Что пишут в блогах
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Азбука ИТНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Python для начинающихНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
| История о свершениях одного QA: о Quality Gates и оптимизации релизных процессов в ОК |
| 27.08.2025 00:00 | ||||||||||||||||||
|
Задача любого тестировщика — проверять продукт на соответствие установленным требованиям и своевременно отлавливать любые баги и ошибки. В идеальных условиях или небольших проектах эта схема работает безотказно. Но в ситуациях, когда над продуктом работает несколько команд разработки, в релизы попадает по 30–70 задач, а обновления выкатываются каждую неделю, фокуса тестировщиков может просто не хватить. В таких условиях не обойтись без Quality Gates. Меня зовут Юлия Садовникова. Я старший специалист по тестированию в команде Core Android компании ОК. В этой статье я расскажу о Quality Gates в ОК и о том, как QA может не просто тестировать, а реально влиять на проект и процессы. Как устроено тестирование в ОКОК — крупная российская соцсеть, которой ежедневно пользуется 38 млн пользователей по всему миру. Android‑приложение ОК доступно уже более 10 лет и за это время скачано более 100 млн раз. В ОК выделено три направления тестирования:
В ОК есть Quality Gates как для продуктовых команд, так и для самого продукта. Примечание: Quality Gates — заранее определенные этапы, во время которых проект проверяется на соответствие необходимым критериям для перехода к следующему этапу. Цель Quality Gates — обеспечить следование набору определенных правил и практик, чтобы предотвратить риски и повысить качество проекта. Quality Gates для процессов в командеДля продуктовых команд Quality Gates реализованы с применением нескольких практик.
Quality Gates для продуктаВ контексте продукта контроль качества и соответствия требованиям обеспечивают:
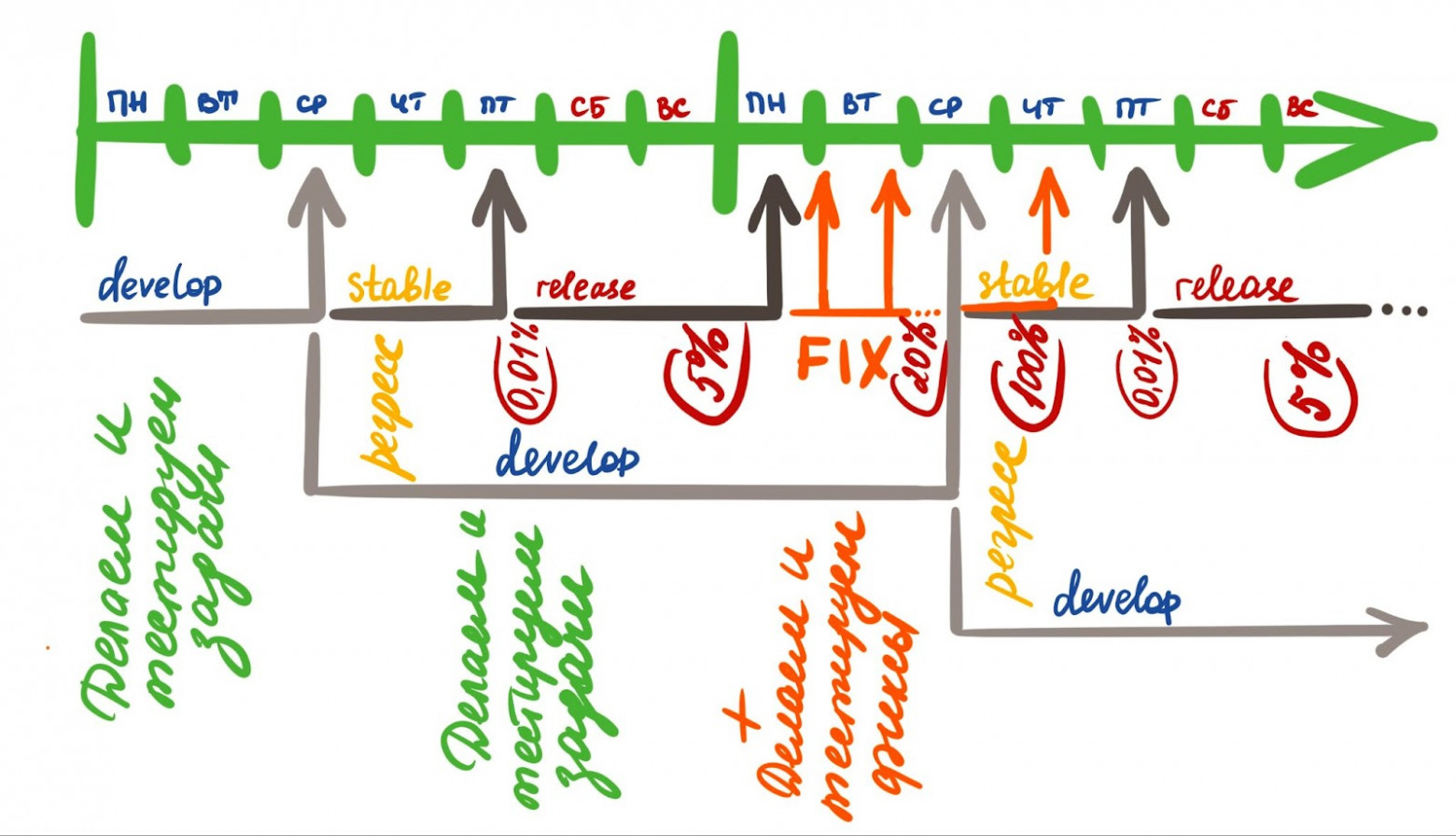
Релизные циклы или история о стабильностиРелизный цикл ОК стабилен более 7 лет — на каждый релиз приходится от 30 до 70 задач, а обновления выходят раз в неделю (не считая фиксовых релизов). С 2019 года, когда я пришла в команду Core Android, процесс строился следующим образом:
Схематично релизный цикл выглядел примерно следующим образом:
Но у такой схемы был один существенный недостаток — поскольку некоторые ветки и релизы накладываются друг на друга, контролировать все процессы небольшой команде QA становится крайне сложно, и практически невозможно, если тестировщик остается один. Столкновение с реальностью и выстраивание новых гейтовВ моей Core Android команде, как и других, работало два тестировщика. Но в 2020 году мой напарник решил уйти из компании, и все процессы остались на мне. К тому моменту у нас уже были:
Но эффективно управлять этим массивом и всеми релизными процессами в одиночку — сложная задача с высокими перегрузками, которые потенциально могли привести к деградации всего продукта. Поэтому было принято решение двигаться в сторону комплексной оптимизации. Первая гипотезаНа первом этапе возникла самая очевидная гипотеза, что можно выпускать релизы реже. Но сразу стало понятно, что рисков и издержек у такого варианта больше, чем потенциальной выгоды:
Одновременно увеличение релизных циклов могло негативно повлиять как на продуктовые метрики, так и на лояльность пользователей:
Соответственно, от идеи с увеличением релизного цикла мы отказались. Вторая гипотезаДалее возникла гипотеза, что можно сократить число девайсов, для который выполняется регресс. Так, ранее под регресс попадали:
При этом регресс у нас занимал несколько дней — с 8:00 среды до вечера пятницы, и время его окончания не было строго определено. Из‑за этого могли возникать проблемы — например, фиксы могли влить в ветку stable в пятницу, вплоть до окончания рабочего дня, несмотря на то, что релиз уже проверен и почти готов к выпуску. Выпуск самого приложения занимал примерно 1,5 часа. Чтобы снизить нагрузку на тестировщиков и уйти от существующих недостатков, было решено оставить регресс только для:
Смоуки и различия начали проверять на максимальной и промежуточной версиях. Более того, вместо относительно свободного формата проведения регресса были установлены более четкие правила:
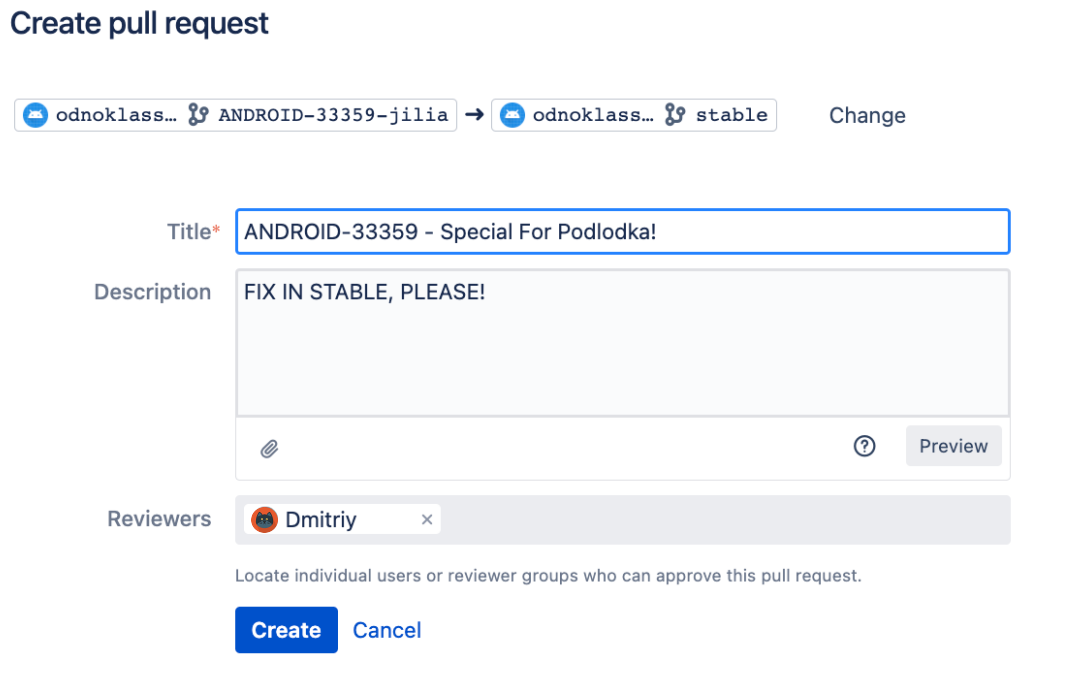
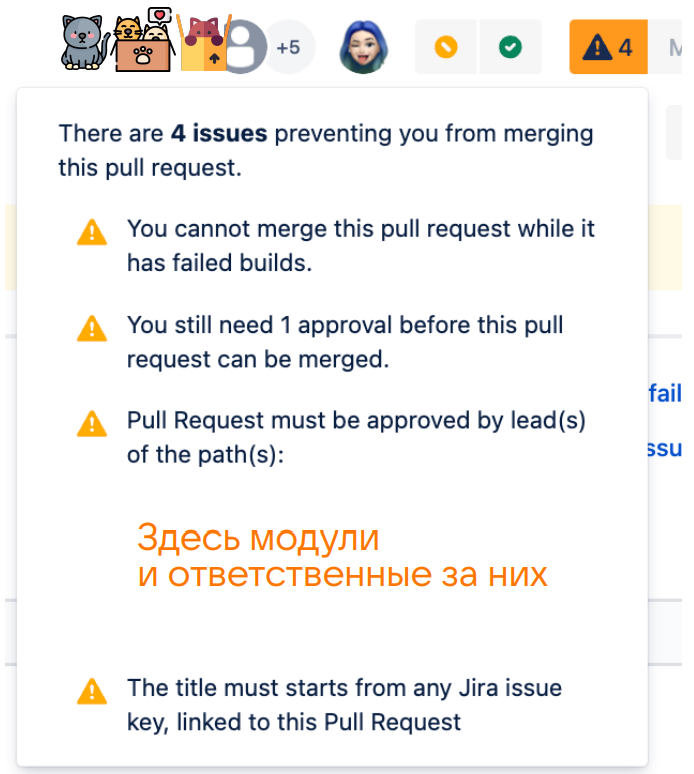
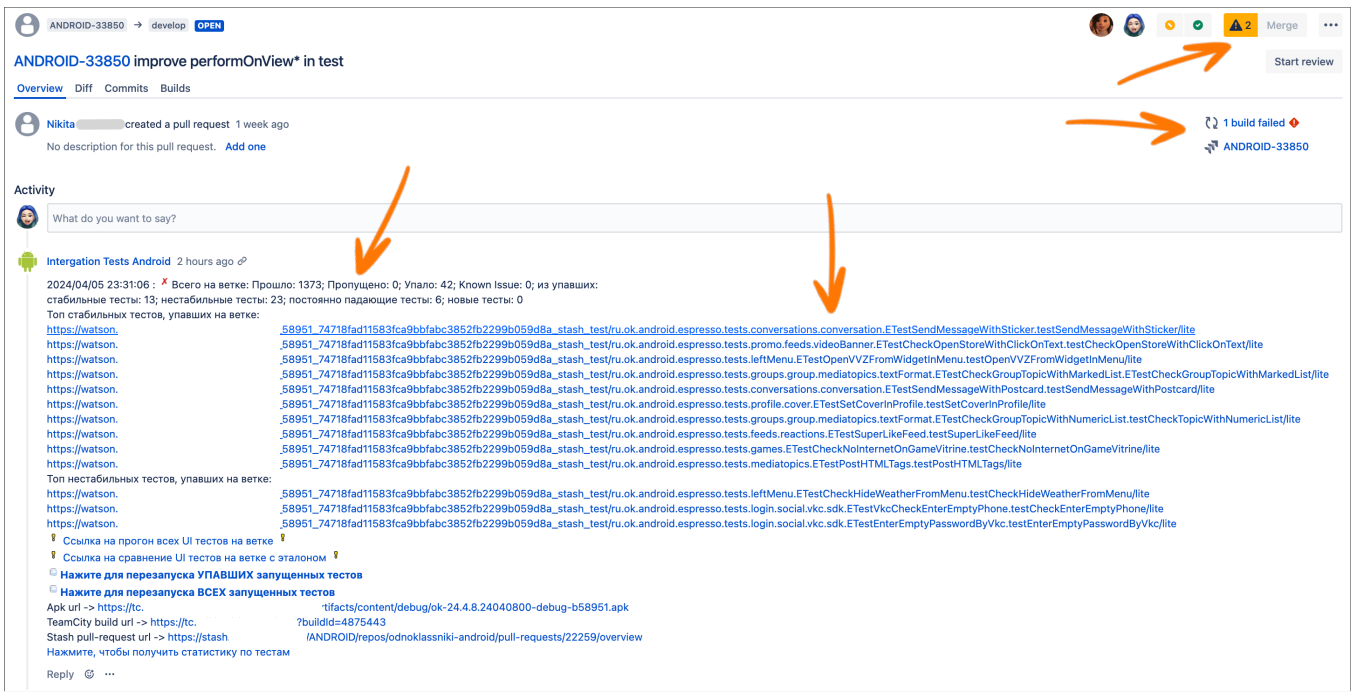
Таким образом мы исключили попадание в прод фичей, не прошедших тестирование, и ушли от ночных релизов. Новые правила для разработчиковДалее я перешла от решения существующих недочетов к выработке практик и мер, которые могут минимизировать сложности в будущем. Для этого изначально был проведен глубокий анализ текущего состояния. Push напрямую в веткиОказалось, что у нас был разрешен push напрямую в ветки develop/stable/release (без создания merge‑реквеста). Это проблема не была подсвечена ранее и потенциально могла превратиться в катастрофу (спойлер: и даже иногда превращалась). Поэтому было принято решение оставить возможность пушить напрямую в ветку только определенному списку дежурных разработчиков и core QA — для остальных при push напрямую будет ошибка. Дежурные разработчики не предупреждены о возможных фиксахДалее я столкнулась с тем, что дежурные разработчики не всегда знали о различных фиксах и задачах в релизной ветке. Из‑за этого разработчики могли случайно или даже специально залить свою задачу в ветку stable и release без договоренностей с дежурными. При этом такие задачи могли задевать чужие разделы, в то время как команда, отвечающая за раздел, даже могла не знать об этом. Отчасти это было возможно, поскольку, чтобы попасть в ветку stable — release, задаче был нужен только один любой апрув, а любые договоренности с дежурным разработчиком были только на словах. Чтобы свести к нулю подобные риски, была придумана система апрувов от дежурных, в рамках которой дежурный разработчик автоматически добавляется во все merge‑реквесты, направленные в ветки stable и release, а апрув дежурного становится обязательным для мерджа. В Bitbucket это теперь выглядит следующим образом: при создании merge‑request автоматически добавляется reviewer — разработчик, который дежурит на этой неделе.
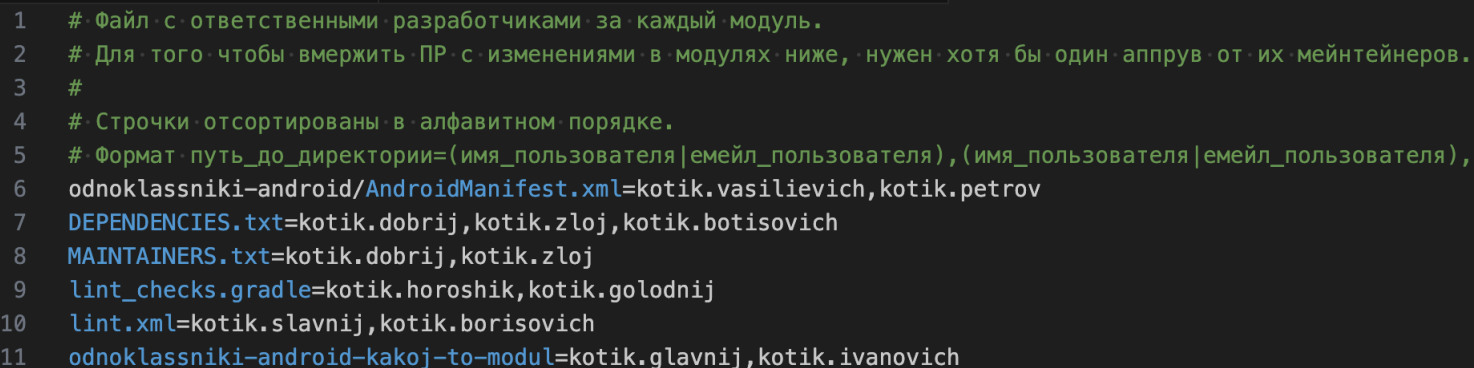
Затрагивание чужих разделов Как я уже упомянула ранее, задачи, залитые без предупреждения, могли затрагивать разделы других команд без их ведома. Чтобы исключить такую возможность и сопутствующие ей риски, мы добавили в проект файл с ответственными разработчиками за каждый модуль (их должно быть два) и сделали обязательным хотя бы один аппрув от мейнтейнеров, если задет чей‑то раздел.
На практике это работает следующим образом:
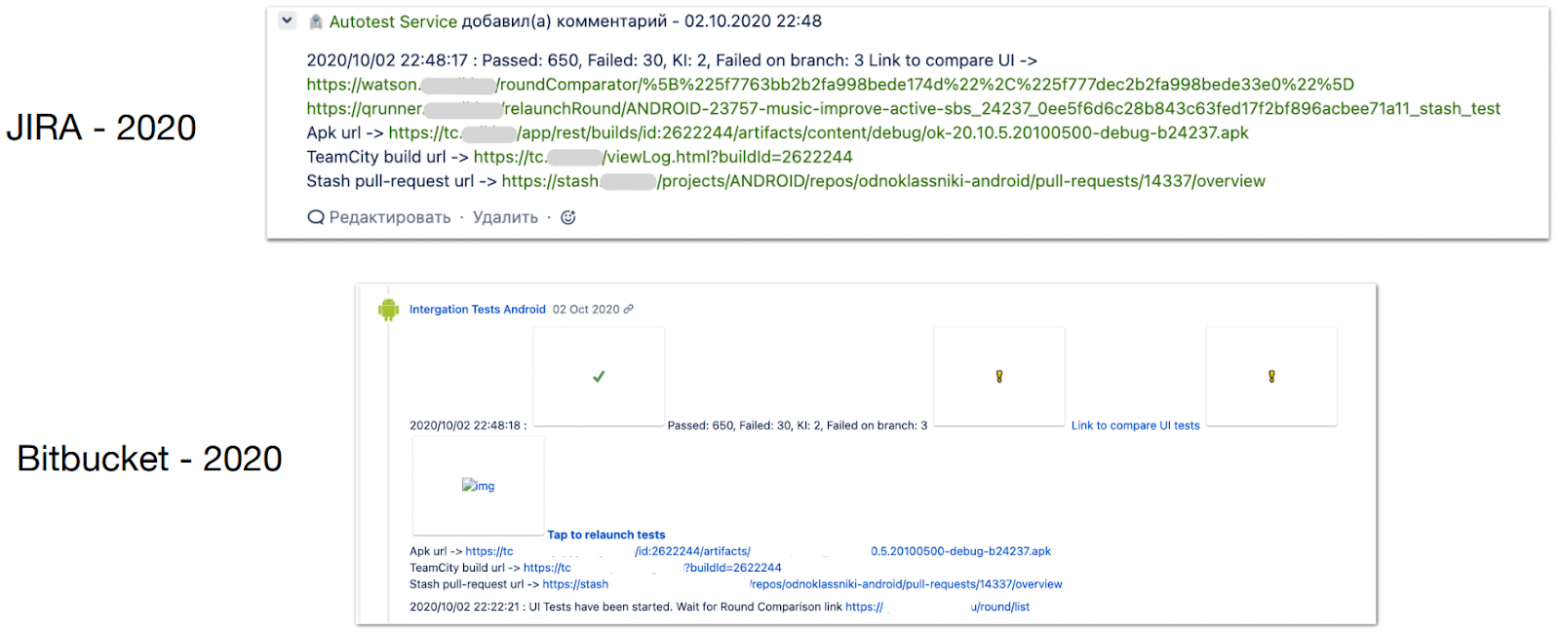
Соответственно, без согласований merge‑реквест не может быть залит. Новые правила для всехОт проблем и оптимизации в части задач разработчиков я перешла к общей оптимизации релизных процессов. Работа с тестамиВ 2020 году у нас уже было реализовано сообщение в Jira и Bitbucket с полезной информацией о билдах. В нем были отчеты о прогонах автотестов, прикрепленные билды, ссылки на merge‑реквест и другие данные.
У нас была вся информация, но в условиях отсутствия строгих регламентов пользы от нее было мало:
Решением стали доработки, реализованные со стороны команды автоматизации и на стороне Bitbucket. Теперь наглядно видно всю информацию обо всех упавших тестах и при падении стабильного теста на выходе будет красный билд — залить merge‑реквест не получится.
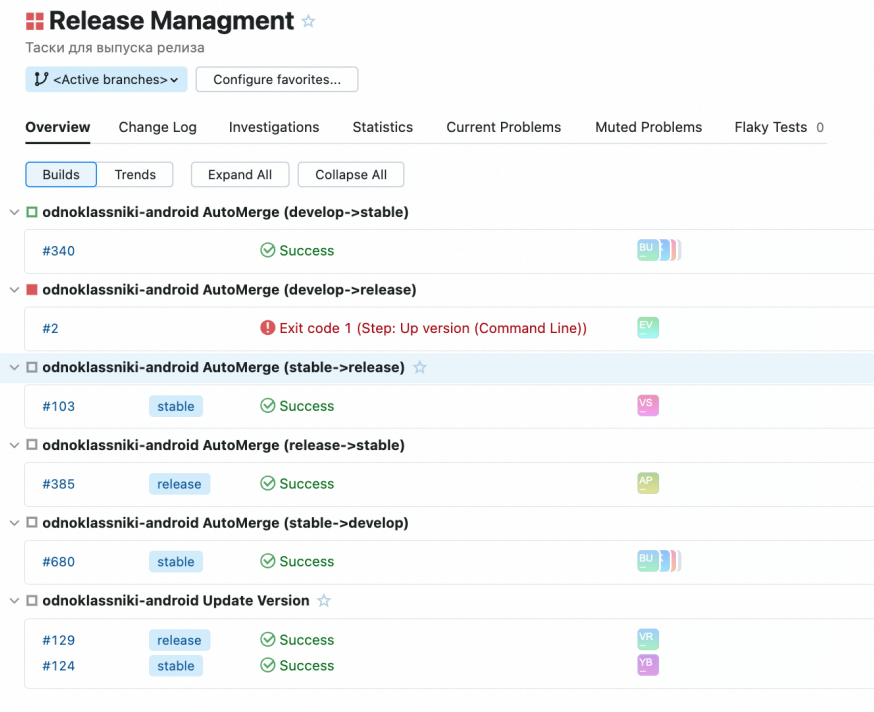
Работа с ветками и версиямиПомимо прочего, я сталкивалась с необходимостью постоянно пинговать разработчиков для отвода веток — например, из Develop в Stable, из Stable в Release. Кроме лишних коммуникаций, это было сопряжено еще и с вынужденным ожиданием — на сборку и переключение разработчика между ветками могло уходить до 1,5–2 часов. Для оптимизации было принято решение создать джобы на CI для менеджмента релизов, собрать их в одном пространстве. Благодаря этому, теперь дежурный разработчик и/или дежурный тестировщик могут сами отводить ветки без переключения между ними и длительных ожиданий.
С поднятиями версий была аналогичная проблема — я была зависима от разработчиков и была вынуждена их пинговать. Для оптимизации в этом случае была написана отдельная джоба, в которой прописывались version code и version name. Нюанс в том, что при ручном поднятии версии сборку приходится ждать лишние 30–40 минут. Поэтому мы с разработчиками пошли дальше и добавили накрутку версии в джобу автоматического автоотвода веток. При этом версия берется из календаря версий в Jira, а сборка выполняется со всеми изменениями. Таким образом мы ушли от длительного ожидания сборки. Дополнительно мы реализовали нотификации от бота, что упростило отслеживание состояние джоб.
Выкладка в сторыТакже мы хотели управлять выкладкой оперативно и в одном месте сразу в несколько сторов. Поэтому решили использовать API от Google, RuStore и AppGallery, чтобы с помощью джобы в любой момент иметь возможность управлять публикациями: загружать, поднимать процент, полностью раскатывать и выполнять другие действия.
Введение SLA на креши и баги Также мы сталкивались с проблемой, что заведенные креши или баги фиксили очень долго либо не фиксили вообще — некоторые мажорные или минорные таски могли висеть годами.
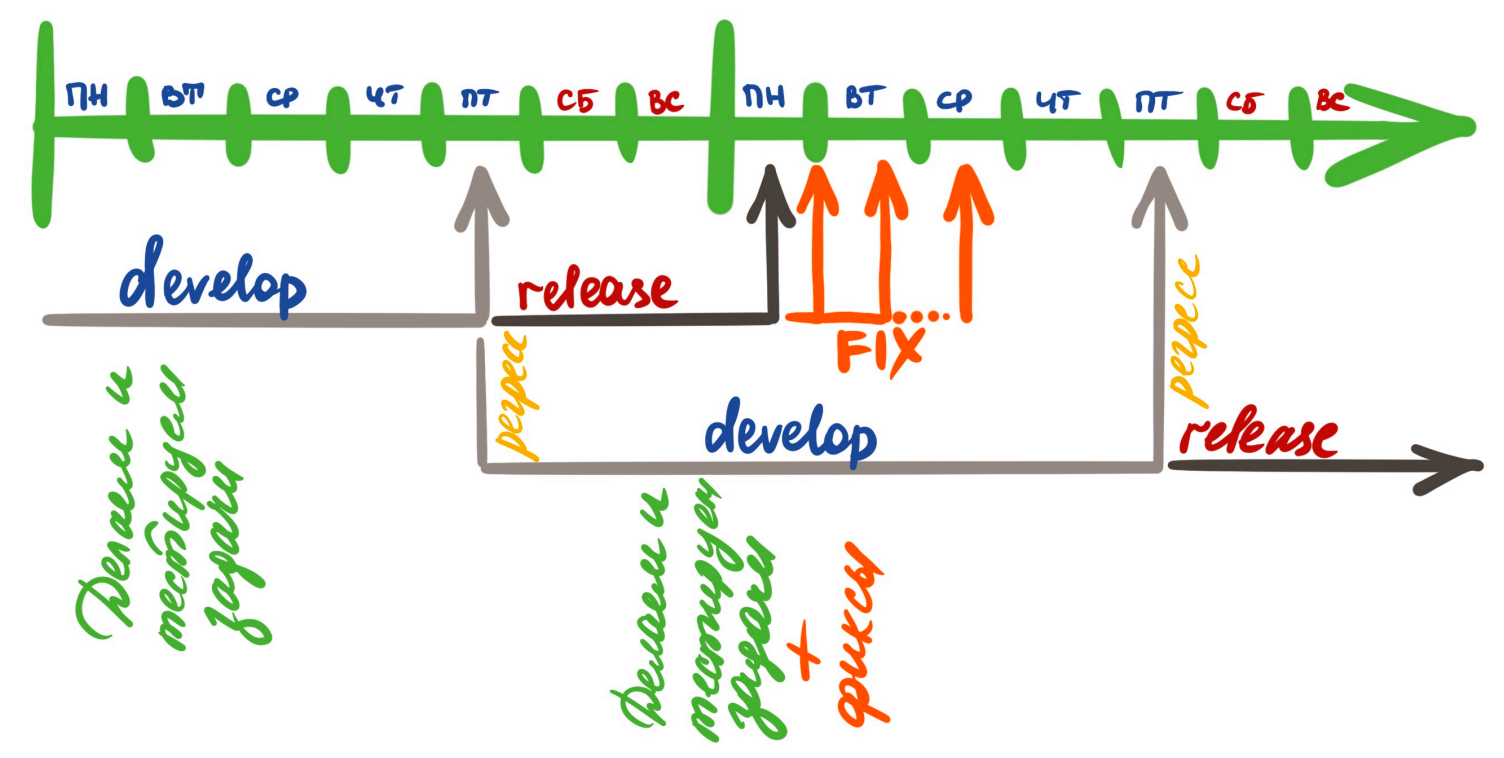
Для удобства также подключили нотификации, которые помогают отслеживать сроки фикса крешей. Отказ от стабильной веткиВ начале 2025 года мы отказались от стабильной ветки — это стало возможным благодаря масштабированию автоматизации на проекте. Так, если в 2019 году у нас было всего 640+ тестов, то к 2025 их число выросло до 1647. То есть мы полностью автоматизировали ручной регресс core команды. Это позволило нам практически безболезненно отказаться от ручного регресса. Но чтобы такой отказ не спровоцировал деградацию процессов и всего продукта, мы:
Вместо исходной реализации с тремя ветками, код фризом утром в среду и регрессом продолжительностью в три дня, мы пришли к новой модели:
Соответственно, изменилась и схема релизных процессов. Так, раньше у нас ветки и релизы могли накладываться друг на друга, а на регресс уходило много времени.
Сейчас же наложение релизов маловероятно, на регресс надо минимум времени, а работа с двумя ветками заметно упростила работу дежурных разработчиков и тестировщиков.
Примечание: Во время подготовки этой статьи наши процессы снова немного трансформировались — мы непрерывно работаем над их улучшением. Теперь наши раскатки приложения в Play market стали проходить по новым процентам: 0.01–5–20–99.99–100%. Это обусловлено тем, что мы хотим иметь возможность манипулировать раскаткой выпущенной версии, и, если необходимо, откатываться к прошлой. Но если ваша версия уже находится на 100% — ничего с ней сделать нельзя. Итоги и планы на будущееПроделанная работа подтверждает, что Quality Gates в релизных процессах — действительно полезный инструмент для нахождения проблем на более ранних этапах разработки и тестирования. Убедилась я и в том, что QA может не только тестировать свой продукт, но и эффективно оптимизировать процессы, в которых работает — я прошла через это лично. Например, благодаря работе над процессами, уменьшился Time to market и освободилось больше времени на написание автотестов. Профит от проделанной работы особенно заметен в числах.
Но мы не останавливаемся на достигнутом и продолжаем комплексную оптимизацию. Так, в перспективе планируется реализовать и добавить:
О том, что из этого получится — расскажем в одной из следующих статей. А пока делитесь в комментариях используемыми практиками проверки проекта на соответствие требованиям и отсутствие багов. |


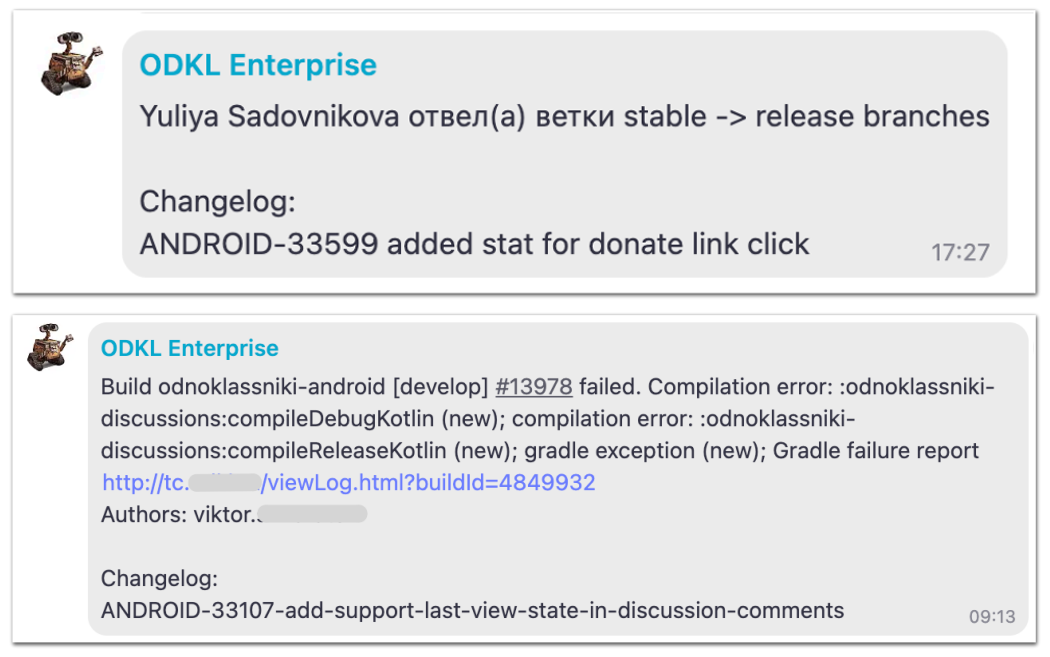

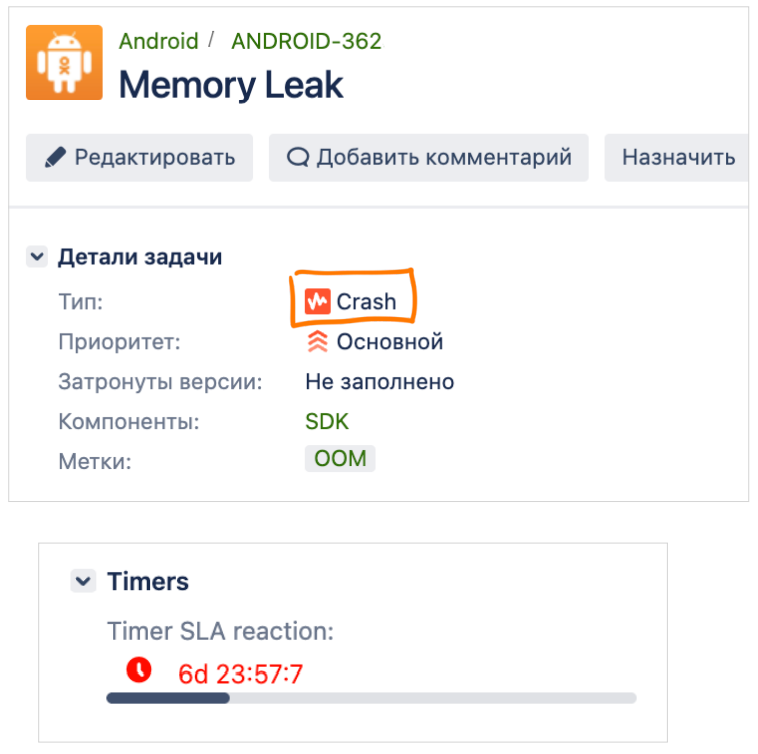 Поэтому было принято решение ввести SLA на креши разного типа. Теперь:
Поэтому было принято решение ввести SLA на креши разного типа. Теперь: