Что пишут в блогах
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Python для начинающихНачало: 16 июля 2026
-
Азбука ИТНачало: 16 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
| Как обеспечивать качество при релизах раз в час |
| 27.02.2023 00:00 |
|
Привет, я Михаил Шваркунов, директор по качеству ВКонтакте. Расскажу, как выглядят наши ежечасные релизы с точки зрения тестирования: как мы переложили часть задач по тестированию на разработчиков, сколько у нас автотестов и что мы ими покрываем. А ещё как команда тестирования сопровождает релиз, какие у нас при этом SLA и что делаем после. И вообще — зачем так часто что-то выкатывать? Что, нельзя подкопить и катать раз в день?
Деплой: раз в месяц → раз в час, или Зачем так часто У разных компаний бывают релизы и раз в месяц, и раз в неделю, у некоторых каждый день. ВКонтакте релиз происходит каждый час. Так было не всегда — до того, как мы так ускорились, наши релизные поезда были длинными и перегруженными, за ними всегда кто-то бежал с криками: «Подождите! Подождите! У меня релиз, договорённости, вы не можете без меня уехать!»
Зачем так часто релизить?
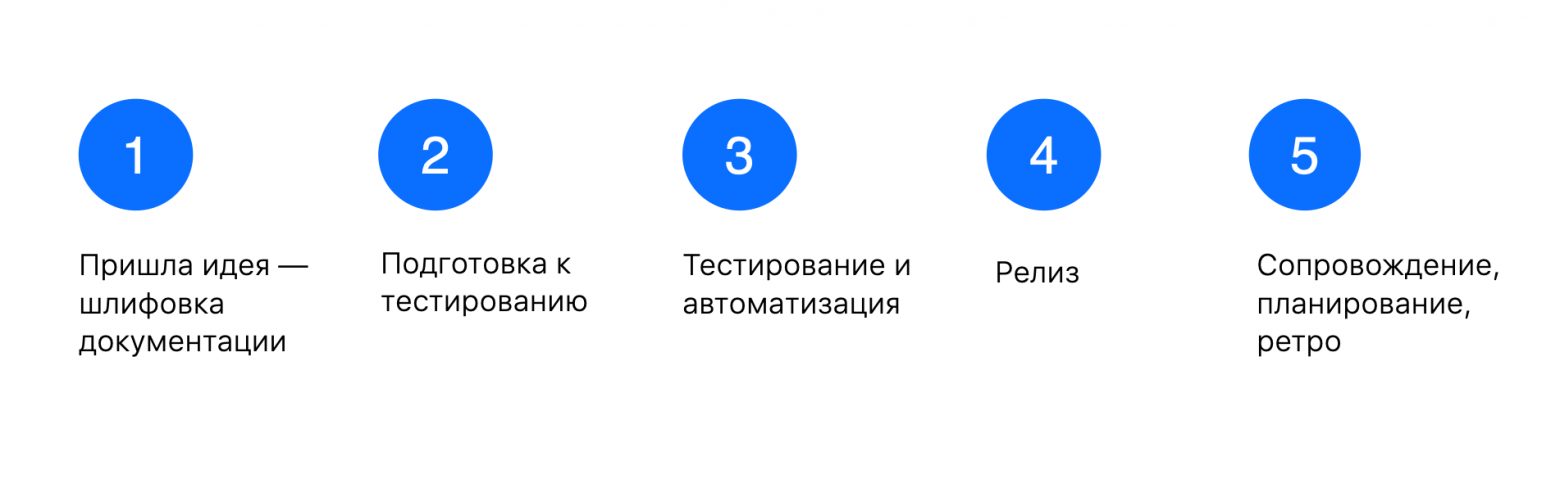
О каких платформах говоримВ этой статье расскажу про релизы ВКонтакте на четырёх платформах: веб, API, mvk, VKUI. Поясню: mvk — это версия ВКонтакте для мобильных браузеров, а VKUI — библиотека React-компонентов, которые используются и в основном приложении, и в сервисах внутри ВКонтакте, и в авторизации VK ID, и в других проектах. У мобильных клиентов ВКонтакте релизный цикл составляет неделю. Сейчас это завязано в основном на продолжительность ревью в сторах. Возможность релиза раз в час означает, что нам нужно в том числе быстро тестировать и подготавливать код к продакшену — поэтому статья будет состоять из двух основных частей: подготовки релиза и самого релиза. Таймлайн подготовки и релизаПокажу по шагам, с чего начинается и из каких этапов состоит подготовка к релизу и сам релиз ВКонтакте. Основные точки таймлайна такие:
Реализация любой новой идеи начинается с документации. Когда есть начальная версия, мы переходим к её тестированию.
За документацией В тестировании документации участвует много людей, потому что практически все фичи ВКонтакте выходят кросс-платформенно: обновления готовятся сразу для Android, iOS, веба и mvk. Соответственно, представители всех платформенных команд участвуют в составлении документации. Может, что-то противоречит уже реализованному поведению в других частях приложения? Или особенности платформы могут сильно повлиять на фичу? Ребята оставляют комментарии, обсуждают. Команда вносит правки, и в итоге получается достаточная документация, чтобы начинать писать тест-кейсы и чеклисты по ней. Если фича новая, документация пишется с нуля, тест-кейсы и чеклисты тоже. Если же она дополняет уже реализованную функциональность, то обновляем предыдущие доки. Храним чеклисты в Allure TestOps — ниже расскажу, почему используем именно этот инструмент. Ещё проводим кросс-ревью — это интересный механизм, который позволяет избежать ситуаций типа «разработчик, читая документацию, подумал одно, а тестировщик — другое». На кросс-ревью продакты и разработчики смотрят, что вообще будут проверять тестировщики, правильно ли команда QA интерпретировала документацию. Когда готовы все тест-кейсы, чеклисты и пройдено кросс-ревью, остаётся ещё пара важных шагов перед непосредственно тестированием. Проверка автотестов и чеклист разработчикаАвтотесты. Прежде чем запускать тестирование фичи, проверяем состояние автотестов. Когда разработчик собирает dev-окружение, сразу запускаются все автотесты. Есть две основные причины, почему они могут не пройти: либо разработчик что-то недосмотрел — тогда ему нужно исправить баги; либо изменилось поведение системы — и нужно адаптировать автотесты с учётом новой функциональности. Без этого дальше не движемся. Чтобы оптимизировать написание автотестов, используем несколько способов. Во-первых, для платформ, о которых говорим в этой статье (веб, API, mvk, VKUI), используется общий стек: Java, TestNG, Java SDK for VK API. Так автоматизацией на всех этих платформах могут заниматься одни и те же люди и не требуется смена контекста. Автотесты можно создавать и апдейтить оперативнее и быстрее убеждаться, что поведение на всех платформах одинаковое. Во-вторых, используем собственный сервис хранения ботов для масштабирования тестов. Сколько окружений разработчик соберёт — столько сможет запустить автотестов параллельно. Сервис позволяет выделить на каждый автотест конкретного бота (или ботов) и предотвратить конфликты в параллельных автотестах. Очень удобно, всем рекомендую. В-третьих, используем ботов с оповещениями: помогают тратить минимум времени на поиски «что где упало, к кому идти, кто виноват».
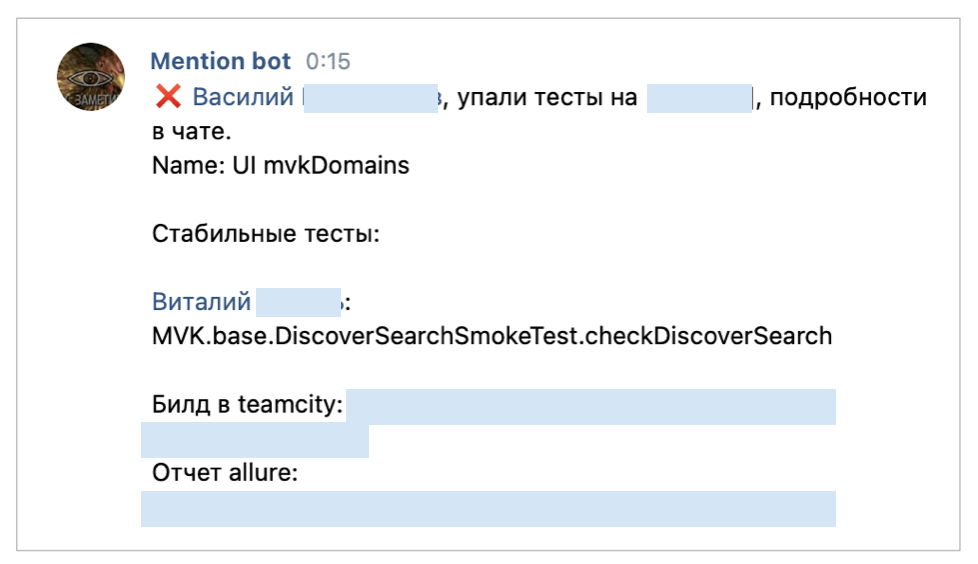
Смотрим на примере: на скрине видно, что бот упомянул разработчика Василия — у него упал тест на поиск в дискавере на mvk. Ещё заменшенили дежурного тестировщика Виталия: он должен убедиться, что никто не проглядел это падение, что все в курсе. Так бот помогает экономить много времени Чеклист разработчика помог нам существенно ускориться — за счёт того, что разработчики сами выполняют базовые проверки и следят, чтобы фича отправлялась на тестирование со всеми нужными ручками, дизайнами и другой информацией. Тестировщикам не приходится устраивать расследование и по пустяковым поводам возвращать коммиты на доработку программистам. В компактном чеклисте мы прописали, какие проверки должен выполнить разработчик, чтобы фича благополучно и оперативно ушла в тестирование. В первой части чеклиста несколько общих пунктов — например, чтобы в тикете был актуальный мастер. Во второй части — проверки для конкретных платформ, чтобы учесть их особенности. Так, если фича выпускается для mvk и веба, то обязательно должна быть поддержка тёмной темы. Или, например, чеклист напомнит для mvk проверить работу в старых браузерах, не поддерживающих современный JS: выбрать условную Nokia Lumia в Chrome DevTools и посмотреть на поведение фичи. Так люди с не самыми современными телефонами смогут воспользоваться возможностями ВКонтакте через мобильную версию. И так со всеми пунктами: каждый помогает убедиться, что фича готова к тестированию, или выявить пробелы. И чем раньше разработчик поймёт, что нужно исправить, тем быстрее и дешевле получится это сделать, чтобы пройти тестирование и выкатить фичу в продакшен.
Web Базовые проверки, web и mvk: домен собрался корректно и указан в тикете; подлит актуальный мастер; нужный код попал на этот домен и базовый сценарий фичи проверен разработчиком; все нужные ручки добавлены в тикет; необходимая документация и макеты присутствуют в тикете (либо в документации, указанной в тикете); заведены задачи на тестирование безопасности и дизайн-ревью, если требуется. Функциональные проверки, web: спецсимволы корректно вводятся и отображаются; фича открывается в Chrome, Firefox, Safari, визуально выглядят одинаково и соответствующе макетам; не сломались виджеты, если менялась исходная функциональность, использующийся в них; работают AJAX-переходы, без перезагрузок страниц на каждый переход; отображаемые пользовательские данные энкодятся (во избежание XSS-уязвимостей); корректно отображается на retina-дисплеях; при включении блокировщика рекламы, фича не ломается; корректное отображаются unicode-символы в переводах; тёмная тема отображается гармонично. Функциональные проверки, mvk: спецсимволы корректно вводятся и отображаются; тёмная тема отображается гармонично; фича работает на старых браузерах (nokia lumia 520 в devtools chrome, отключенный js); работают AJAX-переходы, без перезагрузок страниц на каждый переход; работает десктопный и мобильный варианта отображения; корректный редирект ссылки. Базовые проверки, бэкенд: проверить, что мастер ветка свежа и вмержена; убедиться, что домен раскатан и доступен; прикрепить ссылку на документацию; убедиться, что к задаче прилинкован правильный MR; убедиться, что все ручки (если они требуются) созданы и описаны в доке; убедиться, что приватные методы API отмечены как nodoc; при создании новых методов API убедиться, что описан ответ в JSON-схеме (это нужно для SDK и автоматизации). Функциональные проверки, бэкенд: проверить базовую функциональность изменяемой/создаваемой фичи; проверить, что ручки (если они есть) действительно включают/выключают функциональность; убедиться, что статистика базового кейса из пункта выше (если она должна быть) записывается в принципе; для API проверить, что метод(ы) работает(ют) с полагающимися токенами, и не возникает Access Error; убедиться в валидности кодировки ответов (что нет конфликта кодировок). Как внедрить такой чеклист и не взбесить разработчиков. Чеклист может выглядеть как лишняя работа, которую тестировщики просто не хотят делать. Расскажу, как мы его внедрили, чтобы коллеги позитивно восприняли изменения.
В первую очередь я зашёл к техническому директору ВКонтакте Александру Тоболю: рассказал о проблеме, предложил наш способ решения. Мы обсудили, покрутили и договорились, что проверки по чеклисту должны занимать у разработчика не больше 15 минут. На этом идея чеклиста получила апрув СТО. Потом я пообщался с разработчиками из команд платформ: под каждую мы написали отдельный чеклист и с секундомером зафиксировали, сколько он занимает. Ребята согласились с составом и таймингом чеклиста — так что у нас появился коллективный аргумент для возможных возражений в будущем. Дальше мы выбрали команду, с которой запустили чеклисты как эксперимент и получили первые успешные процессы и цифры: «Вот внедрили, такими лейблами помечали, вот проблема из чеклиста выявилась до тестирования, вот на столько ускорились». После этого мы успешно масштабировали чеклисты на все команды, и запуск прошёл довольно гладко. Тестирование и автоматизация: дорабатываем фреймворк и инфраструктуруПонятно, что в одной статье не получится подробно и конкретно показать, что и как мы тестируем ВКонтакте. Поэтому пока расскажу про несколько решений, которые помогают нам экономить ресурсы тестирования и при этом не оставлять без внимания важные для запусков моменты. Дизайн-ревью. Раньше у нас в процессе дизайн-ревью участвовали разработчики, дизайнеры и тестировщики. QA-команда заводила тикеты, делала скриншоты, отправляла дизайнеру, после изменений переправляла обратно в разработку, там чинили. А потом мы решили упростить схему и убрали из неё тестировщиков. Дизайнеры и разработчики общаются напрямую, а о необходимости дизайн-ревью напоминает наш чеклист.
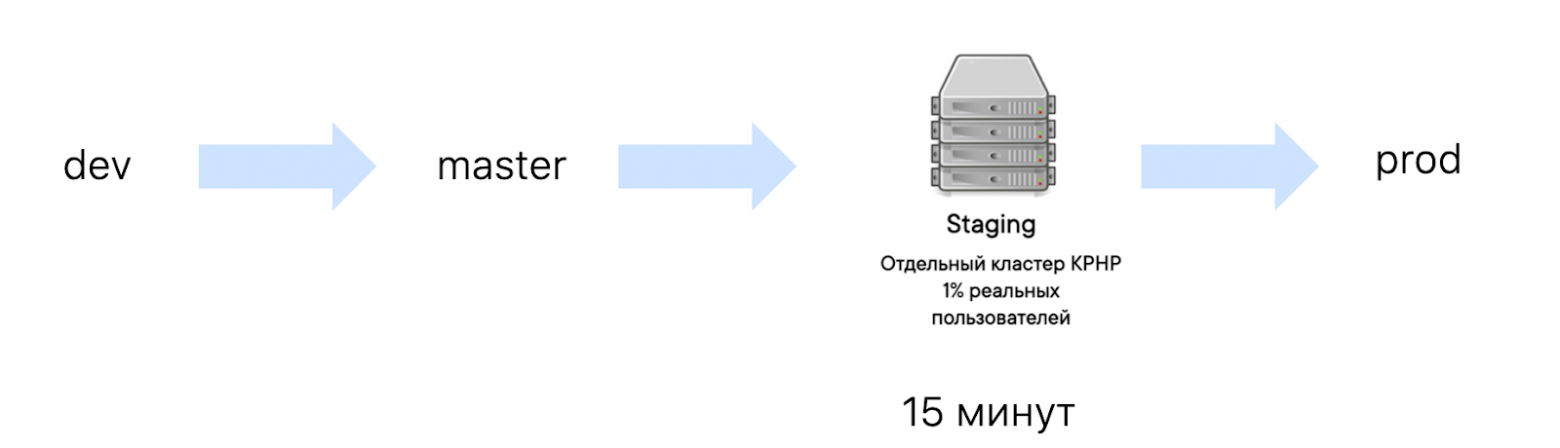
Пентест от информационной безопасности. Было время, когда мы на старте тестирования приходили к разработчику и спрашивали: «Дорогой, а вот в коде, который ты выкатил, потенциально есть уязвимости? А возможности для уязвимостей? Нужно ли нам ставить тикет на отдел ИБ?» И опять выступали как бы посредниками. Решили проблему так же: просто добавили в чеклист разработчика пункт о том, что если есть сомнения в плане уязвимостей, нужно связаться с ИБ. И разработчики решают этот вопрос напрямую с безопасниками. В общем, сейчас система устроена так: когда тикет в Jira переходит в статус Ready for testing, в нём загорается два чекбокса: «нужно дизайн-ревью» и «нужен пентест». Все в курсе и не забывают про нужные этапы. Покрываем автотестами основной сценарий. Почему только основной? Потому что дальнейшие выводы и действия будем продумывать с опорой на цифры — уже после выкатки в продакшен. А до того, как фича попала в релиз, ничего нельзя сказать о том, насколько она понравится пользователям, как много времени они будут взаимодействовать с ней, и будет ли большой трафик. Если фича зашла, доавтоматизируем проверки. Не зашла — ищем по аналитике, что стоит поправить относительно более популярных пользовательских сценариев. И матчим ручные проверки на Allure TestOps. Теперь, когда ручной тестировщик будет начинать тестирование, часть его проверок будет уже пройдена автотестами, которые запустились на dev-домене. Например, есть 100 проверок в плане у тестировщика и 20 из них автоматизировано — значит, мы сэкономили 20% времени специалиста. Релиз: протестированный код в мастереПереходим к самой интересной части — релизу. Весь код проходит через dev-окружение, master, staging и потом попадает в продакшен.
Staging — это отдельный KPHP-кластер, на который попадает 1% пользователей, их набор меняется каждый день. Важно, что у нас есть всего 15 минут для того, чтобы откатать код на staging и понять, всё ли с ним хорошо. Иначе не получится релизиться каждый час. Все этапы релиза рассмотрим на примере.
Двое программистов задеплоили свои изменения и код приехал на staging. Тут же запускаются автотесты: 2 500 автотестов в 40 потоков для API, 700 тестов в 40 потоков для веба. SLA на прогон всех автотестов составляет 5 минут — иначе не уложимся в наш таймлайн.
Параллельно запускаем мониторинги: на JS-ошибки, время загрузки страниц (важный индикатор для того, чтобы понять, если что-то пошло не так), состояние серверов, а также проверяем тематические группы и запросы в поддержку. Неравнодушные к ВКонтакте пользователи очень быстро сообщают о неполадках в специальных сообществах и пишут в поддержку.
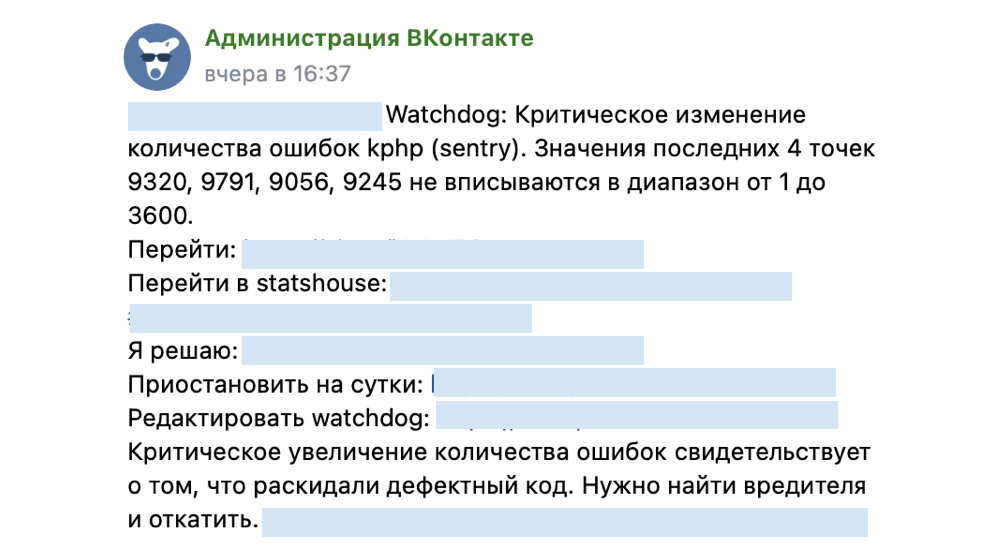
Пример графика мониторинга На графике выше какой-то показатель явно вышел за пределы наших ожиданий — повод обратить на него внимание и дополнительно проверить, всё ли в порядке. Но не забывайте, что мониторинги — это хорошо, но не всегда им можно доверять на 100%. Например, в прошлом году, когда у нас были нерабочие дни в мае, мониторинги сходили с ума, потому что поведение пользователей было нетипичным для будних дней. Если бы админы не учитывали это, могли принять неверные решения. Тем временем на staging завершилось автотестирование и сборка не прошла.
Итак, тест упал, вступают в силу SLA: 3 минуты на реагирование дежурных тестировщиков или админов, не более 5 минут на разбор.
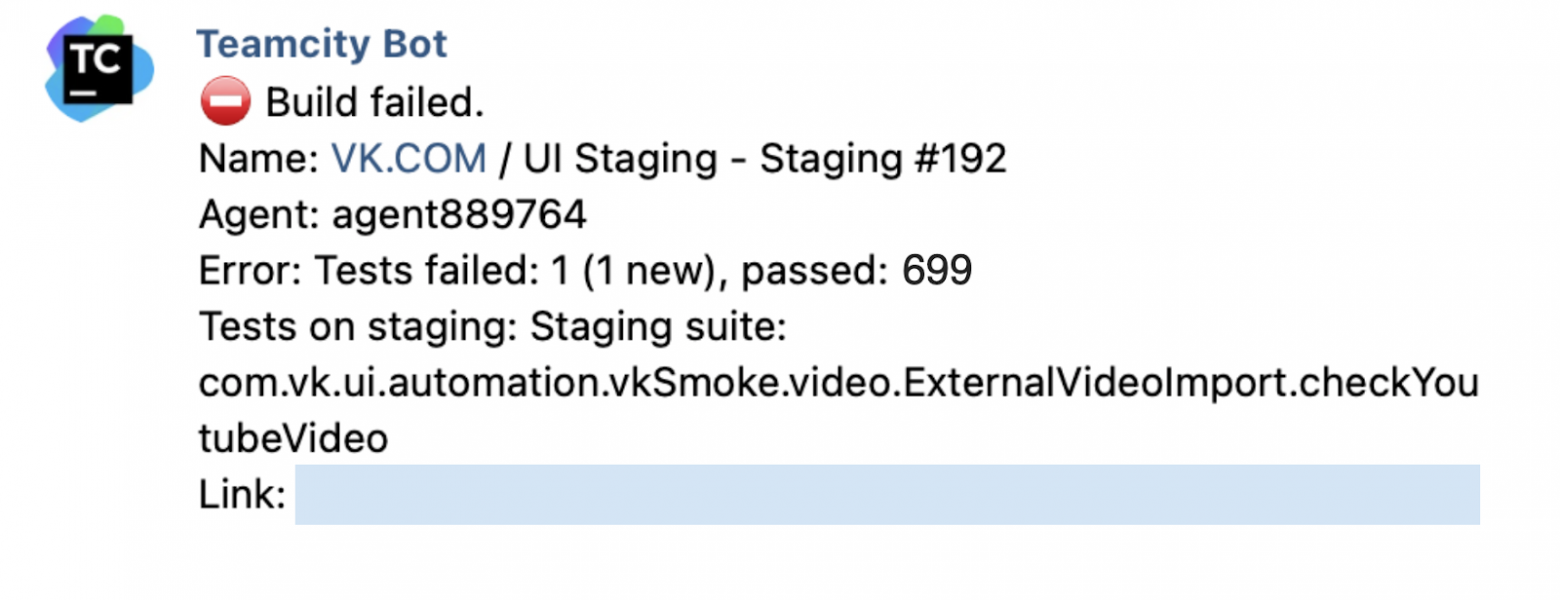
Надо заметить, что автотесты на staging могут падать из-за внешних причин, они не на 100% изолированы. Так, в этом примере мы видим, что упали тесты на YouTube. И это притом, что катились релизы ленты и аудио. Интересно. Дежурный Дима берётся за расследование: проверяет руками, что проблема воспроизводится, проверяет production. То есть с точки зрения автотестов всё верно, надо разбираться с релизом отдельно.
Далее Deploy Bot говорит, что версия на staging уже 15 минут и тот релиз, который не задели упавшие автотесты, готов к раскидыванию на продакшен.
Выкатка в продакшен Наш поезд стал быстрым и красивым. Он уверенно несёт код в продакшен, где уже готовы мониторинги. А у нас тем временем начинается новый цикл и новый релизный час: новый код попадает в мастер, проходит автотесты, попадает на staging и так далее. Но про выкаченные фичи мы тоже не забываем и возвращаемся к ним через 1–2 недели. После релизаКонтрольно проверяем аналитику и доавтоматизируем тестирование. Для примера на скриншоте ниже кусочек выгрузки аналитики наших данных. Она включает разные события — create, like, delete, edit, restore, spam. Некоторые из них помечены как (autotest) — значит, эти события генерируются автотестами, а не пользователями. < Мы анализируем события разными способами и ориентируемся на популярность пользовательских сценариев, чтобы приоритизировать проверки. Убеждаемся, что проверяемые кейсы действительно тестируются: контролируем и себя, и аналитику. Также после релиза проводим ретроспективу и уточняем планы: насколько перспективно вливать в фичу ресурсы и трафик. Анализ жалоб, Helpdesk issue count. Многие сталкивались с проблемами такого плана: есть баг в продакшене, и кто-то говорит, что его нужно срочно починить, а другие — что это не приоритетный вопрос, нужно заняться чем-то другим. Мы решаем такие дилеммы с помощью Helpdesk issue count — механизма сопоставления обращений пользователей и багов из таск-трекера. Если появляется новая жалоба, счётчик увеличивается и чат-бот оповещает команду: внимание, у такого-то тикета уже, например, 24 жалобы. Плюсы метрики пользовательских жалоб:
Выводы — без автотестов никуда
А мы тем временем продолжим ускоряться. Для веба поставили себе новую цель: иметь возможность релизить раз в полчаса. На мобильные платформы планы пока скромнее, но тоже делаем всё, что от нас зависит, чтобы выпускать релизы чаще. |