Что пишут в блогах
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Python для начинающихНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Азбука ИТНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
| Автоматизация нагрузочного тестирования банковского ПО для терминалов |
| 23.08.2017 00:00 |
|
Автор: Команда нагрузочного тестирования компании "Инфосистемы Джет" Оригинальная публикация: habrahabr.ru/company/jetinfosystems/blog/329014/?utm_source=software-testing В этом посте речь пойдет о тестировании серверного ПО, которое обслуживает огромную сеть банковских терминалов в России и за рубежом. Название банка мы раскрыть не можем, некоторые строчки конфигов скрыты. Автоматизация Начнем издалека. Мы постоянно слышим одно и то же: “Автоматизировать нагрузочное тестирование банковского и финансового ПО невозможно! У нас слишком много взаимосвязей! Мы очень сложные!”. Этот вызов только усиливал азарт решения задачи. Нам всегда хотелось проверить сложность на конкретном примере.
Вместо того, чтобы заниматься нагрузочным тестированием ПО на уровне взаимодействий систем, в секторе банковского ПО традиционно все тестируют через UI, как повелось со времен неразъемных систем и приложений. На это уходит много времени и сил, что делает разработку банковского ПО медленной, некачественной и нетехнологичной. Мы в компании “Инфосистемы Джет” были избавлены от этих стереотипов — разработчики сами писали юнит-тесты на свой код, функциональные тестировщики прекрасно программировали UI-тесты через Selenium+Cucumber. Осталось только встроить в процесс дополнительную стадию нагрузочного тестирования. Проектирование инфраструктуры В самом начале мы решили отказаться от взаимосвязей, которые усложняют и размывают ответ на вопрос, насколько производительный и надежный код мы разрабатываем. Например, авторизация и выдача токенов на проведение операций — это функциональность сторонней системы, исследовать производительность которой в рамках задачи было бы избыточно. Помимо этого мы сразу отказались от интеграции с несколькими back-office системами, сделав заглушку, отвечающую нашей системе с определенной задержкой (все мы знаем, как опасно тестировать систему на сверхбыстрых моках). После проектирования и осмотра оставшейся инфраструктуры стало примерно понятно, как будет выстроен процесс, какие бенефиты будут получены, и нужно было приступать к созданию самого процесса НТ.
CI/CD процесс и программное обеспечение Код ПО выкладывается во внутреннем git-репозитории (GitLab). После коммита по специальному триггеру Jenkins вытаскивает код на сборочную машину и пытается собрать релиз с прогоном всех заведенных Unit-тестов. После успешной сборки с помощью скриптов собранный билд инсталлируется в два тестовых окружения ‒ НТ и ФТ ‒ и делает рестарт тестинга. После подъема бэкенда Jenkins прогоняет друг за другом ФТ, UI и ИФТ-тесты. Нагрузочное тестирование запускается отдельной задачей, но про это стоит рассказать отдельно. Самое интересное После того как билд попадает на нагрузочный стенд, посредством скриптов в Jenkins запускается специальная задача для нагрузочного тестирования. Задача настроена классическим способом, через shell-скриптинг и параметризацию.
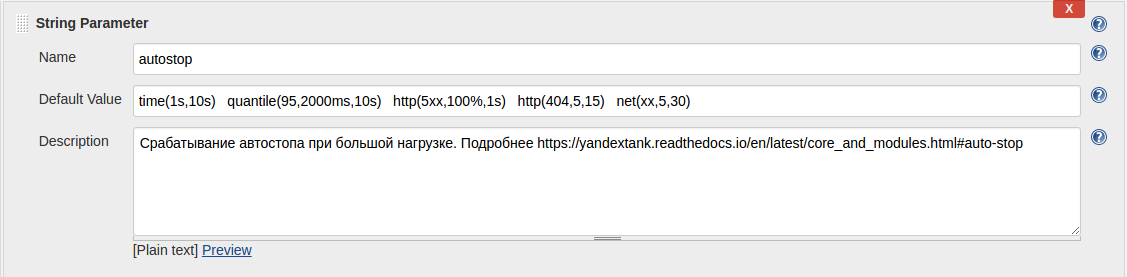
Кликните на картинку, чтобы увеличить изображение Так выглядит конфиг Yandex.Tank:
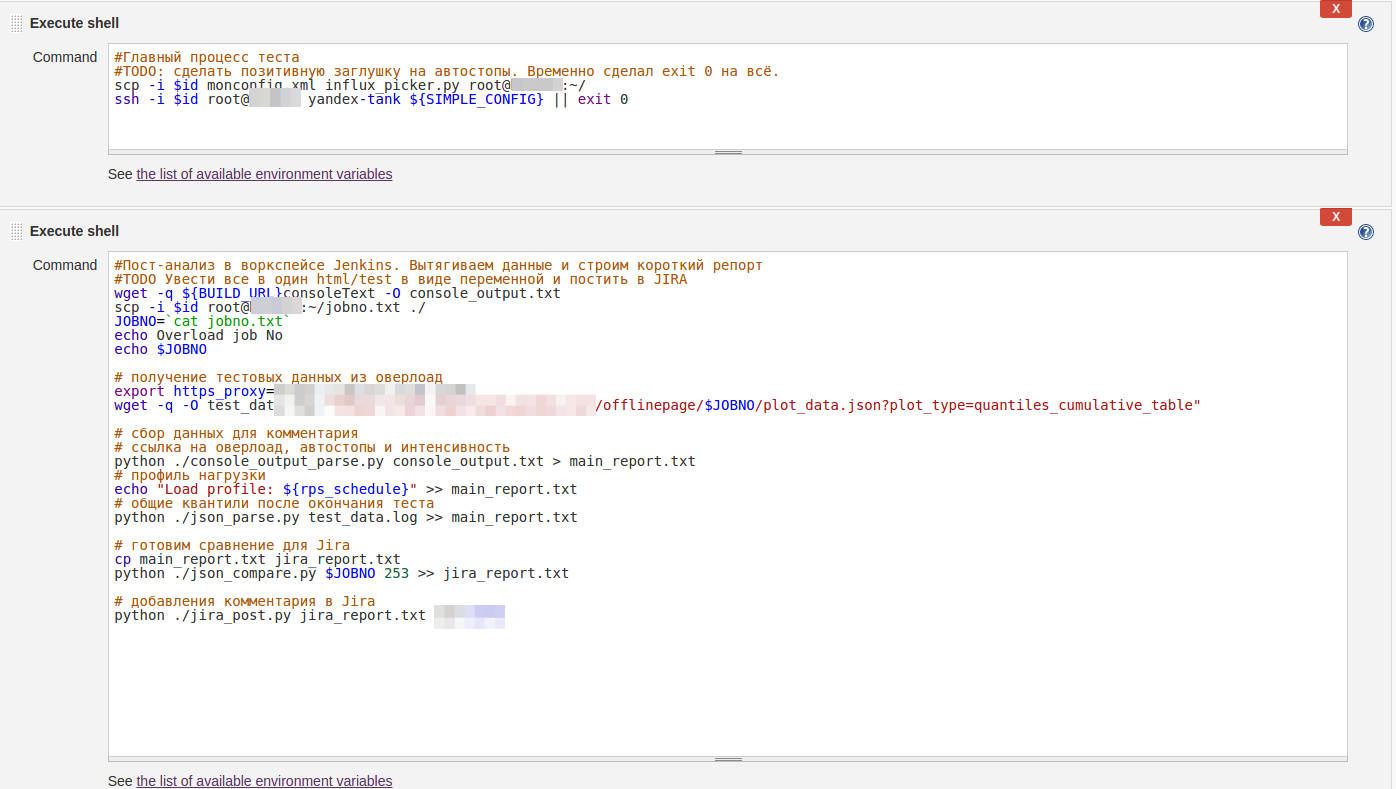
Кликните на картинку, чтобы увеличить изображение А так выглядит пример shell-script запуска всего процесса НТ:
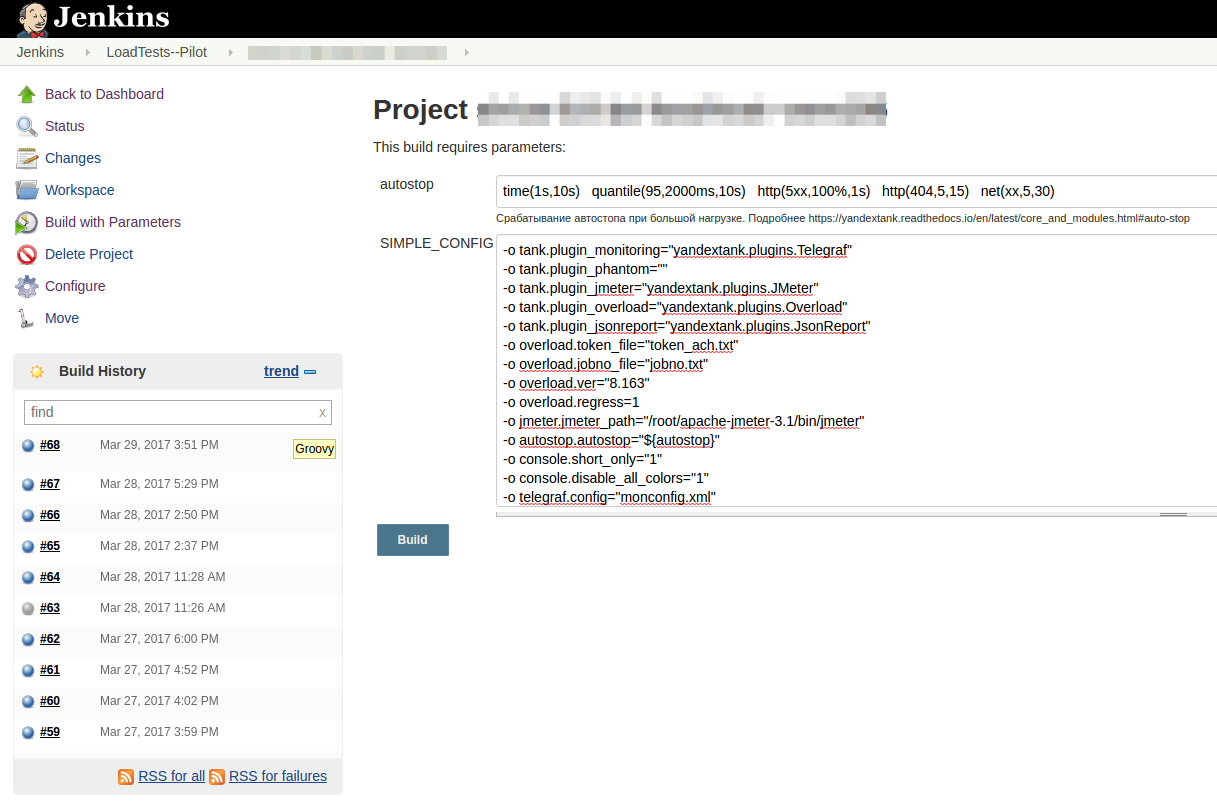
Кликните на картинку, чтобы увеличить изображение Как видите, все настройки достаточно примитивны. При автоматическом запуске джоба дефолтные параметры применяются автоматически, при ручном же запуске вы можете конфигурировать стрелялку параметрами Jenkins, не разбираясь в документации и не копаясь на Linux-машинке и перебирая необходимые конфиги.
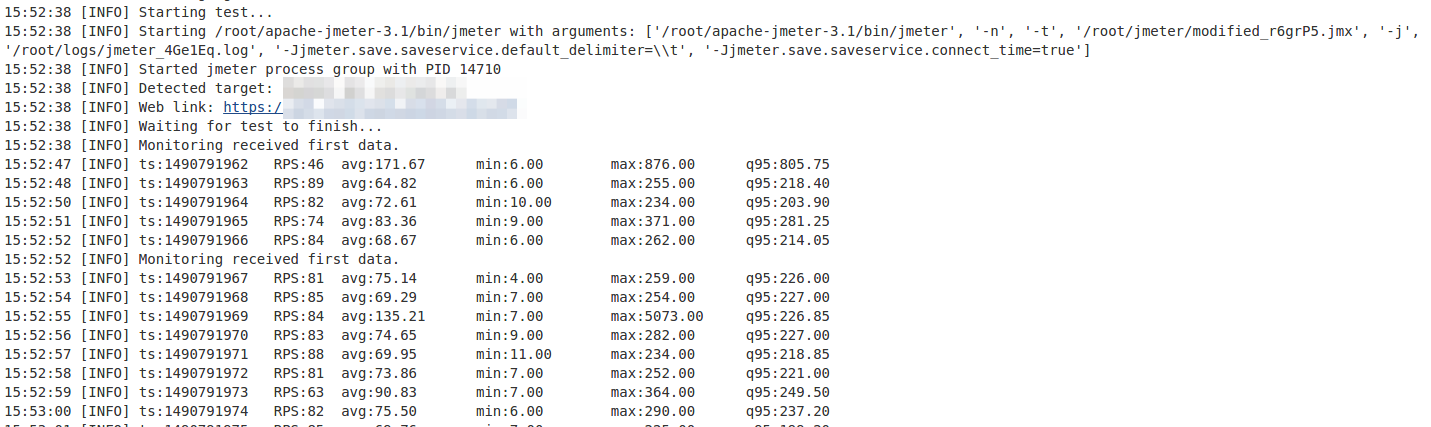
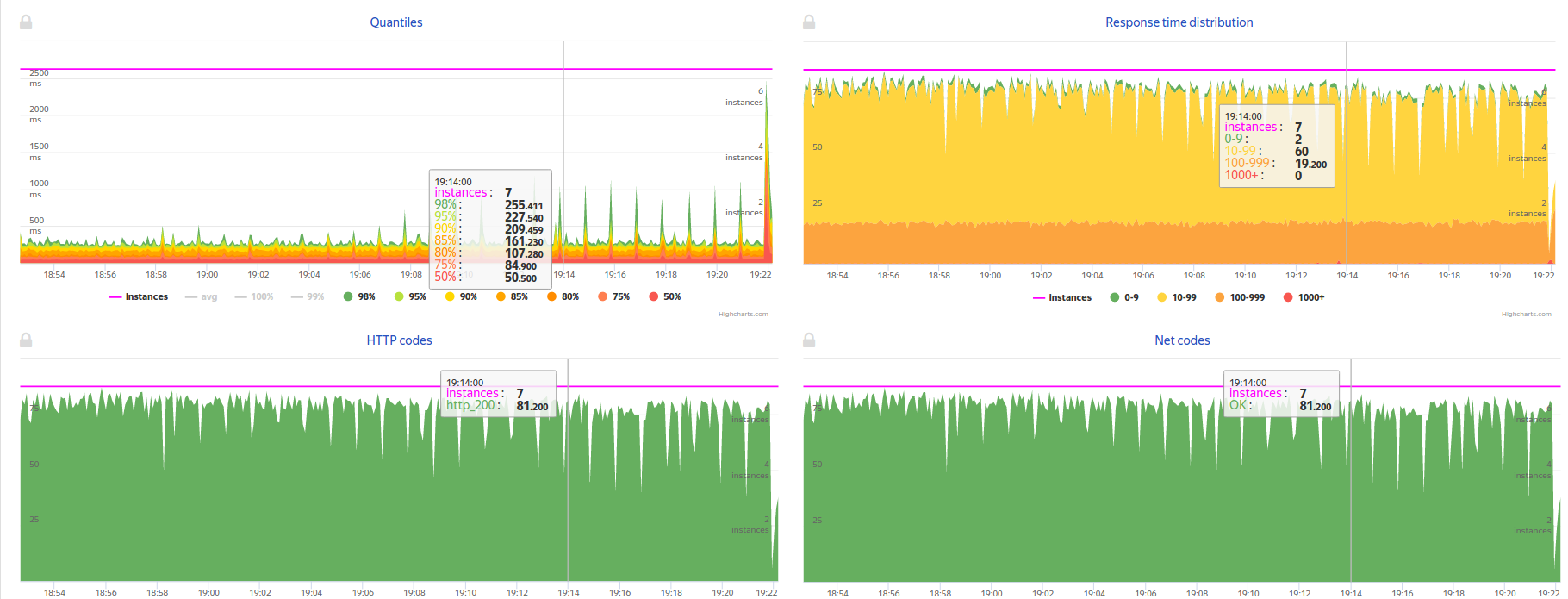
Кликните на картинку, чтобы увеличить изображение После запуска теста вы получаете ссылку в Console View Jenkins и Telegram, перейдя по которой можно наблюдать нагрузочный тест в реальном времени:
Кликните на картинку, чтобы увеличить изображение
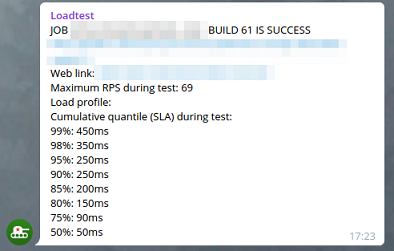
Кликните на картинку, чтобы увеличить изображение Если результаты теста вышли за пределы SLA, то тест автоматически останавливается и вы получаете репорт в Telegram, почту и JIRA о проблемах с релизом. Если же результат хороший, то после репорта релиз получает статус SUCCESS и готов для деплоя на нагруженную среду, в продакшн.
А так бот репортит результаты в JIRA:
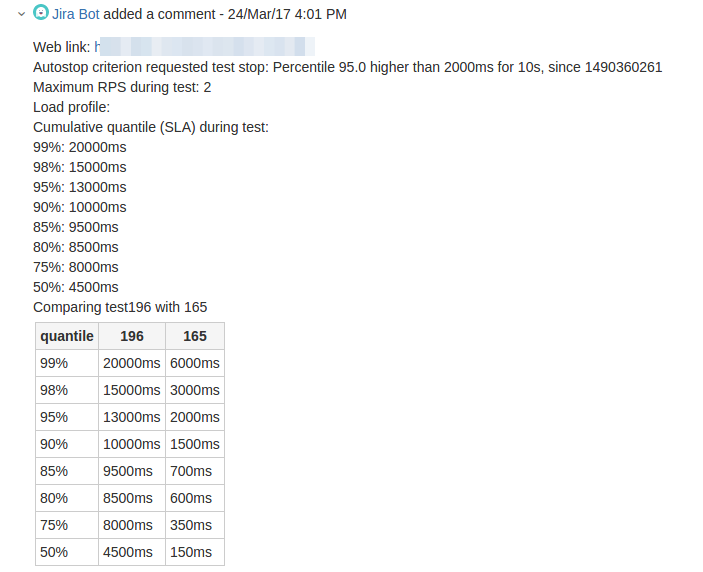
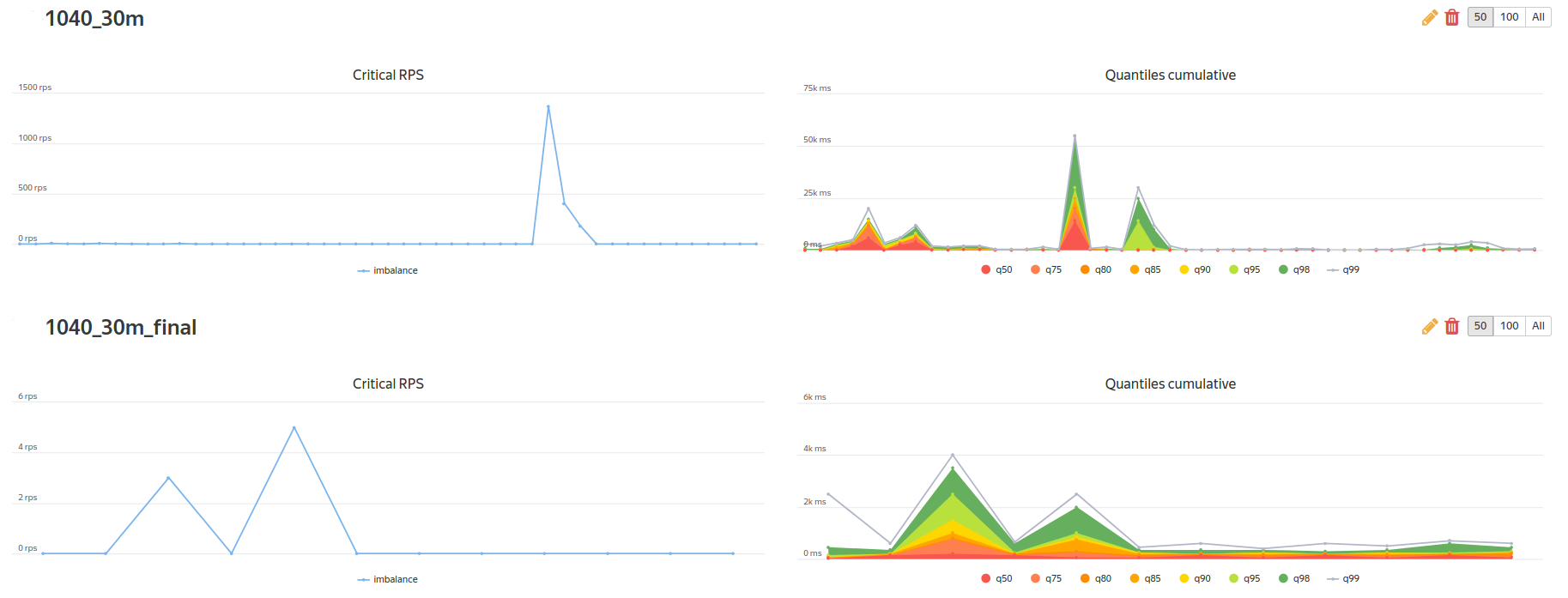
Кликните на картинку, чтобы увеличить изображение В качестве корпоративной “плюшки” от Яндекса мы получили доступ к сравнению тестов:
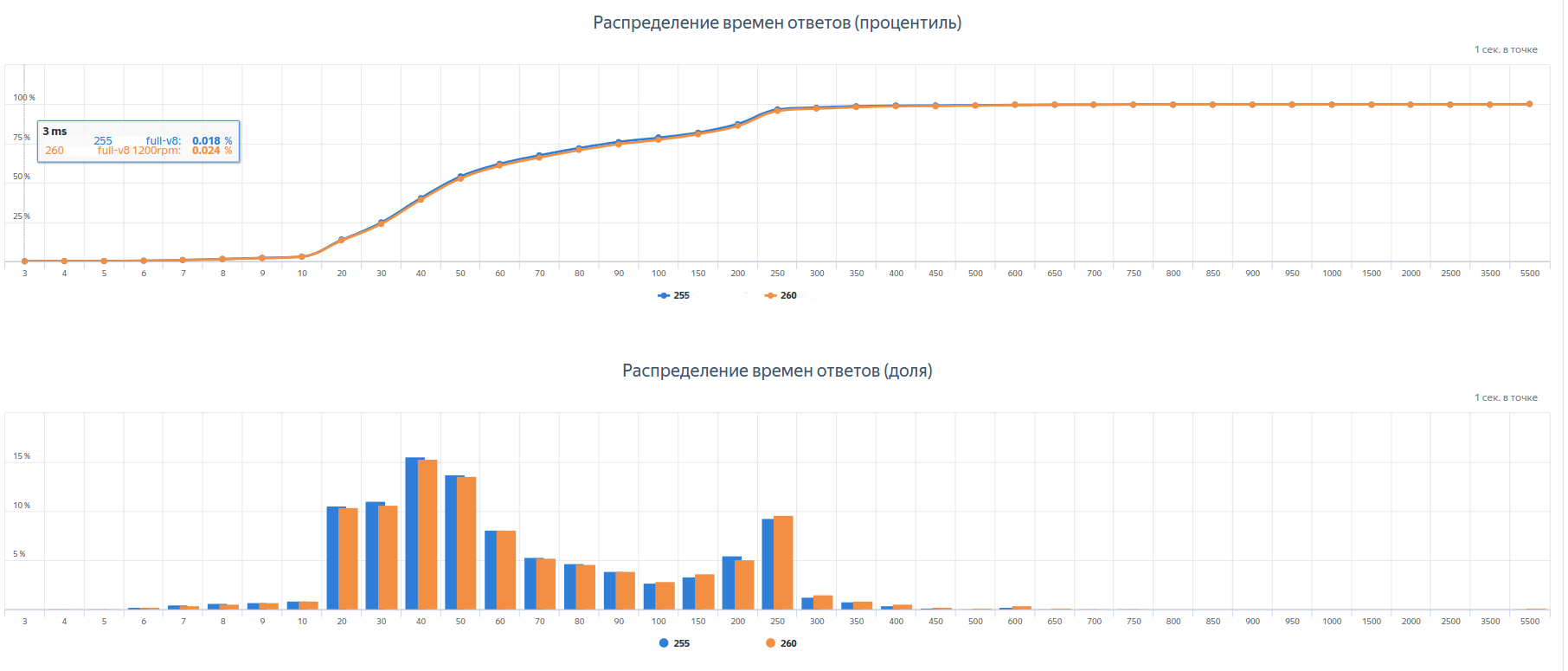
Кликните на картинку, чтобы увеличить изображение и доступ к построению регрессионных отчетов по KPI-метрикам:
Кликните на картинку, чтобы увеличить изображение Проблемы и решения
В данном случае, все метрики с серверов и load-генераторов пишутся в InfluxDB локальными агентами telegraf, а мониторинг Яндекс.Танка уже извлекает данные из InfluxDB простейшим скриптом и пушит данные в Overload. Такой подход позволяет отказаться от поддержки всего зоопарка операционных систем со стороны Яндекс.Танка и избежать необходимости коннекта “от одного ко всем”. from inflow import Client import sys try: connect = Client(sys.argv[1]) try: query_string = "SELECT LAST(" + sys.argv[4] + ") FROM " + sys.argv[3] + " WHERE host='" + sys.argv[2] + "';" result = connect.query(query_string) print (result[0]["values"][0]["last"]) except: print ("Bad request or something wrong with DB. See logs on " + sys.argv[1] + " for details.") except ValueError: print("Something wrong with parameters. " "Usage: python ./influx_picker <http://db_host:port/dbname> <target_host> <group> <metric>") except IndexError: print("Usage: python ./influx_picker <http://db_host:port/dbname> <target_host> <group> <metric>")
<Monitoring> <Host address="localhost" interval="5"> <Custom diff="0" measure="call" label="cpu_sys">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host cpu usage_system</Custom> <Custom diff="0" measure="call" label="cpu_usr">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host cpu usage_user</Custom> <Custom diff="0" measure="call" label="cpu_iowait">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host cpu usage_iowait</Custom> <Custom diff="0" measure="call" label="mem_free_perc">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host mem available_percent</Custom> <Custom diff="0" measure="call" label="mem_used_perc">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host mem used_percent</Custom> <Custom diff="0" measure="call" label="diskio_read">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host diskio read_bytes</Custom> <Custom diff="0" measure="call" label="diskio_write">python influx_picker.py http://<INFLUXDB_IP>:8086/target_host target_host diskio write_bytes</Custom> </Host> </Monitoring>
Кликните на картинку, чтобы увеличить изображение Репортинг. Мы использовали два вида репортинга результатов. Заключение Как можно заметить, данная задача не из разряда Rocket Science, и вы могли читать подобные статьи здесь, здесь и даже смотреть видео здесь. Под капотом лежат обычные скрипты и сервисы ‒ мы всего лишь хотели продемонстрировать, что на самом деле к эре “Devops” и повальной автоматизации финансовый сектор готов уже давно, просто нужно иметь смелость и политическую волю внедрять современные и быстрые процессы.
|