Что пишут в блогах
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Python для начинающихНачало: 16 июля 2026
-
Азбука ИТНачало: 16 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
| QA-метрики: когда они могут быть полезны и как их использовать |
| 22.08.2023 00:00 | ||||||||||||||||||||||||||||||||||||||||||
|
Автор: Копцова Екатерина, руководитель служб тестирования в Яндексе Многие команды сталкиваются с необходимостью формализовать показатели эффективности своей работы для оценки её качества и выявления возможных проблем. Существует множество метрик, с помощью которых оцениваются команды, создаются SLA, KPI, дашборды и графики для визуализации и прочие инструменты. Зрелым командам такие метрики ощутимо помогают:
Меня зовут Катя, я руковожу службами тестирования Музыки и Букмейта, и в этом посте я хочу рассказать про основные метрики, которые мы используем в команде тестирования Яндекс Музыки, и обсудить, как правильно с ними работать.
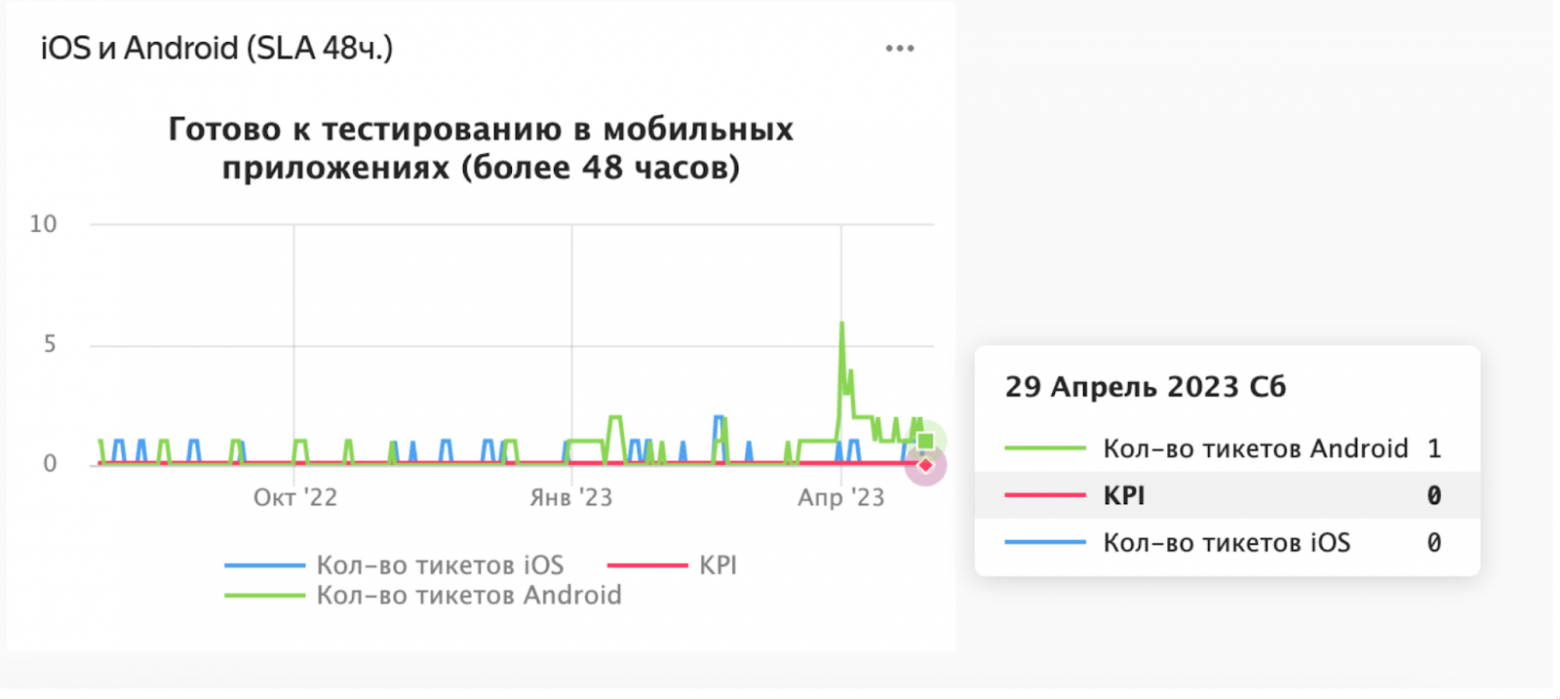
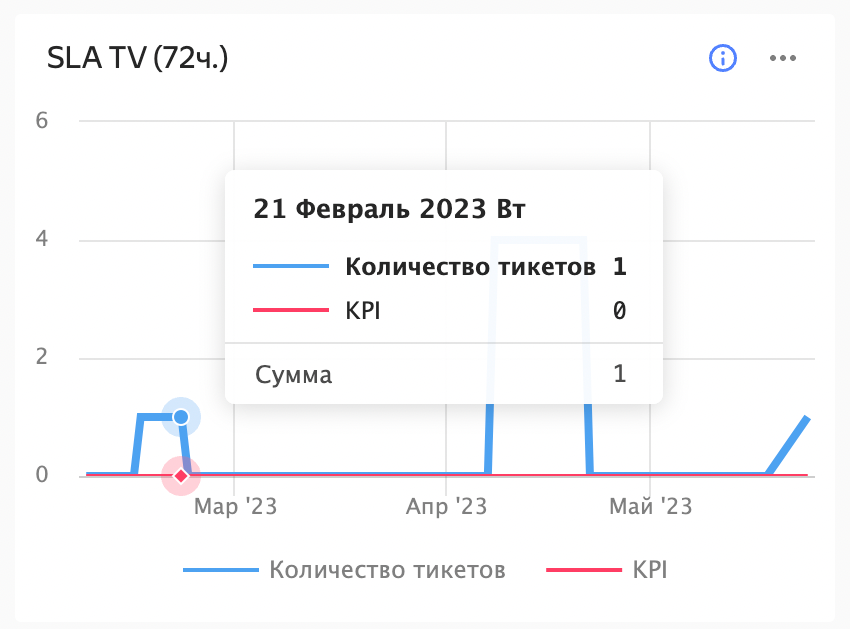
Соглашение об уровне сервиса (SLA)Время взятия тикета в тестирование. Здесь мониторится время, за которое тикет взят в тестирование после его готовности. Исключаются выходные, праздничные дни и нерабочее время. Метрика показывает, насколько оперативно команда реагирует на поступающие задачи. Большая тема для холивара: почему не учитывается время выполнения работы (тестирования задачи)? Если следить только за временем реакции, то что мешает тестировщику быстро набрать в работу 100500 тикетов? Во-первых, любые метрики можно хакнуть. Как вы используете метрики в своём проекте — вопрос целеполагания и культуры в команде (подробнее об этом в заключении). Во-вторых, у нас есть график, который показывает время нахождения задачи в определённом статусе. В контексте статуса Testing график является скорее вспомогательным. Есть ряд задач, которые можно протестировать достаточно быстро, а есть те, тестирование которых может занимать громадное количество времени. Поэтому пытаться вывести для всех единое максимальное время тестирования мы не стали.
Время реагирования на тикет, прилетевший в саппорт. Оно считается от момента передачи тикета от саппорта команде тестирования или разработки до момента взятия этого тикета в локализацию. Мониторится скорость ответа команды тестирования на обращение, переданное от пользователя. Это важно для удовлетворённости пользователей и оперативного решения проблем. Важно отметить, что команда тестирования не является первой линией ответа на обращения пользователей. Речь идёт только о тех обращениях (например, багах или проблемах), которые прошли через несколько линий саппорта и требуют вмешательства разработчиков или тестировщиков. Скорость реагирования здесь должна зависеть от приоритета обращения (можно определять по числу обращений в единицу времени).
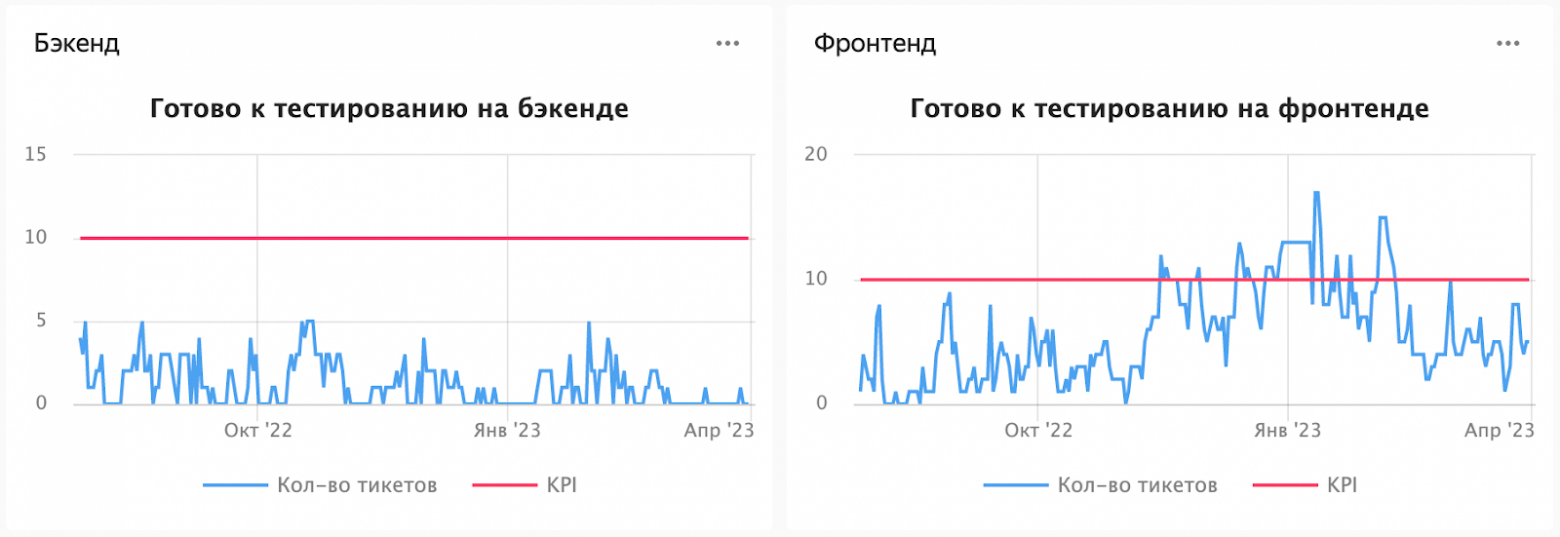
Для этих двух таргетов мы строим графики, плюс есть автоматика, которая сообщает о пробитии таргетов. Например, при массовом обращении пользователей на одну тему приходят автоматические отбивки в чаты. Ключевые показатели эффективности (KPI)Максимальное количество задач, единовременно готовых к тестированию. Эта метрика показывает, насколько команда справляется с текущим объёмом работы и насколько быстро она может переключаться между задачами.
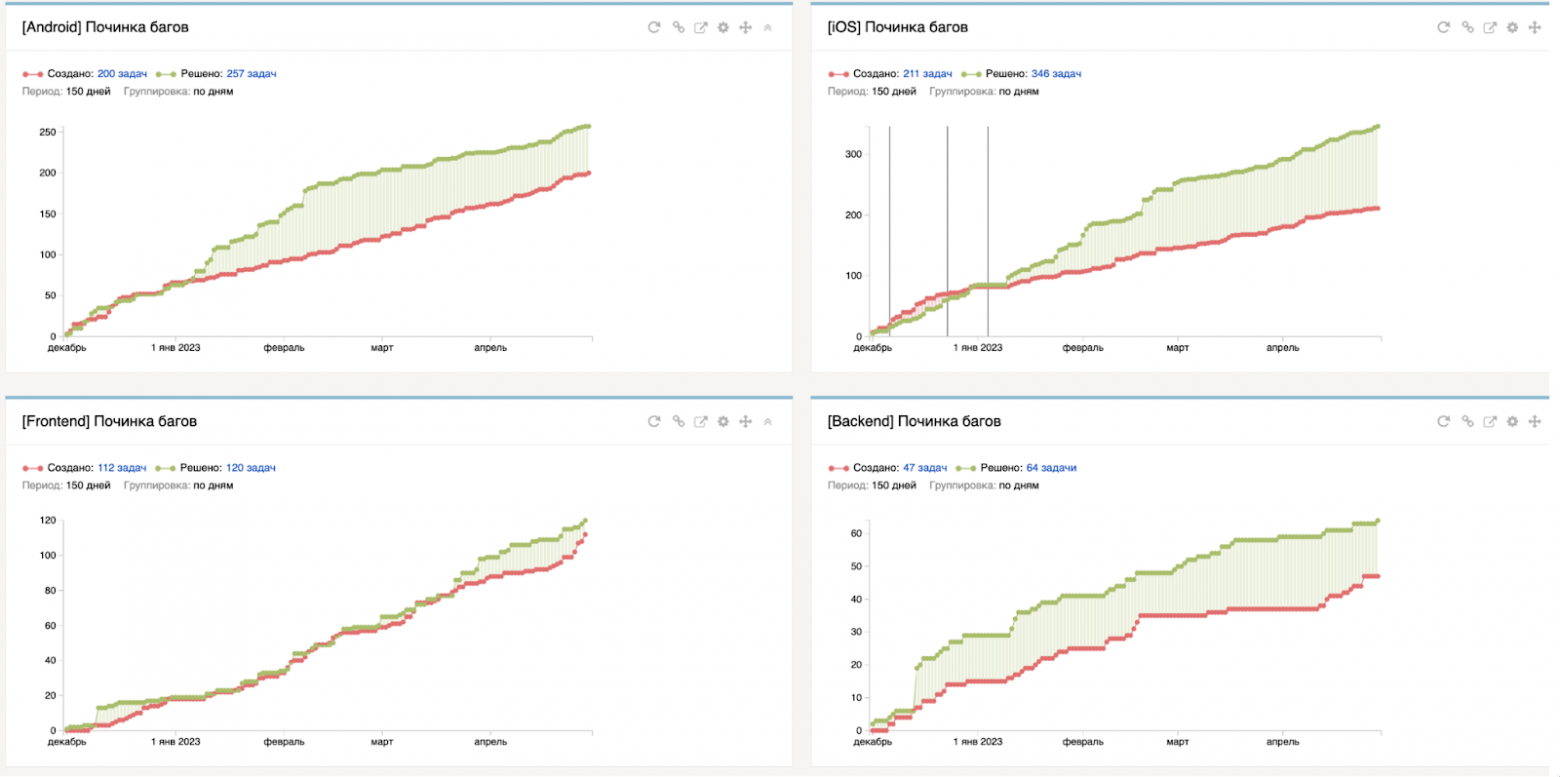
Метрика фиксов багов. Отношение заведённых багов к исправленным по каждой платформе. Эта метрика помогает оценить эффективность процесса исправления багов и определить, нужно ли вносить улучшения в процесс разработки или тестирования.
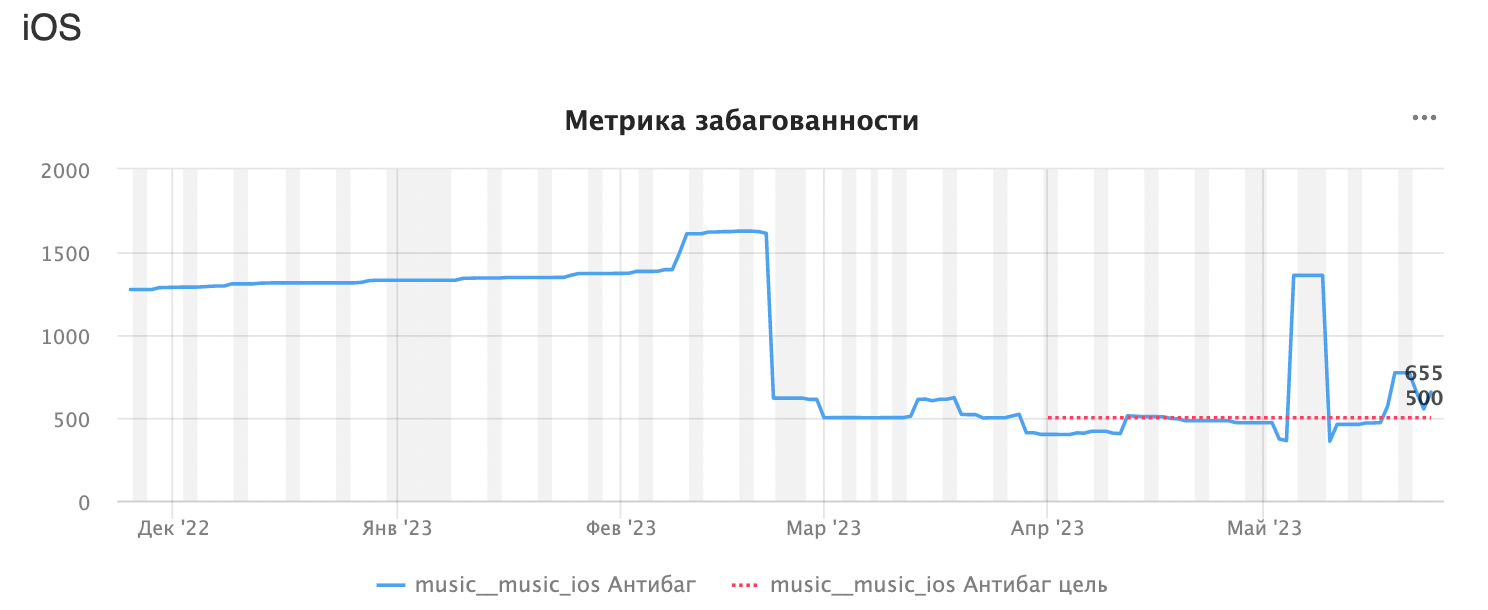
Метрика забагованностиАвтоматическое проставление критичности багаКритичность — вещь почти всегда субъективная. Для менеджера баг, найденный в рамках его горячо любимой фичи, может казаться критикалом, на самом же деле, если смотреть шире (в рамках всего сервиса), то критичность будет ниже. Становится чуть проще, если есть некое общепринятое (в рамках сервиса) формальное описание того, что считается блокером и критикалом. Поэтому, прежде чем приступить к рассмотрению под лупой вашего бэклога, постарайтесь сделать процесс выставления критичности более прозрачным. Мы доверили это ответственное дело беспристрастному роботу. В итоге критичность багу выставляется в зависимости от его веса. Vol 1. Определение веса и критичности багаЗдесь и далее будем рассматривать работу процесса для одной из платформ, чтобы не перегружать пост. Итак, как посчитать вес бага и определить его критичность: Шаг 1: определить минимально необходимый набор параметров, которые будут учитываться при выставлении критичности (определяется индивидуально для каждого продукта или сервиса). Браузер
Коэффициент воспроизводимости
Стадия
Влияние на пользователя
Количество обращений от пользователей На проблему могут жаловаться пользователи. Если у вас настроен счётчик обращений по конкретной проблеме, его также можно использовать для определения критичности бага. Сейчас просто нужно запомнить, что эту циферку тоже важно сохранять — она позволит понять, какие баги оказывают наибольшее влияние на пользователей, и сконцентрировать усилия на их исправлении. Шаг 2: сформировать формулу для расчёта веса бага (также может отличаться для каждого продукта или сервиса).
Шаг 3: определить диапазон весов.
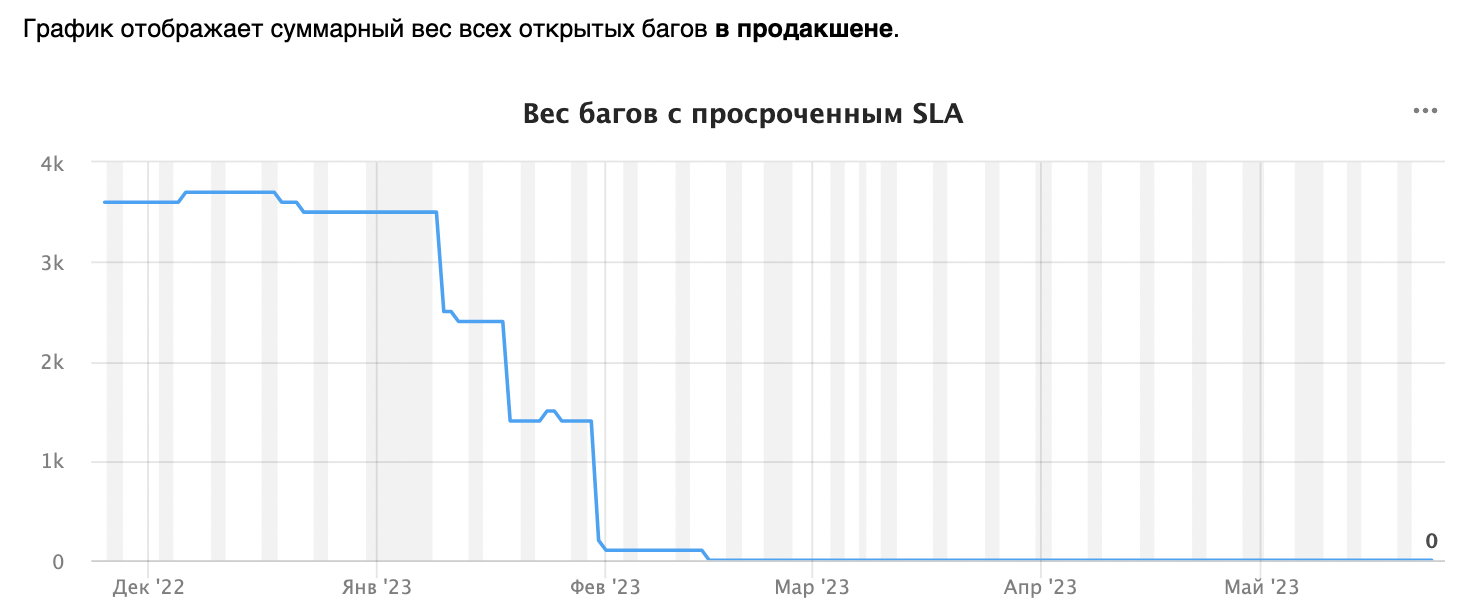
Используя полученные знания, можно честно определять критичность заводимых багов. Идём дальше. Vol 2. Автоматический расчётВышеуказанные входные параметры заполняются вручную автором бага. И тут можно было бы раздать всем тестировщикам по калькулятору. Считать каждый раз вес бага вручную было бы очень больно, поэтому данный процесс лучше автоматизировать. Подбор инструментов для автоматизации зависит от обвязки, которую вы используете: например, можно автоматизировать через скрипты или триггеры в баг-трекере. Автор тикета заполняет четыре поля, и ВЖУХ — вес считается автоматически, критичность также автоматически меняется на основании полученного веса. Vol 3. Обвесы к процессу (улучшайзеры)Что ещё происходит в рамках существующего процесса: призываем и наказываем автора багрепорта и дежурного QA, если для тикета не были проставлены нужные поля. Забагованность сервисаПро графики. Графики, они как стодолларовые купюры — всем нравятся! Если серьёзно, раньше мы собирали статистику по общему количеству открытых багов на каждой из платформ. Но сами по себе эти цифры ничего не дают. Условно можно сказать, много багов или мало, но это слабо коррелирует с забагованностью сервиса в целом. Поэтому мы обзавелись мониторингами, которые дают возможность отслеживать:
Взвесив все существующие баги, мы узнали, что у нас не просто N незакрытых багов в очередях, но и насколько они приоритетные, как влияют на общую картину сервиса. Любой новый баг, который аффектит пользователя и Музыку, сразу покажется на графике. У нас могут быть десятки открытых миноров (их вес небольшой), которые почти не меняют график, а можем словить всего один блокер, вес которого значительно влияет на график, и он сразу же будет заметен.
Когда метрики могут быть недостаточными
Что в итогеВозвращаясь к заголовку статьи, хочется ответить на два вопроса: Когда QA-метрики могут быть полезны? Необходимость внедрения и использования каких-либо метрик должна определяться каждой конкретной командой в каждом конкретном случае. Мне скорее хочется говорить о полезности. Полезно использовать метрики, потому что это позволяет замечать отклонения от ожидаемого поведения по таким параметрам, как скорость, качество, производительность. И далее предпринимать какие-либо действия, приводящие к улучшению процессов. Как использовать QA-метрики? Ухудшения показателей могут сигнализировать, например, о том, что есть недостаток ресурсов (тогда силы команды можно перераспределить или нанять ещё сотрудников) или необходимо пересмотреть текущие процессы (например, процесс планирования починки багов или внедрение дополнительных quality-gate). В статье перечислены те метрики, которые мы используем в своей работе. Они родились из потребностей, болей и идей нашей команды. Для каждого отдельного проекта можно выбирать свои, но при выборе и внедрении метрик важно учитывать контекст и ограничения каждой команды. Важно использовать метрики как инструмент для определения проблем и возможностей улучшения, а не как абсолютные показатели успеха. |