Что пишут в блогах
- Новогодний QA квиз
- Не просри свое время
- Гуру на Урале 4 декабря
- Мои 12 недель в году. Часть 32 (ДР Влада и мой, болезни...)
- Опрос удовлетворенности работой 2025
- DB Fiddle — бесплатная SQL песочница!
- Митап в Т-Банке 20 ноября
- Как яндекс диск сдох при одновременном перемещении папки
- ChatGPT для общения с англоязычной техподдержкой
- Книга: Лидер и племя. Дэйв Логан, Джон Кинг, Хэли Фишер-Райт

Что пишут в блогах (EN)
- User Error
- Dis Is Weird
- Software Testing Weekly – 294th Issue
- IEEE Report: How IT Managers Fail Software Projects
- Observations of a habit transformation
- Agile Testing Days – 2025
- Alun Turing FTW
- On finding clients as an independent consultant
- The State of AI in 2025: McKinsey Report
- Platform Product Testing
Онлайн-тренинги
-
Программирование на Python для тестировщиковНачало: 19 декабря 2025
-
Selenium IDE 3: стартовый уровеньНачало: 19 декабря 2025
-
Python для начинающихНачало: 25 декабря 2025
-
Азбука ITНачало: 25 декабря 2025
-
Логи как инструмент тестировщикаНачало: 12 января 2026
-
Тестирование REST APIНачало: 12 января 2026
-
Школа для начинающих тестировщиковНачало: 15 января 2026
-
Применение ChatGPT в тестированииНачало: 15 января 2026
-
Инженер по тестированию программного обеспеченияНачало: 15 января 2026
-
Тестирование GraphQL APIНачало: 15 января 2026
-
Charles Proxy как инструмент тестировщикаНачало: 15 января 2026
-
Регулярные выражения в тестированииНачало: 15 января 2026
-
Bash: инструменты тестировщикаНачало: 15 января 2026
-
SQL: Инструменты тестировщикаНачало: 15 января 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 15 января 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 15 января 2026
-
Git: инструменты тестировщикаНачало: 15 января 2026
-
Docker: инструменты тестировщикаНачало: 15 января 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 15 января 2026
-
Организация автоматизированного тестированияНачало: 16 января 2026
-
Тестирование производительности: JMeter 5Начало: 16 января 2026
-
Практикум по тест-дизайну 2.0Начало: 16 января 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 19 января 2026
-
Техники локализации плавающих дефектовНачало: 19 января 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 20 января 2026
-
Создание и управление командой тестированияНачало: 22 января 2026
-
Программирование на Java для тестировщиковНачало: 23 января 2026
-
Тестирование мобильных приложений 2.0Начало: 29 января 2026
-
Автоматизация тестирования REST API на JavaНачало: 29 января 2026
-
Автоматизация тестирования REST API на PythonНачало: 29 января 2026
-
Автоматизатор мобильных приложенийНачало: 29 января 2026
-
Тестирование безопасностиНачало: 29 января 2026
-
Автоматизация функционального тестированияНачало: 30 января 2026
-
Школа тест-менеджеров v. 2.0Начало: 4 февраля 2026
-
Аудит и оптимизация QA-процессовНачало: 6 февраля 2026
-
Тестирование веб-приложений 2.0Начало: 6 февраля 2026
-
Школа Тест-АналитикаНачало: 11 февраля 2026
-
Программирование на C# для тестировщиковНачало: 13 февраля 2026
| QA на проде. Почему это круто |
| 26.06.2019 00:00 |
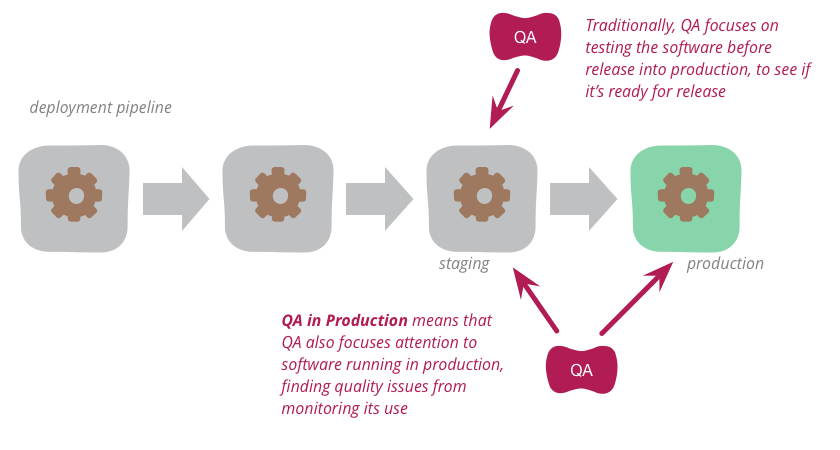
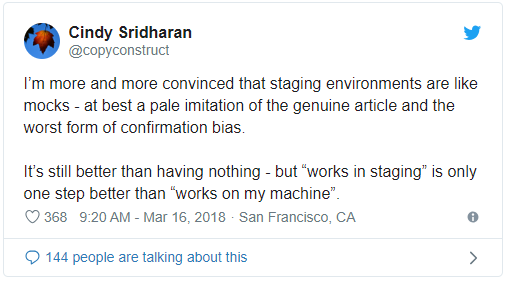
 Автор: Ольга Михальчук, QA инженер ID Finance Многие считают тестирование на production окружении вредной практикой: оно не помогает предотвратить попадание проблем к конечным пользователям, а больше констатирует их наличие. Кроме этого, тестировщик отрывается от стандартного рабочего процесса и методик, применяемых на тестовом окружении. Меня зовут Оля Михальчук, я QA-инженер в финтех-компании ID Finance. В этом посте я расскажу почему тестирование на проде может существенно помочь вашему проекту. Зачем нужно QA на проде, если есть пре-продакшн окружение В процессе разработки ПО всегда есть несколько окружений, на которых развёрнуто приложение. Среда, которой пользуются конечные пользователи, как вы знаете, называется production. Обычно предполагается, что тестирование нужно проводить на отдельном окружении, чаще на QA environment или Staging (пре-прод), чтобы предотвратить попадание ошибок к пользователям. Но есть такая методика, как QA на проде, которая отлично помогает решить задачи, которые на тестовом окружении решить физически невозможно. В каких задачах помогает QA на проде1. Проблема различия Staging и Production окружений. |