Что пишут в блогах
- Мобильный маркетинг начинается с QA: как тестирование влияет на модерацию и рейтинг приложения
- При общении с ИИ не усложняйте вопрос, это сожрет лишние токены
- Настраиваем IDEA с ИИ, уточняем теорию, часть 3
- Как маркетологу готовить сайты и приложения к акциям – и почему нельзя слепо доверять своим...
- Как убрать поп-ап с параметром в ТeamСity
- Перестаньте считать баги: современные метрики тестирования для IT-команд
- Как ИИ нам проверку уязвимостей сломал
- Настраиваем IDEA с ИИ, часть 2
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Тестирование REST APIНачало: 20 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Python для начинающихНачало: 23 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 23 июля 2026
-
Азбука ИТНачало: 23 июля 2026
-
Применение ChatGPT в тестированииНачало: 23 июля 2026
-
Школа для начинающих тестировщиковНачало: 23 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Bash: инструменты тестировщикаНачало: 30 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 30 июля 2026
-
Git: инструменты тестировщикаНачало: 30 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 30 июля 2026
-
Docker: инструменты тестировщикаНачало: 30 июля 2026
-
SQL: Инструменты тестировщикаНачало: 30 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Техники локализации плавающих дефектовНачало: 3 августа 2026
-
Логи как инструмент тестировщикаНачало: 3 августа 2026
-
Школа тест-менеджеров v. 2.0Начало: 5 августа 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 6 августа 2026
-
Тестирование GraphQL APIНачало: 6 августа 2026
-
Charles Proxy как инструмент тестировщикаНачало: 6 августа 2026
-
Регулярные выражения в тестированииНачало: 6 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Тестирование веб-приложений 2.0Начало: 14 августа 2026
-
Школа Тест-АналитикаНачало: 19 августа 2026
-
Программирование на C# для тестировщиковНачало: 21 августа 2026
-
Программирование на Python для тестировщиковНачало: 28 августа 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 31 августа 2026
-
Тестирование производительности: JMeter 5Начало: 4 сентября 2026
-
Организация автоматизированного тестированияНачало: 4 сентября 2026
-
Автоматизация тестирования REST API на JavaНачало: 16 сентября 2026
-
Автоматизация тестирования REST API на PythonНачало: 16 сентября 2026
-
Тестирование безопасностиНачало: 16 сентября 2026
-
Тестирование мобильных приложений 2.0Начало: 16 сентября 2026
-
Создание и управление командой тестированияНачало: 17 сентября 2026
| Точная оценка задач QA: возможно ли это? |
| 20.01.2025 00:00 |
|
Автор: Фроленков Роман Привет! Меня зовут Роман Фроленков, я являюсь руководителем группы тестирования QA в компании «Комус-Тех». В нашей команде более 10 внутренних QA-специалистов, а также свыше 15 специалистов из аутсорса, которые работают в составе продуктовых команд. В этой статье хочу поделиться опытом нашей команды: с какими проблемами мы столкнулись при оценке задач QA, какие подходы пробовали, и какой метод в итоге стал для нас наиболее эффективным. Сразу уточню: я не претендую на универсальность предложенного метода. Этот подход успешно работает в рамках наших процессов, но это не значит, что он подойдет всем без исключения. Методы я решил подробно не описывать, так как их описание можно легко найти в открытых источниках. В данном материале я сделал акцент на правильное сочетание, своевременность применения и нюансы использования этих подходов. Если вам интересно узнать больше о каждом из упомянутых методов, рекомендую ознакомиться с их описанием в этой статье: TestGrow Работая в QA, я часто сталкивался с проблемой: как объективно оценить трудозатраты на тестирование задач? Не раз замечал, что оценки «на глаз» оказывались неточными. Ведь если заложить слишком много рисков — в релиз попадут не все задачи, а если их не заложить — есть и вовсе риск не успеть провести полноценный регресс или найти дефекты только за несколько часов до релиза.
Вкратце про наш флоу тестирования задач:
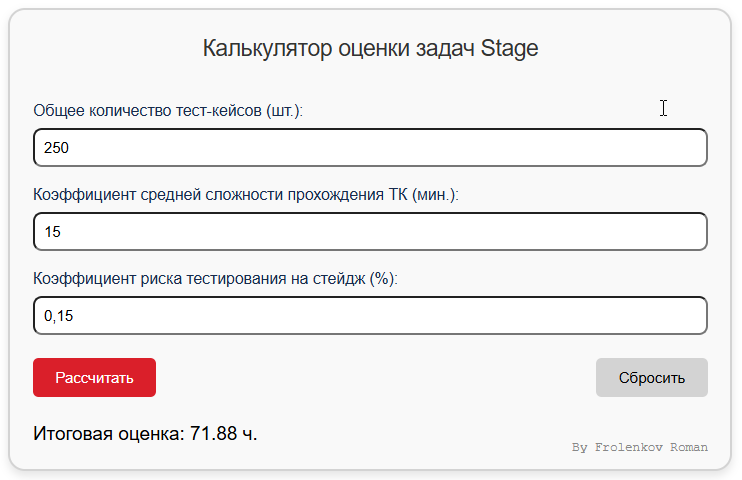
Опираясь на наш флоу, мы с командой выработали подход, базирующийся на двух ключевых точках оценки: 1️⃣ Оценка на основе спецификации (Оценка на QA-стенд)На данном этапе мы сталкиваемся с ограничениями: доступна лишь верхнеуровневая спецификация. Это особенно сложно, если задача связана с новым функционалом или системой, с которой мы ранее не работали. Изначально я планировал использовать метод распределения работ (или декомпозиции задач)* в сочетании с техникой PairWise — разбиваем спецификацию на детальные требования, оцениваем их среднюю сложность проверки, после чего рассчитываем количество проверок техникой PairWise с учетом платформы, браузеров и т. д., далее высчитываем время ну, и закладываем риск, а также время на написание тест‑кейсов. Это помогло бы учесть такие параметры, как кроссплатформенность, кроссбраузерность, типы пользователей и другие важные аспекты. Ведь проверка функционала на всех браузерах, платформах и пользователях, в большинстве случаев, была бы исчерпывающей. Однако в нашем случае реализация такого подхода оказалась слишком ресурсоемкой. Причина в том, что каждая продуктовая команда работает с уникальным функционалом. Несмотря на общий шаблон спецификаций, структура и детализация требований часто отличаются. Это создает сложности для унифицированной декомпозиции задач, требуя значительных временных затрат на адаптацию под каждый конкретный случай. И, проверив такой подход в ретроспективе, оказалось, что результат не всегда оправдывал ожидания. В итоге мы решили отказаться от этого подхода в пользу более гибких и менее трудозатратных методов. Таким образом, для первой точки я выбрал методы эмпирической и сравнительной оценки тестирования* (Методы верхнеуровневой оценки), поскольку детальная оценка требует значительных временных затрат и может быть неэффективной. Однако для крупных задач, где оценка превышала плюс‑минус 100 человеко‑часов, возникали значительные расхождения между оценкой и фактическими затратами. В таких случаях мы начали использовать метод — Pert анализа (анализ трех точек)*, что позволило нам найти баланс между трудозатратами и качеством оценки. Также мы донесли главную информацию до бизнеса и команды, что на данном этапе оценка является верхнеуровневой, в связи с высокой степенью неопределенности и невозможностью предсказать все риски, а также количество, сложность дефектов и проблемы со стендом, которые могут возникнуть в процессе. По тому же принципу мы приняли решение не писать тест‑кейсы на данном этапе. Несмотря на популярность подхода Shift Left, невозможно учесть все факторы и написать корректные тест‑кейсы, основываясь только на спецификации. Это почти всегда приводит к необходимости корректировки тест‑кейсов после тестирования задачи. Кроме того, существуют риски, связанные с изменениями в спецификации или даже отменой задачи. Проблема: трудозатраты на крупные задачи часто сложно спрогнозировать. Решение: метод анализа трёх точек в комбинации с методами эмпирической и сравнительной оценки помогает сбалансировать скорость оценки и её точность. 2️⃣ Оценка после завершения тестирования на QA-стенде (Оценка на STAGE)Когда тестирование задачи на QA завершено, риски уменьшаются и оценка становится проще и точнее. Как раз на текущем этапе мы пишем тест-кейсы и инструкции. Таким образом у нас уже есть: ✔️ Написаны тест-кейсы. Ранее, на данном этапе, оценка проводилась методами эмпирической и сравнительной оценки или высчитывалась в процентном соотношении от времени тестирования на QA, что часто приводило к значительным расхождениям с фактическими затратами. Для уменьшения данного расхождения мы пришли к использованию метода распределения работ (или декомпозиции задач)*, с учетом имеющихся артефактов тестирования (дефектов и тест-кейсов), создав формулу, что позволило повысить точность оценки. Формула оценки трудозатрат:
Где:
Как мы это автоматизировали?
РезультатыБлагодаря данным методам:
А как обстоят дела у вас? Какие подходы вы используете для оценки трудозатрат в QA? Поделитесь своим опытом и инсайтами — возможно, ваши идеи помогут нам улучшить наши процессы! * Источники и описание методов можно посмотреть здесь: TestGrow |