Что пишут в блогах
- Мои 12 недель в году. Часть 34 (Вернулась на работу! ДР мужа и детей: Кате...
- Анализируем данные в файле с помощью ИИ
- Используете ИИ для написания кода? Объясняем, как его правильно тестировать
- Как я сделала отчет о дифференциальном тестировании через Cursor
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Азбука ИТНачало: 30 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Python для начинающихНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Школа для начинающих тестировщиковНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Тестирование REST APIНачало: 10 августа 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 13 августа 2026
-
Применение ChatGPT в тестированииНачало: 13 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 18 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
-
Практикум по тест-дизайну 2.0Начало: 18 сентября 2026
| Новаторские подходы в тестировании |
| 21.06.2018 15:27 |
|
Автор: Елена Шамхалова, компания "Лаборатория качества" Оригинальная публикация: http://quality-lab.ru/report-for-march-2018/ Как показать заказчику, что согласованного времени не хватает на тестирование? Что поможет не пропустить ни одного бага? Эти проблемы мы решили в марте. Что же нам помогло? Нашими спасателями стали тест-анализ, планирование и прозрачная отчетность! Надеемся, что наша статья поможет вам обойти грабли, на которые наступили мы. 1. Внедряем прозрачную отчетностьНа проекте по тестированию мобильного приложения возникла путаница с тестовой документацией, а именно с тест-кейсами и чек-листами. Проблема заключалась в том, что заказчика вообще не интересовала наша документация, и он не спешил согласовывать правильность составленных чек-листов и тест-кейсов. Совершенно не выделялось время как на написание и актуализацию документов, так и на смоук и регрессионное тестирование перед релизами; они выполнялись лишь частично в редкие свободные моменты. Такая ситуация длилась долгое время и привела к тому, что на продуктиве начали сыпаться критические и блокирующие дефекты. Соответственно, у целевой аудитории нарастало раздражение при пользовании продуктом. Наконец было принято решение изменить подход к тестированию – внедрить чек-листы, описывающие весь функционал продукта, оценить трудозатраты на их прохождение (тестирование каждого шага) и использовать их при смоук и регрессионном тестировании, дополняя новыми хитрыми шагами. 1. Отдельный лист с указанием каждого компонента продукта и типа его проверки. При прохождении шага тестировщик указывает статус тестирования, свои ФИ и дату прохождения (тестирования), ссылку на дефект или причины, блокирующие тестирование. Колонки «Статус», «Тестировщик», «Дата последней проверки», «Дефекты» объединены под одну шапку, в которой указывается тестируемая версия и тип тестирования – смоук или регресс; для каждой последующей версии эти колонки дублируются с указанием новой версии в шапке.
2. Лист с общей оценкой на прохождение всего чек-листа с учетом возможных рисков.
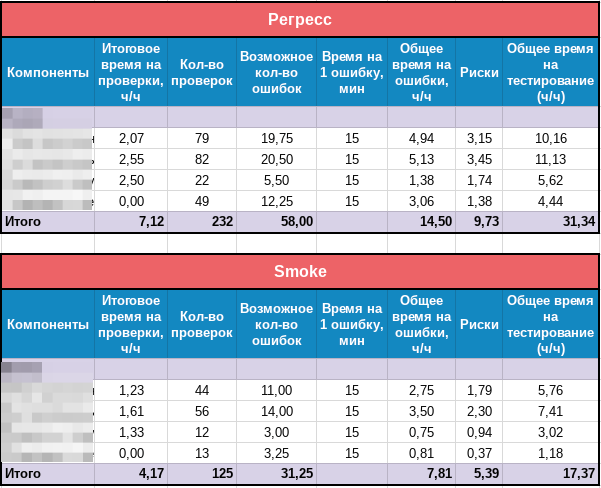
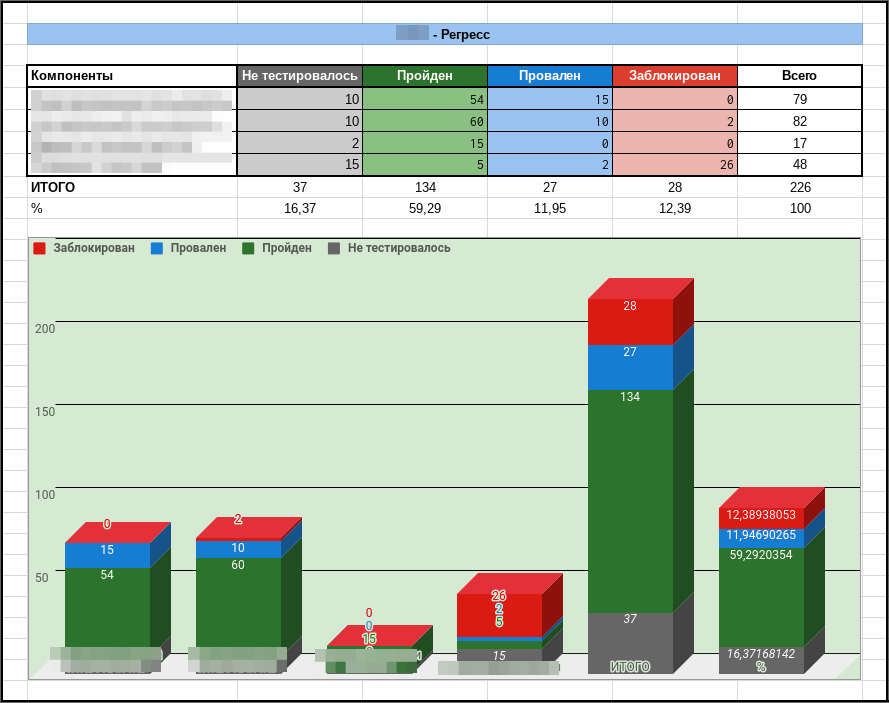
3. Лист с общей статистикой – перечень всех типов проверок и отображение статусов проверки всех компонентов в табличном виде и в виде диаграммы (создается отдельно для каждого смоук и регрессионного тестирования).
Имея перед собой первоначальную оценку и ежедневную статистику (мы отправляли ее скриншот с указанием обработанных за день задач), заказчик получил возможность принимать более эффективные решения. Он наконец-то увидел объем наших работ перед релизом и стал соглашаться с нами в вопросах предоставления нужного количества времени на смоук и регрессионное тестирование. Благодаря указанным чек-листам и отчетам продукт в скором времени обрел заметную стабильность; критические и блокирующие дефекты на продуктиве стали редким явлением, практически не зависящим от нас.
Итак, наметим последовательность действий, которые дадут Вам возможность планировать будущие работы и мониторить статус их выполнения: 1. Составьте чек-лист, в котором будет указано реальное время на тестирование каждого шага (чек-листы могут быть отдельными на каждый модуль, а может быть один на всю систему). 2. Вычислите общее время на тестирование всего чек-листа или общее время тестирования на одном окружении (браузере, устройстве). 3. Подготовьте таблицы для планирования трудозатрат на каждый вид тестирования, который применяется у Вас в практике (смоук, регресс, санити). В этих таблицах рассчитайте все риски, превышающие время из чек-листа:
4. Определите количество тестируемых окружений, взяв за основу масштабы трудозатрат. 5. Создайте таблицы и графики, которые будут показывать постоянную онлайн статистику в разрезе необходимых показателей (по окружениям, по модулям/компонентам системы, по приоритету строк чек-листа и т.д.). Все это можно легко и быстро реализовать без использования дорогих продуктов. 2. Думаем, анализируем, планируем, релизимВ Лаборатории качества мы любим разные проекты: крупные, где более 100 независимых подсистем взаимодействуют друг с другом, средние, в которых 6-7 опытных тестировщиков заботятся о качестве 20-30 модулей под контролем тест-менеджера, и маленькие, требующие участия с нашей стороны всего нескольких специалистов. Не секрет, что даже небольшая команда способна осваивать крупные объемы работ. В данном случае на проекте по тестированию государственной информационной системы муниципальных учреждений, где со стороны Лаборатории качества было задействовано всего два специалиста, ожидался очень крупный релиз. Как все успеть при таких условиях? Как не пропустить ни одного критического дефекта и отдать пользователям качественный продукт, если на все про все остается всего 3 недели? На помощь команде пришел тест-анализ и тест-дизайн. Наши тестировщики проанализировали свой опыт на основе нескольких предыдущих версий, собрали статистику использования системы, выявили проблемные места продукта. Что получилось в итоге?
Мы бы хотели поделиться своим опытом и ответить сразу на три вопроса: как все успеть? как не пропустить ни одного критического дефекта? как отдать пользователям качественный продукт?
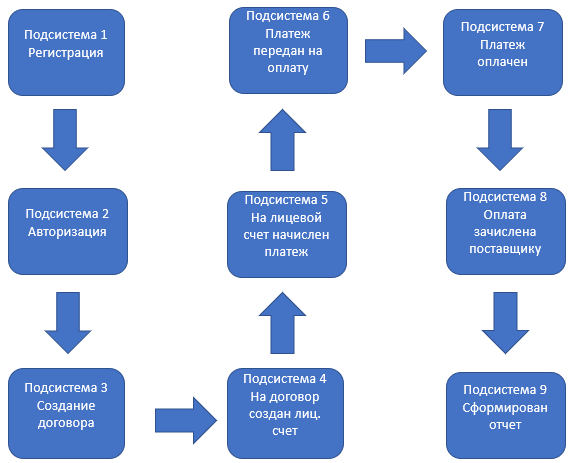
3. Осваиваем системное тестирование на крупном проектеНа проекте по тестированию государственной информационной системы в сфере ЖКХ, включающем более 100 взаимосвязанных подсистем с множеством интеграций с внешними государственными системами, стабильно выпускалось в релиз свыше 60 крупных доработок. К сожалению, процент невыявленных дефектов на продуктиве был довольно высоким для проекта с многомиллионной аудиторией. Исследование показало, что немалая часть дефектов пропускается не на стадии первой итерации тестирования доработки, а на этапе регресса. Сложность также заключалась в том, что каждая доработка затрагивала несколько подсистем с зонами ответственности разных интегрированных команд, которые тестировали ее одновременно. Время окончания тестирования «своей части» у разных команд было разное; нередко баг-фикс дефектов наводил новые дефекты в других подсистемах, проверка которых уже была завершена.
В процессе поиска выхода из ситуации рассматривались разные варианты решений (в том числе и увеличение объема регресса), но в итоге было признано целесообразным внедрить «системное тестирование». В чем суть данного подхода? Мы исходили из того, что каждая доработка, даже затрагивая несколько подсистем (причем изменения могут иметь различные объемы и логику), делается с единой целью: достичь работоспособности каких-то конкретных бизнес-сценариев. Теперь, получая такую доработку, мы действовали по следующему алгоритму:
После того, как последняя команда из участвующих завершает свой тест, в доработке снова проверяется составленный сквозной бизнес-сценарий, затрагивающий все подсистемы. При его успешности доработка закрывается и считается успешно протестированной. 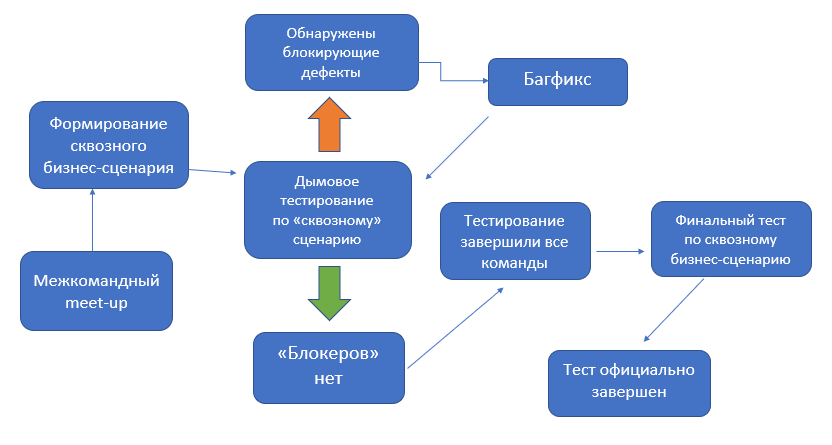
4. Развиваем нашу команду!Указанные проекты стали самыми интересными, но далеко не единственными делами нашего коллектива. Чем еще запомнился прошедший месяц? 1. Наша команда пополнилась новым тест-менеджером. Мы расширяемся и развиваемся, ведь каждый новый сотрудник – это привнесенные навыки, свежий взгляд на процесс и ресурс для охвата большего объема работ! 2. Два специалиста нашей команды успешно окончили курсы по тест-дизайну и SQL для тестировщиков. Мы непрерывно улучшаем качество знаний и навыков наших сотрудников, а также осваиваем новые направления, которые в дальнейшем могут быть востребованы на проектах наших клиентов. 3. Не можем не упомянуть и о многочисленных «отзывах счастья», полученных от наших заказчиков. Вот только некоторые из них:  |