Что пишут в блогах
- Гибкие и хаотичные: современные модели разработки ПО глазами тестировщика
- Техники тест-дизайна: теория против реальности.
- Какое юзабилити-тестирование вам нужно?
- Методологии разработки ПО: классика глазами тестировщика
- API и облака: как тестировать то, что нельзя потрогать?
- Библиотека промтов для ChatGPT на русском языке
- Как провести эффективное функциональное тестирование для web и мобильных приложений?
- Тест-кейсы без ошибок: структура, правила
- Почему ручное тестирование всё ещё критически важно для успешного релиза мобильного приложения
- Quality Gate - что это такое?

Что пишут в блогах (EN)
- 2025 Ministry of Justice consultation
- Test Cases – a partial exploration
- No, it’s not you, it’s definitely me . . .
- Avoid a Race to the Bottom in Software Quality
- Rock Bottom?
- Beyond AI and Automation: The Real Foundations of Software Quality
- Double Identity Speak
- Episode 022 - Practicing Testing with James Lyndsay - The Evil Tester Show
- The Next Big Leap in Software Testing Technology – Interview with Coty Rosenblath (CTO of...
- Five for Friday – March 14, 2025
Онлайн-тренинги
-
Школа тест-менеджеров v. 2.0Начало: 16 апреля 2025
-
Bash: инструменты тестировщикаНачало: 17 апреля 2025
-
Charles Proxy как инструмент тестировщикаНачало: 17 апреля 2025
-
Chrome DevTools: Инструменты тестировщикаНачало: 17 апреля 2025
-
Docker: инструменты тестировщикаНачало: 17 апреля 2025
-
Git: инструменты тестировщикаНачало: 17 апреля 2025
-
Python для начинающихНачало: 17 апреля 2025
-
Азбука ITНачало: 17 апреля 2025
-
Применение ChatGPT в тестированииНачало: 17 апреля 2025
-
SQL: Инструменты тестировщикаНачало: 17 апреля 2025
-
Школа для начинающих тестировщиковНачало: 17 апреля 2025
-
Программирование на Python для тестировщиковНачало: 18 апреля 2025
-
Английский для тестировщиковНачало: 21 апреля 2025
-
Тестирование REST APIНачало: 21 апреля 2025
-
Школа Тест-АналитикаНачало: 23 апреля 2025
-
CSS и Xpath: инструменты тестировщикаНачало: 24 апреля 2025
-
Автоматизация тестов для REST API при помощи PostmanНачало: 24 апреля 2025
-
Тестирование GraphQL APIНачало: 24 апреля 2025
-
Инженер по тестированию программного обеспеченияНачало: 24 апреля 2025
-
Тестирование производительности: JMeter 5Начало: 25 апреля 2025
-
Практикум по тест-дизайну 2.0Начало: 25 апреля 2025
-
Автоматизатор мобильных приложенийНачало: 30 апреля 2025
-
Автоматизация тестирования REST API на PythonНачало: 30 апреля 2025
-
Тестирование безопасностиНачало: 30 апреля 2025
-
Тестирование мобильных приложений 2.0Начало: 30 апреля 2025
-
Автоматизация тестирования REST API на JavaНачало: 30 апреля 2025
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 12 мая 2025
-
Техники локализации плавающих дефектовНачало: 12 мая 2025
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 13 мая 2025
-
Тестирование юзабилити (usability)Начало: 14 мая 2025
-
Регулярные выражения в тестированииНачало: 15 мая 2025
-
Selenium WebDriver: полное руководствоНачало: 16 мая 2025
-
Организация автоматизированного тестированияНачало: 16 мая 2025
-
Логи как инструмент тестировщикаНачало: 19 мая 2025
-
SQL для тестировщиковНачало: 19 мая 2025
-
Создание и управление командой тестированияНачало: 22 мая 2025
-
Автоматизация функционального тестированияНачало: 23 мая 2025
-
Программирование на Java для тестировщиковНачало: 23 мая 2025
-
Программирование на C# для тестировщиковНачало: 30 мая 2025
-
Тестирование веб-приложений 2.0Начало: 30 мая 2025
-
Selenium IDE 3: стартовый уровеньНачало: 6 июня 2025
-
Аудит и оптимизация QA-процессовНачало: 6 июня 2025
| Ядро автоматизации тестирования в микросервисной архитектуре |
| 28.11.2017 12:32 |
|
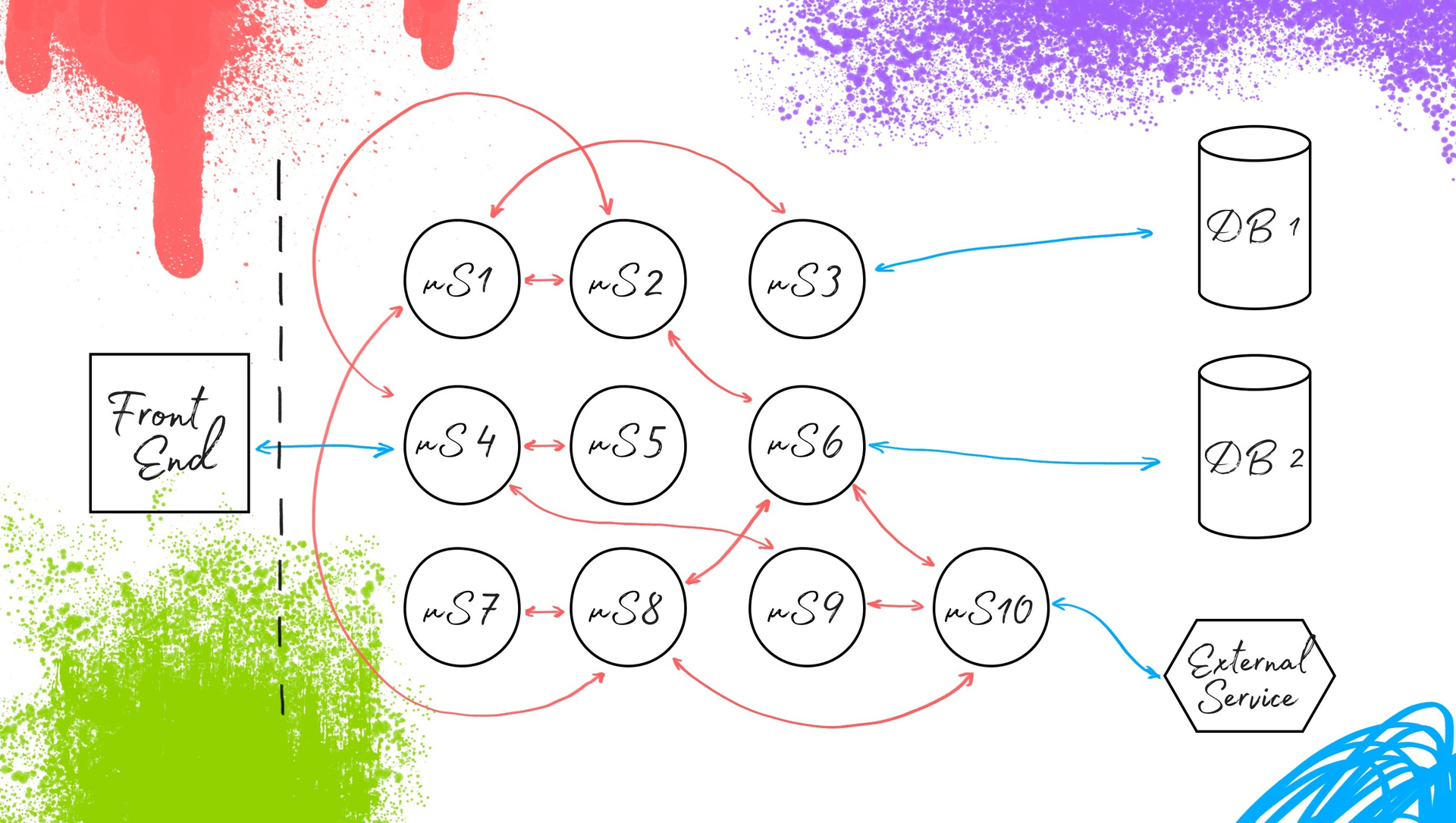
Оригинальная публикация: https://habrahabr.ru/company/avito/blog/333644/ Меня зовут Дмитрий Химион, я руковожу отделом обеспечения качества в Avito. Cегодня я хочу рассказать про автоматизацию тестирования в рамках работы с микросервисной архитектурой. Что мы можем предложить разработке для того, чтобы облегчить контроль качества? Читайте под катом. Вместо вступления“An implementation should be conservative in its sending behavior, and liberal in its receiving behavior”. Что такое микросервисная архитектура?Чтобы мой рассказ был полным, начнем с основ. Если упростить, микросервисная архитектура — это способ организации сервера приложений. Как он работает? По сути, это просто ответ сервис-ориентированной архитектуры на появление такой практики, как DevOps. Если в SOA не регламентированы размеры сервисов и то, что именно они должны делать, то в рамках микросервисной архитектуры есть некоторые умозрительные ограничения. Микросервис — это некоторая сущность, которая заключает в себе одну небольшую функциональность, которой она заведует и предоставляет внешним сервисам какие-то данные. Иногда приводят информацию, что микросервис — это 500 строк кода. Но это не обязательно; смысл заключается в том, что сервисы эти достаточно маленькие и образуют те же бизнес-процессы, что и монолитный бэк-энд, который работает на многих проектах. Функционально — то же самое, отличия — в организационной структуре. Переход к микросервисам
Для начала рассмотрим переход от монолита к микросервисной архитектуре. В случае с монолитом для того, чтобы заменить какой-либо кусочек в этой системе, мы не можем выкатить его отдельно. Нужно делать сборку заново и полностью обновлять бэк-энд. Это не всегда рационально и удобно. Что происходит при переходе на микросервисную архитектуру? Мы берем бэк-энд и делим его на составляющие компоненты, разделяя их по функциональности. Определяем взаимодействия между ними, и получается новая система с тем же фронт-эндом и теми же базами данных. Микросервисы взаимодействуют между собой и обеспечивают всё те же бизнес-процессы. Для пользователя и системного тестирования всё осталось таким, как и прежде, изменилась внутренняя организация. Контракты для микросервисной архитектуры
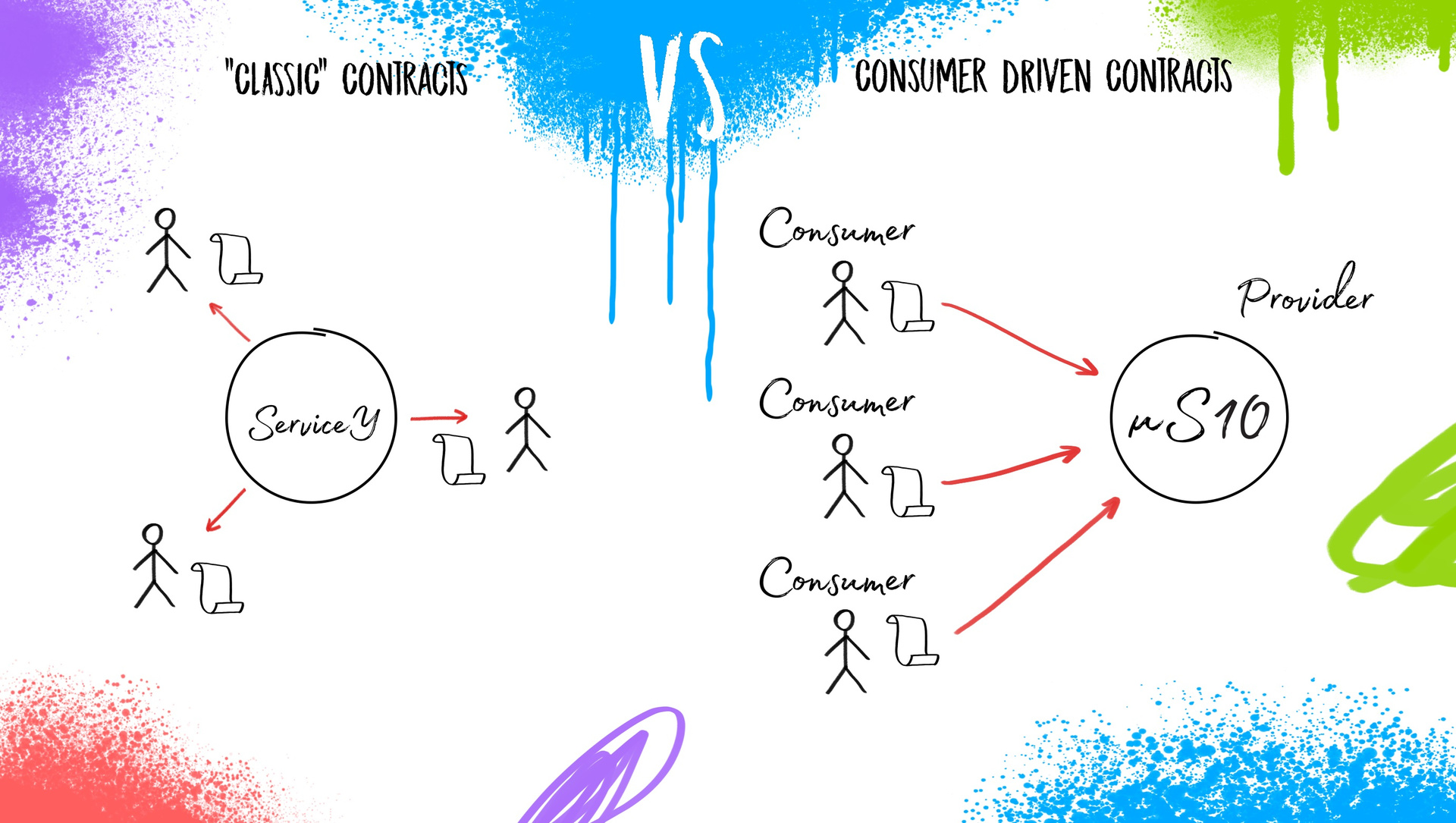
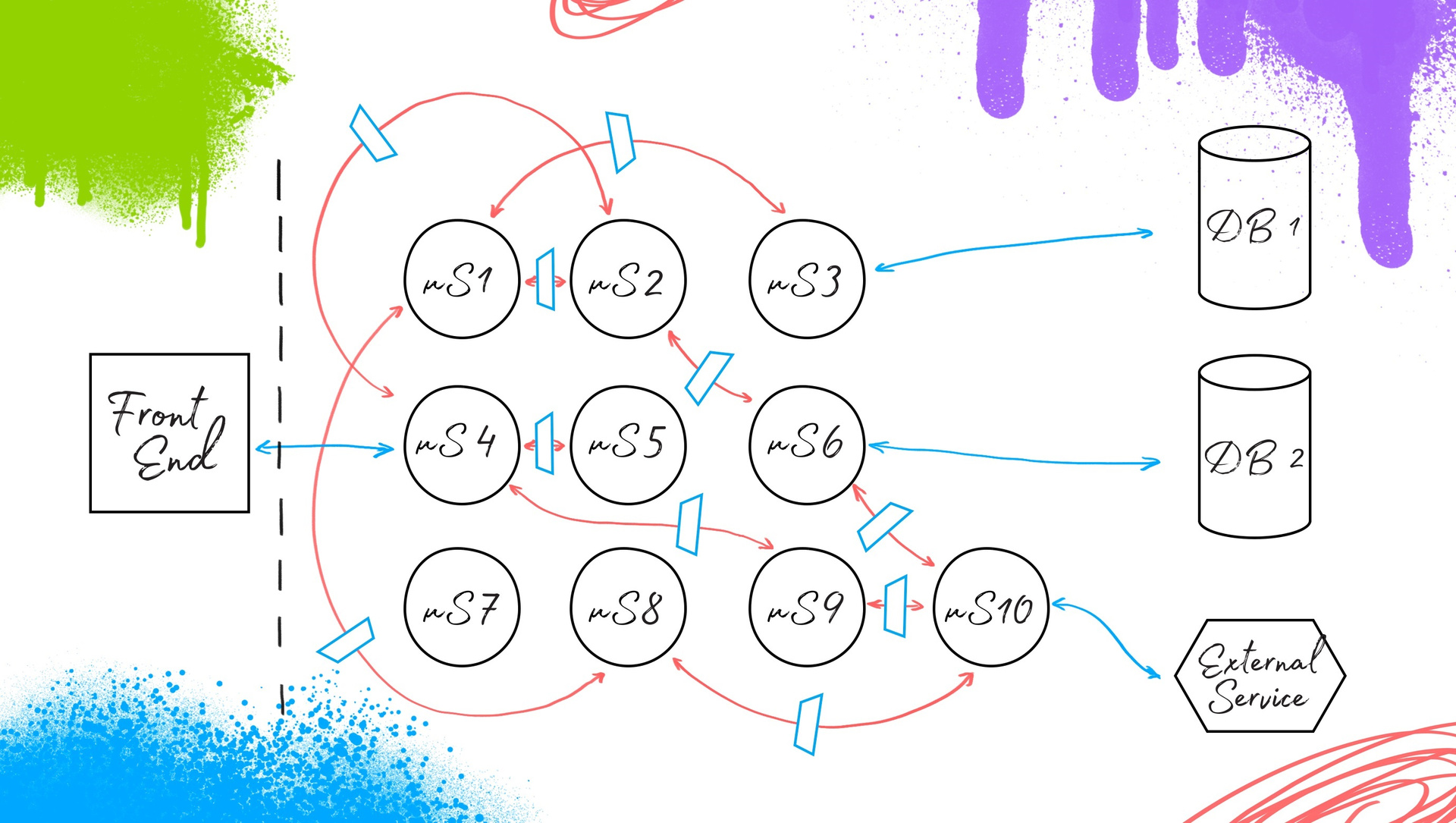
Взаимодействия микросервисов между собой реализуются посредством контрактов. Что это значит для сервис-ориентированной архитектуры? Контракт — это некоторое соглашение, которое разработчики сервиса создают для взаимодействия между собой внешних пользователей. Разработчики сервиса сами решают, что вы можете запросить у них “X”, а они вам предоставят “Y”. Сервис может предоставлять внешним пользователям яблоки, помидоры, плутоний, продавать детскую одежду или телевизоры — ему не декларируется чёткий фокус на функционал. Внутреннее наполнение регламентируется только на уровне здравого смысла. И соответственно, это сервис диктует внешним пользователям то, что они будут получать, и как к нему необходимо обращаться. Пользователь 1: “Я слышал, вы поставляете яблоки. Мне нужны маленькие и зелёные”.
Таким образом получается, что пользователи создают контракты, задают требования и направляют их к провайдеру, который их реализует. В чем плюс? Так как у каждого сервиса достаточно ограниченное количество потребителей, получить от каждого по три спецификации и реализовать их гораздо проще, чем пытаться угадать, какие именно “яблоки” нужно предоставить в каждом конкретном случае и что еще им может понадобиться к этим “фруктам” дополнительно. Предикаты для CDC-testing (Consumer Driven Contracts)
Без чего нельзя начать работать по принципам CDC-testing? Первое. У нас не получится помочь, если мы видим что у нас в разработке не соблюдается процесс работы по контрактам. Вторая вещь более техническая: это система post-commit (post-PR, если хотите) hook-ов, которая обрабатывает этот поток общения между девелоперами с помощью контрактов и сигнализирует нашей системе тестирования об их обновлении, удалении, появлении новых. Соответственно, заводятся соответствующие таски в Jira, чтобы автоматизаторы успели это все “переварить”. К этому базовому процессу можно добавить еще все что угодно — дополнительные проверки, процессные примочки, но без контроля изменения контрактов взаимодействия между микросервисами жить будет достаточно сложно. Выполнив в каком-то виде эти два пункта, мы можем приступить к имплементации. Имплементация автоматизации под CDC
В основу нашей системы автоматизации тестирования ляжет такое решение, как PACT-фреймворки. Что нужно о них знать? Это протокольное взаимодействие с API: JSON over HTTP, в этом нет ничего сложного. Эти решения взаимодействуют с нашими микросервисами и дают некоторый дополнительный функционал для изоляции и организации тестирования. Что сказать еще? Я видел, как это реализовано в том или ином виде на семи языках программирования (Java, Javascript, Ruby, Python, Go, .NET, Swift). Но если вашего нет в этом списке, не пугайтесь: можно взять базовую библиотеку и сделать свой велосипед, или написать что-то подобное тому, что уже реализовано. Что учесть при имплементации?
Что же нужно учесть при имплементации? Первое — это использование контейнеризации и виртуализации в процессе сборки/деплоя микросервиса. И наша система автоматизации тестирования точно так же закручивается в контейнер. Как будете обеспечивать взаимодействие микросервиса и системы автоматизации тестирования — это уже не столь важно: как удобнее, так и делайте. Итоги
|