|
 Авторы: Долинский Александр, Иванов Павел, Идиятуллина Лилия Авторы: Долинский Александр, Иванов Павел, Идиятуллина Лилия
Оригинальная публикация: https://habrahabr.ru/company/alfa/blog/335278/
C ростом команд неизбежно растет количество фич, а вместе с тем и тестовая модель и количество тест-кейсов, которые необходимо проверять при регрессионном тестировании. При этом количество команд растет не просто так, в нашем случае бизнесу хочется релизиться все чаще и чаще, не потеряв в качестве.
То, как мы в Альфа-Лаборатории решали проблему поиска баланса между скоростью, бюджетом и качеством, мы и рассмотрим сегодня на примере Альфа-Мобайла. Забегая вперед, ВНИМАНИЕ, СПОЙЛЕР!!! наше решение доступно на github: библиотека colibri-ui и шаблон colibri-ui-template для быстрого старта.
В написании статьи принимали активное участие Павел pvivanov и Лилия Lidiyatullina
Что случилось?
В далёком 2013 нас даже не посещали мысли об автоматизации тестирования, поскольку процесс регрессионного тестирования занимал один день одного тестировщика на обе ОС (iOS/Android).
Однако с активным ростом приложения, добавлением в него новых услуг и сервисов затраты на ручное тестирование стали также расти высокими темпами.
Прибавьте сюда увеличение количества команд (с одной до шести), которые постоянно производят новые фичи — и регрессионное тестирование станет тромбом ваших процессов, который рискует оторваться и поставить под угрозу производство.
В какой-то момент мы пришли к тому, что на момент подготовки приложения к релизу все шесть команд “простаивают”, пока все шесть тестировщиков не покладая рук “регрессят” релиз-кандидат. Во временном эквиваленте продолжительность регрессионного тестирования выросла до 8 рабочих дней (шести человек!).
Не добавляет мотивации такое положение дел и самим тестировщикам. В определенный момент у нас даже появилась шутка “На регресс как на праздник!”
Что делать?
Проблему нужно было как-то решать, и у нас было два пути “пристроить баблишко”:
- вывод новых людей в ряды тестировщиков;
- автоматизация тестирования с целью отказа от ручного тестирования.
По этическим и экономическим соображениям мы выбрали второй вариант, всё-таки затраты на автоматизацию, как ни крути, гораздо более выгодное вложение.
Движение в выбранном направлении решили начать с пилотного проекта автоматизации тестирования мобильных приложений. По его результатам мы сформировали требования к будущему инструменту:
- Инструмент для автоматизации тестирования должен быть с максимально низким порогом входа в разработку для начала его использования.
Речь о минимизации написания кода, избавлении от написания сложных локаторов и т.д., поскольку основными пользователями инструмента являются тестировщики из продуктовых команд, которые могут не иметь опыта автоматизации.
- Сценарии тестов должны быть понятны пользователям, не связанным с разработкой;
- Решение должно быть кроссплатформенным и работать сразу на двух платформах — Android и iOS;
- Должна быть сформирована ферма с подключенным набором мобильных устройств;
- Решение должно быть масштабируемым на другие мобильные приложения банка.
На основании полученных требований предстояло выбрать инструмент автоматизации.
В рамках пилотного проекта мы рассмотрели:
- Robotium
- Espresso
- UI Recorder
- Keep it Functional
- Calabash
- Appium
Требование к кроссплатформенности решения сузило выбор до последней пары из списка. Окончательный же выбор был сделан в пользу Appium по причине более активного сообщества, участвующего в разработке и поддержке.
Снижаем порог входа в разработку
Автоматизация какого-либо процесса на нижнем уровне — это скрипты и код. Однако далеко не каждый может разбираться в инструментах разработки или даже писать что-то самостоятельно. Именно поэтому мы решили максимально упростить этот момент, используя BDD-методологию на проектах.
Наш фреймворк разделен на несколько уровней абстракции, где верхний уровень пишется на популярном языке написания тестов Gherkin, а нижний уровень пишется разработчиками на языке программирования Java. Для написания сценариев был выбран JBehave.
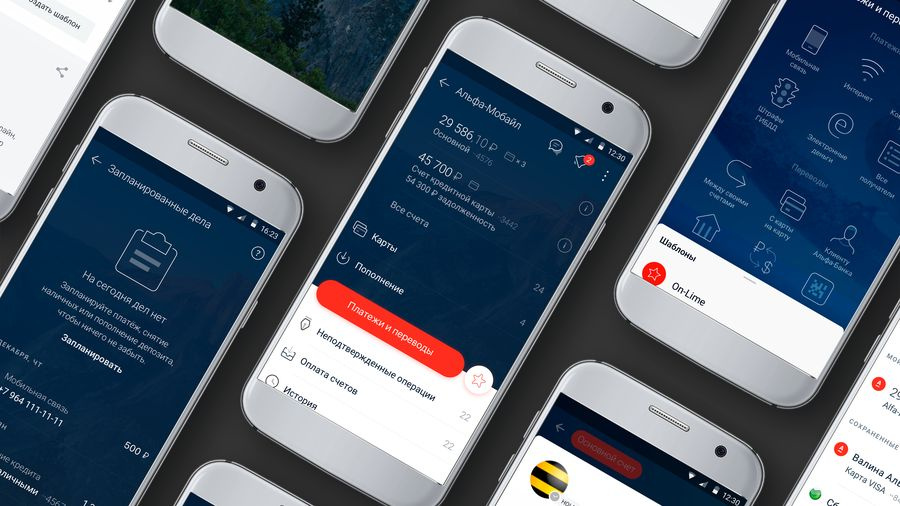
Итак, как же выглядит наше решение со стороны пользователя?
Then загружена страница "Главный экран"
When скролл внутри "Основной список" до "Платежи и переводы"
When выполнено нажатие на "Платежи и переводы"
Then загружена страница "Платежи и переводы"
When скролл внутри "Список платежей и переводов" до "Мобильная связь"
When выполнено нажатие на "Мобильная связь"
В этом примере описан процесс перехода с главного экрана на экран оплаты мобильной связи. Возможно, кто-то возразит, что с точки зрения бизнес-процесса ему неважно, каким путем он попадет на нужный экран, и он будет прав. Действительно, ничто не мешает нам перейти в нужный раздел, заменив последние пять строчек предыдущего сценария на одну, например, вот так:
When перейти в раздел "Мобильная связь"
Однако такие шаги будут менее атомарными и их сложнее будет переиспользовать сразу на двух платформах, iOS и Android. Ведь когда мы хотим снизить порог входа в разработку, нужно максимально переиспользовать текущие шаги, иначе тестировщику все время будут нужны новые и как следствие — их реализация. А здесь, как мы помним, не всегда у тестировщика есть нужные навыки разработки.
Описываем экраны
Если со сценарием все предельно ясно, он читаем «с листа» и описывает наши действия, то как же указать локаторы, при этом стараясь явно их не использовать?
Один из способов достижения задачи по снижению порога входа — это упростить написание сложных локаторов и спрятать все в проект поглубже. Так родились две фабрики, которые позволяют по описанию создать локатор и использовать его для поиска. К сожалению, не всегда можно обойтись без написания локаторов, в редких случаях его приходится писать. Для таких ситуаций мы оставили возможность найти элемент по XPath.
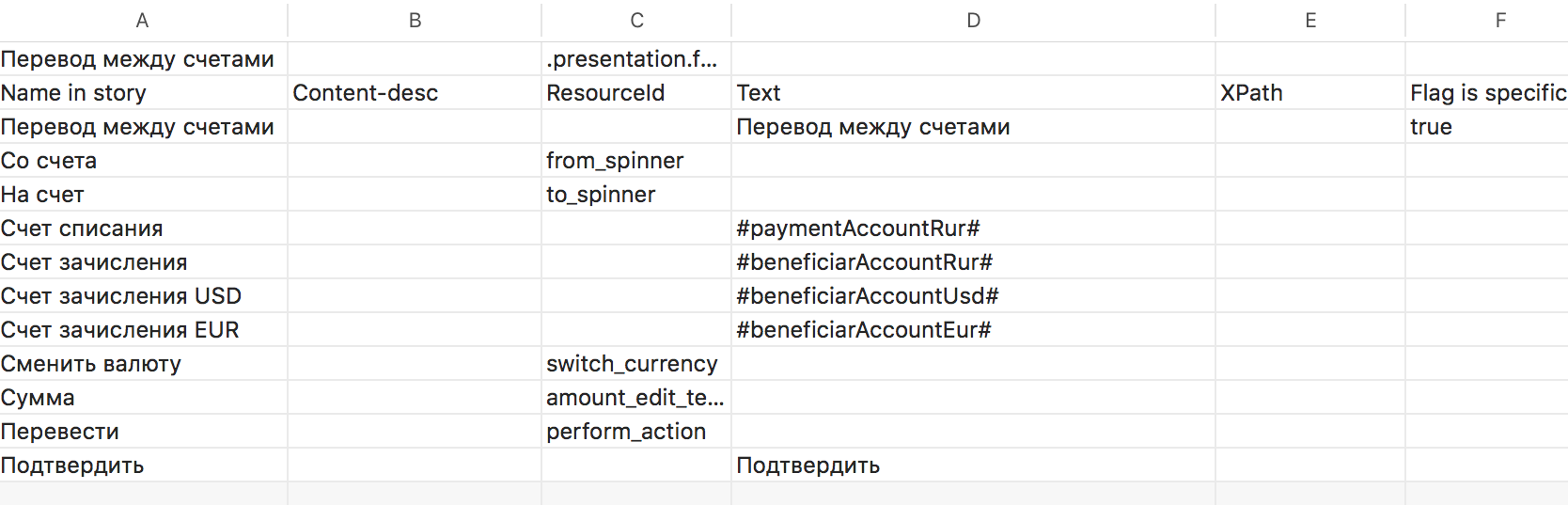
Описание элементов на экране у нас может состоять из четырех компонент. Все четыре компоненты никогда не используются, но две вполне могут использоваться, например, в случае, когда надо сначала скроллить до элемента, а затем нажать на него.
Составные части описания страницы как набора элементов:
- Content description — по этому идентификатору можно найти элементы на Android;
- ResourceId / AccessabilityIdeitificator — уникальный идентификатор. Иногда разработчики приложений не ставят идентификаторы, но это самый желанный элемент, который мы можем найти в разметке приложения для Android / iOS соответственно;
- Text — видимый текст, например, на кнопке, на которую можем нажать;
- XPath — обычный XPath по xml-разметке. Используется в случаях, когда предыдущими тремя способами однозначно описать элемент не получилось.
Имя элемента (Name in story) мы будем использовать в сценарии, по нему будем вытаскивать Content description / ResourceId / AccessabilityIdeitificator / Text / XPath.
Все описания мы собираем в .csv файлы, где в табличном виде можно удобно их править. С одной стороны, это обычный PageObject, а с другой — нашим тестировщикам не приходится править локаторы в коде.

Кажется, что куда уже проще! Описали экран, написали сценарий, запустили автотесты, но поговорим немного про нетривиальные задачи и посмотрим на наш фреймворк colibri-ui изнутри.
Настраиваем окружение
При работе с Appium всегда необходимо указывать, с каким мобильным устройством мы хотим работать. В нашем решении необходимо передать в проект udid устройства (уникальный идентификатор) и его название. Название также будет упоминаться в логах, если что-то пойдет не так. Отметим, что с помощью udid наш проект будет работать с нужным мобильным устройством, ведь их у нас целая ферма и все они подключены к одному Mac.
В настоящее время описания мобильных устройств хранятся в виде набора папок, в каждой из которых содержатся файлы настроек типа .property и json-объект. В файле типа .property указаны udid и имя устройства, json-объект содержит описание настроек ноды для работы в режиме кластера (см. шаблон colibri-ui-template).
Небольшой оффтоп, или как получить udid подключенных устройств!
Для Android мы выполняем в консоли «adb devices», для iOS — " instruments -s devices | grep -v (Simulator|$(id -un))" и получаем список подключенных девайсов. В случае с Android в списке будут как реальные устройства, так и эмуляторы, а для iOS мы фильтруем только реальные устройства. Если кому-то необходимо получить только эмуляторы, необходима другая фильтрация «instruments -s devices | grep Simulator».
В планах перенести этот набор папок в БД или в другое хранилище, либо получать список динамически, выполняя в процессе формирования окружения вышеуказанные команды. В настоящее время у нас нет потребности в таком улучшении.
Дополнительно отметим, что для работы вышеуказанных команд на вашем Mac должны быть установлены ADB Driver и Xcode соответственно. При работе с эмуляторами также не забываем выкачать их образы.
Описываем пользователя
К настоящему моменту мы учли все, что необходимо для запуска проекта в самом простом режиме. У нас есть сценарии, описания экранов и описания устройств. Однако в приложениях, которые тестируем мы, этого недостаточно. В наших приложениях необходимо авторизоваться каким-то пользователем на тестовый стенд и использовать его учетные данные, такие как: номер телефона, логин, пароль, номера счетов и т.д.
Файлы с учетными данными пользователей также лежат в проекте отдельной папкой. В перспективе, так же как и с устройствами, перенести их в БД или централизованное хранилище.
В сценариях и описаниях страниц мы используем маркеры вида #userName#, по которым получаем значение property из файла пользователя и заменяем эти маркеры в процессе прогона.
Таким образом, у нас может гоняться один и тот же набор сценариев на разных пользователях, в том числе одновременно.
Вот так это выглядит в описании страницы:

Вот так это выглятит в файле user.property:
paymentAccountRur=··0278
beneficiarAccountRur=··0163
beneficiarAccountUsd=··0889
beneficiarAccountEur=··0038
Обязательно должны быть указаны ключи и значения.
Формируем Uber-шаги и некоторые побочные эффекты
Мы начали разработку с описания довольно мелких шагов, например, ввести текст или нажать на что-то. Со временем мы поняли, что писать сценарии мелкими шагами, либо писать сложные шаги, например, вернуться на главный экран, без дублирования кода мы не можем. Так начались поиски решения для переиспользования мелких шагов в более крупные.
Первой попыткой было добавить в проект guiсe, для организации DI, но его внедрение несло с собой переработку почти всего ядра проекта. А поскольку в зависимостях, прямо в appium-java-client, уже есть Spring, для нас решение стало очевидным и следующим нашим шагом было внедрение Spring.
При внедрении Sping в наш проект объем изменений был минимальный. В самой глубине проекта изменилась только фабрика шагов JBeHave и пара строчек в подключении Allure report. Почти все классы были объявлены компонентами и убрано большинство зависимостей.
Эффектом от внедрения стали не только шаги-конструкторы, в которых мы можем переиспользовать более мелкие действия, но и возможность вынести общие решения в библиотеку (ссылка на гитхаб была в самом начале). Для нас это актуально, т.к этим решением мы пользуемся на нескольких мобильных проектах.
Ну и самый необычный эффект в том, что мы можем написать тесты на тесты. Как бы смешно и неуклюже это ни звучало, но от качества инструмента тоже многое зависит, поэтому его тоже надо поддерживать и развивать. На текущий момент работы по покрытию еще идут. С внесением изменений в ядро проекта мы будем расширять тестовое покрытие внутри библиотеки.
Запускаем проект
Как уже говорилось, мы запускаем наш проект на определенном наборе устройств параллельно.
Пример запуска проекта из консоли:
./gradlew --info clean test --tests "*AndroidStories*" -Dorg.gradle.project.platform=Nexus6p_android6 -Dorg.gradle.project.user=6056789 -Dorg.gradle.project.testType=smokeNewReg -Dorg.gradle.project.buildVersion=9.0.0.7,development
Из примера видно, что тесты запускаются для Android (--tests "*AndroidStories*"). Также в качестве параметров передаются:
Устройство, на котором будет запущен прогон тестов, Nexus6p_android6. Не забываем описывать устройство в проекте, об этом мы писали выше. Вот так это сделано у нас.
Файл device.properties содержит:
UDID=ENU14008659
deviceName=Nexus6p
Файл test_node.json содержит данные для запуска ноды.
Тестовый пользователь 6056789, данные которого мы будем использовать. На проекте есть целый набор тестовых пользователей, которых мы используем для прогона наших тестов. Пользователь должен быть обязательно описан в user.properties.
Вид тестирования smokeNewReg, в нашем фреймворке реализована логика выбора тестовых сценариев по меткам Meta. В каждом сценарии в блоке Meta есть набор меток.
Meta:
@regressCycle
@smokeCycle
В файле testCycle.properties содержатся ключи и значения к меткам.
smoke=+smokeCycle,+oldRegistration,-skip
smokeNewReg=+smokeCycle,+newRegistrationCardNumber,-skip
smokeNewAccountReg=+smokeCycle,+newRegistrationAccountNumber,-skip
regress=+regressCycle,+oldRegistration,-skip
regressNewReg=+regressCycle,+newRegistrationCardNumber,-skip
Таким образом, благодаря наличию Meta Matcher в JBehave, мы можем формировать набор тестовых сценариев на конкретный цикл тестирования.
Номер сборки, которую мы выкачиваем из централизованного хранилища, и ветку, из которой будет выкачана сборка. В нашем случае в файле environmentAndroid.properties лежит ссылка с подстановочными символами, которая формируется исходя из параметров, которые в свою очередь передаются на вход из консоли.
remoteFilePathReleaseAndDevelopment=http:
Теперь, зная, как запустить проект из консоли, можно запросто интегрировать проект в Jenkins. На наших проектах есть такая интеграция, и тестировщику достаточно просто сформировать job в Jenkins для прогона автотестов.
Сейчас также сформирована ферма с мобильными устройствами. Это Mac Pro, к которому подключены порядка десяти мобильных устройств.
Формируем отчет
В нашем проекте отчет формируется с помощью allure report. Поэтому после того как тесты отработали, достаточно выполнить “allure generate directory-with-results”
В отчете мы можем увидеть статусы по каждому сценарию. Если начать открывать сценарии в отчете, то там можно найти шаги, по которым проходил тест, почти до вызова каждого метода. В случае если что-то развалилось, в шаге с ошибкой внутри будет находиться скриншот экрана.
Ранее скриншоты были в каждом шаге, но мы посчитали, что это бессмысленно, и скрин делается только на развалившихся сценариях. К тому же с ростом количества автоматизированных сценариев отчет начинает занимать все больше места.
Результат, который мы получили
Подведем итог по задачам, которые мы перед собой ставили.
- Нам удалось сделать инструмент для автоматизации тестирования с довольно низким порогом входа в разработку. В среднем, как показала практика, тестировщику достаточно две недели для того, чтобы уверенно начать писать и запускать автотесты. Наибольшие трудности у тестировщиков связаны с окружением по настройке appium.
- Сценарии тестов понятны всем членам команды, это особенно важно, когда на вашем проекте применяется BDD-методология.
- Наш фреймворк может работать одновременно с двумя платформами — iOS и Android.
- В текущий момент мы сформировали ферму из десяти мобильных устройств и Mac Pro. Проект интегрирован с Jenkins, и любой тестировщик может запустить автотесты в параллели на всех десяти устройствах.
- Наше решение масштабируемое и уже несколько мобильных проектов активно работают с нашим фреймворком и запускают автотесты.
В качестве бонуса:
- На одном из мобильных проектов за счет автоматизации мы полностью избавили функциональных тестировщиков от тестирования front-а на обратную совместимость с backend-ом. После внедрения автоматизации время тестирования в данном случае сократилось в 8 раз (с 8 часов до 1 часа).
- Новые автотесты пишутся тестировщиками в спринте вместе с разработкой новой функциональности в мобильных приложениях;
- Часть регрессионного тестирования уже автоматизирована, как следствие — мы сократили время на регресс с 8 дней до 1 дня. Это позволило нам релизиться чаще, а тестировщики перестали выпадать из команд на период регрессионного тестирования. Ну и просто стали чуточку счастливее :)
Результаты оправдали наши ожидания и подтвердили правильность решения пойти в автоматизацию.
Мы продолжаем развивать наше решение, которое доступно на github: библиотека colibri-ui и шаблон colibri-ui-template для быстрого старта. Дальше только больше!
Обсудить в форуме
|