Что пишут в блогах
- ИИ, помоги мне настроить IDE
- Типы границ для классов эквивалентности
- Какие задачи в тестировании пора отдать ИИ, чтобы получить результат, а не новые проблемы?
- Готова ли ваша IT-инфраструктура к внедрению цифрового рубля?
- Software Engineering Happiness Index 2025
- От вебинаров до биллинга: что нужно тестировать в EdTech на самом деле
- Штат, гибрид или аутсорс тестирования: честный разбор экономики QA-команд в 2026
- Как нагрузочное тестирование защищает бизнес от убытков?
- Исследовательское тестирование и UX‑аудит для интернет-магазина
- Юзабилити‑тестирование без розовых очков: почему идеальный функционал не спасёт от провала?

Что пишут в блогах (EN)
- The AI House presented by KPMG
- Humans In The Way
- Checking Isn’t Testing. Soon It Won’t Be Employment Either
- Measuring for AI success and quality improvement
- BSides Luxembourg 2026 - True Community Spirit
- Growing trees, today
- MCA Awards 2026
- Testing: The Art of Unlearning
- More work for the same salary
- Estimating the population of Zabok using public data
Онлайн-тренинги
-
Школа тест-менеджеров v. 2.0Начало: 24 июня 2026
-
Python для начинающихНачало: 25 июня 2026
-
Азбука ИТНачало: 25 июня 2026
-
Школа для начинающих тестировщиковНачало: 25 июня 2026
-
Тестирование веб-приложений 2.0Начало: 26 июня 2026
-
Тестирование REST APIНачало: 29 июня 2026
-
Тестирование без требований: выявление и восстановление информации о продуктеНачало: 29 июня 2026
-
Школа Тест-АналитикаНачало: 1 июля 2026
-
Bash: инструменты тестировщикаНачало: 2 июля 2026
-
Chrome DevTools: Инструменты тестировщикаНачало: 2 июля 2026
-
Git: инструменты тестировщикаНачало: 2 июля 2026
-
Инженер по тестированию программного обеспеченияНачало: 2 июля 2026
-
Автоматизация тестов для REST API при помощи PostmanНачало: 2 июля 2026
-
Применение ChatGPT в тестированииНачало: 2 июля 2026
-
SQL: Инструменты тестировщикаНачало: 2 июля 2026
-
Docker: инструменты тестировщикаНачало: 2 июля 2026
-
Программирование на C# для тестировщиковНачало: 3 июля 2026
-
Организация автоматизированного тестированияНачало: 3 июля 2026
-
Техники локализации плавающих дефектовНачало: 6 июля 2026
-
Логи как инструмент тестировщикаНачало: 6 июля 2026
-
Charles Proxy как инструмент тестировщикаНачало: 9 июля 2026
-
CSS и Xpath: инструменты тестировщикаНачало: 9 июля 2026
-
Регулярные выражения в тестированииНачало: 9 июля 2026
-
Тестирование GraphQL APIНачало: 9 июля 2026
-
Программирование на Python для тестировщиковНачало: 10 июля 2026
-
Автоматизация тестирования REST API на JavaНачало: 15 июля 2026
-
Автоматизация тестирования REST API на PythonНачало: 15 июля 2026
-
Тестирование безопасностиНачало: 15 июля 2026
-
Тестирование мобильных приложений 2.0Начало: 15 июля 2026
-
Создание и управление командой тестированияНачало: 16 июля 2026
-
Тестирование производительности: JMeter 5Начало: 17 июля 2026
-
Тестировщик ПО: интенсивный курс (ПОИНТ) со стажировкойНачало: 21 июля 2026
-
Практикум по тест-дизайну 2.0Начало: 24 июля 2026
-
Программирование на Java для тестировщиковНачало: 31 июля 2026
-
Аудит и оптимизация процессов тестированияНачало: 7 августа 2026
-
Автоматизация функционального тестированияНачало: 7 августа 2026
| Выбираем подходящий баг-трекинг |
| 19.07.2019 00:00 |
|
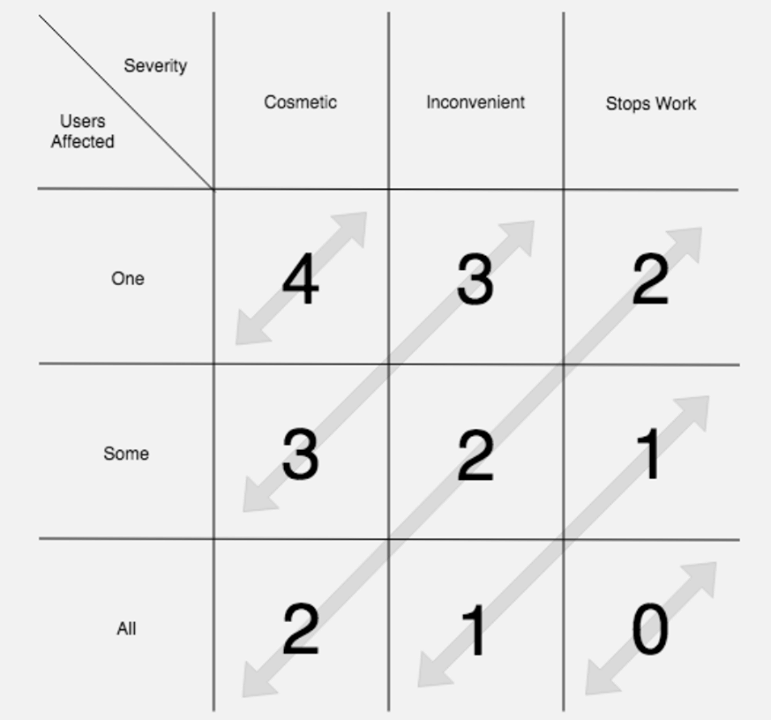
Автор: Евгений Иванченко Я общался с десятками QA-инженеров из разных компаний и каждый из них рассказывал о том, что у них используют разные системы и инструменты для баг-трекинга. Мы тоже пробовали несколько из них и я решил поделиться решением, к которому мы пришли. ИнтроБуду банален. Ошибки появляются и обнаруживаются на различных этапах процесса разработки. Поэтому можно разделить баги на категории, в зависимости от времени их обнаружения:
С чего мы начинали, или JiraДва года назад у нас была выделенная команда тестировщиков, которые вручную тестировали продукт после интеграции кода всех команд. До этого момента код проверялся разработчиками на девелоперских стендах. Ошибки которые находили тестировщики заносились в бэклог в Jira. Баги хранились в общем бэклоге и переезжали из спринта в спринт с другими задачами. Каждый спринт два-три бага доставались и чинились, но большинство оставалось на дне бэклога:
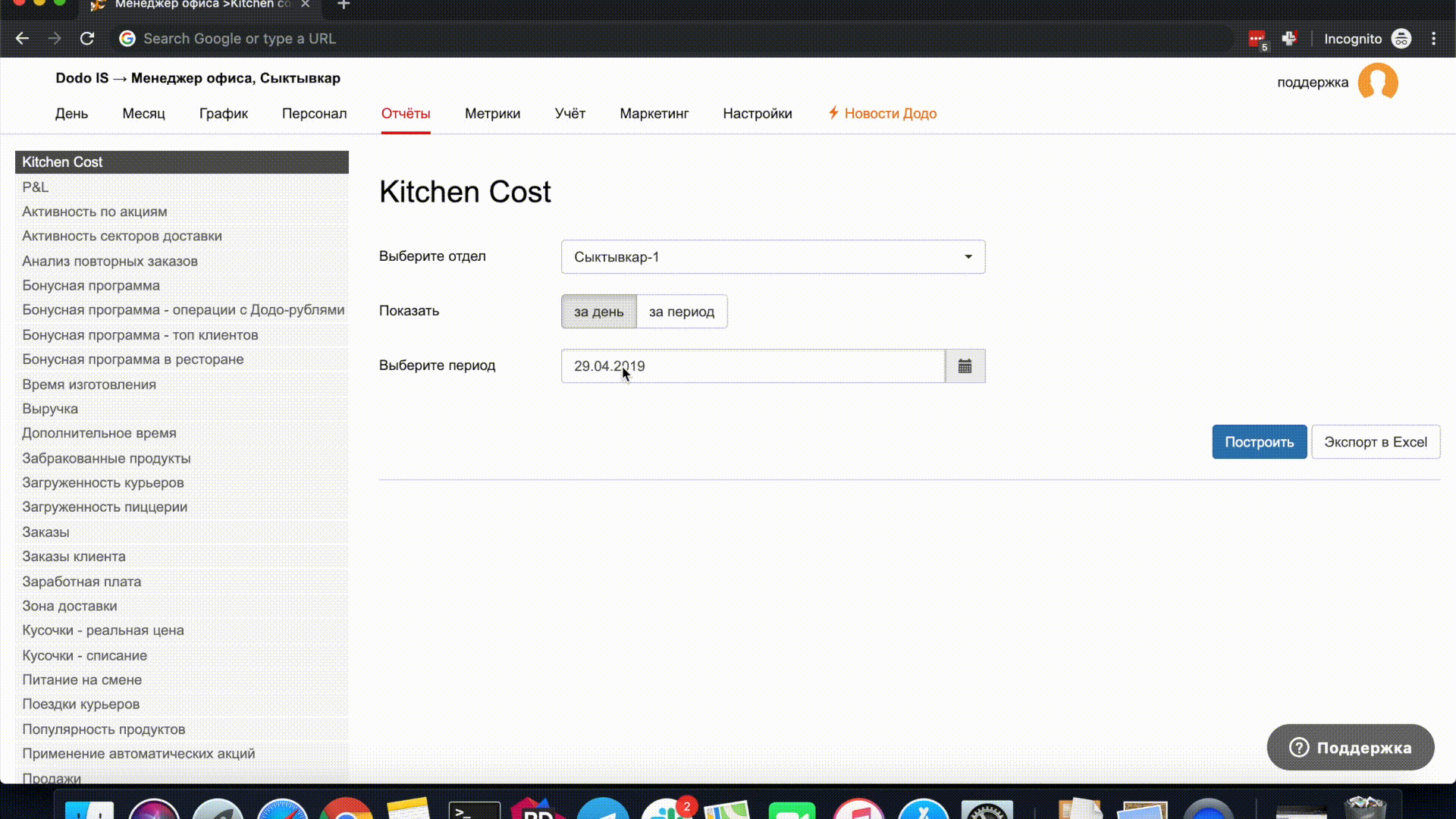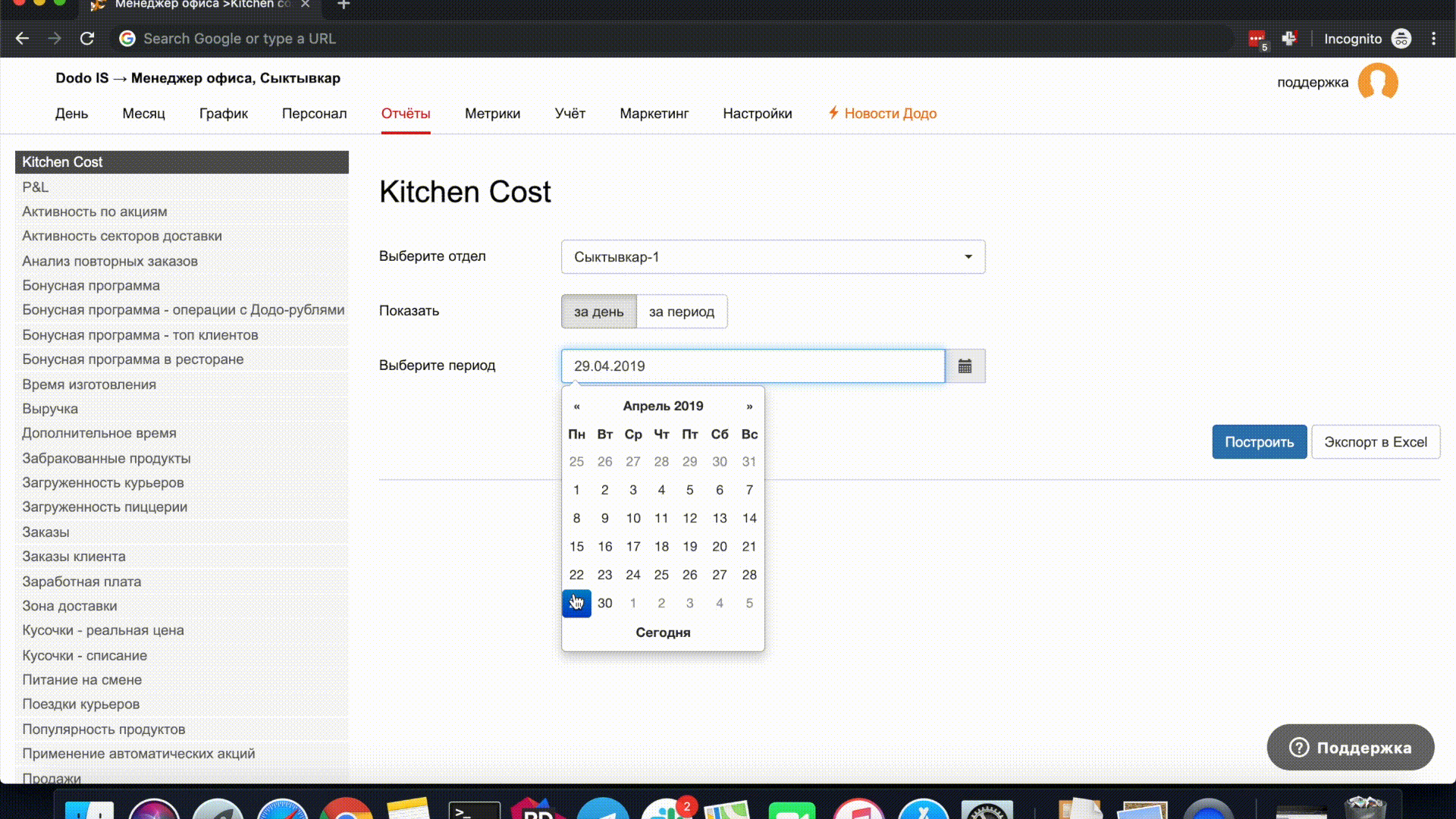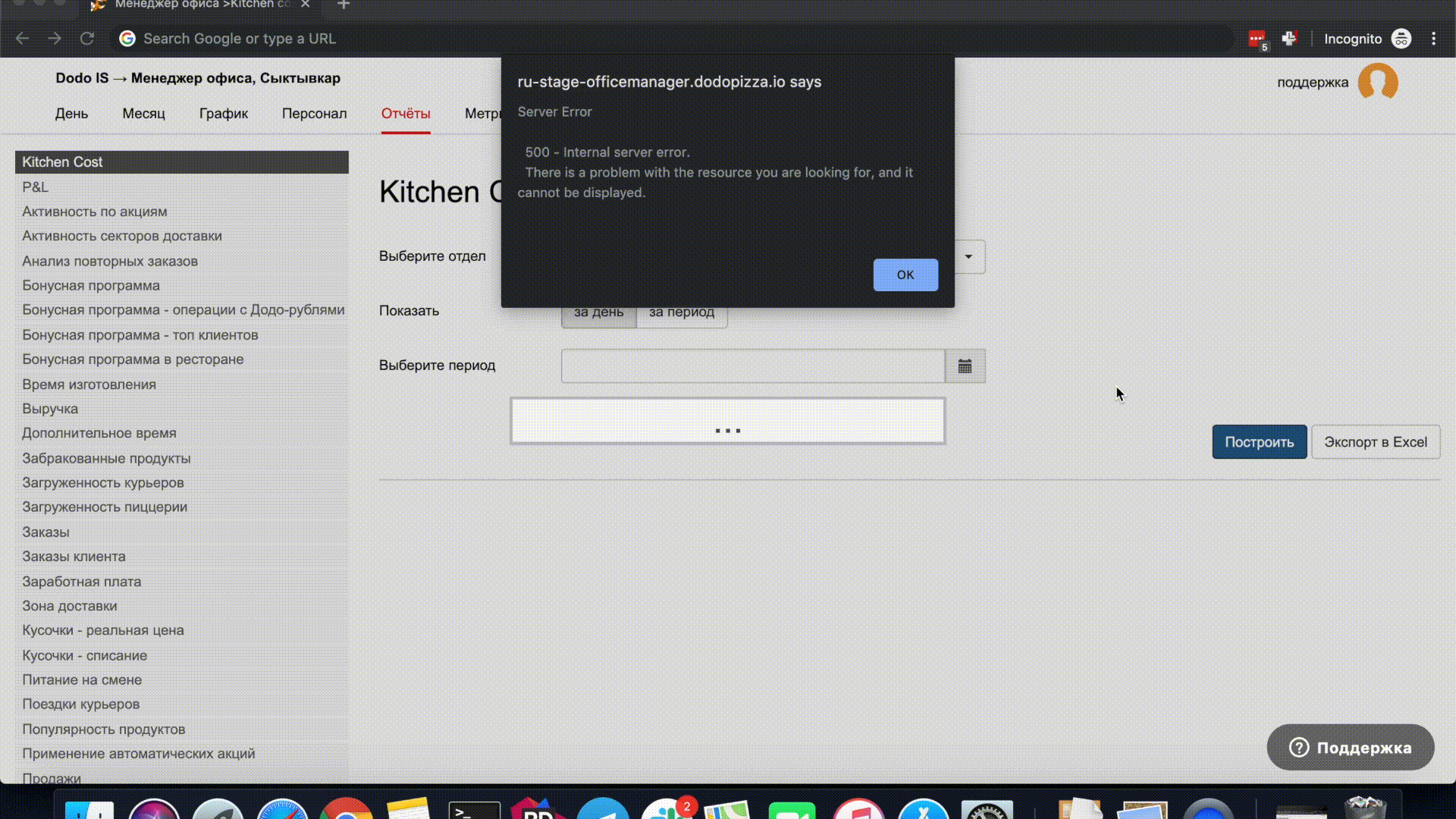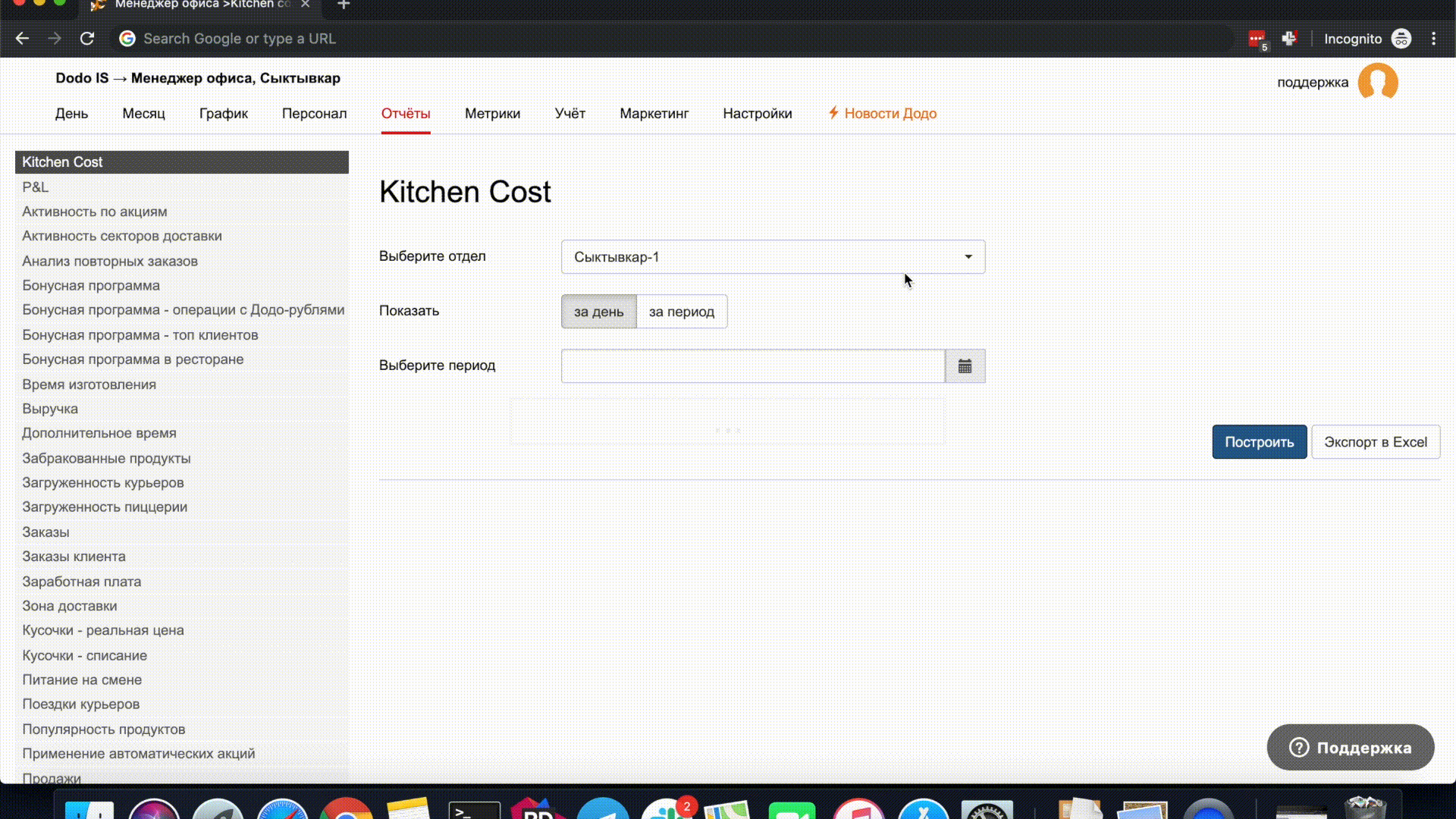
Приведу простой пример. При построении отчётов в полях ввода даты по умолчанию подставляется сегодняшний день. При изменении даты в попапе можно снова выбрать сегодняшний день и поле ввода даты очистится.
Прощай Jira, да здравствует Kaiten Весной 2018 года мы отказались от Jira и перешли в Kaiten. Смена инструментов была вызвана причинами, о которых Андрей Арефьев написал в статье «Почему Додо Пицца стала использовать Kaiten вместо связки Trello и Jira». После перехода в Kaiten наш подход к работе с багами не изменился:
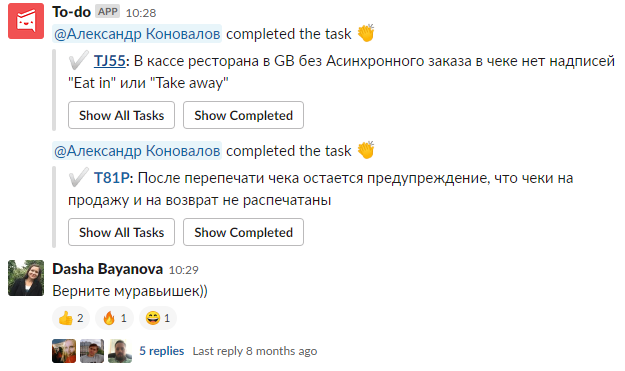
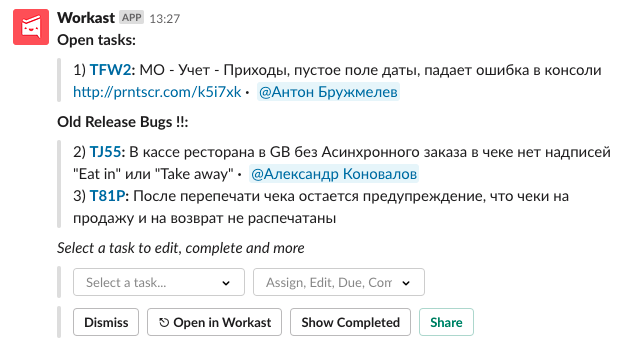
Время экспериментов, или нетМы решили поэкспериментировать с форматами и создали отдельную доску в Kaiten, на которой хранили баги и меняли статусы. Мы упростили заведение баг-репорта, чтобы тратить меньше времени. При добавлении карточки в Kaiten тестировщики помечали разработчиков. Об этом им на почту отправлялось уведомление. Мы вывели эту доску на монитор, который висел в проходе рядом с нашим рабочим местом, чтобы разработчики видели прогресс и процесс тестирования стал прозрачным. Эта практика тоже не прижилась, потому что основной канал общения – Slack. Наши разработчики не проверяют почту часто. Поэтому это решение быстро перестало работать и мы снова вернулись к Slack. Верните муравьишекПосле неудачного эксперимента с доской в Kaiten, некоторые разработчики всё ещё были против формата с сообщением в Slack. И мы стали думать как трекать баги в слаке и решить проблемы, которые мешали разработчикам. В результате поисков наткнулись на приложение для Slack, Workast, которое помогает организовать работу с тудушками прямо в мессенджере. Мы подумали, что это приложение позволит управлять процессом работы с багами более гибко. У этого приложения были свои плюсы: смена статусов и назначение на разработчиков по одному нажатию кнопки, завершенные задачи скрывались и сообщение не разрасталось до огромных размеров. Наш идеальный способ по работе с багами сейчасВ конце 2018 - начале 2019 года у нас в компании произошли ряд изменений, которые повлияли на процесс работы с багами.
ИтогиКоротко говоря, мы отказались в принципе от баг-трекинговой системы. С помощью такого подхода работы с багами мы решили несколько болей:
Я не хочу сказать, что трэкинг багов бесполезен. Баги которые мы берём в работу трэкаются как и любые другие задач. Но баг-трэкинговая система это не обязательный атрибут тестирования. Её не нужно использовать только потому, что используют большинство компаний и так принято в индустрии. Нужно «думать головой» и примерять инструменты к своим процессам и потребностям. Для нас идеально работать без баг-трекинговой системы сейчас. За пол года такой работы, мы ни разу не подумали о том, чтобы вернуться к ней и снова заводить все баги туда. |