Что пишут в блогах
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Азбука ИТНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Python для начинающихНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
| Руководство по тестированию производительности – с чего начать |
| 01.06.2018 12:10 |
|
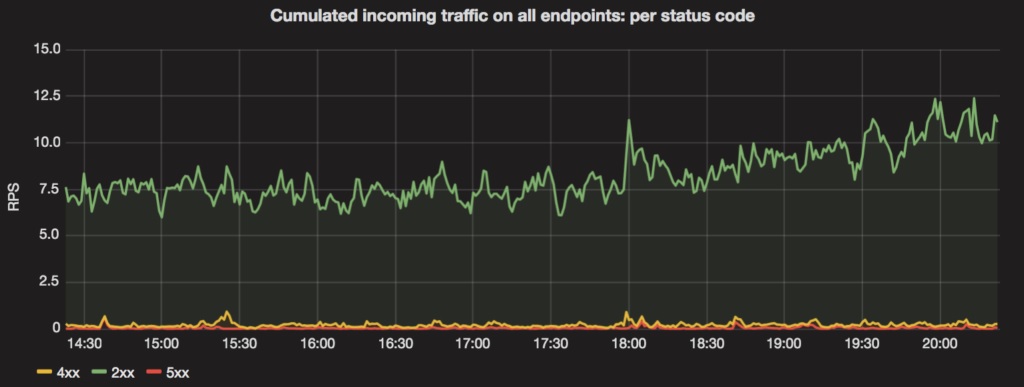
Перевод: Анна Радионова Я заметил, что тема тестирования производительности все еще остается не до конца понятной для большинства тест-инженеров. Мы стремимся сфокусировать внимание на функциональном аспекте тестирования, оставляя производительность, масштабирование и настройку на усмотрение разработчиков. Разве не является стабильность существенной составляющей качества программного продукта? Особенно во времена распределенной обработки данных, когда мы масштабируем приложения независимо друг от друга и всецело рассчитываем на внедрение интеграций по HTTP протоколу. Другим существенным фактором является возможность расширения систем. Для того, чтобы справиться с увеличением трафика, мы должны быть осведомлены об ограничениях пропускной способности. Существует несколько хорошо известных тестировщикам инструментов, таких как JMeter, Gatling, Tsung и т.д. И хотя они довольно просты в использовании, анализ полученных результатов и выводы на их основании представляют для тестировщиков сложность. Во время проведения собеседований на позицию QA инженера я часто встречаю кандидатов, утверждающих, что у них есть опыт в области тестирования производительности, но, по факту, не обладающих знаниями метрик и основных понятий с ним связанным. Поскольку основной задачей тестирования производительности является не знание инструментария, а данные, полученные с его помощью, цель этой статьи - рассмотреть основные аспекты этой сферы тестирования. Тест на производительность vs Нагрузочный тест Одно из основных заблуждений заключается в смешении понятий тестирования производительности и нагрузочного тестирования. Оба эти термина зачастую используются как синонимы, но совершенно очевидно, что это разные понятия. Цель тестирования производительности - выявить “узкие места” в системе или архитектуре. Существует выражение, что наша система является настолько быстрой, насколько быстр наш самый медленный сервис. Представим, что система состоит из различных микросервисов. У каждого существует свое время ответа или расчетная (предполагаемая) нагрузка. В таком уравнении существует даже больше переменных как, например, тип базы данных, серверов или местоположение центра обработки данных. Пользователям приложения нужны две вещи: быстрое время ответа и высокая отказоустойчивость. С помощью тестирования производительности мы можем выявлять эти узкие места в архитектуре и масштабировать, конфигурировать и регулировать сервисы независимо для достижения такого быстродействия конечными пользователями. А что насчет высокой отказоустойчивости? Эта характеристика как раз на стороне нагрузочного тестирования. Проще говоря, нагрузочное тестирование - это проверка нашей системы с помощью огромного количества одновременных пользователей или подключений, которые и являются нашей нагрузкой. Это количество мы постоянно увеличиваем для достижения максимального количества задач, с которыми система может справиться. Нагрузочное испытание наиболее актуально при релизе нового сервиса, когда нужно проверить, выдержит ли он ожидаемый поток трафика. Цель такого испытания - проверка работоспособности всей системы, а не производительность ее отдельных сервисов. И хотя методы проведения нагрузочного тестирования и тестирования производительности кажутся схожими с точки зрения инструментария и техник, различия становятся более явными при анализировании результатов и определении способов реагирования. Время задержки, пропускная способность и ширина пропускания канала Как я уже сказал, определяющую роль в нагрузочном тестировании и тестировании производительности играет анализ результатов. Чтобы его сделать, необходимо знать основные метрики производительности. В особенности в мире сетевого взаимодействия, очень важно снимать метрики времени задержки, пропускной способности и ширины пропускания канала:
В то время как ширина пропускания канала, как правило, величина постоянная (в определенный период времени), очень важно производить анализ метрик времени задержки и пропускной способности параллельно, т.к., основываясь на них, можно сделать заключение о производительности вашего приложения. Процентили После измерения времени задержки, одним из use-кейсов, который приходит на ум, является подсчет среднего времени задержки в определенный отрезок времени. Первые статистические данные, которые кажутся необходимыми для расчета - это расчет средне-арифметического значения. Однако, сложность состоит в том, что средне-арифметическое значение очень чувствительно к большим отклонениям. Поскольку схема времени задержки выглядит довольно равномерной с несколькими заметными всплесками, процентили являются более подходящей статистической единицей в этом случае. Если вам нужно измерить среднее время задержки сервиса, вы можете использовать медиану, которая является 50-м процентилем (p50). Но помните, что p50 также очень чувствительна к статистическим колебаниям. Наиболее используемыми величинами для измерения среднего времени ответа являются 90-й и 99-й процентили (p90 и p99). Например, если время задержки для p90 составляет 1ms, это означает, что в 90% случаев ваш сервис отвечает по истечению 1ms. Частота появления ошибок Как уже было сказано, при измерении показателя пропускной способности мы получаем величину объема трафика, который обрабатывается сервисом, но что можно сказать об ответах? Коды ответов сервиса (2xx, 4xx или 5xx) имеют существенное значение. По ним определяется частота появления ошибок. Цель мониторинга частоты появления ошибок - определить, какое количество (или процент) ответов сервиса составляют положительные ответы и т.п. Всегда есть доля ответов с ошибками (в том числе связанных с валидацией на клиенте - 4xx код). И если мы замечаем внезапные всплески на диаграмме частоты появления ошибок, это может говорить о неполадках сервиса. Пример схемы частоты возникновения ошибок приведен на рисунке выше. Заключение В последнее время я замечаю, что тестировщики пытаются использовать инструменты для проведения тестирования производительности, не владея основными понятиями области тестирования производительности и нагрузочного тестирования. Для эффективной отладки и масштабирования системы нужно понимать, ЧТО необходимо измерить, а КАК измерить - вопрос второстепенный.
|