Что пишут в блогах
- TechWriter Days 3. Как это было
- Ричард Румельт. Взлом стратегии.
- Должны ли разработчики тестировать свой код
- Мои 12 недель в году. Часть 33 (вышла книга по SQL, закончила книгу про ИИ)
- Почему SaaS падает при росте нагрузки?
- Как рассчитать реальный предел SaaS
- Эльба: ну вы там как-нибудь сами проверьте, где ошибка произошла
- Почему без реальных пользователей вы тестируете не продукт, а иллюзию?
- QA-агенты. Автономные системы меняют экономику тестирования
- 1 тест = 1 проверка. Чем хорош принцип атомарности в автотестах в Postman

Что пишут в блогах (EN)
- Dr. AI Yourself?
- Test Automation Days Follow Up
- (Un)Ethical AI
- Rabbit, Meet Unemployment Line
- ATD 2026 – The Great Liberation: Software Testing in the Age of AI
- AI and Testing: Improving Retrieval Quality, Part 3
- AI and Testing: Improving Retrieval Quality, Part 2
- AI and Testing: Improving Retrieval Quality, Part 1
- Requirements lead into worse testing?
- AI and Testing: Contextual Precision
Онлайн-тренинги
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 14 апреля 2026
-
Школа тест-менеджеров v. 2.0Начало: 15 апреля 2026
-
Charles Proxy как инструмент тестировщикаНачало: 16 апреля 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 16 апреля 2026
-
Тестирование GraphQL APIНачало: 16 апреля 2026
-
Азбука ИТНачало: 16 апреля 2026
-
Python для начинающихНачало: 16 апреля 2026
-
Инженер по тестированию программного обеспеченияНачало: 16 апреля 2026
-
Программирование на Java для тестировщиковНачало: 17 апреля 2026
-
Автоматизация тестирования REST API на JavaНачало: 22 апреля 2026
-
Тестирование безопасностиНачало: 22 апреля 2026
-
Автоматизация тестирования REST API на PythonНачало: 22 апреля 2026
-
Школа Тест-АналитикаНачало: 22 апреля 2026
-
Тестирование мобильных приложений 2.0Начало: 22 апреля 2026
-
Школа для начинающих тестировщиковНачало: 23 апреля 2026
-
Автоматизация функционального тестированияНачало: 24 апреля 2026
-
Тестирование REST APIНачало: 27 апреля 2026
-
Применение ChatGPT в тестированииНачало: 30 апреля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 30 апреля 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 11 мая 2026
-
Техники локализации плавающих дефектовНачало: 11 мая 2026
-
Логи как инструмент тестировщикаНачало: 11 мая 2026
-
Bash: инструменты тестировщикаНачало: 14 мая 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 14 мая 2026
-
Docker: инструменты тестировщикаНачало: 14 мая 2026
-
SQL: Инструменты тестировщикаНачало: 14 мая 2026
-
Регулярные выражения в тестированииНачало: 14 мая 2026
-
Git: инструменты тестировщикаНачало: 14 мая 2026
-
Организация автоматизированного тестированияНачало: 15 мая 2026
-
Тестирование веб-приложений 2.0Начало: 15 мая 2026
-
Программирование на C# для тестировщиковНачало: 15 мая 2026
-
Создание и управление командой тестированияНачало: 21 мая 2026
-
Программирование на Python для тестировщиковНачало: 22 мая 2026
-
Тестирование производительности: JMeter 5Начало: 29 мая 2026
-
Практикум по тест-дизайну 2.0Начало: 5 июня 2026
-
Аудит и оптимизация процессов тестированияНачало: 5 июня 2026
| Нагрузочное тестирование с locust |
| 07.02.2019 00:00 |
|
Автор: Алексей Остапов Нагрузочное тестирование не так сильно востребовано и распространено, как иные виды тестирования — инструментов, позволяющих, провести такое тестирование, не так много а простых и удобных вообще можно пересчитать на пальцах одной руки. Для тех, кому лень идти под кат, записал видео: Что это?Опенсорс тул, позволяющий задать сценарии нагрузки Python кодом, поддерживающий распределенную нагрузку и, как уверяют авторы, использовался для нагрузочного тестирования Battlelog для серии игр Battlefild (сразу подкупает)
Из минусов:
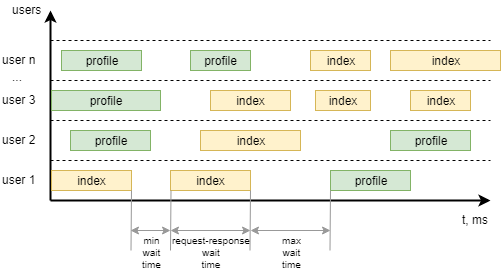
Процесс тестированияЛюбое тестирование — комплексная задача, требующая планирования, подготовки, контроля выполнения и анализа результатов. При нагрузочном тестировании, если есть возможность, можно и нужно собирать все возможные данные, которые могут повлиять на результат:
Описанные далее примеры можно классифицировать как black-box функциональное нагрузочное тестирование. Даже не зная ничего о тестируемом приложении и не доступа к логам, мы можем измерить его производительность. Перед началомДля того, чтобы на практике проверять нагрузочные тесты, я развернул локально простой веб сервер https://github.com/typicode/json-server. Почти все следующие примеры я буду приводить для него. Данные для сервера я взял из развернутого онлайн примера — https://jsonplaceholder.typicode.com/ Подробности установки можно подсмотреть в официальной документации. Разбор примераДалее нам нужен файл теста. Я взял пример из документации, так как он очень прост и понятен:
Здесь же стоит упомянуть, что есть 2 способа объявления поведения пользователя: первый уже указан в примере выше — функции объявлены заранее. Второй способ — объявления методов прямо внутри класса UserBehavior:
Начало работыЗапустим сервер, производительность которого мы будем тестировать:
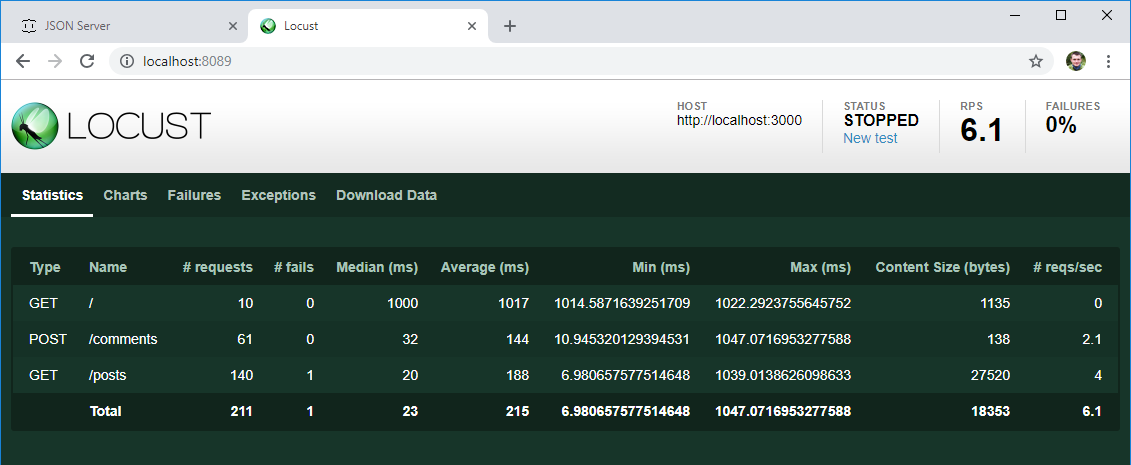
где host — адрес тестируемого ресурса. Именно к нему будут добавлены адреса сервисов, указанные в тесте. РезультатыЧерез определенное время остановим тест и взглянем на первые результаты:
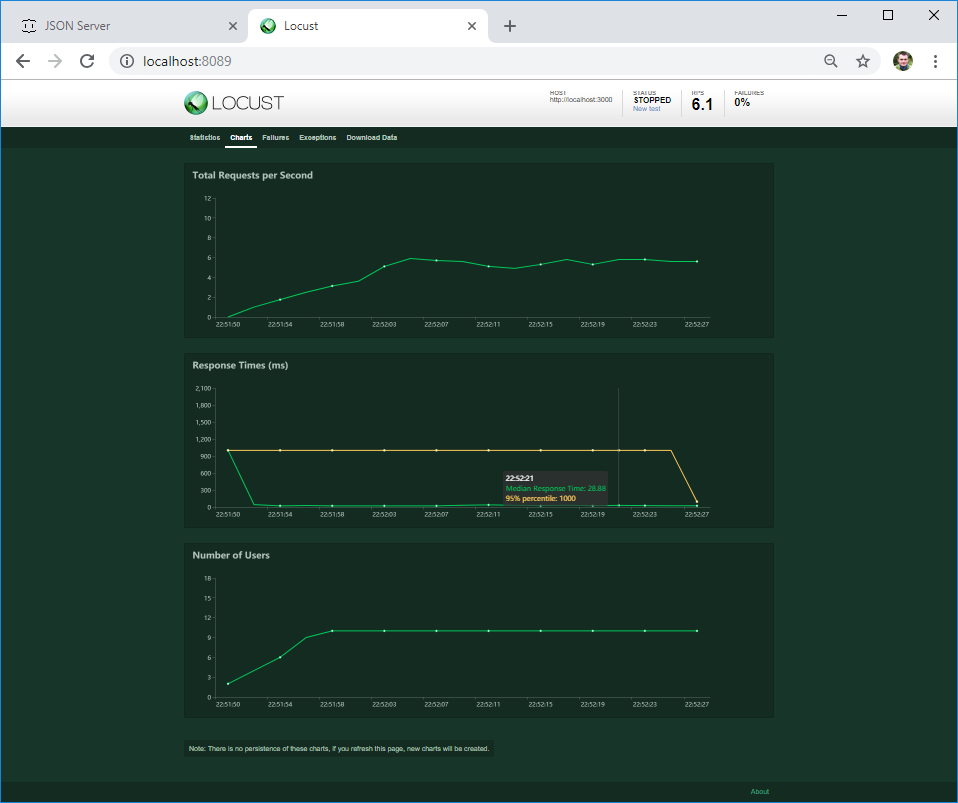
На второй вкладке можно посмотреть графики нагрузки в режиме реального времени. В случае, если сервер падает при определенной нагрузке или его поведение меняется, на графике это будет сразу видно.
|