого я начал свой доклад. Такой дифф иногда получается в Microsoft Edge:
Слева эталон, а текущее изображение получилось полностью прозрачным:
Почему? Насколько нам удалось выяснить, из-за всплывающих диалоговых окон, ворующих фокус: если в этот момент снимался скриншот, он может получиться прозрачным.
В InternetExplorerDriver, используемом в Selenium для взаимодействия с IE, в коде был замечательный костыль: сразу после снятия изображение проверяется на однотонность, и, если оно однотонное, после ожидания в две секунды процесс повторяется. Кстати, из-за этого ожидания браузер иногда перестаёт отвечать на любые запросы и может закрэшиться.
В EdgeDriver, видимо, такого уже нет, поэтому иногда мы имеем то, что имеем.
Но вернёмся к браузерам. Последнее место занимают «старички» вроде Opera 12.16, Android Browser 4.3, IE8 и так далее. Проблема в том, что поддержка WebDriver осталась на уровне, где была во времена этих браузеров.
Общая рекомендация: использовать Headless Chrome и спускаться ниже, только если вам не хватает покрытия и вы начинаете пропускать баги в продакшн. Помните, что добавление каждого браузера в тестирование — это дополнительные накладные расходы на поддержку инфраструктуры.
С браузерами всё. Теперь давайте выполним упражнение на внимательность, классическое для любого материала по визуальному тестированию: чем различаются эти скриншоты?
Есть очевидные вещи: нескрывшийся скролл, разный порядок выдачи. Есть вещи, которые сложнее уже заметить: например, курсор в поле ввода. А есть те, которые невооружённым глазом практически невозможно заметить. Кто заметил на этом изображении больше пяти отличий?
Общая картина выглядит вот так. Что же отличается?
Эти 8 отличий — некоторое summary того, о чём я буду говорить дальше.
Прежде чем мы перейдём к рассмотрению каждого, давайте ещё раз взглянем на исходные изображения.
Мы нашли 8 отличий, но это анализ без контекста. А если смотреть с точки зрения тестирования интерфейсов, то отличий-то и нет. Именно поэтому все эти вещи достойны нашего внимания.
Начнем, пожалуй, с тех, которые можно исправить со стороны проекта.
Значимые отличия Чтобы разобраться, что такое «значимые отличия», пойдём от обратного и разберёмся с «незначимыми». Это те отличия, которые для данного конкретного теста не имеют особого значения.
Являются ли отличия в контенте (например, в порядке выдачи элементов) значимыми? Для тестирования сайта целиком — безусловно. Но с точки зрения тестирования интерфейсов, пожалуй, нет, каждый из элементов отображается корректно. И чтобы не было ложных срабатываний, необходимо делать тесты максимально воспроизводимыми. Нужно банально stub'ать бэкенд.
Если есть возможность гонять тесты на заранее подготовленных статических HTML — замечательно. Если тестирование происходит на сайте, обращающемся в базу данных, нужно дампить состояния БД на момент написания тестов и хранить дампы в репозитории, рядом с исходниками, тестовыми сценариями и эталонами.
Если у вас более сложный бэкенд (например, обращающийся по сети в другие источники), можно написать прокси, перехватывающий ответы и также дампящий их на файловую систему. Дальше всё по накатанной: храним на файловой системе и в процессе выполнения тестов запускаем сервер в режиме чтения дампов.
Частный случай отличий в контенте — отличия вложенных блоков (в данном случае логотипа). Представьте, что есть набор тестов, и в какой-то момент дизайнер решает поменять логотип. Тогда нам необходимо переснять эталоны для всех тестов с этим логотипом. А это дорого, потому что при принятии эталона его необходимо полностью провалидировать глазами (не только что это отличие валидное, но и что мы ничего другого нового не сняли). Представьте, что у нас этих тестов тысяча. Решением в данном случае будет модульность.
Необходимо писать тесты максимально модульными. В идеале должен быть отдельно тест на логотип, отдельно на все вложенные блоки в любом их состоянии, и отдельно тест на взаимное расположение этих блоков (здесь должны играть роль только их размеры и положение в каком-то более высокоуровневом блоке).
Как игнорировать элементы, зависит от инструмента. В Hermione есть опция ignoreElements, передающая в команду assertView.
При передаче этой опции место, занимаемое игнорируемым элементом, будет закрашено чёрным прямоугольником, и при сравнении таких изображений отличий в этом месте найдено не будет.
Время
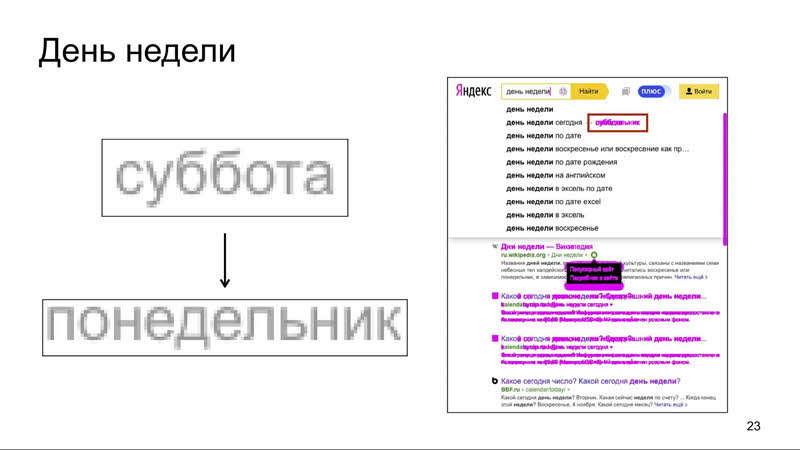
Эталон снимался в субботу, тест прогонялся в понедельник, а в итоге видим дифф, хотя в обоих случаях всё отображается корректно. И так могут отличаться все блоки, зависящие от времени: само время, дата, год. Классический пример: 1 января всегда падает какое-то количество тестов с отличиями в футере, где написан год.
Избежать таких срабатываний можно двумя способами. Первый — игнорировать элемент, как в предыдущем варианте, но это не всегда помогает. Может измениться размер (как в нашем случае, где он зависит от дня недели), а иногда нам необходимо протестировать сам этот элемент. Что делать? Можно застабать дату.
Дата стабается выполнением JavaScript на клиенте. Я привёл самый простой пример: после открытия страницы подменяем глобальную функцию. Важно помнить, что некоторые элементы могут инициализироваться в процессе загрузки страницы, и после загрузки стабать дату будет поздно. Тогда скрипт необходимо внедрять в страницу в процессе её сборки, куда-нибудь на самый верх.
Анимация Наш пример проблемы из-за анимации — положение поп-апа. Если присмотреться к этим двум увеличенным изображениям, видно, что на правом поп-ап чуть ниже.
Чтобы понять, что это из-за анимации, нужно обладать контекстом: например, знать, что анимация там есть. Иначе отличие выглядит валидным (смещение блока, вызванное багом в вёрстке). Как мы поступали бы при тестировании руками? Дожидались завершения анимации, а потом приступали к проверке. Так нужно и в тестах.
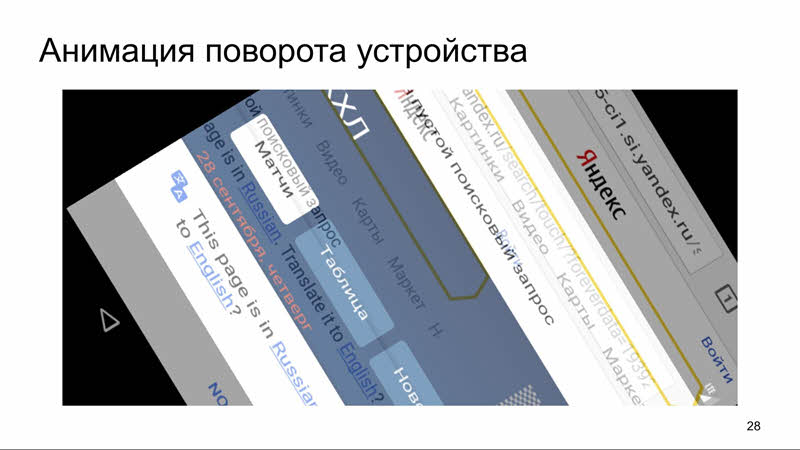
Отдельно хочется поговорить об анимации поворота устройства. В протоколе WebDriver поворот устройства не зафиксирован. Эту функциональность предоставляет Appium, и никто не гарантирует, что возврат в код исполнения тестов будет осуществлён после завершения анимации. И можно попасть на такие кейсы:
Это вполне реальное изображение, снятое в одном из наших тестов.
Чтобы дождаться завершения анимации, в конфигурации Hermione предусмотрена опция screenshotDelay (количество миллисекунд, которое инструмент ждёт перед снятием скриншота). Если для изображения всего элемента необходимо выполнить серию скриншотов, перед каждым будет выполняться ожидание.
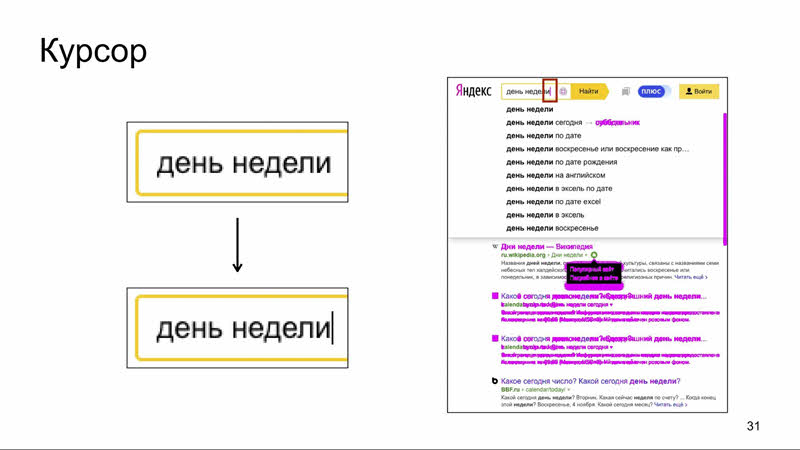
Курсор Частный случай проблем с анимацией — курсор. С отличием в том, что это бесконечная анимация.
Курсор моргает, и иногда скриншот будет с ним, а иногда без. Классический flaky-тест. А это ещё хуже, чем false positive, так как его тяжело воспроизвести.
Дождаться завершения анимации мы не можем. Что делать? Что-то с курсором: либо полностью скрыть, либо отключить моргание. И если скрыть можно средствами браузера (например, сделать его полностью прозрачным), то с отключением моргания придётся повозиться, так как для некоторых браузеров это системная настройка.
В Ubuntu есть возможность настраивать графическую библиотеку. Можно положить в домашнюю директорию конфиг, выключающий моргание курсора.
Из двух вариантов предпочтительнее отключить моргание: это, в частности, позволяет протестировать положение курсора внутри поля ввода.
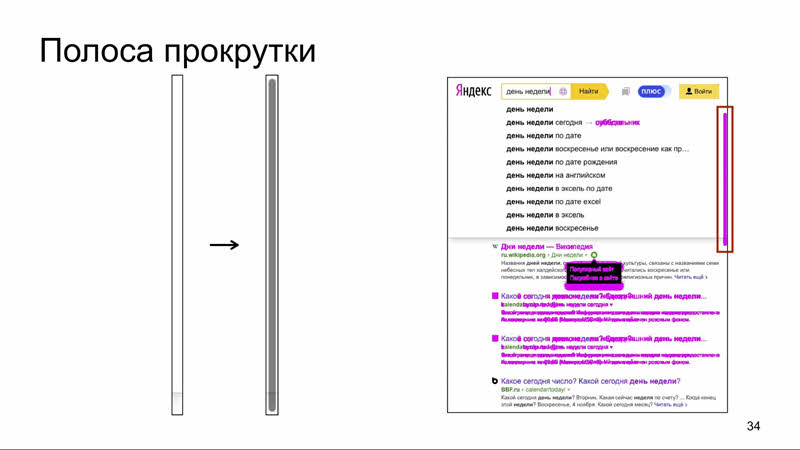
Полоса прокрутки Следующий частный пример анимации — скрытие полосы прокрутки.
Та же проблема: иногда скриншот будет сниматься с ней, иногда без неё, а если вы очень везучие, будет и наполовину спрятанный скролл. Как поступать?
Можно дождаться, использовав опцию screenshotDelay, а можно опять-таки отключить показ полосы прокрутки или её исчезновение. Предпочтительнее, наверное, отключить исчезание полосы прокрутки, потому что иногда её наличие на странице — как раз признак бага. Если её отключить, этого просто не увидеть. В Headless Chrome есть отдельная опция hide scrollbars. Она передается бинарнику браузера при его запуске, и с ней на скриншотах нет скролла. Вообще по (https://peter.sh/experiments/chromium-command-line-switches/) этой ссылке много опций командной строки для Chrome, я рекомендую хотя бы одним глазком взглянуть.
«Состояние» Здесь речь идёт о состоянии браузера, сохраняющемся между прогонами теста.
И это уже относится не только к настройке со стороны проекта, но и к самому браузеру.
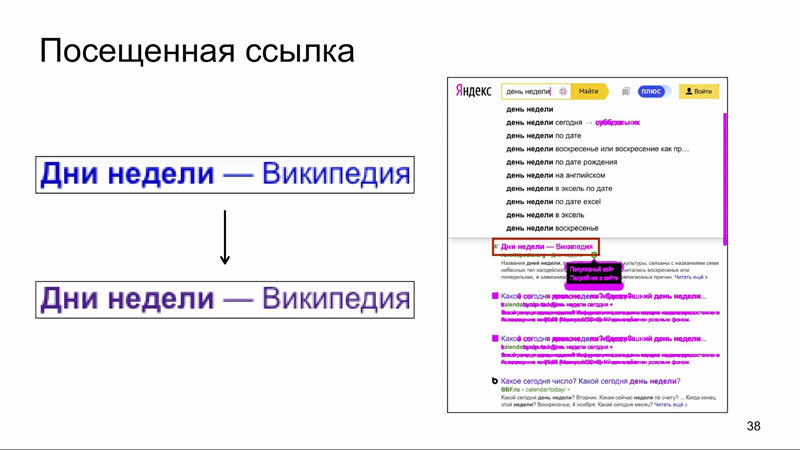
В нашем случае проблема с состоянием в ссылке, прокрасившейся как посещённая. Важно помнить, что такая посещённая ссылка будет ложным срабатыванием только в случае, если действия, которые привели к этому, были осуществлены либо в другом тесте, либо в другом прогоне этого самого теста. И чтобы этого не происходило, необходимо для каждого теста поднимать чистую сессию.
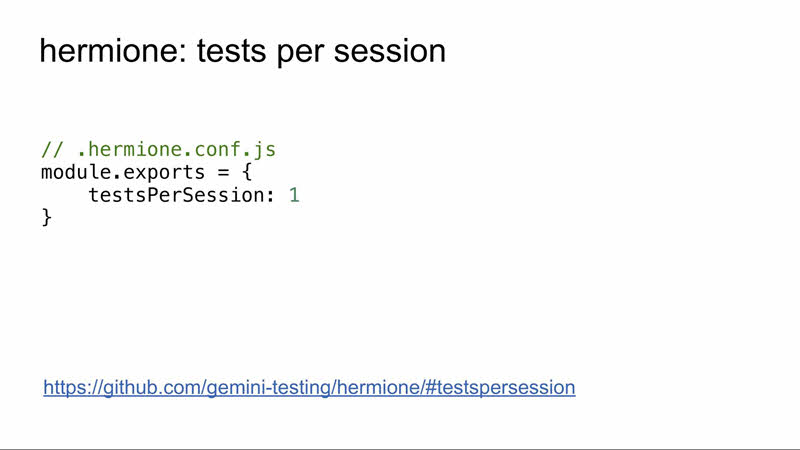
В Hermione для этого есть опция testPerSession, по умолчанию она выставлена в infinity из соображений производительности.
Обращаю внимание, что, если поставить слишком маленькое число, можно получить существенное увеличение времени прогона тестов, так как постоянно будет подниматься новая сессия. На время поднятия уходит от нескольких секунд до двух минут в зависимости от браузера.
Отдельно хочется поговорить о состоянии, сохраняющемся между сессиями: размере окна. Это тоже может влиять на отображение сайта.
Чтобы не испытывать этих проблем, в конфиге можно указать ожидаемый размер окна, выставляемый перед каждым тестом.
То же с ориентацией устройства, в конфиге можно указать желаемую.
На этом, пожалуй, заканчивается то, что можно решить с помощью настройки тестового стенда, инструмента и использования каких-то вещей со стороны проектов. И мы переходим в область ответственности библиотеки сравнения изображений.
Давайте для начала обозначим проблемную область. Мы определили, что на этом диффе у нас 8 отличий. Но компьютер видит больше 27 000.
Почему так происходит? Мы с вами видим отличия уже сгруппированными образами, а компьютер — набором пикселей. Кластеризация объектов — это отдельная большая задача из области цифровой обработки изображений. А научить компьютер, что можно игнорировать — это задача из области машинного обучения.
Чтобы этого не приходилось делать, нужно просто настраивать тестовый стенд специальным образом, о котором мы говорили ранее. Но даже если всё это сделать, остаётся набор отличий, которые мы просто не видим.
Антиалиасинг 99% таких отличий выпадает на долю антиалиасинга. Чтобы понять, что это такое, начнём с того, что такое алиасинг.
Алиасинг возникает при отрисовке фигуры на дискретном множестве пикселей. Пиксель не закрасить наполовину, поэтому мы закрашиваем целиком те, которые большей частью попадают внутрь фигуры. Получаются хорошо заметные «ступеньки» — артефакты алиасинга. И для борьбы с ними, для сглаживания, применяется антиалиасинг.
Самый простой способ реализации антиалиасинга: определить, какая часть пикселя покрывается фигурой, и если это 50%, то прокрасить цветом на 50% между цветом бэкграунда и цветом фигуры (в нашем случае это чёрный и белый). Если пиксель закрывается более чем на 50%, то прокрашиваем более светлым, если меньше, то более тёмным. Это так называемое grayscale-сглаживание. А в чём проблема с ним?
В том, что этот антиалиасинг, скажем так, живой и нестабильный. При определённых обстоятельствах пиксели могут отрисоваться чуть-чуть по-другому. Человек этого не заметит, но строгое сравнение изображений уже не сработает.
Игнорировать эти отличия должен инструмент. И тут мы вступаем на тонкий лёд компромиссов, потому что хотим снизить качество сравнения изображений до уровня восприятия человека, но не хотим, чтобы наш инструмент начал пропускать баги.
Цветовое отличие Если мы считаем, что какой-то пиксель недостаточно отличается от другого, то нужно игнорировать такие незначительные отличия в цвете. Осталось это формализовать.
Вопрос: вот эти изображения разные или нет?
Логика понятная: я рассказываю о цветовых различиях, значит, изображения различные.
Но на самом деле они одинаковые. А вот эти разные:
Проблема в том, что они нам тоже кажутся одинаковыми. И как понять, когда можно игнорировать цветовые различия? Где грань?
Первое приходящее в голову — вспомнить, что цвет является точкой в трёхмерном пространстве, и представить расстояние между цветами как расстояние между двумя точками в пространстве.
Идея простая, но плохая. Во-первых, недостаточно посчитать расстояния между точками — ещё нужно понять, какие можно игнорировать. А во-вторых, наши глаза воспринимают отличие в цветах неодинаково. Это видимый спектр:
Левее ультрафиолетовое излучение, правее — инфракрасное. Наши глаза лучше всего воспринимают отличия цветов из середины спектра: весь зелёный, часть синего и часть красного. А то, что на краях, мы не особо отличаем. Кроме того, мы воспринимаем цвета по-разному в зависимости от яркости. И попытка считать разницу между цветами в RGB не учитывает всё это. Так что же делать?
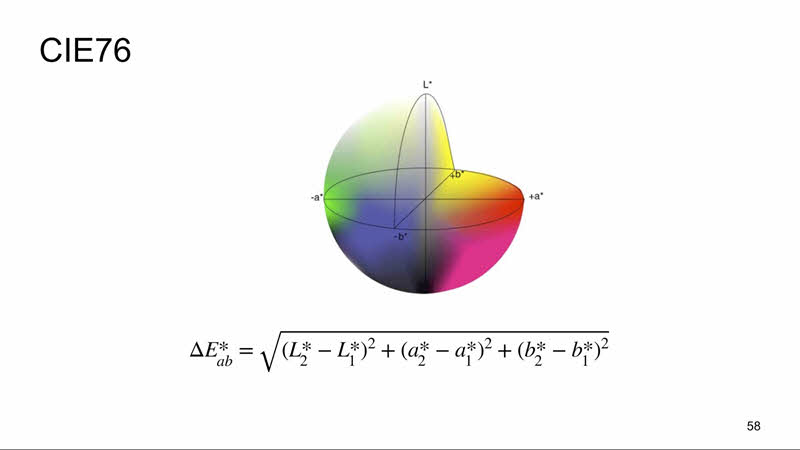
Решение даёт Международная комиссия по освещению, которая разработала и стандартизировала метрику цветового различия Delta E.
Формула стандарта 1976 года как раз являлась формулой расстояния между двумя точками, но уже в другом пространстве Lab. Оно отличается от RGB тем, что яркость отделена от значения хроматической составляющей цвета, задается координатой L и меняется от 0 до 100 (от самого тёмного до самого светлого), а хроматическая составляющая задаётся двумя декартовыми координатами a и b. A — это положение цвета в диапазоне от зелёного до красного, b — от синего до жёлтого.
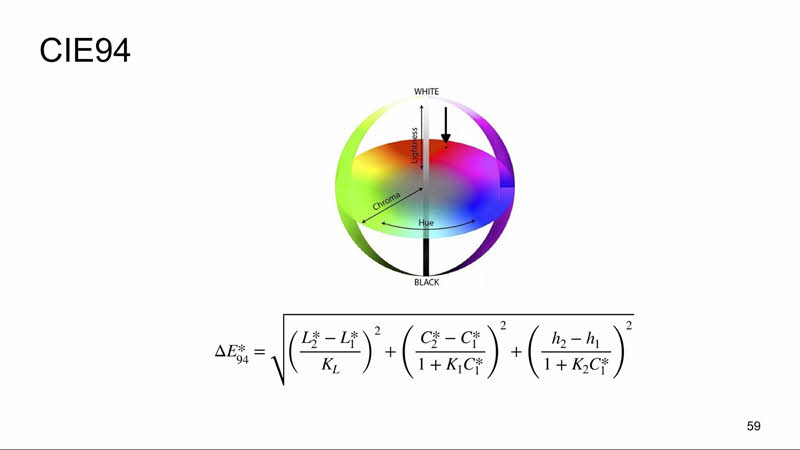
С развитием техники точности формулы 1976 года стало не хватать, и был разработан новый стандарт 1994 года, задававшийся уже в другом цветовом пространстве LCh. У LCh координаты хроматической составляющей задаются уже угловыми координатами, а не декартовыми, это цветовой тон и насыщенность, а яркость так и осталась отдельной компонентой. В эту формулу также была внесена некоторая константа, которую можно менять в зависимости от области применения (искусство и промышленность). И это, пожалуй, была последняя простая для восприятия формула. Текущий стандарт 2000 года выглядит приблизительно вот так:
В формулу внесли корректировки, и она стала трудной для восприятия, но это не так важно, потому что библиотеки умеют считать это за нас. Важно другое: вместе с формулой комиссия по освещению дала понимание того, что цвета, которые разнятся по ней менее, чем на 2,3, неразличимы для большинства людей. А это как раз то, что нам было нужно.
Эти изображения, которые я уже приводил, отличаются на 0,52. Именно поэтому мы и не видим этих различий.
Максимальное цветовое различие, позволяющие игнорировать отличия в изображениях, в Hermione задается опцией tolerance. По умолчанию она выставлена в 2,3, и менять это в большинстве случаев не нужно. Но, как я уже говорил, компромисс достигается за счёт возможности настраивать точность сравнения изображений.
Применение формул цветового различия и tolerance в 2,3 в нашем примере позволяет решить проблему с отличиями в середине кнопки, так как там цветовая разница составляет 1,9. Но не позволяет решить проблему с отличиями на краю кнопки, там разность уже 2,8. А увеличивать tolerance до 2,8 я бы не рекомендовал: разница цвета становится заметной. Обратите внимание, что правый прямоугольник светлее.
Что же делать в таком случае?
Antialiasing detecting Если мы обнаруживаем, что по пикселю не понять, можно ли его проигнорировать, то можем попытаться определить, является ли этот пиксель следствием антиалиасинга.
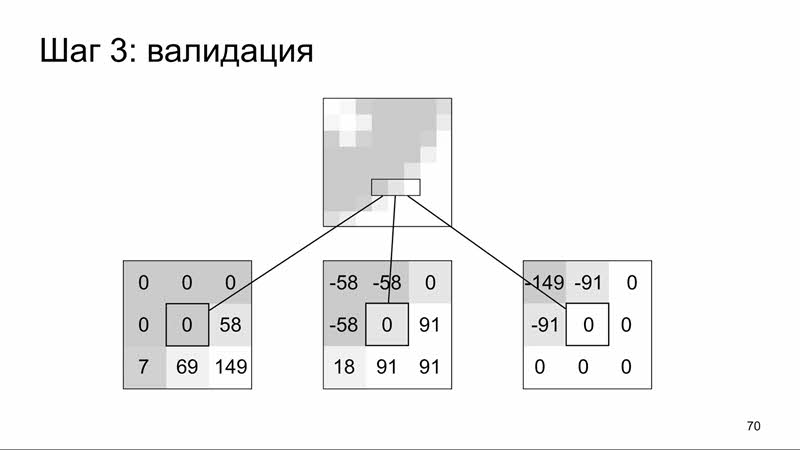
Итак, задача: по окружающим пикселям понять, что проверяемый — следствие антиалиасинга. В этом нам поможет метод, описанный Витаутасом Вишняускасом в 2009 году в журнале «Электроника и электротехника». Его суть: можно определить пиксель, который лежит на склоне яркости, по яркости соседних пикселей. Этот алгоритм реализован в библиотеке looks-same, которая используется в Gemini и Hermione, и также, насколько мне известно, его реализует библиотека pixelmatch.
На каждом шаге этого алгоритма используется сам пиксель, который мы проверяем, и 8 его соседей — то есть, фактически, квадрат размером 3 на 3.
На первом шаге мы преобразовываем цвет из RGB в относительную яркость по стандартной формуле. Кстати, если посмотреть на коэффициенты в этой формуле, можно заметить этот самый вклад, который осуществляет каждый из цветов в эту самую яркость. Помним, что зелёный у нас находится в середине видимого спектра, и поэтому у него самый большой коэффициент.
На следующем шаге мы высчитываем для каждого соседа разницу между его яркостью и яркостью проверяемого пикселя. Вокруг пикселей, которые лежат на склоне яркости, будут отрицательные и положительные значения. Если вокруг не больше двух нулей, то этот пиксель лежит на склоне яркости.
И на последнем шаге определяем, что пиксель не находится на продолжительном склоне яркости (например, градиенте). Для этого применяем тот же алгоритм на самый тёмный и на самый светлый пиксель из соседей. В нашем примере для этих пикселей вокруг больше двух нулей — значит, они находятся не на склоне яркости, а наверху и внизу этого склона.
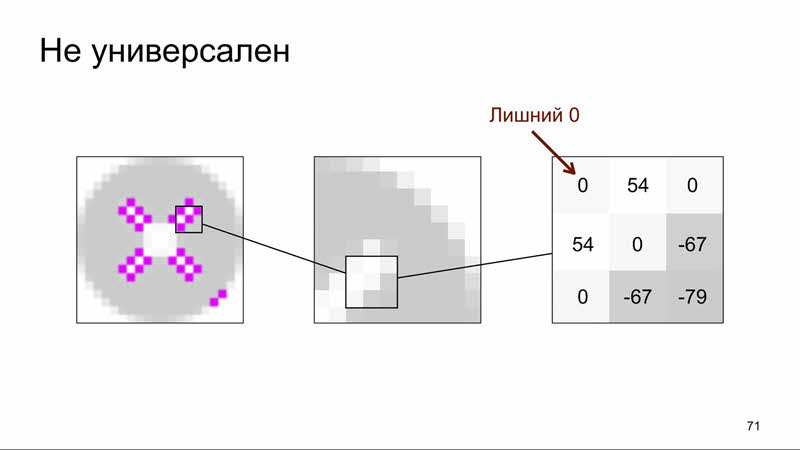
Этот алгоритм достаточно простой и эффективный для большинства сгенерированных изображений, то есть по факту элементов страницы. Но, к сожалению, он даёт сбои, когда речь идет о склонах яркости, находящихся близко или пересекающихся. Поэтому алгоритм не работает, например, для элементов с тенью, наложенных на элементы с антиалиасингом, и не работает для очень мелких объектов (например, шрифтов).
Сглаживание шрифтов О сглаживании шрифтов хочется поговорить отдельно.
Говоря об алиасинге, я утверждал, что мы не можем закрасить часть пикселя. Это утверждение, скажем так, не совсем соответствует истине. Вот взгляд на монитор под микроскопом.
Это так называемые субпиксели, последовательность из трёх (красного, зелёного и синего) даёт нам один пиксель. И в основе субпиксельного сглаживания, которое часто применяется для сглаживания шрифтов, лежит идея, что можно поменять яркость одного из субпикселей. Как это выглядит?
Первое изображение — буква «А» высотой в 8 пикселей без сглаживания. Здесь отчётливо видны артефакты алиасинга, «ступеньки».
Второе — то же, но с grayscale-сглаживанием. На мелких изображениях это действительно выглядит так страшно, но мы этого не замечаем (тут ведь увеличенное).
Третье — реализация субпиксельного сглаживания.
А четвёртое — как его видим мы. Уже больше похоже на букву «а», правда?
Для большего понимания вот сравнение: при grayscale-сглаживании меняется яркость всего пикселя, при субпиксельном меняется часть. Идея простая: меняя яркость части пикселя, приклеить её к основной массе, и издалека этот субпиксель не отличить от основной массы. А другая часть приклеивается к бэкграунду.
Технического решения, гарантированно решающего проблему с субпиксельным слаживанием, на данный момент нет. Общая рекомендация: отключать сглаживание шрифтов в тестируемой среде.
В Ubuntu, насколько мне известно, оно отключено по умолчанию, а в Windows это сделать несложно. Но вот Edge, скажем так, плевать на настройки системы в этом вопросе. И приходится применять другой способ. Можно использовать библиотеку Resemble.js с опцией ignoreAntialiasing.
Нужна осторожность, так как Resemble.js игнорирует эти отличия, фактически, за счёт увеличения tolerance. Чтобы случайно не пропустить лишнее, я бы рекомендовал выполнять два сравнения: с игнорированием антиалиасинга и без. И принимать решение о том, можно ли игнорировать эти отличия, на основе этих двух результатов.
С игнорированием они должны быть одинаковыми, а без игнорирования отличия должны быть незначительные. Незначительность можно определить по свойствам misMatchPercentage и diffBounds результата, который возвращает вам Resemble.js при сравнении. Если этого не делать, то можно пропускать такие вот отличия:
Обратите внимание на разметку поля. Resemble.js считает её антиалиасингом.
А вот сравнение прокрашенной (посещенной) и непрокрашенной ссылки.
Отличия нашлись только в слове, написанном жирным шрифтом, а в остальных было проигнорировано, хотя поменялся цвет (и это довольно крупный шрифт, 18-й).
В этом отношении Resemble слишком лоялен к отличиям, но предоставляет вам возможность самим решить, являются ли эти отличия существенными.
Давайте подведём итог. Чтобы сократить количество отличающихся изображений, ложных срабатываний и времени на анализ отчётов, необходимо придерживаться следующих правил:
Также мы с вами выяснили, что простое попиксельное сравнение в большинстве случаев будет давать ложное срабатывание. Одна из главных задач разработки инструментов визуального тестирования — «очеловечивание» этого сравнения, снижение его качества до уровня восприятия человека. И тут главное не перегнуть.
Если вам понравился этот доклад, обратите внимание: 17-18 мая в Петербурге состоится следующий Heisenbug, там тоже будет множество интересных докладов по тестированию. Вся уже известная информация о мероприятии — на (https://heisenbug-piter.ru) на сайте. Также до 11 марта мы еще принимаем заявки на доклады. По промокоду SoftwareTestingPromo —скидка 1000 рублей на персональные билеты. |