|
 Меня зовут Елена Расторгуева, я отвечаю за продукт «Фактор» в HFLabs. «Фактор» — чертовски сложный алгоритмический enterprise, он обрабатывает данные в промышленных масштабах. Меня зовут Елена Расторгуева, я отвечаю за продукт «Фактор» в HFLabs. «Фактор» — чертовски сложный алгоритмический enterprise, он обрабатывает данные в промышленных масштабах.
В статье я расскажу, как мы начинали тестировать «Фактор», как развивали автотесты и почему пришли к самописным фреймворкам.
Оригинальная публикация
Что за продукт такой — «Фактор»«Фактор» чистит данные в базах с миллионами клиентов: убирает опечатки в ФИО, телефонах и емейлах, проверяет паспорта, делает еще кучу всего. Самое сложное — исправлять почтовые адреса.

Адреса́ пишут сотнями способов, поэтому под капотом у «Фактора» неслабый алгоритмический аппарат
«Фактор» работает как сервис: данные на вход — данные на выход.
Это stateless-система, где каждое обращение не зависит от предыдущих. Stateless сильно упрощает жизнь тестировщика. Намного сложнее тестировать stateful системы, когда важна последовательность действий.
Продукт должен быть надежным как МКС, потому что им пользуются банки, сотовые операторы, страховые, ритейлеры уровня «Ленты». За ошибки мы отвечаем головой вплоть до того, что отсутствие ошибок — часть SLA в договоре с заказчиком.
Из-за требований к надежности автотесты мы писали с самого начала разработки. Один из критериев готовности задачи — «Добавлены автотесты».
Начинали с ручной проверки и автотестов
Мы зарелизили «Фактор» в 2005 году и сначала тестировали его руками. Утром тестировщик прогонял автотесты на файле с кейсами и сравнивал результат обработки данных с результатом предыдущего дня: что изменилось после вчерашнего коммита кода.
Процесс мог занять полдня, такой расклад никуда не годился. Поэтому мы взяли минимальный набор тестов на ключевую функциональность и завернули в юнит-тесты. Эти тесты быстрые, и разработчик сам запускал их перед коммитом.
Юнит-тесты такие удобные и работают так быстро, что мы добавляли их тысячами. А потом уперлись: когда тесты выглядят как простыня из тысяч кусочков кода, даже долистать до нужного места непросто. Не говоря о добавлении или обновлении.

Юнит-тест на проверку формата СНИЛС
К тому же в промышленных данных регулярно появляется что-то внезапное, что не покрывают юнит-тесты. Например, пришел новый заказчик с новыми особенностями в адресах, юнит-тесты эти особенности не покрывают. Нужно сесть и посмотреть, какие тесты добавить для новых данных. Мы все еще делали такое вручную.
Создали свой фреймворкВ традиционных юнит-тестах данные и код идут вперемешку, выискивать нужные участки тяжело.
Поэтому мы попробовали автотесты в парадигме Data Driven Testing (DDT). DDT — это когда данные для тестирования хранятся отдельно от кода для тестирования.
Кейсы загружали из excel-файла, они лежали в колонках «Неочищенные данные» и «Ожидаемый результат». DDT стал прорывом: апдейтить кейсы в «эксельнике» невыразимо проще.
Понемногу мы развили подход и разработали собственный фреймворк для тестирования. На вход он принимает текстовые файлы, внутри них — исходные данные и ожидаемый результат.

От excel-файлов как хранилища мы отказались: текстовые быстрее открываются, не меняют содержимое, из них проще забрать данные
Фреймворку помогают стандартные инструменты:
- TeamCity автоматически запускает тесты каждую ночь;
- testNG сравнивает ожидаемый и фактический результаты.

Если результат отличается от ожидаемого, в TeamCity тест краснеет. Если всё как надо, тест зеленый
Доработали фреймворк под себяС тех пор прошло 12 лет. За это время фреймворк оброс возможностями, которых нет в стандартных решениях.
Учет статуса задач в Jira. HFLabs придерживается Test Driven Development: сначала пишем тест или добавляем тест-кейсы на новое поведение, а только потом меняем функциональность.
Новые кейсы мы отключали комментированием строки. Иначе они первое время падали и мешали, поскольку кейсы добавляли раньше фичи или исправления бага.
Но соответствующую тест-кейсу задачу могут и не выполнить: баг окажется исключительно редким или заказчик принесет что-то поважнее. Некоторые задачи месяцами висели с низким приоритетом, и отключенные кейсы накапливались. При этом непонятно, к какому таску относится каждый кейс, можно ли этот кейс удалить.
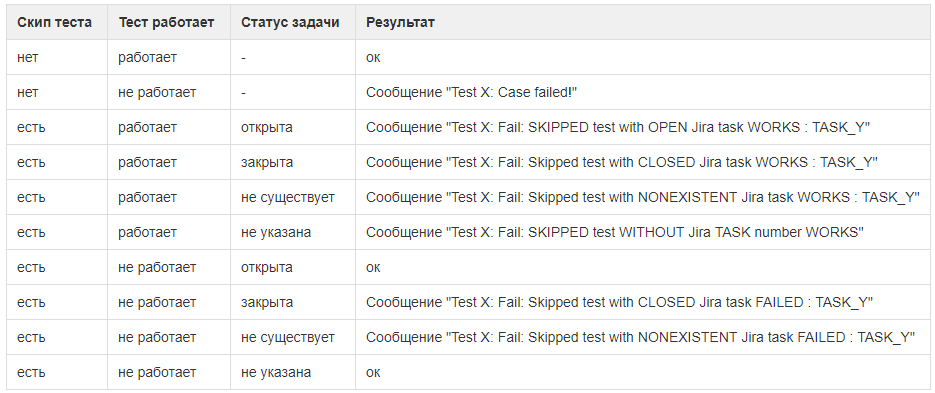
Поэтому мы добавили к отключенным кейсам номер таска и навернули немного автоматики. Теперь все работает так:
- тест-кейс отключают, сопоставив ему открытую задачу в Jira;

Чтобы привязать кейс к задаче, пишем перед ним # и номер таска
- фреймворк прогоняет тесты даже по отключенным кейсам. Но игнорирует падения, пока задача открыта в Jira;
- как только задачу закрывают, тест начинает падать на привязанных к ней кейсах. Это сигнал: задачу сдали, а кейсы включить забыли;
- если вдруг тест по отключенному кейсу начал проходить при открытой задаче, фреймворк об этом тоже сообщит. Возможно, пора включить кейс или закрыть привязанный к нему таск (плюс обновить release notes и сообщить заказчикам).

Фреймворк говорит, что отключенный кейс проходит. Возможно, кто-то поправил код в рамках другой задачи, и теперь все работает
Так мы сохранили TDD и победили забывчивость при управлении тест-кейсами.

Все варианты со статусами тест-кейсов и связанных задач мы задокументировали, чтобы не забыть
Актуализация тест-кейсов в полуавтоматическом режиме. Казалось бы, если тест падает, ищи ошибку в коде. Но для нас это не всегда так. Бывает, актуализировать нужно именно тест-кейсы, потому что изменились требования к результату.
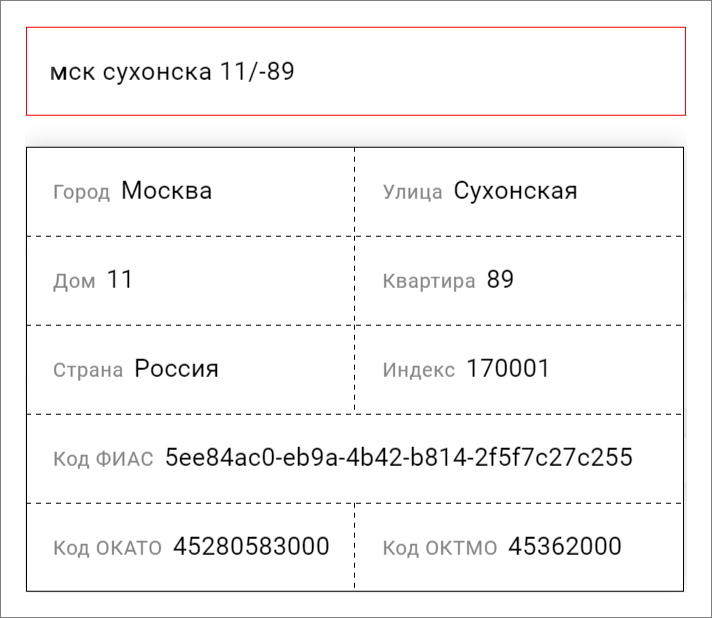
Например, раньше заказчик в очищенном адресе хотел «г. Москва» одним полем. Теперь он изменил архитектуру БД, хочет «город» одним полем, «Москва» — другим. Пора менять тест-кейсы.
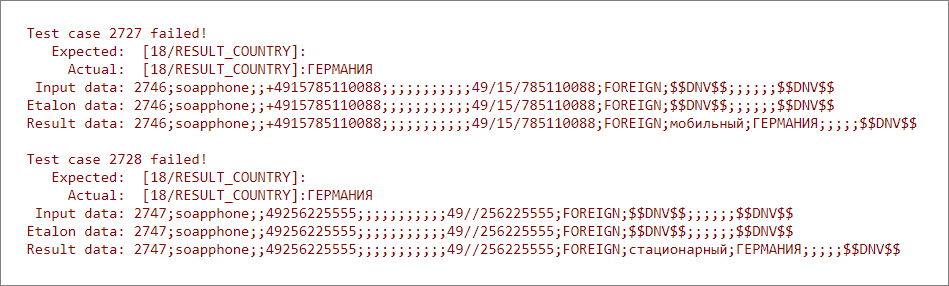
Для упавшего теста TeamCity показывает разницу между ожидаемым и актуальным результатами. Раньше мы копировали эту разницу и руками обновляли тест-кейсы. Для массовых изменений — очень затратное мероприятие.

Живой пример: мы научили «Фактор» определять страну по номеру телефона, тесты в TeamCity упали. Новый эталон можно взять из фактического результата, но это долго
Мы сделали так, чтобы фреймворк сам обновлял эталон. Для этого после прогона тестов он заменяет в эталоне ожидаемые результаты очистки на фактические там, где они не совпали. Итог сохраняет в артефактах как файл актуализации кейсов.
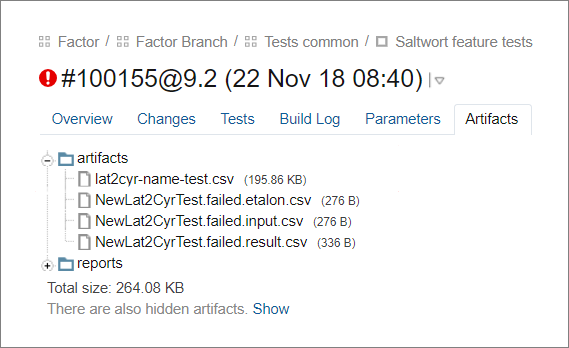
Первый файл — это новый эталон, в котором фреймворк обновил ожидаемые результаты. Остальные файлы — это входящие данные, старый эталон и фактические данные для упавших кейсов
С новым эталоном тестировщик актуализирует кейсы в три шага.
- Скачивает сгенерированный файл.
- Проверяет через любой инструмент мерджинга, какие изменения попали в новый эталон. Оставляет только нужные.
- Коммитит.

Тестировщик проверяет, насколько обновления в новом эталоне корректны, и коммитит их
Да, если актуализировать бездумно, ничего хорошего не получится. Но риск бездумной актуализации есть и при работе вручную.
Стабилизация тестовых данных заглушками. «Фактор» возвращает обработанные данные в десятках полей. В одном только адресе куча составляющих: индекс, регион, тип региона, тип города, город, тип улицы, дом, строение, корпус, квартира. К ним «Фактор» цепляет ИФНС, ОКАТО, ОКТМО и еще по мелочи. Так из одной строки на входе получаются десятки значений.
Не все поля из результата нужно проверять тест-кейсами. Например, распознавание того же адреса прямо зависит от государственного справочника — ФИАС. А в нем регулярно меняются поля, для наших задач совсем посторонние. Обновление каких-нибудь КЛАДР-кодов для домов роняло сотни тест-кейсов.
Мы добавили заглушки на ожидаемый результат, когда поняли, что впустую тратим время на анализ неважных падений.
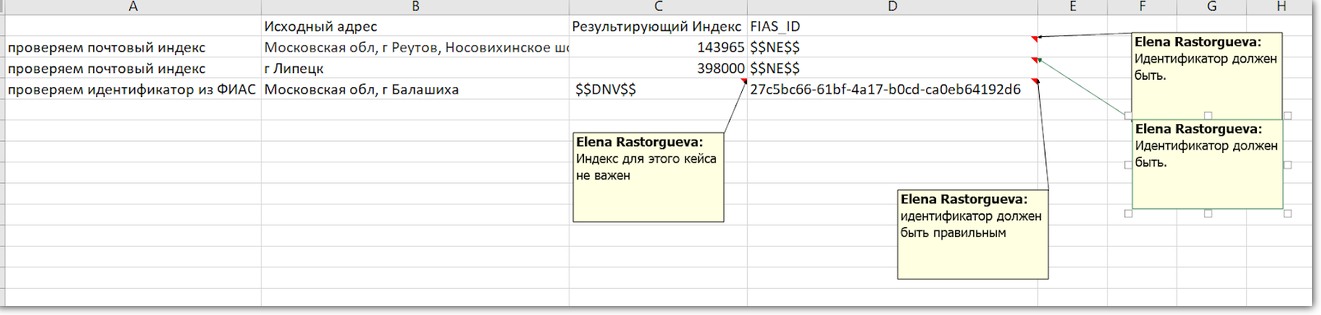
Когда поле вообще не нужно проверять, тестировщик пишет в ожидаемый результат условное обозначение: $$DNV$$. Когда поле должно быть заполнено, но само значение не важно: $$NE$$.

ФИАС ID в адресе есть всегда, поэтому мы проверяем его на всех тестах. Если поле не заполнено, что-то не так. А вот индекса может и не быть, поэтому при проверке ФИАС ID индекс мы игнорируем
Можно было пойти по другому пути и разделить тесты: на каждое поле свой. Но это сложно, потому что не всё можно изолировать. Например, «город» и «улица» являются частями адреса и друг без друга не имеют смысла.
Самописный фреймворк удобнееПоэтому я совсем не считаю создание собственного фреймворка глупой затеей. Не создай мы собственный инструмент, не получили бы столько новых возможностей и такую гибкость.
Выключение текст-кейса по статусу задачи, генерация нового эталона, заглушки на результат — это штуки, которые теперь просят наши тестировщики в остальных фреймворках. Если бы мы взяли стандартные решения, никогда бы не смогли этого сделать. Обсудить в форуме |